Recognition: unknown
Why Self-Supervised Encoders Want to Be Normal
Pith reviewed 2026-05-07 05:27 UTC · model grok-4.3
The pith
Self-supervised encoders prefer normal distributions because this satisfies the information bottleneck principle.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
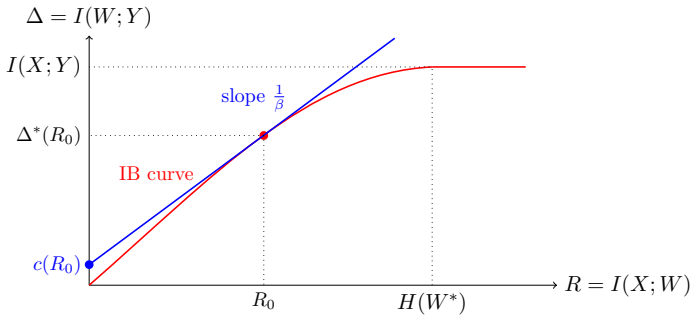
By recasting the Information Bottleneck objective as a rate-distortion problem over the predictive manifold, optimal target-neutral latent representations tend toward isotropic Gaussian states. These representations correspond to soft clustering of inputs that share similar predictive distributions, organized within a natural simplex structure. The framework unifies supervised and less-supervised objectives, supplies a principled account of common regularization schemes, and yields practical loss functions that approximate the desired structure while preventing collapse.
What carries the argument
The recasting of the Information Bottleneck as a rate-distortion problem over the predictive manifold, which forces target-neutral latents into isotropic Gaussian states organized as soft clusters in a simplex.
If this is right
- Latent representations function as soft clusters grouped by shared predictive distributions inside a simplex.
- The same principle unifies supervised, self-supervised, and joint-embedding objectives under one geometric account.
- Common regularization terms are justified as approximations that keep representations close to the optimal Gaussian states.
- Derived loss functions that enforce the simplex structure improve stability and prevent collapse on standard benchmarks.
Where Pith is reading between the lines
- Architectures could be designed to operate directly on the predictive manifold rather than on raw latents, potentially improving sample efficiency.
- The simplex view suggests that the effective dimensionality of useful representations is bounded by the number of distinct predictive behaviors in the data.
- Rate-distortion tools from classical compression could be imported to derive new regularization schedules that explicitly control entropy.
- Forcing a non-Gaussian prior in small-scale experiments would provide a direct test of whether performance drops exactly when the bottleneck constraint is violated.
Load-bearing premise
The information bottleneck, once rewritten as rate-distortion on the predictive manifold, must produce isotropic Gaussians for optimal target-neutral representations regardless of encoder architecture details.
What would settle it
A self-supervised encoder trained with an added constraint that forces non-Gaussian latents and still matches or exceeds standard performance on downstream tasks while preserving high mutual information with the input would contradict the necessity of the Gaussian preference.
Figures













read the original abstract
Self-supervised learning has achieved remarkable empirical success in learning robust representations without explicit labels, most recently demonstrated within the framework of Joint-Embedding Predictive Architectures (JEPA). However, a fundamental question remains: what analytical principles drive these encoders toward specific distributional states? In this paper, we demonstrate that the preference for normal distributions in self-supervised encoders is a direct consequence of the Information Bottleneck (IB) principle. By recasting the IB objective as a rate-distortion problem over the predictive manifold, we provide a theoretical basis for why optimal, target-neutral, latent representations should tend towards isotropic Gaussian states. Under this framework, we show that latent representations correspond to soft clustering of inputs sharing similar predictive distributions, organized within a natural simplex structure. This perspective unifies a wide range of existing supervised and less-supervised objectives and provides a principled explanation for commonly used regularization schemes. Furthermore, we derive practical loss objectives that approximate this structure and demonstrate their effectiveness on standard benchmarks. Ultimately, our framework offers a geometric lens to understanding representation collapse and it establishes a mathematical system for regularization strategies to be used to ensure high-entropy, informative embeddings in modern self-supervised models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that the preference for isotropic Gaussian latent representations in self-supervised encoders (particularly JEPA-style models) is a direct consequence of the Information Bottleneck (IB) principle. By recasting the IB objective as a rate-distortion optimization problem over the manifold of predictive distributions, the authors argue that optimal target-neutral latents minimize to isotropic Gaussians. They interpret these latents as soft clustering of inputs with similar predictive behavior, naturally organized on a simplex structure. This framework unifies a range of supervised and self-supervised objectives, explains common regularization schemes, derives practical approximating losses, demonstrates their effectiveness on standard benchmarks, and offers a geometric perspective on representation collapse.
