Recognition: unknown
Position-Aware Drafting for Inference Acceleration in LLM-Based Generative List-Wise Recommendation
Pith reviewed 2026-05-07 07:37 UTC · model grok-4.3
The pith
Augmenting the draft model with item-slot and speculation-depth position embeddings accelerates LLM-based list recommendation inference up to 3.1 times while preserving output quality.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
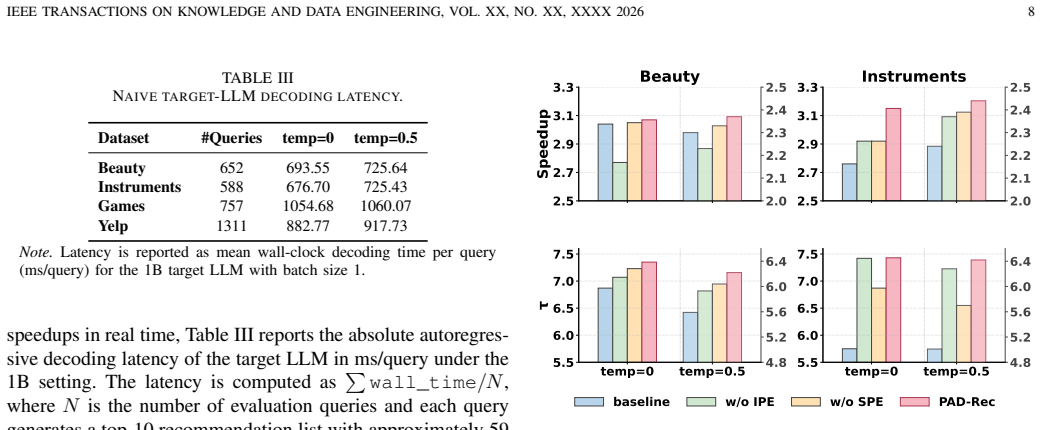
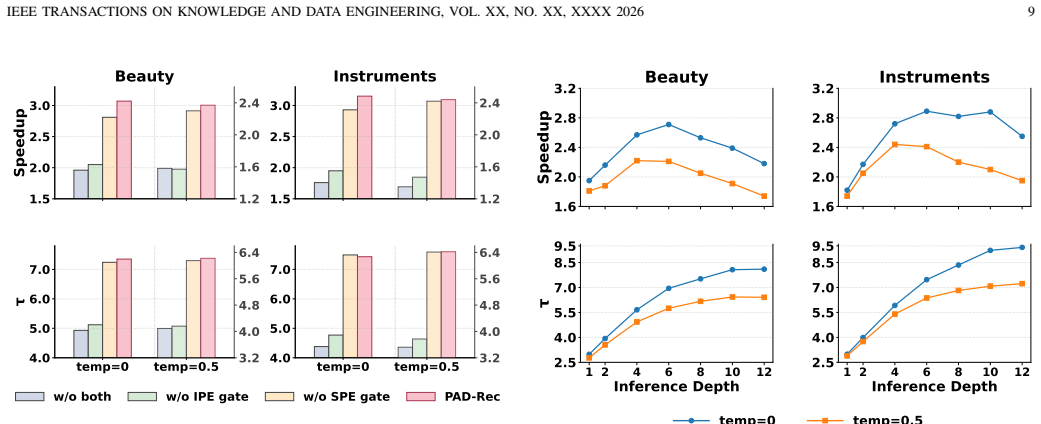
PAD-Rec augments any draft model by injecting item position embeddings that mark each token's slot inside its semantic ID, step position embeddings that track speculation depth, and two gates (a learnable scalar for item slots and a context-driven gate for steps) that fuse these signals with the base features; the improved drafts raise the average accepted prefix length in speculative decoding for list-wise recommendation, delivering up to 3.1x wall-clock speedup and roughly 5 percent average gain over strong baselines while keeping recommendation metrics nearly unchanged.
