Recognition: unknown
Linguistically Informed Multimodal Fusion for Vietnamese Scene-Text Image Captioning: Dataset, Graph Framework, and Phonological Attention
Pith reviewed 2026-05-07 06:06 UTC · model grok-4.3
The pith
Cross-modal graph edges degrade scene-text fusion, so Vietnamese captioning needs phonological attention instead.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Vietnamese scene-text image captioning requires linguistically informed multimodal fusion. The Heterogeneous Scene-Text Fusion Graph (HSTFG) with learned spatial attention bias shows through topology analysis that cross-modal graph edges are harmful for fusion. Specializing this design yields the Phonological Scene-Text Fusion Graph (PhonoSTFG), which incorporates phonological attention to handle Vietnamese tonal and diacritic reasoning. The claim rests on the introduced ViTextCaps dataset, where 52.8 percent of the vocabulary risks meaning change from missing diacritics.
What carries the argument
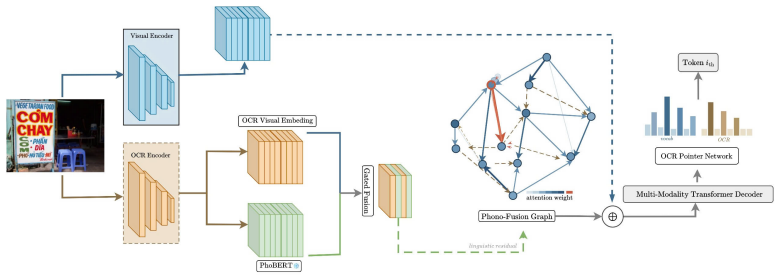
PhonoSTFG, the Phonological Scene-Text Fusion Graph that extends the general HSTFG framework by adding phonological attention to integrate linguistic knowledge and resolve tonal and diacritic ambiguities during Vietnamese scene-text captioning.
If this is right
- Graph fusion for scene-text images should omit direct cross-modal edges to avoid performance degradation.
- Phonological attention can mitigate diacritic collisions and tone ambiguities that standard fusion misses in tonal languages.
- The ViTextCaps dataset supplies a benchmark revealing that over half the vocabulary in Vietnamese scene-text captions is diacritic-sensitive.
- Learned spatial attention bias improves edge weighting within modality-specific subgraphs without needing cross-modal links.
Where Pith is reading between the lines
- The result on harmful cross-modal edges may prompt re-examination of graph fusion designs across other vision-language tasks that currently connect modalities densely.
- PhonoSTFG-style phonological attention could transfer to other tonal languages such as Thai or Mandarin where diacritics or tones similarly affect word identity.
- Stronger phonological modeling inside fusion might lessen the downstream damage caused by typical OCR mistakes on diacritic-rich text.
- The dataset statistics suggest future OCR systems for Vietnamese should prioritize diacritic preservation as a core accuracy metric.
Load-bearing premise
The topology finding that cross-modal edges are harmful will hold on other datasets and phonological attention will deliver measurable gains not offset by OCR errors or over-specialization to the ViTextCaps collection.
What would settle it
Repeating the topology analysis on a non-Vietnamese scene-text dataset where adding cross-modal edges raises BLEU or CIDEr scores, or showing that PhonoSTFG yields no improvement over HSTFG when supplied with ground-truth text rather than OCR output.
