Recognition: unknown
HAVEN: Hybrid Automated Verification ENgine for UVM Testbench Synthesis with LLMs
Pith reviewed 2026-05-07 05:27 UTC · model grok-4.3
The pith
HAVEN generates UVM testbenches and sequences by directing LLMs to plan architecture while using fixed protocol templates and a DSL for the actual code.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
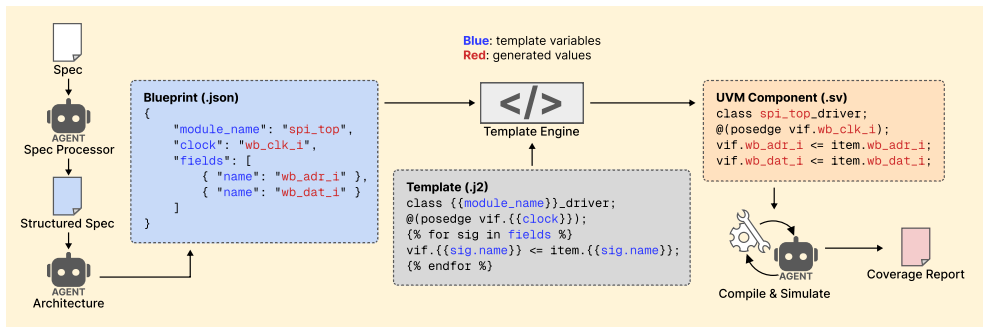
HAVEN is the first system that utilizes pre-defined, protocol-specific Jinja2 templates to generate all UVM components and UVM sequences using our proposed Protocol-Aware DSL and rule-based code generator. LLM agents produce an architectural plan from specifications; the Template Engine then combines this plan with the templates to produce components that include correct bus-handshake timing. Sequences begin with predefined DSL patterns for high baseline coverage; LLM agents iteratively analyze coverage gap reports and compose additional DSL sequences. On 19 open-source IP designs spanning three interface protocols the system achieves 100 percent compilation success, 90.6 percent code cover,
What carries the argument
HAVEN Template Engine paired with the Protocol-Aware Sequence Domain-Specific Language (DSL) and rule-based code generator that fills predefined Jinja2 templates instead of letting LLMs emit HDL directly.
If this is right
- All UVM components for the three protocols are produced with correct bus-handshake timing without any direct HDL output from the LLM.
- Predefined DSL patterns establish a high baseline coverage rate before any LLM involvement in sequence creation.
- Iterative LLM analysis of coverage gap reports produces additional sequences that raise both code and functional coverage.
- The hybrid pipeline yields 100 percent compilation success and average coverage of 90.6 percent code and 87.9 percent functional across 19 designs.
- The method outperforms prior LLM-assisted UVM generation approaches on the same set of protocols and designs.
Where Pith is reading between the lines
- Adding support for a new protocol would require only new templates and DSL patterns, after which the same LLM planning and gap-analysis loop could be reused.
- The separation between LLM planning and template-driven code generation could be applied to other syntax-heavy generation tasks where raw LLM output is unreliable.
- Verification teams could shift effort from writing boilerplate UVM code to reviewing the architectural plans and coverage reports produced by the system.
- The DSL itself could serve as a readable, human-editable intermediate representation even if the LLM layer were removed.
Load-bearing premise
Predefined protocol-specific templates and DSL patterns can be written and maintained to correctly produce every required UVM component and bus-handshake timing for the supported protocols, while LLM agents can reliably interpret coverage gap reports to add sequences without omissions or new errors.
What would settle it
Apply HAVEN to an open-source IP core that uses one of the three tested protocols but contains timing or functional features absent from the original 19 designs, then check whether compilation still succeeds at 100 percent and measured coverage remains above 85 percent.