What carries the argument
The PAD-Rec module: item-position embeddings encoding within-item token slots, step-position embeddings encoding draft depth, and two simple gates (learnable coefficient for slots plus context-driven gate for steps) that integrate the signals into a standard draft model.
If this is right
- Speculative decoding reaches up to 3.1x wall-clock speedup on real-world recommendation datasets.
- Recommendation quality metrics remain largely unchanged compared with strong speculative-decoding baselines.
- The module adds negligible inference overhead and integrates with existing draft models without architectural changes.
- Average wall-clock speedup gain of about 5 percent is observed over competitive baselines across four datasets.
Where Pith is reading between the lines
- The same position-aware drafting pattern could be applied to other multi-token structured generation tasks such as code or product-description synthesis.
- Because draft quality improves without enlarging the draft model, memory footprint during inference may be reduced by using smaller draft networks.
- The explicit slot embeddings may expose which tokenization choices inside items most affect acceptance rates, guiding future semantic-ID designs.
- Stacking this technique with orthogonal accelerations such as quantization or tree-based drafting could compound the observed speedups.
Load-bearing premise
The added position embeddings and gates will raise draft quality enough to increase accepted prefix length consistently across datasets and model sizes without creating harmful distribution shift or needing heavy per-dataset retuning.
What would settle it
On a new recommendation dataset or larger target LLM, if the average number of accepted tokens per verification round fails to rise or wall-clock latency does not drop by at least 1.5 times relative to plain speculative decoding, the claimed benefit would be refuted.
Figures




read the original abstract
Large language model (LLM)-based generative list-wise recommendation has advanced rapidly, but decoding remains sequential and thus latency-prone. To accelerate inference without changing the target distribution, speculative decoding (SD) uses a small draft model to propose several next tokens at once and a target LLM to verify and accept the longest prefix, skipping multiple steps per round. In generative recommendation, however, each item is represented by multiple semantic-ID tokens, often with separators, and current drafts typically treat these tokens uniformly. This overlooks two practical facts: (i) a token's semantics depend on its within-item slot, and (ii) uncertainty tends to increase with speculation depth. Without modeling these effects, SD's speedups can be limited. We introduce PAD-Rec, Position-Aware Drafting for generative Recommendation, a lightweight module that augments the draft model with two complementary signals. Item position embeddings explicitly encode the within-item slot of each token, strengthening structural awareness. Step position embeddings encode the draft step, allowing the model to adapt to depth-dependent uncertainty and improve proposal quality. To harmonize these signals with base features, we add simple gates: a learnable coefficient for item slots and a context-driven gate for draft steps. The module is trainable, easy to integrate with standard draft models, and adds negligible inference overhead. Extensive experiments on four real-world datasets show up to 3.1x wall-clock speedup and about 5% average wall-clock speedup gain over strong SD baselines, while largely preserving recommendation quality.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes PAD-Rec, a lightweight position-aware drafting module to accelerate inference in LLM-based generative list-wise recommendation via speculative decoding. It augments standard draft models with item-position embeddings (encoding within-item token slots) and step-position embeddings (encoding speculation depth), combined via a learnable coefficient for item slots and a context-driven gate for draft steps. The module is claimed to be trainable with negligible overhead. Extensive experiments on four real-world datasets report up to 3.1× wall-clock speedup and ~5% average wall-clock speedup gain over strong SD baselines while largely preserving recommendation quality.
Significance. If the reported speedups are robust, the work addresses a practical bottleneck in deploying generative recommenders by improving draft quality for multi-token item representations without changing the target distribution. The lightweight, integrable design could enable faster inference in production systems, particularly where item semantic IDs involve variable-length token sequences.
major comments (2)
- [Experiments] Experiments section: The abstract and results claim concrete speedups (3.1× peak, ~5% average) and quality preservation on four datasets, but supply no details on statistical significance, error bars, number of runs, exact baseline implementations (e.g., draft model sizes, acceptance-rate statistics), or ablation studies isolating item-position vs. step-position contributions. This is load-bearing for the central empirical claim, as the skeptic note highlights potential dataset-specific artifacts from untested generalization of the gates.