Figures







read the original abstract
Scene-text image captioning requires fusing three information streams -- visual features, OCR-detected text, and linguistic knowledge -- to generate descriptions that faithfully integrate text visible in images. Existing fusion approaches treat text as language-agnostic, which fails for Vietnamese: a tonal language where diacritics alter word meaning, OCR errors are pervasive, and word boundaries are ambiguous. We argue that Vietnamese scene-text captioning demands \textit{linguistically informed multimodal fusion}, where language-specific structural knowledge is explicitly incorporated into the fusion mechanism. Motivated from these insights, we propose \textbf{HSTFG} (Heterogeneous Scene-Text Fusion Graph), a general-purpose graph fusion framework with learned spatial attention bias, and show through topology analysis that cross-modal graph edges are harmful for scene-text fusion. Building on this finding, we design \textbf{PhonoSTFG} (Phonological Scene-Text Fusion Graph) which specializes graph-level fusion for Vietnamese linguistic reasoning. To support evaluation, we introduce \textbf{ViTextCaps}, the first large-scale Vietnamese scene-text captioning dataset (\textbf{15{,}729} images with \textbf{74{,}970} captions), with comprehensive linguistic analysis showing that 52.8\% of the vocabulary is at risk of diacritic collision.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces ViTextCaps, a new dataset of 15,729 Vietnamese scene-text images paired with 74,970 captions, along with linguistic analysis indicating that 52.8% of the vocabulary risks diacritic collision. It proposes the Heterogeneous Scene-Text Fusion Graph (HSTFG) as a general graph-based fusion framework incorporating learned spatial attention bias to combine visual features, OCR text, and linguistic knowledge. Topology analysis is used to conclude that cross-modal graph edges are harmful for scene-text fusion. This finding motivates the Phonological Scene-Text Fusion Graph (PhonoSTFG), which specializes the framework with phonological attention to address Vietnamese-specific issues such as tonal diacritics, OCR errors, and word-boundary ambiguity. The central claim is that linguistically informed multimodal fusion via phonological attention yields improved Vietnamese scene-text image captioning.
Significance. If the topology analysis and performance gains hold after addressing methodological controls, the work would provide a useful new benchmark dataset for non-English scene-text captioning and a graph fusion approach adapted to tonal languages. The emphasis on language-specific structural knowledge (phonology) and real-world OCR challenges in Vietnamese could inform similar adaptations for other low-resource or morphologically complex languages. The dataset scale and explicit linguistic analysis are positive contributions that could support future multilingual multimodal research.
major comments (1)
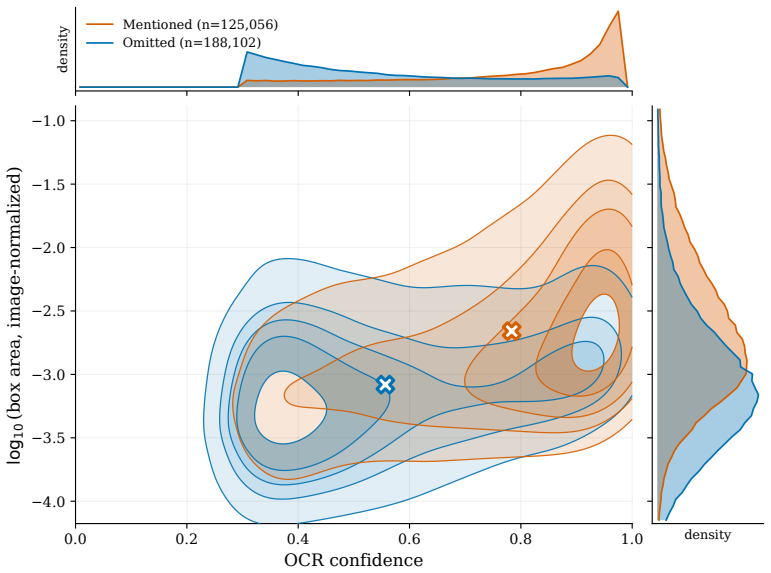
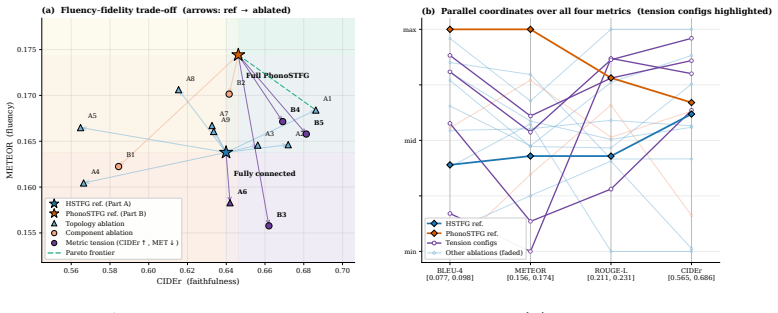
- [Topology Analysis] Topology Analysis section: the central claim that cross-modal graph edges are harmful (and thus motivate shifting from HSTFG to PhonoSTFG) rests on a comparison that removes those edges. Removing cross-modal edges necessarily reduces total edge count, average degree, and changes message-passing paths in the heterogeneous graph. No control experiment is described that holds edge count or connectivity fixed (e.g., by randomly pruning an equal number of intra-modal edges while preserving cross-modal ones, or by inserting neutral edges). Consequently, any performance change cannot be unambiguously attributed to the semantic harm of cross-modal fusion rather than generic sparsity or Laplacian effects. This is load-bearing for the argument that phonological attention is required as the remedy.