Figures



read the original abstract
Integrated Circuit (IC) verification consumes nearly 70% of the IC development cycle, and recent research leverages Large Language Models (LLMs) to automatically generate testbenches and reduce verification overhead. However, LLMs have difficulty generating testbenches correctly. Unlike high-level programming languages, Hardware Description Languages (HDLs) are extremely rare in LLMs training data, leading LLMs to produce incorrect code. To overcome challenges when using LLMs to generate Universal Verification Methodology (UVM) testbenches and sequences, wepropose HAVEN (Hybrid Automated Verification ENgine) to prevent LLMs from writing HDL directly. For UVM testbench generation, HAVEN utilizes LLM agents to analyze design specifications to produce a structured architectural plan. The HAVEN Template Engine then combines with predefined and protocol-specific templates to generate all UVM components with correct bus-handshake timing. For UVM sequence generation, HAVEN introduces a Protocol-Aware Sequence Domain-Specific Language (DSL) that decomposes sequences into fine-grained step types. A set of predefined DSL patterns first establishes sequences that achieve a high coverage rate without LLM involvement. HAVEN continues to improve the coverage rate by iteratively leveraging LLM agents to analyze coverage gap reports and compose additional targeted DSL sequences. Unlike previous works, HAVEN is the first system that utilizes pre-defined, protocol-specific Jinja2 templates to generate all UVM components and UVM sequences using our proposed Protocol-Aware DSL and rule-based code generator. Our experimental results on 19 open-source IP designs spanning three interface protocols (Direct, Wishbone, AXI4-Lite) show that HAVEN achieves 100% compilation success, 90.6% code coverage, and 87.9% functional coverage on average, and is SOTA among LLM-assisted testbench generation systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces HAVEN, a hybrid system for automated UVM testbench and sequence generation that combines LLM agents for design analysis and coverage-gap closure with a Template Engine using pre-defined protocol-specific Jinja2 templates and a Protocol-Aware Sequence DSL plus rule-based generator. It claims this prevents direct HDL generation by LLMs, achieves 100% compilation success, 90.6% code coverage, and 87.9% functional coverage on average across 19 open-source IP designs for Direct, Wishbone, and AXI4-Lite protocols, and is the first such system to use these templates for all UVM components and sequences, making it SOTA among LLM-assisted approaches.
Significance. If the template correctness and experimental reproducibility hold, HAVEN could meaningfully lower the verification overhead (claimed at ~70% of IC development) by providing a more reliable hybrid path than pure LLM generation for UVM testbenches. The hybrid design with DSL decomposition and iterative coverage-driven sequence generation is a practical engineering contribution that could be adopted in industry flows if the templates prove maintainable and generalizable beyond the three protocols.
major comments (3)
- [Abstract, §3] Abstract and §3 (HAVEN Template Engine): The central claim that HAVEN is the first system to use pre-defined protocol-specific Jinja2 templates to generate all UVM components with correct bus-handshake timing rests on the assumption that these manually authored templates fully encode every legal timing, reset, and phasing rule for Direct, Wishbone, and AXI4-Lite. No section describes validation of the templates against an independent reference UVM implementation or stress-testing on corner cases (e.g., back-to-back transactions with variable wait states). Without this, the reported 100% compilation success is not demonstrably reproducible or generalizable to new designs exercising untested rules.
- [§5] §5 (Experimental Results): The headline metrics (100% compilation, 90.6% code coverage, 87.9% functional coverage) are reported as averages over 19 designs without per-design tables, explicit selection criteria for the open-source IPs, or full baseline comparisons against prior LLM-assisted UVM systems. This makes it impossible to verify the SOTA claim or assess whether the hybrid pipeline's non-LLM half is the decisive factor versus the LLM coverage-closure loop.
- [§4] §4 (Protocol-Aware Sequence DSL and LLM agents): The iterative coverage-closure loop assumes LLM agents can reliably analyze gap reports and compose additional DSL sequences without introducing errors or missing cases. The paper provides no failure-mode analysis, error rates for the LLM step, or fallback mechanisms when the rule-based generator plus LLM composition fails to reach the reported functional coverage.
minor comments (3)
- [Abstract] Abstract contains a typo: 'wepropose' should be 'we propose'.
- [§3] The paper should clarify whether the protocol-specific Jinja2 templates and DSL patterns will be released as open source; without them, the reproducibility of the 100% compilation result is limited.
- [§4] Notation for the DSL step types and coverage metrics could be formalized in a table for clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments on our paper. We have addressed each major comment point by point below, proposing revisions to the manuscript where appropriate to improve its clarity and completeness.
read point-by-point responses
-
Referee: [Abstract, §3] Abstract and §3 (HAVEN Template Engine): The central claim that HAVEN is the first system to use pre-defined protocol-specific Jinja2 templates to generate all UVM components with correct bus-handshake timing rests on the assumption that these manually authored templates fully encode every legal timing, reset, and phasing rule for Direct, Wishbone, and AXI4-Lite. No section describes validation of the templates against an independent reference UVM implementation or stress-testing on corner cases (e.g., back-to-back transactions with variable wait states). Without this, the reported 100% compilation success is not demonstrably reproducible or generalizable to new designs exercising untested rules.