Significance. If the rate-distortion recasting is shown to be robust, the work supplies a principled information-theoretic explanation for the Gaussian bias observed in modern SSL and a geometric account of collapse, which could inform regularization design for high-entropy embeddings. The unification of objectives and derivation of practical losses are concrete strengths that could influence practice. The significance is reduced, however, by the absence of a demonstration that the Gaussian outcome is independent of the chosen manifold metric and distortion function; prior IB applications in representation learning have not uniformly produced the same conclusion, so the result risks being parameterization-specific rather than a universal consequence of IB.
major comments (2)
- [§3] §3 (Rate-Distortion Recasting of IB): the claim that isotropic Gaussians are the preferred states for target-neutral latents rests on an implicit Euclidean geometry of the predictive manifold together with quadratic distortion and differential entropy as the rate; the manuscript provides no proof or sensitivity analysis showing that the minimizer remains Gaussian when the distortion is replaced by, e.g., KL divergence or Wasserstein distance on the manifold. This assumption is load-bearing for the central assertion that the Gaussian preference is a 'direct consequence' of IB rather than an artifact of the chosen parameterization.
- [§4] §4 (Simplex Structure and Soft Clustering): the asserted 'natural simplex structure' for organizing soft clusters of predictive distributions is in tension with the unbounded support of isotropic Gaussians; the paper does not specify the embedding or high-dimensional limit that reconciles a fixed-support simplex geometry with Gaussian distributions, nor does it show that the Gaussian remains optimal once this embedding is made explicit. Without this clarification the derivation risks circularity with the chosen representation of the predictive manifold.
minor comments (2)
- [Abstract] The term 'target-neutral' is introduced in the abstract without definition; a one-sentence clarification in the introduction or §2 would improve accessibility.
- [§4] The unification of existing objectives (contrastive, predictive, etc.) is asserted but not accompanied by an explicit mapping table or equation-by-equation comparison; adding such a table in §4 would strengthen the unification claim without altering the central argument.
Simulated Author's Rebuttal
We appreciate the referee's detailed feedback, which highlights important aspects of our rate-distortion formulation and geometric interpretation. We respond to each major comment below and will incorporate revisions to strengthen the manuscript's clarity and address the concerns about parameterization dependence.
read point-by-point responses
-
Referee: [§3] §3 (Rate-Distortion Recasting of IB): the claim that isotropic Gaussians are the preferred states for target-neutral latents rests on an implicit Euclidean geometry of the predictive manifold together with quadratic distortion and differential entropy as the rate; the manuscript provides no proof or sensitivity analysis showing that the minimizer remains Gaussian when the distortion is replaced by, e.g., KL divergence or Wasserstein distance on the manifold. This assumption is load-bearing for the central assertion that the Gaussian preference is a 'direct consequence' of IB rather than an artifact of the chosen parameterization.
Authors: We thank the referee for pointing out this important qualification. The recasting in §3 indeed employs the standard quadratic distortion measure, which, together with differential entropy, yields the well-known Gaussian rate-distortion function. This choice aligns with the L2-based predictive losses commonly used in JEPA-style models. We acknowledge that the manuscript does not include a sensitivity analysis for alternative distortions such as KL or Wasserstein. In the revision, we will add a new subsection discussing the role of the distortion function, explicitly stating that the isotropic Gaussian solution is derived under quadratic distortion, and noting that other metrics may lead to different optimal distributions (e.g., Laplace for L1). We will also clarify that our claim of a 'direct consequence' is within the context of this standard rate-distortion setup for continuous latent spaces. This revision will make the assumptions transparent and mitigate the risk of the result appearing parameterization-specific. revision: yes
-
Referee: [§4] §4 (Simplex Structure and Soft Clustering): the asserted 'natural simplex structure' for organizing soft clusters of predictive distributions is in tension with the unbounded support of isotropic Gaussians; the paper does not specify the embedding or high-dimensional limit that reconciles a fixed-support simplex geometry with Gaussian distributions, nor does it show that the Gaussian remains optimal once this embedding is made explicit. Without this clarification the derivation risks circularity with the chosen representation of the predictive manifold.