- [Method] Method section (PAD-Rec module description): The learnable coefficient for item slots and context-driven gate for draft steps are presented as trainable signals to harmonize position embeddings with base features, yet there is no analysis or evidence on whether these gates are frozen after training or require per-dataset retuning, nor any measurement of acceptance rates as a function of list length or draft step. If distribution shift in item-length or depth-dependent uncertainty occurs, the reported speedups may not hold, directly undermining the assumption that the module consistently improves proposal quality.
minor comments (2)
- [Abstract] Abstract: The phrasing 'about 5% average wall-clock speedup gain' is imprecise; report the exact computed average, the set of baselines it is averaged over, and whether it is mean or median across datasets.
- [Method] Notation: The paper introduces 'PAD-Rec module' and 'item-position embeddings' without a clear equation or diagram showing how these embeddings are added to the draft model's input (e.g., concatenation, addition to token embeddings).
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will incorporate the suggested additions in the revised manuscript to improve clarity and empirical rigor.
read point-by-point responses
-
Referee: [Experiments] Experiments section: The abstract and results claim concrete speedups (3.1× peak, ~5% average) and quality preservation on four datasets, but supply no details on statistical significance, error bars, number of runs, exact baseline implementations (e.g., draft model sizes, acceptance-rate statistics), or ablation studies isolating item-position vs. step-position contributions. This is load-bearing for the central empirical claim, as the skeptic note highlights potential dataset-specific artifacts from untested generalization of the gates.
Authors: We agree that the manuscript currently lacks these experimental details. In the revision we will expand the Experiments section to report results over multiple independent runs with error bars and statistical significance tests, provide exact baseline configurations including draft model sizes and acceptance-rate statistics, and add ablation studies that isolate the contributions of item-position embeddings versus step-position embeddings. These changes will directly address concerns about robustness and generalization. revision: yes
-
Referee: [Method] Method section (PAD-Rec module description): The learnable coefficient for item slots and context-driven gate for draft steps are presented as trainable signals to harmonize position embeddings with base features, yet there is no analysis or evidence on whether these gates are frozen after training or require per-dataset retuning, nor any measurement of acceptance rates as a function of list length or draft step. If distribution shift in item-length or depth-dependent uncertainty occurs, the reported speedups may not hold, directly undermining the assumption that the module consistently improves proposal quality.
Authors: We acknowledge the absence of this analysis. In the revised manuscript we will add a subsection clarifying the training and inference behavior of the gates (including whether they are frozen post-training or benefit from per-dataset retuning) and include new figures/tables reporting acceptance rates as a function of list length and draft step across all datasets. This will provide direct evidence on robustness to potential distribution shifts. revision: yes
Circularity Check
No derivation chain present; empirical engineering paper with no circularity
full rationale
The manuscript describes an empirical method (PAD-Rec) that augments a draft model with item-position and step-position embeddings plus learnable gates, then reports wall-clock speedups from experiments on four datasets. No equations, first-principles derivations, or predictions appear in the abstract or method description. The gates are explicitly trainable parameters optimized during training rather than fitted post-hoc to the reported metrics, and no uniqueness theorems or self-citation chains are invoked to force the architectural choices. Because the central claims rest on external experimental validation rather than any reduction of outputs to inputs by construction, the work is self-contained and exhibits no circularity.
