Recognition: unknown
How Code Representation Shapes False-Positive Dynamics in Cross-Language LLM Vulnerability Detection
Pith reviewed 2026-05-07 05:53 UTC · model grok-4.3
The pith
Cross-language false positives in LLM vulnerability detection arise from the joint choice of code representation at training and inference time.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Cross-language FPR reflects the joint effect of training-time and inference-time representation, not either alone. Text fine-tuning drives FPR upward monotonically while F1 remains stable, masking the collapse. Surface-cue memorisation is the primary mechanism: text fine-tuning encodes C/C++-specific API names and syntactic idioms as vulnerability triggers that fire indiscriminately on target-language code. A cross-representation probe, applying text-trained weights to AST-encoded input without retraining, isolates this effect by dropping FPR from 0.866 to 0.583 on Java, with 37.2 percent of false positives reverting to true negatives. Direct AST fine-tuning does not preserve the benefit, as
What carries the argument
The cross-representation probe that applies weights from a text-fine-tuned model to AST-encoded inputs at inference time without retraining, thereby isolating the contribution of inference-time representation to false positive rates.
If this is right
- Text fine-tuning on C/C++ data causes cross-language FPR to rise monotonically with training intensity while F1 scores remain between 0.637 and 0.688.
- Applying AST input at inference to a text-trained model reduces FPR from 0.866 to 0.583 on Java and to 0.554 on Python.
- 37.2 percent of false positives revert to true negatives when AST input is used with text-trained weights.
- Direct fine-tuning on linearized AST representations produces FPR of at least 0.970 because the flattening step introduces new structural surface cues.
- A consistency gate that runs alerts through both text and AST paths filters false positives without retraining, at the cost of lower recall.
Where Pith is reading between the lines
- Representation format functions as a critical hyperparameter that should be varied explicitly when adapting LLMs to security tasks across languages.
- The dual-path consistency gate provides a practical, retraining-free safeguard that practitioners could add to existing vulnerability scanners.
- Analogous surface-cue memorization may appear in other cross-language code tasks such as bug localization or repair.
- Future benchmarks that explicitly control for code complexity would allow sharper tests of whether surface cues or other factors dominate.
Load-bearing premise
The observed false positive rate changes are caused by the model memorizing C/C++ surface cues during text fine-tuning rather than by unmeasured differences in code complexity, label distributions, or model capacity between the source and target benchmarks.
What would settle it
Re-running the text-to-AST probe on a new pair of benchmarks where C/C++ training samples and Java test samples are matched on complexity metrics, API usage frequency, and label balance; if the FPR reduction disappears, the surface-cue memorization account is falsified.
Figures




read the original abstract
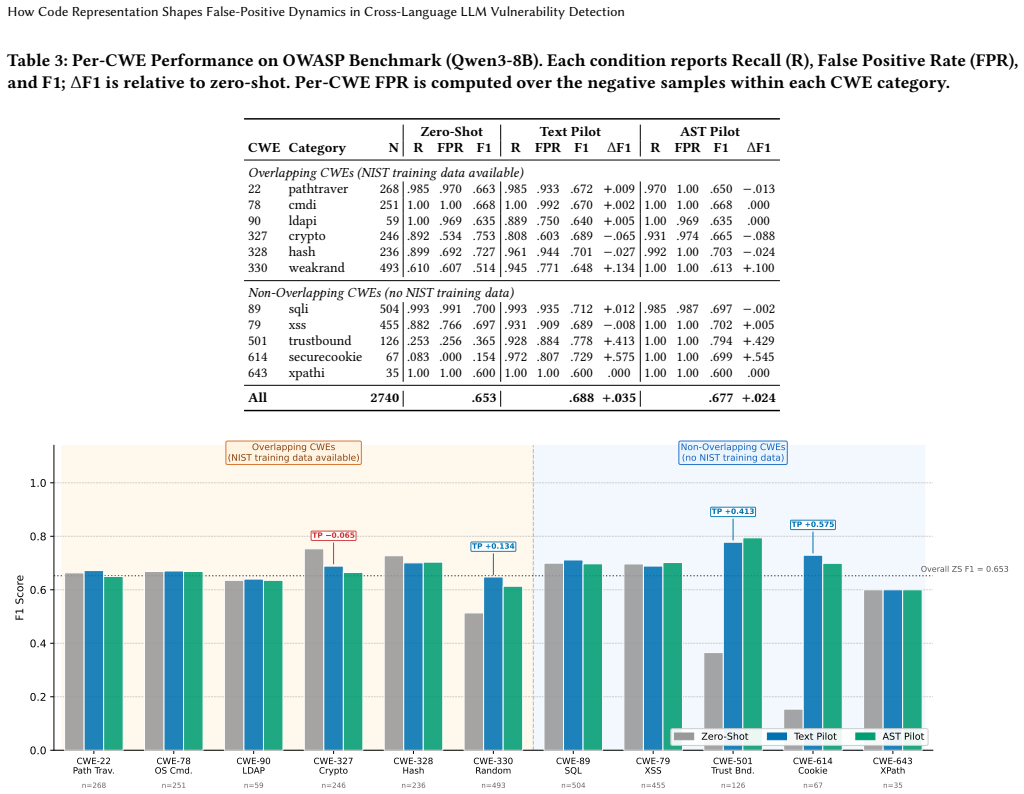