Authors: We agree that the relationship between the simplex geometry of the predictive distributions and the Gaussian latents requires clearer exposition to avoid any appearance of circularity. The simplex structure refers to the convex combinations in the space of predictive distributions (i.e., the probability simplex over possible future states or targets), while the latent representations are modeled as isotropic Gaussians in the embedding space. The embedding is such that each Gaussian corresponds to a soft cluster center in the predictive manifold, with the means of the Gaussians lying within the convex hull (simplex) of the predictive modes. In high dimensions, the variance of the Gaussians allows for the unbounded support while the effective clustering is determined by the means. We will revise §4 to include an explicit description of this embedding, perhaps with a diagram or formal definition of how the Gaussian parameters map to points on the predictive simplex. Additionally, we will show that the optimality of the Gaussian form holds as long as the rate is measured by differential entropy and distortion by quadratic distance in the latent space, independent of the specific simplex embedding. This should resolve the tension and strengthen the geometric perspective. revision: yes
- A general demonstration that the isotropic Gaussian minimizer is independent of the manifold metric and distortion function (e.g., for KL divergence or Wasserstein distance) is not provided in the current manuscript and would require additional theoretical development.
Circularity Check
No significant circularity; central claim builds on standard external IB principle without self-referential reduction or fitted inputs renamed as predictions.
full rationale
The abstract presents the Gaussian preference as a consequence of recasting the Information Bottleneck (a pre-existing principle from Tishby et al.) as a rate-distortion problem on the predictive manifold. No equations are supplied in the visible text that define the manifold or distortion measure in terms of the target Gaussian outcome, nor is there a self-citation to a uniqueness theorem authored by the same writer that would force the result. The simplex structure for soft clustering is described as a derived perspective rather than an input assumption. Because the derivation chain relies on an independent, externally established objective (IB) and does not exhibit any of the enumerated circular patterns (self-definition, fitted-input prediction, load-bearing self-citation, etc.) in the provided material, the paper remains self-contained against external benchmarks. Full equations would be needed to confirm the manifold metric is not chosen to guarantee isotropy, but nothing in the given text triggers a circularity flag.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The Information Bottleneck objective can be recast as a rate-distortion problem over the predictive manifold
Reference graph
Works this paper leans on
-
[1]
A scale-dependent notion of effective dimension.arXiv preprint arXiv:2001.10872, 2020
Aqeel Abbas and Marcus Hutter. A scale-dependent notion of effective dimension.arXiv preprint arXiv:2001.10872, 2020
-
[2]
Emergence of invariance and disentanglement in deep representations.Journal of Machine Learning Research, 19(50):1–34, 2018
Alessandro Achille and Stefano Soatto. Emergence of invariance and disentanglement in deep representations.Journal of Machine Learning Research, 19(50):1–34, 2018. 26
2018
-
[3]
Deep variational information bottleneck
Alexander A Alemi, Ian Fischer, Joshua V Dillon, and Kevin Murphy. Deep variational information bottleneck. InInternational Conference on Learning Representations, 2017
2017
-
[4]
Springer, 2016
Shun-ichi Amari.Information Geometry and Its Applications. Springer, 2016
2016
-
[5]
An algorithm for computing the capacity of arbitrary discrete memoryless channels.IEEE Transactions on Information Theory, 18(1):14–20, 1972
Suguru Arimoto. An algorithm for computing the capacity of arbitrary discrete memoryless channels.IEEE Transactions on Information Theory, 18(1):14–20, 1972
1972
-
[6]
Lejepa: Provable and scalable self-supervised learning without the heuristics, 2025
Randall Balestriero and Yann LeCun. LeJEPA: Provable and scalable self-supervised learning without the heuristics.arXiv preprint arXiv:2511.08544, 2025
-
[7]
Prentice- Hall, 1971
Toby Berger.Rate Distortion Theory: A Mathematical Basis for Data Compression. Prentice- Hall, 1971
1971
-
[8]
Wiley, 3 edition, 1995