Axiom & Free-Parameter Ledger
free parameters (2)
- learnable coefficient for item slots
- context-driven gate for draft steps
axioms (1)
- domain assumption Speculative decoding preserves the target model's output distribution when the draft proposals are verified by the target model.
invented entities (1)
-
PAD-Rec module
no independent evidence
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2509.03236 , year=
B. Chen, X. Guo, S. Wang, Z. Liang, Y . Lv, Y . Ma, X. Xiao, B. Xue, X. Zhang, Y . Yanget al., “Onesearch: A preliminary exploration of the unified end-to-end generative framework for e-commerce search,”arXiv preprint arXiv:2509.03236, 2025
-
[2]
OneRec: Unifying Retrieve and Rank with Generative Recommender and Iterative Preference Alignment
J. Deng, S. Wang, K. Cai, L. Ren, Q. Hu, W. Ding, Q. Luo, and G. Zhou, “Onerec: Unifying retrieve and rank with generative recommender and iterative preference alignment,”arXiv preprint arXiv:2502.18965, 2025
work page internal anchor Pith review arXiv 2025
-
[3]
Dlcrec: A novel approach for managing diversity in llm-based recommender systems,
J. Chen, C. Gao, S. Yuan, S. Liu, Q. Cai, and P. Jiang, “Dlcrec: A novel approach for managing diversity in llm-based recommender systems,” inProceedings of the Eighteenth ACM International Conference on Web Search and Data Mining, 2025, pp. 857–865
2025
-
[4]
Knowledge-enhanced con- versational recommendation via transformer-based sequential modeling,
J. Zou, A. Sun, C. Long, and E. Kanoulas, “Knowledge-enhanced con- versational recommendation via transformer-based sequential modeling,” ACM Transactions on Information Systems, vol. 42, no. 6, pp. 1–27, 2024
2024
-
[5]
Decoding in latent spaces for efficient inference in llm-based recommendation,
C. Wang, Y . Zhang, Z. Wang, T. Shi, K. Bao, F. Feng, and T.-S. Chua, “Decoding in latent spaces for efficient inference in llm-based recommendation,”arXiv preprint arXiv:2509.11524, 2025
-
[6]
Efficient inference for large language model-based generative recommendation,
X. Lin, C. Yang, W. Wang, Y . Li, C. Du, F. Feng, S.-K. Ng, and T.- S. Chua, “Efficient inference for large language model-based generative recommendation,” inThe Thirteenth International Conference on Learn- ing Representations, 2025
2025
-
[7]
Efficiency unleashed: Inference acceleration for llm-based recommender systems with speculative decoding,
Y . Xi, H. Wang, B. Chen, J. Lin, M. Zhu, W. Liu, R. Tang, Z. Wei, W. Zhang, and Y . Yu, “Efficiency unleashed: Inference acceleration for llm-based recommender systems with speculative decoding,” inProceed- ings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval, 2025, pp. 1891–1901
2025
-
[8]
Fast inference from transform- ers via speculative decoding,
Y . Leviathan, M. Kalman, and Y . Matias, “Fast inference from transform- ers via speculative decoding,” inInternational Conference on Machine Learning. PMLR, 2023, pp. 19 274–19 286
2023
-
[9]
Lossless speedup of autoregressive translation with generalized aggressive decoding
H. Xia, T. Ge, P. Wang, S.-Q. Chen, F. Wei, and Z. Sui, “Speculative decoding: Exploiting speculative execution for accelerating seq2seq generation,”arXiv preprint arXiv:2203.16487, 2022
-
[10]
Unlocking efficiency in large language model inference: A comprehensive survey of speculative decoding,
H. Xia, Z. Yang, Q. Dong, P. Wang, Y . Li, T. Ge, T. Liu, W. Li, and Z. Sui, “Unlocking efficiency in large language model inference: A comprehensive survey of speculative decoding,” inACL (Findings), 2024
2024
-
[11]
Accelerating Large Language Model Decoding with Speculative Sampling
C. Chen, S. Borgeaud, G. Irving, J.-B. Lespiau, L. Sifre, and J. Jumper, “Accelerating large language model decoding with speculative sam- pling,”arXiv preprint arXiv:2302.01318, 2023
work page internal anchor Pith review arXiv 2023
-
[12]
Specinfer: Accelerating large language model serving with tree-based speculative inference and ver- ification,
X. Miao, G. Oliaro, Z. Zhang, X. Cheng, Z. Wang, Z. Zhang, R. Y . Y . Wong, A. Zhu, L. Yang, X. Shiet al., “Specinfer: Accelerating large language model serving with tree-based speculative inference and ver- ification,” inProceedings of the 29th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 3...