Authors: We appreciate this observation. The templates in HAVEN were carefully crafted to adhere to the official protocol specifications, which define the legal timing, reset, and phasing rules. However, the original manuscript lacks explicit details on their validation. We will revise Section 3 to include a description of the template validation methodology, including cross-verification with standard UVM reference implementations and targeted testing for corner cases like back-to-back transactions with varying wait states. This addition will better support the reproducibility of our 100% compilation success rate and the generalizability of the approach. revision: yes
-
Referee: [§5] §5 (Experimental Results): The headline metrics (100% compilation, 90.6% code coverage, 87.9% functional coverage) are reported as averages over 19 designs without per-design tables, explicit selection criteria for the open-source IPs, or full baseline comparisons against prior LLM-assisted UVM systems. This makes it impossible to verify the SOTA claim or assess whether the hybrid pipeline's non-LLM half is the decisive factor versus the LLM coverage-closure loop.
Authors: We agree that aggregate metrics alone are insufficient for thorough evaluation. In the revised version, we will include a detailed table presenting per-design results for compilation success, code coverage, and functional coverage across all 19 designs. Additionally, we will specify the selection criteria for the open-source IPs, which were selected from established repositories to represent a range of complexities for the Direct, Wishbone, and AXI4-Lite protocols. We will also enhance the baseline comparisons by providing more comprehensive analysis against prior LLM-assisted UVM systems, emphasizing the role of the non-LLM components (templates and DSL) in achieving the reported performance. This will allow readers to better verify the SOTA claim and evaluate the hybrid pipeline's contributions. revision: yes
-
Referee: [§4] §4 (Protocol-Aware Sequence DSL and LLM agents): The iterative coverage-closure loop assumes LLM agents can reliably analyze gap reports and compose additional DSL sequences without introducing errors or missing cases. The paper provides no failure-mode analysis, error rates for the LLM step, or fallback mechanisms when the rule-based generator plus LLM composition fails to reach the reported functional coverage.
Authors: This is a valid point regarding the robustness of the LLM agents. The original paper focuses on the overall success of the system but does not detail the internal performance of the iterative loop. We will add to Section 4 an analysis of failure modes observed during our experiments, such as cases where the LLM suggested incomplete sequences, along with approximate error rates derived from our experimental logs. Furthermore, we will describe the fallback mechanisms, including prompt engineering retries and reliance on the predefined DSL patterns when the LLM step does not improve coverage. These additions will provide a more complete picture of how the system maintains high functional coverage. revision: yes
Circularity Check
No circularity: applied system paper with empirical results only
full rationale
HAVEN is a hybrid engineering system paper whose central claims rest on the explicit construction of protocol-specific Jinja2 templates, a rule-based DSL generator, and LLM agents for coverage closure, followed by direct experimental measurement on 19 open-source designs. No equations, fitted parameters, predictions, or derivations appear anywhere in the provided text. The performance numbers (100% compilation success, 90.6% code coverage, 87.9% functional coverage) are reported as measured outcomes rather than derived quantities that reduce to prior results by construction. The novelty statement (“first system that utilizes pre-defined, protocol-specific Jinja2 templates”) is an empirical claim about the implemented pipeline, not a self-referential or self-citation-dependent theorem. No self-citation load-bearing steps, uniqueness theorems, or ansatz smuggling are present. The derivation chain is therefore self-contained through implementation description and external benchmark evaluation.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption LLMs are capable of producing accurate architectural plans from design specifications and analyzing coverage gap reports to generate targeted sequences.