minor comments (3)
- [Abstract] Abstract: states that topology analysis shows cross-modal edges are harmful and that PhonoSTFG improves fusion, yet provides no quantitative results, baselines, error bars, ablation details, or specific metrics supporting these claims.
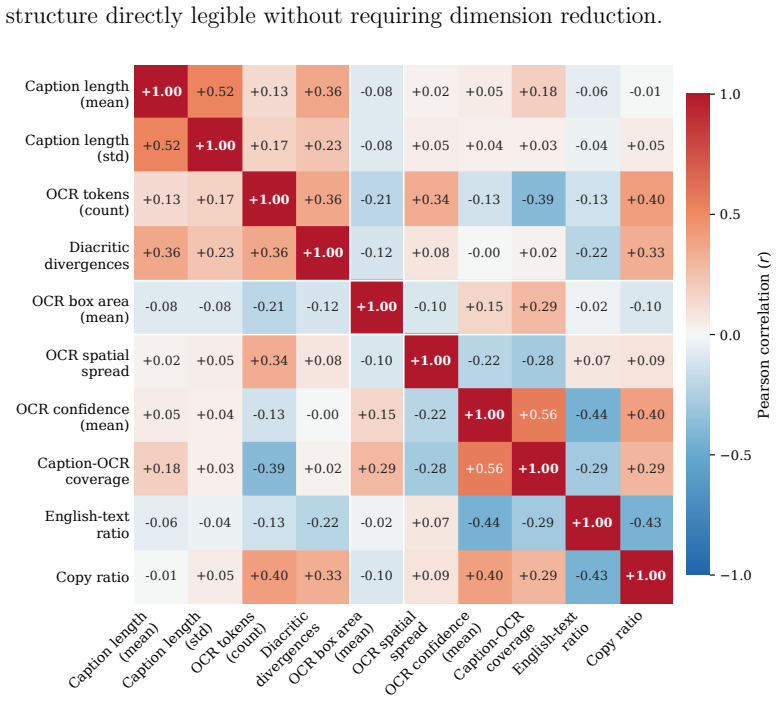
- [Dataset] Dataset section: the claim of 'comprehensive linguistic analysis' for the 52.8% diacritic-collision risk is presented without details on the computation method, vocabulary size, or how this statistic directly impacts captioning performance or OCR error rates.
- [Abstract] Notation and terminology: the acronyms HSTFG and PhonoSTFG are introduced in the abstract and title without immediate parenthetical expansion, which may reduce readability for readers unfamiliar with the framework.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed review. The methodological concern regarding the topology analysis is valid and directly impacts the strength of our central claim. We address it point-by-point below and will revise the manuscript to incorporate the suggested control.
read point-by-point responses
-
Referee: [Topology Analysis] Topology Analysis section: the central claim that cross-modal graph edges are harmful (and thus motivate shifting from HSTFG to PhonoSTFG) rests on a comparison that removes those edges. Removing cross-modal edges necessarily reduces total edge count, average degree, and changes message-passing paths in the heterogeneous graph. No control experiment is described that holds edge count or connectivity fixed (e.g., by randomly pruning an equal number of intra-modal edges while preserving cross-modal ones, or by inserting neutral edges). Consequently, any performance change cannot be unambiguously attributed to the semantic harm of cross-modal fusion rather than generic sparsity or Laplacian effects. This is load-bearing for the argument that phonological attention is required as the remedy.