2024
-
[13]
Distillspec: Improving speculative decoding via knowledge distillation,
Y . Zhou, K. Lyu, A. S. Rawat, A. K. Menon, A. Rostamizadeh, S. Ku- mar, J.-F. Kagy, and R. Agarwal, “Distillspec: Improving speculative decoding via knowledge distillation,”arXiv preprint arXiv:2310.08461, 2023. IEEE TRANSACTIONS ON KNOWLEDGE AND DATA ENGINEERING, VOL. XX, NO. XX, XXXX 2026 11
-
[14]
Eagle: Speculative sampling requires rethinking feature uncertainty,
Y . Li, F. Wei, C. Zhang, and H. Zhang, “Eagle: Speculative sampling requires rethinking feature uncertainty,” inInternational Conference on Machine Learning. PMLR, 2024, pp. 28 935–28 948
2024
-
[15]
Learning harmonized rep- resentations for speculative sampling,
L. Zhang, X. Wang, Y . Huang, and R. Xu, “Learning harmonized rep- resentations for speculative sampling,” inThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[16]
Tokenrec: Learning to tokenize id for llm-based generative recommendations,
H. Qu, W. Fan, Z. Zhao, and Q. Li, “Tokenrec: Learning to tokenize id for llm-based generative recommendations,”IEEE Transactions on Knowledge and Data Engineering, 2025
2025
-
[17]
Adapting large language models by integrating collaborative semantics for recommendation,
B. Zheng, Y . Hou, H. Lu, Y . Chen, W. X. Zhao, M. Chen, and J.-R. Wen, “Adapting large language models by integrating collaborative semantics for recommendation,” in2024 IEEE 40th International Conference on Data Engineering (ICDE). IEEE, 2024, pp. 1435–1448
2024
-
[18]
Autoregressive image generation using residual quantization,
D. Lee, C. Kim, S. Kim, M. Cho, and W.-S. Han, “Autoregressive image generation using residual quantization,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 11 523–11 532
2022
-
[19]
Blockwise parallel decoding for deep autoregressive models,
M. Stern, N. Shazeer, and J. Uszkoreit, “Blockwise parallel decoding for deep autoregressive models,”Advances in Neural Information Pro- cessing Systems, vol. 31, 2018
2018
-
[20]
Eagle-2: Faster inference of language models with dynamic draft trees,
Y . Li, F. Wei, C. Zhang, and H. Zhang, “Eagle-2: Faster inference of language models with dynamic draft trees,” inProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, 2024, pp. 7421–7432
2024
-
[21]
Sequoia: Scalable, robust, and hardware-aware speculative decoding,
Z. Chen, A. May, R. Svirschevski, Y . Huang, M. Ryabinin, Z. Jia, and B. Chen, “Sequoia: Scalable, robust, and hardware-aware speculative decoding,”CoRR, 2024
2024
-
[22]
Specexec: Massively parallel speculative decoding for interactive llm inference on consumer devices,