- domain assumption Predefined protocol-specific templates can correctly implement all UVM components with proper bus-handshake timing for the supported protocols.
invented entities (2)
-
Protocol-Aware Sequence Domain-Specific Language (DSL)
no independent evidence
-
HAVEN Template Engine
no independent evidence
Reference graph
Works this paper leans on
-
[1]
2024 wilson research group ic/asic functional verification trend report,
H. Foster, “2024 wilson research group ic/asic functional verification trend report,”Siemens Digital Industries Software, 2025
2024
-
[2]
The 2022 wilson research group functional verification study,
H. Fosteret al., “The 2022 wilson research group functional verification study,”Siemens. com, 2022
2022
-
[3]
International technology roadmap for semicon- ductors,
S. I. Associationet al., “International technology roadmap for semicon- ductors,”http://www. itrs. net, 2009
2009
-
[4]
Llm4eda: Emerging progress in large language models for electronic design automation,
R. Zhong, X. Du, S. Kai, Z. Tang, S. Xu, H.-L. Zhen, J. Hao, Q. Xu, M. Yuan, and J. Yan, “Llm4eda: Emerging progress in large language models for electronic design automation,”arXiv preprint arXiv:2401.12224, 2023
-
[5]
A survey of research in large language models for electronic design automation,
J. Pan, G. Zhou, C.-C. Chang, I. Jacobson, J. Hu, and Y . Chen, “A survey of research in large language models for electronic design automation,” ACM Transactions on Design Automation of Electronic Systems, vol. 30, no. 3, pp. 1–21, 2025
2025
-
[6]
Meic: Re-thinking rtl debug automation using llms,
K. Xu, J. Sun, Y . Hu, X. Fang, W. Shan, X. Wang, and Z. Jiang, “Meic: Re-thinking rtl debug automation using llms,” inProceedings of the 43rd IEEE/ACM International Conference on Computer-Aided Design, 2024, pp. 1–9
2024
-
[7]
Uvllm: An automated universal rtl verification framework using llms,
Y . Hu, J. Ye, K. Xu, J. Sun, S. Zhang, X. Jiao, D. Pan, J. Zhou, N. Wang, W. Shanet al., “Uvllm: An automated universal rtl verification framework using llms,” in2025 62nd ACM/IEEE Design Automation Conference (DAC). IEEE, 2025, pp. 1–7
2025
-
[8]
Llm4dv: Using large language models for hardware test stimuli generation,
Z. Zhang, B. Szekely, P. Gimenes, G. Chadwick, H. McNally, J. Cheng, R. Mullins, and Y . Zhao, “Llm4dv: Using large language models for hardware test stimuli generation,” in2025 IEEE 33rd Annual Interna- tional Symposium on Field-Programmable Custom Computing Machines (FCCM). IEEE, 2025, pp. 133–137
2025
-
[9]
Verigen: A large language model for verilog code generation,
S. Thakur, B. Ahmad, H. Pearce, B. Tan, B. Dolan-Gavitt, R. Karri, and S. Garg, “Verigen: A large language model for verilog code generation,” ACM Transactions on Design Automation of Electronic Systems, vol. 29, no. 3, pp. 1–31, 2024
2024
-
[10]
Chipnemo: Domain-adapted llms for chip design,
M. Liu, T.-D. Ene, R. Kirby, C. Cheng, N. Pinckney, R. Liang, J. Alben, H. Anand, S. Banerjee, I. Bayraktarogluet al., “Chipnemo: Domain- adapted llms for chip design,”arXiv preprint arXiv:2311.00176, 2023
-
[11]
Christiaan Baaij, Matthijs Kooijman, Jan Kuper, Arjan Boeijink, and Marco Gerards
K. Chang, Y . Wang, H. Ren, M. Wang, S. Liang, Y . Han, H. Li, and X. Li, “Chipgpt: How far are we from natural language hardware design,”arXiv preprint arXiv:2305.14019, 2023
-
[12]
Assertllm: Generating hardware verification assertions from design specifications via multi-llms,
Z. Yan, W. Fang, M. Li, M. Li, S. Liu, Z. Xie, and H. Zhang, “Assertllm: Generating hardware verification assertions from design specifications via multi-llms,” inProceedings of the 30th Asia and South Pacific Design Automation Conference, 2025, pp. 614–621
2025
-
[13]
Revolution or hype? seeking the limits of large models in hardware design,
Q. Xu, L. Stok, R. Drechsler, X. Wang, G. L. Zhang, and I. L. Markov, “Revolution or hype? seeking the limits of large models in hardware design,” in2025 IEEE/ACM International Conference On Computer Aided Design (ICCAD). IEEE, 2025, pp. 1–9