How code representation format shapes false positive behaviour in cross-language LLM vulnerability detection remains poorly understood. We systematically vary training intensity and code representation format, comparing raw source text with pruned Abstract Syntax Trees at both training time and inference time, across two 8B-parameter LLMs (Qwen3-8B and Llama 3.1-8B-Instruct) fine-tuned on C/C++ data from the NIST Juliet Test Suite (v1.3) and evaluated on Java (OWASP Benchmark v1.2) and Python (BenchmarkPython v0.1). Cross-language FPR reflects the joint effect of training-time and inference-time representation, not either alone. Text fine-tuning drives FPR upward monotonically (Qwen3-8B: 0.763 zero-shot, 0.866 pilot, 1.000 full-scale) while F1 remains stable (0.637-0.688), masking the collapse. We argue surface-cue memorisation is the primary mechanism: text fine-tuning encodes C/C++-specific API names and syntactic idioms as vulnerability triggers that fire indiscriminately on target-language code. A cross-representation probe, applying text-trained weights to AST-encoded input without retraining, isolates this: Qwen3-8B FPR drops from 0.866 to 0.583, and 37.2% of false positives revert to true negatives under AST input alone. Direct AST fine-tuning does not preserve the benefit (FPR at least 0.970), as flat linearisation introduces structural surface cues of its own. The pattern replicates across both model families. On BenchmarkPython the AST probe yields FPR=0.554, within 2.9 percentage points of the Java result, despite maximal surface-syntax differences, substantially weakening a domain-shift explanation. These findings motivate a pre-deployment consistency gate, running alerts through both text and AST paths, as a retraining-free filter for false-positive-sensitive settings, at the cost of reduced recall.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that false-positive rates (FPR) in cross-language LLM vulnerability detection arise from the joint effect of training-time and inference-time code representations rather than either factor alone. Text fine-tuning on C/C++ data (NIST Juliet) monotonically increases FPR on Java (OWASP) and Python targets (e.g., Qwen3-8B: 0.763 zero-shot to 1.000 full fine-tune) while F1 remains roughly stable (0.637–0.688), which the authors attribute to surface-cue memorization of C/C++-specific APIs and idioms. A cross-representation probe applies text-trained weights to AST-linearized inputs without retraining, reducing FPR (Qwen3-8B: 0.866 → 0.583) and reverting 37.2% of false positives to true negatives; direct AST fine-tuning yields FPR ≥ 0.970. The pattern holds across Qwen3-8B and Llama 3.1-8B, and the AST probe on Python yields FPR=0.554. The authors propose a consistency gate that runs both text and AST paths as a retraining-free filter.
Significance. If the mechanistic interpretation is confirmed, the work supplies concrete empirical evidence that representation choice at training and inference jointly drives spurious cross-language transfer in security tasks, together with a simple, deployable mitigation. The systematic ablation across training regimes, two 8B models, and two target languages (with maximal syntactic divergence on Python) is a useful contribution to the literature on LLM-based vulnerability detection. The probe result and the consistency-gate proposal are practically relevant for false-positive-sensitive settings.
major comments (1)
- [cross-representation probe experiment] The cross-representation probe (abstract and results) reports an FPR reduction (Qwen3-8B: 0.866 → 0.583) and that 37.2% of false positives revert to true negatives when text-trained weights are applied to AST inputs, but does not report recall, true-positive rate, or F1 for the probe condition. Without these metrics it is impossible to distinguish selective removal of C/C++ surface cues from a general negative bias induced by out-of-distribution AST linearization. This distinction is load-bearing for the claim that surface-cue memorization is the primary mechanism, for the contrast with direct AST fine-tuning, and for the proposed consistency gate.
minor comments (2)
- [results and evaluation] No error bars, confidence intervals, or statistical significance tests accompany the reported FPR and F1 values across training intensities and representation choices.