Patrick Billingsley.Probability and Measure. Wiley, 3 edition, 1995
1995
-
[9]
Bishop.Pattern Recognition and Machine Learning
Christopher M. Bishop.Pattern Recognition and Machine Learning. Springer, 2006
2006
-
[10]
Computation of channel capacity and rate-distortion functions.IEEE Trans- actions on Information Theory, 18(4):460–473, 1972
Richard Blahut. Computation of channel capacity and rate-distortion functions.IEEE Trans- actions on Information Theory, 18(4):460–473, 1972
1972
-
[11]
Combining labeled and unlabeled data with co-training
Avrim Blum and Tom Mitchell. Combining labeled and unlabeled data with co-training. InProceedings of the Eleventh Annual Conference on Computational Learning Theory, pages 92–100. ACM, 1998
1998
-
[12]
Emerging properties in self-supervised vision transformers
Mathilde Caron, Hugo Touvron, Ishan Misra, Herv´ e J´ egou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emerging properties in self-supervised vision transformers. InInterna- tional Conference on Computer Vision, pages 9650–9660, 2021
2021
-
[13]
Information bottleneck for Gaussian variables.Journal of Machine Learning Research, 6:165–188, 2005
Gal Chechik, Amir Globerson, Naftali Tishby, and Yair Weiss. Information bottleneck for Gaussian variables.Journal of Machine Learning Research, 6:165–188, 2005
2005
-
[14]
A simple framework for contrastive learning of visual representations
Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey Hinton. A simple framework for contrastive learning of visual representations. InInternational Conference on Machine Learning, pages 1597–1607, 2020
2020
-
[15]
Wiley-Interscience, 2nd edition, 2006
Thomas M Cover and Joy A Thomas.Elements of Information Theory. Wiley-Interscience, 2nd edition, 2006
2006
-
[16]
A test for normality based on the empirical charac- teristic function.Biometrika, 70(3):723–726, 1983
Thomas W Epps and Lawrence B Pulley. A test for normality based on the empirical charac- teristic function.Biometrika, 70(3):723–726, 1983
1983
-
[17]
John Wiley & Sons, 2nd edition, 2003
Kenneth Falconer.Fractal Geometry: Mathematical Foundations and Applications. John Wiley & Sons, 2nd edition, 2003
2003
-
[18]
Testing the manifold hypothesis
Charles Fefferman, Sanjoy Mitter, and Hariharan Narayanan. Testing the manifold hypothesis. Journal of the American Mathematical Society, 29(4):983–1049, 2016
2016
-
[19]
A Bayesian analysis of some nonparametric problems.The Annals of Statistics, 1(2):209–230, 1973
Thomas S Ferguson. A Bayesian analysis of some nonparametric problems.The Annals of Statistics, 1(2):209–230, 1973
1973
-
[20]
The conditional entropy bottleneck.Entropy, 22(9):999, 2020
Ian Fischer. The conditional entropy bottleneck.Entropy, 22(9):999, 2020
2020
-
[21]
On the mathematical foundations of theoretical statistics.Philosophical Transactions of the Royal Society of London A, 222:309–368, 1922
Ronald A Fisher. On the mathematical foundations of theoretical statistics.Philosophical Transactions of the Royal Society of London A, 222:309–368, 1922. 27
1922
-
[22]
Common information is far less than mutual information
Peter G´ acs and J´ anos K¨ orner. Common information is far less than mutual information. Problems of Control and Information Theory, 2(2):149–162, 1973
1973
-
[23]
The information bottleneck problem and its applications in machine learning.IEEE Journal on Selected Areas in Information Theory, 1(1):99–129, 2020
Ziv Goldfeld and Yury Polyanskiy. The information bottleneck problem and its applications in machine learning.IEEE Journal on Selected Areas in Information Theory, 1(1):99–129, 2020
2020
-
[24]
Semi-supervised learning by entropy minimization
Yves Grandvalet and Yoshua Bengio. Semi-supervised learning by entropy minimization. In Advances in Neural Information Processing Systems, volume 17, 2004
2004
-
[25]
Boot- strap your own latent: A new approach to self-supervised learning
Jean-Bastien Grill, Florian Strub, Florent Altch´ e, Corentin Tallec, Pierre Richemond, Elena Buchatskaya, Carl Doersch, Bernardo Avila Pires, Zhaohan Chen, Michal Valko, et al. Boot- strap your own latent: A new approach to self-supervised learning. InAdvances in Neural Information Processing Systems, 2020
2020
-
[26]
The information bottleneck revisited or how to choose a good distortion measure
Peter Harrem¨ oes and Naftali Tishby. The information bottleneck revisited or how to choose a good distortion measure. InIEEE International Symposium on Information Theory, pages 566–570, 2007
2007
-
[27]