2025
-
[14]
Understanding and mitigating errors of llm-generated rtl code,
J. Zhang, C. Liu, L. Cheng, X. Li, and H. Li, “Understanding and mitigating errors of llm-generated rtl code,”IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, 2026
2026
-
[15]
Llm hallucinations in practical code generation: Phenomena, mechanism, and mitigation,
Z. Zhang, C. Wang, Y . Wang, E. Shi, Y . Ma, W. Zhong, J. Chen, M. Mao, and Z. Zheng, “Llm hallucinations in practical code generation: Phenomena, mechanism, and mitigation,”Proceedings of the ACM on Software Engineering, vol. 2, no. ISSTA, pp. 481–503, 2025
2025
-
[16]
A comprehensive survey of hallucination mitigation techniques in large language models
S. Tonmoy, S. Zaman, V . Jain, A. Rani, V . Rawte, A. Chadha, and A. Das, “A comprehensive survey of hallucination mitigation techniques in large language models,”arXiv preprint arXiv:2401.01313, vol. 6, 2024
-
[17]
Autobench: Automatic testbench generation and evaluation using llms for hdl design,
R. Qiu, G. L. Zhang, R. Drechsler, U. Schlichtmann, and B. Li, “Autobench: Automatic testbench generation and evaluation using llms for hdl design,” inProceedings of the 2024 ACM/IEEE International Symposium on Machine Learning for CAD, 2024, pp. 1–10
2024
-
[18]
Correctbench: Automatic testbench generation with functional self-correction using llms for hdl design,
——, “Correctbench: Automatic testbench generation with functional self-correction using llms for hdl design,” in2025 Design, Automation & Test in Europe Conference (DATE). IEEE, 2025, pp. 1–7
2025
-
[19]
Confibench: Automatic testbench generation with confidence- based scenario mask and testbench ensemble using llms for hdl design,
R. Qiu, G. L. Zhang, R. Drechsler, T. Ho, U. Schlichtmann, and B. Li, “Confibench: Automatic testbench generation with confidence- based scenario mask and testbench ensemble using llms for hdl design,” ACM Transactions on Design Automation of Electronic Systems, 2025
2025
-
[20]
Rtlfixer: Automatically fixing rtl syntax errors with large language model,
Y . Tsai, M. Liu, and H. Ren, “Rtlfixer: Automatically fixing rtl syntax errors with large language model,” inProceedings of the 61st ACM/IEEE Design Automation Conference, 2024, pp. 1–6
2024
-
[21]
Hdldebugger: Streamlining hdl debugging with large lan- guage models,
X. Yao, H. Li, T. H. Chan, W. Xiao, M. Yuan, Y . Huang, L. Chen, and B. Yu, “Hdldebugger: Streamlining hdl debugging with large lan- guage models,”ACM Transactions on Design Automation of Electronic Systems, vol. 30, no. 6, pp. 1–26, 2025
2025
-
[22]
Ieee standard for universal verification method- ology language reference manual,
I. S. Associationet al., “Ieee standard for universal verification method- ology language reference manual,”IEEE Std, vol. 2020, pp. 1–458, 1800
2020
-
[23]
From Concept to Practice: an Automated LLM-aided UVM Machine for RTL Verification
J. Ye, Y . Hu, K. Xu, D. Pan, Q. Chen, J. Zhou, S. Zhao, X. Fang, X. Wang, N. Guanet al., “From concept to practice: an auto- mated llm-aided uvm machine for rtl verification,”arXiv preprint arXiv:2504.19959, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
Efficient stimuli generation using reinforcement learning in design veri- fication,
D. N. Gadde, T. Nalapat, A. Kumar, D. Lettnin, W. Kunz, and S. Simon, “Efficient stimuli generation using reinforcement learning in design veri- fication,” in2024 20th International Conference on Synthesis, Modeling, Analysis and Simulation Methods and Applications to Circuit Design (SMACD). IEEE, 2024, pp. 1–4
2024
-
[25]
Coverage directed test generation for functional verification using bayesian networks,
S. Fine and A. Ziv, “Coverage directed test generation for functional verification using bayesian networks,” inProceedings of the 40th annual Design Automation Conference, 2003, pp. 286–291