Authors: We agree that the existing comparison does not hold total edge count or average degree fixed, and therefore cannot unambiguously attribute performance differences to the semantic content of the cross-modal edges rather than generic effects of graph sparsity or altered message-passing paths. In the revised manuscript we will add an explicit control experiment that randomly prunes an equal number of intra-modal edges while retaining all cross-modal edges, thereby matching the edge count of the no-cross-modal variant. We will report the resulting captioning metrics, update the topology analysis section with the new results, and discuss whether the performance drop remains larger when cross-modal edges are removed. This control will strengthen (or, if necessary, qualify) the motivation for introducing phonological attention in PhonoSTFG. revision: yes
Circularity Check
No circularity: empirical topology analysis and dataset introduction are independent of self-referential inputs
full rationale
The paper introduces a new dataset (ViTextCaps) and two graph frameworks (HSTFG, PhonoSTFG) whose central claims rest on empirical performance comparisons across graph topologies and linguistic properties of Vietnamese. The statement that cross-modal edges are harmful is presented as the outcome of topology analysis on trained models rather than any equation or fitted parameter that reduces the result to its own inputs by construction. No self-citation chains, ansatzes smuggled via prior work, or uniqueness theorems are invoked to force the phonological attention mechanism; the specialization is motivated directly by diacritic and tonal characteristics described in the linguistic analysis of the new data. The derivation chain therefore remains self-contained against external benchmarks such as standard captioning metrics.
Axiom & Free-Parameter Ledger
free parameters (1)
- learned spatial attention bias
axioms (2)
- domain assumption Graph neural networks with attention can effectively integrate visual, OCR, and linguistic streams for caption generation.
- domain assumption Phonological information is necessary and sufficient to mitigate diacritic collision and OCR errors in Vietnamese.
invented entities (2)
-
HSTFG
no independent evidence
-
PhonoSTFG
no independent evidence
Reference graph
Works this paper leans on
-
[1]
URLhttps://doi.org/10.1007/ 978-3-030-58536-5_44
O. Sidorov, R. Hu, M. Rohrbach, A. Singh, TextCaps: A dataset for image captioning with reading comprehension, in: Computer Vision – ECCV 2020, 2020, pp. 742–758. doi:10.1007/978-3-030-58536-5\_44
-
[2]
Z. Wang, J. Bao, W. Zhou, W. Zhu, J.-Y. Li, Confidence-aware non- repetitive multimodal transformers for TextCaps, in: Proceedings of the AAAI Conference on Artificial Intelligence, volume 35, 2021, pp. 2835–2843. doi:10.1609/aaai.v35i4.16389
-
[3]
R. Hu, A. Singh, T. Darrell, M. Rohrbach, Iterative answer predic- tion with pointer-augmented multimodal transformers for TextVQA, in: 2020 IEEE/CVF Conference on Computer Vision and Pattern Recog- nition (CVPR), 2020, pp. 9989–9999. doi:10.1109/CVPR42600.2020. 01001
-
[4]
J. Tang, Q. Liu, Y. Ye, J. Lu, S. Wei, A.-L. Wang, C. Lin, H. Feng, Z. Zhao, Y. Wang, Y. Liu, H. Liu, X. Bai, C. Huang, MTVQA: Bench- 48 marking multilingual text-centric visual question answering, in: Find- ings of the Association for Computational Linguistics: ACL 2025, 2025, pp. 7748–7763. doi:10.18653/v1/2025.findings-acl.404