Edwin T. Jaynes. Information theory and statistical mechanics.Physical Review, 106(4):620– 630, 1957
1957
-
[28]
Dirichlet variational autoen- coder.Pattern Recognition, 107:107514, 2020
Weonyoung Joo, Wonsung Lee, Sungrae Park, and Il-Chul Moon. Dirichlet variational autoen- coder.Pattern Recognition, 107:107514, 2020
2020
-
[29]
Kingma, Shakir Mohamed, Danilo Jimenez Rezende, and Max Welling
Diederik P. Kingma, Shakir Mohamed, Danilo Jimenez Rezende, and Max Welling. Semi- supervised learning with deep generative models. InAdvances in Neural Information Processing Systems, volume 27, 2014
2014
-
[30]
Nonlinear information bottle- neck.Entropy, 21(12):1181, 2019
Artemy Kolchinsky, Brendan D Tracey, and Steven Van Kuyk. Nonlinear information bottle- neck.Entropy, 21(12):1181, 2019
2019
-
[31]
Andrei N Kolmogorov and Vladimir M Tikhomirov.ε-entropy andε-capacity of sets in func- tional spaces.American Mathematical Society Translations, 17:277–364, 1961
1961
-
[32]
A path towards autonomous machine intelligence
Yann LeCun. A path towards autonomous machine intelligence. Technical report, Meta AI, 2022
2022
-
[33]
Completeness, similar regions, and unbiased estimation: Part I.Sankhy¯ a, 10(4):305–340, 1950
Erich L Lehmann and Henry Scheff´ e. Completeness, similar regions, and unbiased estimation: Part I.Sankhy¯ a, 10(4):305–340, 1950
1950
-
[34]
The intrinsic dimension of images and its impact on learning
Phillip Pope, Chen Zhu, Ahmed Abdelkader, Micah Goldblum, and Tom Goldstein. The intrinsic dimension of images and its impact on learning. InInternational Conference on Learning Representations, 2021
2021
-
[35]
On the information bottleneck theory of deep learning
Andrew M Saxe, Yamini Bansal, Joel Dapello, Madhu Advani, Artemy Kolchinsky, Bren- dan D Tracey, and David D Cox. On the information bottleneck theory of deep learning. In International Conference on Learning Representations, 2018
2018
-
[36]
Coding theorems for a discrete source with a fidelity criterion.IRE National Convention Record, 7(4):142–163, 1959
Claude E Shannon. Coding theorems for a discrete source with a fidelity criterion.IRE National Convention Record, 7(4):142–163, 1959
1959
-
[37]
To compress or not to compress—self-supervised learning and information theory: A review.Entropy, 26(3):252, 2024
Ravid Shwartz-Ziv and Yann LeCun. To compress or not to compress—self-supervised learning and information theory: A review.Entropy, 26(3):252, 2024. 28
2024
-
[38]
Opening the Black Box of Deep Neural Networks via Information
Ravid Shwartz-Ziv and Naftali Tishby. Opening the black box of deep neural networks via information.arXiv preprint arXiv:1703.00810, 2017
work page Pith review arXiv 2017
-
[39]
The deterministic information bottleneck.Neural Computa- tion, 29(6):1611–1630, 2017
DJ Strouse and David J Schwab. The deterministic information bottleneck.Neural Computa- tion, 29(6):1611–1630, 2017
2017
-
[40]
The information bottleneck method
Naftali Tishby, Fernando C Pereira, and William Bialek. The information bottleneck method. InProceedings of the 37th Annual Allerton Conference on Communication, Control, and Com- puting, pages 368–377, 1999
1999
-
[41]
On mutual information maximization for representation learning
Michael Tschannen, Josip Djolonga, Paul K Rubenstein, Sylvain Gelly, and Mario Lucic. On mutual information maximization for representation learning. InInternational Conference on Learning Representations, 2020
2020
-
[42]
A survey on semi-supervised learning.Machine Learning, 109(2):373–440, 2020
Jesper E van Engelen and Holger H Hoos. A survey on semi-supervised learning.Machine Learning, 109(2):373–440, 2020
2020
-
[43]
A conditional entropy bound for a pair of discrete random variables.IEEE Transactions on Information Theory, 21(5):493–501, 1975
Hans S Witsenhausen and Aaron D Wyner. A conditional entropy bound for a pair of discrete random variables.IEEE Transactions on Information Theory, 21(5):493–501, 1975
1975
-
[44]
Wyner and Jacob Ziv
Aaron D. Wyner and Jacob Ziv. The rate-distortion function for source coding with side information at the decoder.IEEE Transactions on Information Theory, 22(1):1–10, 1976
1976
-
[45]
manifold
Aolin Xu and Maxim Raginsky. Information-theoretic analysis of generalization capability of learning algorithms. InAdvances in Neural Information Processing Systems, 2017. Appendices A Effective Dimension in the Continuous Case WhenYis continuous,p(Y|x) is a density and the predictive manifoldM={p(Y|x) :x∈ X } is a subset of an infinite-dimensional functi...
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.