2003
-
[26]
Optimizing constrained random verification with ml and bayesian estimation,
B. Kumar, G. Parthasarathy, S. Nanda, and S. Rajakumar, “Optimizing constrained random verification with ml and bayesian estimation,” in 2023 ACM/IEEE 5th Workshop on Machine Learning for CAD (ML- CAD). IEEE, 2023, pp. 1–6
2023
-
[27]
Survey of machine learning for software-assisted hardware design verification: Past, present, and prospect,
N. Wu, Y . Li, H. Yang, H. Chen, S. Dai, C. Hao, C. Yu, and Y . Xie, “Survey of machine learning for software-assisted hardware design verification: Past, present, and prospect,”ACM Transactions on Design Automation of Electronic Systems, vol. 29, no. 4, pp. 1–42, 2024
2024
-
[28]
Coverage-directed test generation auto- mated by machine learning–a review,
C. Ioannides and K. I. Eder, “Coverage-directed test generation auto- mated by machine learning–a review,”ACM Transactions on Design Automation of Electronic Systems (TODAES), vol. 17, no. 1, pp. 1–21, 2012
2012
-
[29]
Grammar prompting for domain-specific language generation with large language models,
B. Wang, Z. Wang, X. Wang, Y . Cao, R. A Saurous, and Y . Kim, “Grammar prompting for domain-specific language generation with large language models,”Advances in Neural Information Processing Systems, vol. 36, pp. 65 030–65 055, 2023
2023
-
[30]
Generating structured outputs from language models: Benchmark and studies,
S. Geng, H. Cooper, M. Moskal, S. Jenkins, J. Berman, N. Ranchin, R. West, E. Horvitz, and H. Nori, “Generating structured outputs from language models: Benchmark and studies,”arXiv e-prints, pp. arXiv– 2501, 2025
2025
-
[31]
Coverage metrics for functional validation of hardware designs,
S. Tasiran and K. Keutzer, “Coverage metrics for functional validation of hardware designs,”IEEE Design & Test of Computers, vol. 18, no. 4, pp. 36–45, 2002
2002
-
[32]
Constraint-based random stimuli generation for hardware verification,
Y . Naveh, M. Rimon, I. Jaeger, Y . Katz, M. Vinov, E. s Marcu, and G. Shurek, “Constraint-based random stimuli generation for hardware verification,”AI magazine, vol. 28, no. 3, pp. 13–13, 2007
2007
-
[33]
Llm4cov: Execution-aware agentic learning for high-coverage testbench genera- tion,
H. Zhang, Z. Yu, C.-T. Ho, H. Ren, B. Khailany, and J. Zhao, “Llm4cov: Execution-aware agentic learning for high-coverage testbench genera- tion,”arXiv preprint arXiv:2602.16953, 2026
-
[34]
Tb or not tb: Coverage- driven direct preference optimization for verilog stimulus generation,
B. Nadimi, K. Filom, D. Chen, and H. Zheng, “Tb or not tb: Coverage- driven direct preference optimization for verilog stimulus generation,” arXiv preprint arXiv:2511.15767, 2025
-
[35]
P. Jin, D. Huang, C. Li, S. Cheng, Y . Zhao, X. Zheng, J. Zhu, S. Xing, B. Dou, R. Zhanget al., “Realbench: Benchmarking verilog generation models with real-world ip designs,”arXiv preprint arXiv:2507.16200, 2025
-
[36]
Fixme: Towards end-to-end bench- marking of llm-aided design verification,
G.-W. Wan, S. Wong, S. Su, C. Niu, N. Wang, X. Wan, Q. Chen, M. Xing, J. Zhang, J. Yeet al., “Fixme: Towards end-to-end bench- marking of llm-aided design verification,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 40, no. 2, 2026, pp. 1087– 1095
2026
-
[37]
Verilogeval: Evaluating large language models for verilog code generation,
M. Liu, N. Pinckney, B. Khailany, and H. Ren, “Verilogeval: Evaluating large language models for verilog code generation,” in2023 IEEE/ACM International Conference on Computer Aided Design (ICCAD). IEEE, 2023, pp. 1–8
2023
-
[38]
Rtllm: An open-source benchmark for design rtl generation with large language model,
Y . Lu, S. Liu, Q. Zhang, and Z. Xie, “Rtllm: An open-source benchmark for design rtl generation with large language model,” in2024 29th Asia and South Pacific Design Automation Conference (ASP-DAC). IEEE, 2024, pp. 722–727
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.