-
[5]
Q. V. Nguyen, N. H. Nguyen, K. Van Nguyen, et al., ViTextVQA: A large-scale visual question answering dataset for evaluating Vietnamese text comprehension in images, Expert Systems with Applications 308 (2026) 130839. doi:10.1016/j.eswa.2025.130839
-
[6]
H. Q. Pham, T. K.-B. Nguyen, Q. Van Nguyen, D. Q. Tran, N. H. Nguyen, K. Van Nguyen, N. L.-T. Nguyen, ViOCR VQA: Novel bench- mark dataset and VisionReader for visual question answering by under- standing Vietnamese text in images, Multimedia Systems 31 (2025) 106. doi:10.1007/s00530-025-01696-7
- [7]
-
[8]
N. H. Tran, D. T. Duong, K. Nguyen, K. V. Phan, N. H. Tran, N. Nguyen, T. Nguyen, OpenViVQA: Task, dataset, and multimodal fusion models for visual question answering in Vietnamese, Inf. Fusion 100 (2023). doi:10.1016/j.inffus.2023.101868
-
[9]
Q. H. Lam, Q. D. Le, V. K. Nguyen, N. L.-T. Nguyen, UIT-ViIC: A dataset for the first evaluation on Vietnamese image captioning, in: Proc. Int. Conf. Comput. Collective Intell., 2020, pp. 730–742. doi:10. 1007/978-3-030-63007-2\_57
2020
- [10]
-
[11]
T. Baltruˇ saitis, C. Ahuja, L.-P. Morency, Multimodal machine learning: A survey and taxonomy, IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI) 41 (2019) 423–443. doi:10.1109/TPAMI. 2018.2798607
- [12]
-
[13]
P. K. Atrey, M. A. Hossain, A. El Saddik, M. S. Kankanhalli, Multi- modal fusion for multimedia analysis: a survey, Multimedia Syst. 16 (2010) 345–379. doi:10.1007/s00530-010-0182-0
-
[14]
D. Lahat, T. Adali, C. Jutten, Multimodal data fusion: An overview of methods, challenges, and prospects, Proceedings of the IEEE 103 (2015) 1449–1477. doi:10.1109/JPROC.2015.2460697
-
[15]
J. Ngiam, A. Khosla, M. Kim, J. Nam, H. Lee, A. Y. Ng, Multimodal deep learning, in: Proceedings of the 28th International Conference on International Conference on Machine Learning (ICML), 2011, pp. 689–696. doi:10.5555/3104482.3104569
-
[16]
C. G. M. Snoek, M. Worring, A. W. M. Smeulders, Early versus late fusion in semantic video analysis, in: Proceedings of the 13th An- nual ACM International Conference on Multimedia, 2005, pp. 399–402. doi:10.1145/1101149.1101236
-
[17]
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, I. Polosukhin, Attention is all you need, in: Proceedings of the 31st International Conference on Neural Information Processing Systems (NeurIPS), volume 30, 2017, pp. 6000—-6010. doi:10.5555/ 3295222.3295349
-
[18]
J. Lu, D. Batra, D. Parikh, S. Lee, ViLBERT: Pretraining task-agnostic visiolinguistic representations for vision-and-language tasks, in: Ad- vances in Neural Information Processing Systems (NeurIPS), volume 32, 2019
2019
-
[19]
H. Tan, M. Bansal, LXMERT: Learning cross-modality encoder repre- sentations from transformers, in: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th Inter- national Joint Conference on Natural Language Processing (EMNLP- IJCNLP), 2019, pp. 5100–5111. doi:10.18653/v1/D19-1514
-
[20]
Arevalo, T
J. Arevalo, T. Solorio, M. Montes-y Gómez, F. A. González, Gated multimodal units for information fusion, in: Proc. 5th Int. Conf. Learn. Represent. Workshop Track (ICLR Workshop), 2017. 50
2017
-
[21]
J. Yang, P. Wang, Y. Zhu, M. Feng, M. Chen, X. He, Gated multimodal fusion with contrastive learning for turn-taking prediction in multiparty conversation, in: ICASSP 2022 - 2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2022, pp. 7747–