R. Svirschevski, A. May, Z. Chen, B. Chen, Z. Jia, and M. Ryabinin, “Specexec: Massively parallel speculative decoding for interactive llm inference on consumer devices,”Advances in Neural Information Pro- cessing Systems, vol. 37, pp. 16 342–16 368, 2024
2024
-
[23]
Break the sequential de- pendency of llm inference using lookahead decoding,
Y . Fu, P. Bailis, I. Stoica, and H. Zhang, “Break the sequential de- pendency of llm inference using lookahead decoding,” inProceedings of the 41st International Conference on Machine Learning, 2024, pp. 14 060–14 079
2024
-
[24]
Cllms: Consistency large language models,
S. Kou, L. Hu, Z. He, Z. Deng, and H. Zhang, “Cllms: Consistency large language models,” inForty-first International Conference on Machine Learning, 2024
2024
-
[25]
Rest: Retrieval- based speculative decoding,
Z. He, Z. Zhong, T. Cai, J. D. Lee, and D. He, “Rest: Retrieval- based speculative decoding,” in2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL 2024. Association for Computational Linguistics (ACL), 2024, pp. 1582–1595
2024
-
[26]
Ouroboros: Generating longer drafts phrase by phrase for faster speculative decoding,
W. Zhao, Y . Huang, X. Han, W. Xu, C. Xiao, X. Zhang, Y . Fang, K. Zhang, Z. Liu, and M. Sun, “Ouroboros: Generating longer drafts phrase by phrase for faster speculative decoding,” inProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, 2024, pp. 13 378–13 393
2024
-
[27]
Medusa: Simple llm inference acceleration framework with multiple decoding heads,
T. Cai, Y . Li, Z. Geng, H. Peng, J. D. Lee, D. Chen, and T. Dao, “Medusa: Simple llm inference acceleration framework with multiple decoding heads,” inProceedings of the 41st International Conference on Machine Learning, 2024, pp. 5209–5235
2024
-
[28]
Hydra: Sequentially-dependent draft heads for medusa decoding,
Z. Ankner, R. Parthasarathy, A. Nrusimha, C. Rinard, J. Ragan-Kelley, and W. Brandon, “Hydra: Sequentially-dependent draft heads for medusa decoding,” inFirst Conference on Language Modeling, 2024
2024
-
[29]
S. Hu, J. Li, X. Xie, Z. Lu, K.-C. Toh, and P. Zhou, “Griffin: Effec- tive token alignment for faster speculative decoding,”arXiv preprint arXiv:2502.11018, 2025
-
[30]
Boosting lossless speculative decoding via feature sampling and partial alignment distillation,
L. Gui, B. Xiao, L. Su, and W. Chen, “Boosting lossless speculative decoding via feature sampling and partial alignment distillation,”arXiv preprint arXiv:2408.15562, 2024
-
[31]
Y . Weng, D. Mei, H. Qiu, X. Chen, L. Liu, J. Tian, and Z. Shi, “Coral: Learning consistent representations across multi-step training with lighter speculative drafter,”arXiv preprint arXiv:2502.16880, 2025
-
[32]
How speculative can speculative decoding be?