- [methodology and evaluation setup] The manuscript does not detail how false positives were labeled or verified on the target benchmarks (OWASP Benchmark v1.2 and BenchmarkPython v0.1), which is especially relevant in a cross-language setting where ground-truth definitions may differ.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive review. The major comment identifies a genuine gap in our reporting of the cross-representation probe. We address it below and will incorporate the requested metrics in the revised manuscript.
read point-by-point responses
-
Referee: The cross-representation probe (abstract and results) reports an FPR reduction (Qwen3-8B: 0.866 → 0.583) and that 37.2% of false positives revert to true negatives when text-trained weights are applied to AST inputs, but does not report recall, true-positive rate, or F1 for the probe condition. Without these metrics it is impossible to distinguish selective removal of C/C++ surface cues from a general negative bias induced by out-of-distribution AST linearization. This distinction is load-bearing for the claim that surface-cue memorization is the primary mechanism, for the contrast with direct AST fine-tuning, and for the proposed consistency gate.
Authors: We agree that recall, true-positive rate, and F1 must be reported for the probe condition to allow readers to rule out a general negative bias. The 37.2% reversion figure already suggests the effect is selective rather than a uniform shift toward negatives, but the referee is correct that this is insufficient on its own. In the revised manuscript we will add recall, TPR, and F1 for the cross-representation probe on both Java and Python targets. We will also report the same three metrics for the direct AST fine-tuning condition so that the contrast is complete. These additions will be placed in the main results table and discussed in the text. We believe the new numbers will reinforce rather than undermine the surface-cue memorization interpretation, but we will let the data speak. revision: yes
Circularity Check
Empirical ablation study with no circular derivations or self-referential predictions
full rationale
The paper conducts an empirical ablation study that varies training and inference representations (raw text vs. pruned AST) on fixed external benchmarks (NIST Juliet for C/C++ fine-tuning, OWASP Java and BenchmarkPython for cross-language evaluation). All reported quantities—FPR values (e.g., 0.763 zero-shot to 1.000 full-scale for text fine-tuning; 0.866 to 0.583 for the cross-representation probe), F1 scores, and the 37.2% reversion rate—are direct measurements on held-out data rather than quantities derived from equations or fitted parameters inside the paper. No mathematical derivations, uniqueness theorems, or self-citations are invoked to justify core claims; the surface-cue memorization interpretation is presented as a post-hoc reading of the probe results, not a prediction that reduces to the inputs by construction. The study is therefore self-contained against external benchmarks with no load-bearing steps that loop back to the paper's own definitions or fits.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption NIST Juliet, OWASP Benchmark, and BenchmarkPython provide representative vulnerability labels for C/C++, Java, and Python respectively.
Reference graph
Works this paper leans on
-
[1]
Tim Boland and Paul E. Black. 2012. The Juliet 1.1 C/C++ and Java Test Suite. Computer45, 10 (2012), 83–90. doi:10.1109/MC.2012.345
-
[2]
Saikat Chakraborty, Rahul Krishna, Yangruibo Ding, and Baishakhi Ray. 2022. Deep Learning Based Vulnerability Detection: Are We There Yet?IEEE Trans- actions on Software Engineering48, 9 (2022), 3280–3296. doi:10.1109/TSE.2021. 3087402
-
[3]
Yizheng Chen, Zhoujie Ding, Lamya Alowain, Xinyun Chen, and David Wagner
-
[4]
InProceedings of the 26th International Symposium on Research in Attacks, Intrusions and Defenses
DiverseVul: A New Vulnerable Source Code Dataset for Deep Learning Based Vulnerability Detection. InProceedings of the 26th International Symposium on Research in Attacks, Intrusions and Defenses. 654–668. doi:10.1145/3607199. 3607242
-
[5]