2022
-
[22]
doi:10.1109/ICASSP43922.2022.9747056
-
[23]
D. Zhang, R. Cao, S. Wu, Information fusion in visual question answer- ing: A survey, Information Fusion 52 (2019) 268–280. doi:10.1016/j. inffus.2019.03.005
work page doi:10.1016/j 2019
-
[24]
A. Gandhi, K. Adhvaryu, S. Poria, E. Cambria, A. Hussain, Multimodal sentiment analysis: A systematic review of history, datasets, multimodal fusion methods, applications, challenges and future directions, Informa- tion Fusion 91 (2023) 424–444. doi:10.1016/j.inffus.2022.09.025
-
[25]
D. Gkoumas, Q. Li, C. Lioma, Y. Yu, D. Song, What makes the difference? An empirical comparison of fusion strategies for mul- timodal language analysis, Information Fusion 66 (2021) 184–197. doi:10.1016/j.inffus.2020.09.005
-
[26]
W. Zhang, J. Yu, H. Hu, H. Hu, Z. Qin, Multimodal feature fusion by re- lational reasoning and attention for visual question answering, Informa- tion Fusion 55 (2020) 116–126. doi:10.1016/j.inffus.2019.08.009
-
[27]
S. Zhang, M. Chen, J. Chen, F. Zou, Y. Li, P. Lu, Multimodal feature- wise co-attention method for visual question answering, Information Fusion 73 (2021) 1–10. doi:10.1016/j.inffus.2021.02.022
-
[28]
T. Yao, Y. Pan, Y. Li, T. Mei, Exploring visual relationship for image captioning, in: Computer Vision – ECCV 2018, 2018, pp. 711–727. doi:10.1007/978-3-030-01264-9_42
- [29]
-
[30]
D. Gao, K. Li, R. Wang, S. Shan, X. Chen, Multi-modal graph neural network for joint reasoning on vision and scene text, in: 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020, pp. 12743–12753. doi:10.1109/CVPR42600.2020.01276. 51
-
[31]
S. Yun, M. Jeong, R. Kim, J. Kang, H. J. Kim, Graph transformer networks, in: Advances in Neural Information Processing Systems, vol- ume 32, 2019
2019
-
[32]
W. Zhang, J. Yu, W. Zhao, C. Ran, DMRFNet: Deep multimodal reasoning and fusion for visual question answering and explanation gen- eration, Information Fusion 72 (2021) 70–79. doi:10.1016/j.inffus. 2021.02.006
-
[33]
Q. Li, Z. Han, X.-m. Wu, Deeper insights into graph convolutional net- works for semi-supervised learning, in: 32nd AAAI Conference on Arti- ficial Intelligence (AAAI), volume 32, 2018. doi:10.1609/aaai.v32i1. 11604
-
[34]
O. Vinyals, A. Toshev, S. Bengio, D. Erhan, Show and tell: A neural image caption generator, in: 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2015, pp. 3156–3164. doi:10.1109/ CVPR.2015.7298935
-
[35]
K. Xu, J. Ba, R. Kiros, K. Cho, A. Courville, R. Salakhudinov, R. Zemel, Y. Bengio, Show, attend and tell: Neural image caption generation with visual attention, in: Proceedings of the 32nd International Conference on Machine Learning, volume 37, PMLR, 2015, pp. 2048–2057
2015
-
[36]
P. Anderson, X. He, C. Buehler, D. Teney, M. Johnson, S. Gould, L. Zhang, Bottom-up and top-down attention for image caption- ing and visual question answering, in: 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2018, pp. 6077–6086. doi:10.1109/CVPR.2018.00636
-
[37]
J. Wang, J. Tang, J. Luo, Multimodal attention with image text spatial relationship for OCR-Based image captioning, in: Proceedings of the 28th ACM International Conference on Multimedia, 2020, pp. 4337–
2020
-
[38]
doi:10.1145/3394171.3413753
-
[39]