Z. Liu, C. Zhang, and D. Song, “How speculative can speculative decoding be?” inProceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024), 2024, pp. 8265–8275
2024
-
[33]
Heterospec: Leveraging con- textual heterogeneity for efficient speculative decoding,
S. Liu, Y . Ye, Q. Zhu, Z. Cao, and Y . He, “Heterospec: Leveraging con- textual heterogeneity for efficient speculative decoding,”arXiv preprint arXiv:2505.13254, 2025
-
[34]
H2o: Heavy-hitter oracle for efficient generative inference of large language models,
Z. Zhang, Y . Sheng, T. Zhou, T. Chen, L. Zheng, R. Cai, Z. Song, Y . Tian, C. R´e, C. Barrettet al., “H2o: Heavy-hitter oracle for efficient generative inference of large language models,”Advances in Neural Information Processing Systems, vol. 36, pp. 34 661–34 710, 2023
2023
-
[35]
A bi-step grounding paradigm for large language mod- els in recommendation systems,
K. Bao, J. Zhang, W. Wang, Y . Zhang, Z. Yang, Y . Luo, C. Chen, F. Feng, and Q. Tian, “A bi-step grounding paradigm for large language mod- els in recommendation systems,”ACM Transactions on Recommender Systems, vol. 3, no. 4, pp. 1–27, 2025
2025
-
[36]
Large language models are learnable planners for long-term recommendation,
W. Shi, X. He, Y . Zhang, C. Gao, X. Li, J. Zhang, Q. Wang, and F. Feng, “Large language models are learnable planners for long-term recommendation,” inProceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval, 2024, pp. 1893–1903
2024
-
[37]
Reinforced latent reasoning for llm-based recommendation.arXiv preprint arXiv:2505.19092.2025
Y . Zhang, W. Xu, X. Zhao, W. Wang, F. Feng, X. He, and T.-S. Chua, “Reinforced latent reasoning for llm-based recommendation,”arXiv preprint arXiv:2505.19092, 2025
-
[38]
Recommender systems with generative retrieval,
S. Rajput, N. Mehta, A. Singh, R. Hulikal Keshavan, T. Vu, L. Heldt, L. Hong, Y . Tay, V . Tran, J. Samostet al., “Recommender systems with generative retrieval,”Advances in Neural Information Processing Systems, vol. 36, pp. 10 299–10 315, 2023
2023
-
[39]
Actionpiece: Contextually tokeniz- ing action sequences for generative recommendation,
Y . Hou, J. Ni, Z. He, N. Sachdeva, W.-C. Kang, E. H. Chi, J. McAuley, and D. Z. Cheng, “Actionpiece: Contextually tokeniz- ing action sequences for generative recommendation,”arXiv preprint arXiv:2502.13581, 2025
-
[40]
Learnable item tokenization for generative recommendation,
W. Wang, H. Bao, X. Lin, J. Zhang, Y . Li, F. Feng, S.-K. Ng, and T.-S. Chua, “Learnable item tokenization for generative recommendation,” in Proceedings of the 33rd ACM International Conference on Information and Knowledge Management, 2024, pp. 2400–2409
2024
-
[41]
How to index item ids for recommendation foundation models,
W. Hua, S. Xu, Y . Ge, and Y . Zhang, “How to index item ids for recommendation foundation models,” inProceedings of the Annual International ACM SIGIR Conference on Research and Development in Information Retrieval in the Asia Pacific Region, 2023, pp. 195–204
2023
-
[42]
Recommendation as language processing (rlp): A unified pretrain, personalized prompt & predict paradigm (p5),
S. Geng, S. Liu, Z. Fu, Y . Ge, and Y . Zhang, “Recommendation as language processing (rlp): A unified pretrain, personalized prompt & predict paradigm (p5),” inProceedings of the 16th ACM conference on recommender systems, 2022, pp. 299–315
2022
-
[43]
Eager: Two-stream generative recommender with behavior-semantic collaboration,
Y . Wang, J. Xun, M. Hong, J. Zhu, T. Jin, W. Lin, H. Li, L. Li, Y . Xia, Z. Zhaoet al., “Eager: Two-stream generative recommender with behavior-semantic collaboration,” inProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, 2024, pp. 3245–3254
2024
-
[44]