Qianjin Du, Shiji Zhou, Xiaohui Kuang, Gang Zhao, and Jidong Zhai. 2023. Joint Geometrical and Statistical Domain Adaptation for Cross-domain Code Vulnera- bility Detection. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 12791–12800. doi:10.18653/v1/2023.emnlp-main.788
-
[6]
Zhangyin Feng, Daya Guo, Duyu Tang, Nan Duan, Xiaochuan Feng, Ming Gong, Linjun Shou, Bing Qin, Ting Liu, Daxin Jiang, and Ming Zhou. 2020. CodeBERT: A Pre-Trained Model for Programming and Natural Language. InFindings of the Association for Computational Linguistics: EMNLP 2020. 1536–1547. doi:10.18653/ v1/2020.findings-emnlp.139
2020
-
[7]
Michael Fu and Chakkrit Tantithamthavorn. 2022. LineVul: A Transformer- based Line-Level Vulnerability Prediction. InProceedings of the 19th International Conference on Mining Software Repositories. 608–620. doi:10.1145/3524842.3528452
-
[8]
Zeyu Gao, Hao Wang, Yuchen Zhou, Yuandong Ni, and Chao Zhang. 2024. How Far Have We Gone in Vulnerability Detection Using Large Language Models. arXiv preprint arXiv:2311.12420(2024). arXiv:2311.12420 doi:10.48550/arXiv.2311. 12420
-
[9]
Robert Geirhos, Jörn-Henrik Jacobsen, Claudio Michaelis, Richard Zemel, Matthias Bethge, Bernhard Schölkopf, and Felix A Wichmann. 2020. Short- cut Learning in Deep Neural Networks.Nature Machine Intelligence2, 11 (2020), 665–673. doi:10.1038/s42256-020-00257-z
-
[10]
Daya Guo, Shuai Lu, Nan Duan, Yanlin Wang, Ming Zhou, and Jian Yin. 2022. UniXcoder: Unified Cross-Modal Pre-training for Code Representation. InPro- ceedings of the 60th Annual Meeting of the Association for Computational Linguis- tics. 7212–7225. doi:10.18653/v1/2022.acl-long.499
-
[11]
Jacob A. Harer, Louis Y. Kim, Rebecca L. Russell, Onur Ozdemir, Leonard R. Kosta, Akshay Rangamani, Lei H. Hamilton, Gabriel I. Centeno, Jonathan R. Key, Paul M. Ellingwood, Marc W. McConley, Jeffrey M. Mattson, Andy Long, Chris Enck, Steven Miley, and Tomo Lazovich. 2018. Automated Software Vulnera- bility Detection with Machine Learning.arXiv preprint a...
-
[12]
Xuefeng Jiang, Lvhua Wu, Sheng Sun, Jia Li, Jingjing Xue, Yuwei Wang, Tingt- ing Wu, and Min Liu. 2024. Investigating Large Language Models for Code Vulnerability Detection: An Experimental Study. doi:10.48550/arXiv.2412.18260
-
[13]
Zhiming Li, Yanzhou Li, Tianlin Li, Mengnan Du, Bozhi Wu, Yushi Cao, Junzhe Jiang, and Yang Liu. 2024. Unveiling Project-Specific Bias in Neural Code Models. InProceedings of the 2024 Joint International Conference on Computational Lin- guistics, Language Resources and Evaluation (LREC-COLING 2024). 17205–17216. doi:10.18653/v1/2024.lrec-main.1494
- [14]
-
[15]
Yu Liu, Lang Gao, Mingxin Yang, Yu Xie, Ping Chen, Xiaojin Zhang, and Wei Chen. 2024. VulDetectBench: Evaluating the Deep Capability of Vulnerability Detection with Large Language Models.arXiv preprint arXiv:2406.07595(2024). arXiv:2406.07595 doi:10.48550/arXiv.2406.07595
-
[16]
Yisroel Mirsky, George Macon, Michael Brown, Carter Yagemann, Matthew Pruett, Evan Downing, Sukarno Mertoguno, and Wenke Lee. 2023. VulChecker: Graph-based Vulnerability Localization in Source Code. In32nd USENIX Security Symposium. 2041–2058. doi:10.5555/3620237.3620604
- [17]
-
[18]
Georgios Nikitopoulos, Konstantina Dritsa, Panos Louridas, and Dimitris Mitropoulos. 2021. CrossVul: A Cross-Language Vulnerability Dataset with Commit Data. InProceedings of the 29th ACM Joint Meeting on European Soft- ware Engineering Conference and Symposium on the Foundations of Software Engineering. 1565–1569. doi:10.1145/3468264.3473122
-
[19]
Dave Wichers and Dave Maher. 2015. OWASP Benchmark Project. https: //owasp.org/www-project-benchmark/
2015
-
[20]
Yaqin Zhou, Shangqing Liu, Jingkai Siow, Xiaoning Du, and Yang Liu. 2019. Devign: Effective Vulnerability Identification by Learning Comprehensive Pro- gram Semantics via Graph Neural Networks. InAdvances in Neural Information Processing Systems, Vol. 32. doi:10.5555/3454287.3455202
-
[21]
Botong Zhu and Huobin Tan. 2023. VuLASTE: Long Sequence Model with Abstract Syntax Tree Embedding for Vulnerability Detection. InAAIA 2023 – International Conference on Advances in Artificial Intelligence and Applications. 392–396. doi:10.1145/3603273.3635667
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.