Z. Yang, Y. Lu, J. Wang, X. Yin, D. Florencio, L. Wang, C. Zhang, L. Zhang, J. Luo, TAP: Text-aware pre-training for text-vqa and text-caption, in: 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2021, pp. 8747–8757. doi:10.1109/ CVPR46437.2021.00864. 52
-
[40]
M. Cornia, M. Stefanini, L. Baraldi, R. Cucchiara, Meshed-memory transformer for image captioning, in: 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020, pp. 10575– 10584. doi:10.1109/CVPR42600.2020.01059
-
[42]
S. Li, C. Gong, Y. Zhu, C. Luo, Y. Hong, X. Lv, Context-aware multi- level question embedding fusion for visual question answering, Informa- tion Fusion 102 (2024) 102000. doi:10.1016/j.inffus.2023.102000
-
[43]
OpenAI, GPT-4o system card, arXiv preprint arXiv:2410.21276 (2024)
work page internal anchor Pith review arXiv 2024
-
[44]
D. Q. Nguyen, A. T. Nguyen, PhoBERT: Pre-trained language models for Vietnamese, in: Findings of the Association for Computational Lin- guistics: EMNLP 2020, 2020, pp. 1037–1042. doi:10.18653/v1/2020. findings-emnlp.92
-
[45]
L. Phan, H. Tran, H. Nguyen, T. H. Trinh, ViT5: Pretrained text-to- text transformer for Vietnamese language generation, in: Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies: Student Research Workshop (SR W), 2022, pp. 136–142. doi:10.18653/v1/2022. naacl-srw.18
-
[46]
T.-P. Le, T. L. C. Phan, N. H. Nguyen, K. Van Nguyen, LiGT: layout- infused generative transformer for visual question answering on Viet- namese receipts, Int. J. Doc. Anal. Recognit. (IJDAR) 28 (2025) 717–
2025
-
[47]
doi:10.1007/s10032-025-00515-z
-
[48]
X. Li, S. Dalmia, J. Li, M. Lee, P. Littell, J. Chang, A. W. Black, Universal phone recognition with a multilingual allophone system, in: ICASSP 2020 - 2020 IEEE International Conference on Acous- tics, Speech and Signal Processing (ICASSP), 2020, pp. 8249–8253. doi:10.1109/ICASSP40776.2020.9054362
-
[49]
R. E. Banchs, M. Zhang, X. Duan, H. Li, A. Kumaran, Report of NEWS 2015 machine transliteration shared task, in: Proc. 5th Named Entity 53 Workshop (NEWS), Association for Computational Linguistics, Beijing, China, 2015, pp. 10–23. doi:10.18653/v1/W15-3902
-
[50]
Enriching Word Vectors with Subword Information
P. Bojanowski, E. Grave, A. Joulin, T. Mikolov, Enriching word vectors with subword information, Transactions of the Association for Compu- tational Linguistics 5 (2017) 135–146. doi:10.1162/tacl_a_00051
-
[51]
H. Hu, J. Gu, Z. Zhang, J. Dai, Y. Wei, Relation networks for object detection, in: 2018 IEEE/CVF Conference on Computer Vision and Pat- tern Recognition, 2018, pp. 3588–3597. doi:10.1109/CVPR.2018.00378
-
[52]
C. Zhu, M. Chen, S. Zhang, C. Sun, H. Liang, Y. Liu, J. Chen, SKEAFN: Sentiment knowledge enhanced attention fusion network for multimodal sentiment analysis, Information Fusion 100 (2023). doi:10.1016/j.inffus.2023.101958
-
[53]
Huang, Y
M. Huang, Y. Liu, Z. Peng, C. Liu, D. Lin, S. Zhu, N. J. Yuan, K. Ding, L. Jin, SwinTextSpotter: Scene text spotting via better synergy between text detection and text recognition, in: 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022, pp. 4583–
2022
-
[54]
doi:10.1109/CVPR52688.2022.00455
-
[55]
P. Zhang, X. Li, X. Hu, J. Yang, L. Zhang, L. Wang, Y. Choi, J. Gao, Vinvl: Revisiting visual representations in vision-language models, in: 2021 IEEE/CVF Conference on Computer Vision and Pattern Recog- nition (CVPR), 2021, pp. 5579–5588. doi:10.1109/CVPR46437.2021. 00553
-
[56]
T. T. Đoàn, Ngữ âm tiếng Việt, Nhà xuất bản Đại học Quốc gia Hà Nội, 2007. URL:https://archive.org/details/nguamtiengviet
2007
-
[57]
L. C. Thompson, A Vietnamese grammar, University of Wash- ington Press, Seattle, 1965. URL:https://archive.org/details/ vietnamesegramma00thom
1965
-
[58]
K. Papineni, S. Roukos, T. Ward, W.-J. Zhu, Bleu: a method for automatic evaluation of machine translation, in: Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, 2002, pp. 311–318. doi:10.3115/1073083.1073135. 54
-
[59]
R. Vedantam, C. L. Zitnick, D. Parikh, CIDEr: Consensus-based image description evaluation, in: 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2015, pp. 4566–4575. doi:10.1109/ CVPR.2015.7299087
-
[60]
Lin, ROUGE: A package for automatic evaluation of summaries, in: Text Summarization Branches Out, Association for Computational Linguistics, Barcelona, Spain, 2004, pp
C.-Y. Lin, ROUGE: A package for automatic evaluation of summaries, in: Text Summarization Branches Out, Association for Computational Linguistics, Barcelona, Spain, 2004, pp. 74–81
2004
-
[61]
S. Banerjee, A. Lavie, METEOR: An automatic metric for MT evalua- tion with improved correlation with human judgments, in: Proceedings of the Second Workshop on Statistical Machine Translation, 2007, pp. 228—-231. doi:10.3115/1626355.1626389
-
[62]
In: Proceedings of the IEEE/CVF International Conference on Computer 16 J
L. Huang, W. Wang, J. Chen, X.-Y. Wei, Attention on attention for im- age captioning, in: 2019 IEEE/CVF International Conference on Com- puter Vision (ICCV), 2019, pp. 4633–4642. doi:10.1109/ICCV.2019. 00473
-
[63]
D. P. Kingma, J. Ba, Adam: A method for stochastic optimization, in: International Conference on Learning Representations (ICLR), Open- Review.net, 2015
2015
-
[64]
T.-Y. Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ramanan, P. Dollár, C. L. Zitnick, Microsoft COCO: Common objects in context, in: Computer Vision – ECCV 2014, 2014, pp. 740–755. doi:10.1007/ 978-3-319-10602-1\_48
2014
-
[65]
V. A. Vu, Underthesea: Vietnamese nlp toolkit, GitHub repository,
-
[66]
A vailable at: https://github.com/undertheseanlp/underthesea
-
[67]
ko”is retained rather than corrected to“không
V. Tran, Pyvi: Python vietnamese toolkit, GitHub repository, 2016. A vailable at: https://github.com/traitrandev/pyvi. 55 Appendix A. Dataset Construction Details Appendix A.1. Annotation Protocol Annotator Recruitment.The annotation process involved30 undergrad- uate studentsrecruited from Vietnam National University Ho Chi Minh City (VNU-HCM) and affili...
2016
-
[68]
color”, rank 1),có(“have
are domain-specific terms that appear far more frequently than in general Vietnamese text. •Descriptive vocabulary:màu(“color”, rank 1),có(“have”, rank 2), trên(“on”, rank 6) are common Vietnamese function and descriptive words used to situate text within the visual scene. The co-occurrence of these two groups reflects the dual nature of scene- text capti...
-
[69]
6 Unit: % N V E A CH M Nc R C FW Figure B.13: POS tag distribution of ViTextCaps reference captions (74,970 captions). Nouns dominate at 42.6%—substantially above typical image captioning datasets (∼30% in MSCOCO)—driven by OCR-extracted proper nouns, store names, and brand names. Underthesea [61]. Appendix B.8.1. Part-of-Speech Distribution Figure B.13 s...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.