J. Zhai, L. Liao, X. Liu, Y . Wang, R. Li, X. Cao, L. Gao, Z. Gong, F. Gu, M. Heet al., “Actions speak louder than words: Trillion-parameter sequential transducers for generative recommendations,”arXiv preprint arXiv:2402.17152, 2024
work page internal anchor Pith review arXiv 2024
-
[45]
Sprec: Self- play to debias llm-based recommendation,
C. Gao, R. Chen, S. Yuan, K. Huang, Y . Yu, and X. He, “Sprec: Self- play to debias llm-based recommendation,” inProceedings of the ACM on Web Conference 2025, ser. WWW ’25, 2025, pp. 5075–5084
2025
-
[46]
Process- supervised llm recommenders via flow-guided tuning,
C. Gao, M. Gao, C. Fan, S. Yuan, W. Shi, and X. He, “Process- supervised llm recommenders via flow-guided tuning,” inProceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval, ser. SIGIR ’25, 2025, pp. 1934– 1943
2025
-
[47]
Nextquill: Causal preference modeling for enhancing llm personalization,
X. Zhao, J. You, Y . Zhang, W. Wang, H. Cheng, F. Feng, S.-K. Ng, and T.-S. Chua, “Nextquill: Causal preference modeling for enhancing llm personalization,”arXiv preprint arXiv:2506.02368, 2025
-
[48]
Don’t start over: A cost-effective framework for migrating personalized prompts between llms,
Z. Zhao, C. Gao, Y . Zhang, H. Liu, W. Gan, H. Guo, Y . Liu, and F. Feng, “Don’t start over: A cost-effective framework for migrating personalized prompts between llms,”arXiv preprint arXiv:2601.12034, 2026
-
[49]
C. Wang, Y . Zhang, W. Wang, X. Zhao, F. Feng, X. He, and T.-S. Chua, “Think-while-generating: On-the-fly reasoning for personalized long-form generation,”arXiv preprint arXiv:2512.06690, 2025
-
[50]
Integrating large language models with reinforcement learning: A survey of llm-rl synergistic recommendation,
M. Gao, C. Gao, J. Tang, J. Zhang, X. Zhao, B. Wang, J. Chen, H. He, L. Pan, X. Chen, X. Xin, Q. Cai, P. Jiang, K. Gai, H. Liu, F. Feng, and X. He, “Integrating large language models with reinforcement learning: A survey of llm-rl synergistic recommendation,”TechRxiv Preprint, 2026
2026
-
[51]
Generative retrieval with semantic tree-structured identifiers and contrastive learning,
Z. Si, Z. Sun, J. Chen, G. Chen, X. Zang, K. Zheng, Y . Song, X. Zhang, J. Xu, and K. Gai, “Generative retrieval with semantic tree-structured identifiers and contrastive learning,” inProceedings of the 2024 Annual International ACM SIGIR Conference on Research and Development in Information Retrieval in the Asia Pacific Region, 2024, pp. 154–163
2024
-
[52]
Idgenrec: Llm- recsys alignment with textual id learning,
J. Tan, S. Xu, W. Hua, Y . Ge, Z. Li, and Y . Zhang, “Idgenrec: Llm- recsys alignment with textual id learning,” inProceedings of the 47th international ACM SIGIR conference on research and development in information retrieval, 2024, pp. 355–364
2024
-
[53]
Wide & deep learning for recommender systems,
H.-T. Cheng, L. Koc, J. Harmsen, T. Shaked, T. Chandra, H. Aradhye, G. Anderson, G. Corrado, W. Chai, M. Ispiret al., “Wide & deep learning for recommender systems,” inProceedings of the 1st workshop on deep learning for recommender systems, 2016, pp. 7–10. IEEE TRANSACTIONS ON KNOWLEDGE AND DATA ENGINEERING, VOL. XX, NO. XX, XXXX 2026 12
2016
-
[54]
Lightgcn: Simplifying and powering graph convolution network for recommenda- tion,
X. He, K. Deng, X. Wang, Y . Li, Y . Zhang, and M. Wang, “Lightgcn: Simplifying and powering graph convolution network for recommenda- tion,” inProceedings of the 43rd International ACM SIGIR conference on research and development in Information Retrieval, 2020, pp. 639– 648
2020
-
[55]
Second order derivatives for network pruning: Optimal brain surgeon,
B. Hassibi and D. Stork, “Second order derivatives for network pruning: Optimal brain surgeon,”Advances in neural information processing systems, vol. 5, 1992
1992
-
[56]
Boosting parameter efficiency in llm-based recommendation through sophisticated pruning,
S. Zheng, K. Bao, J. Zhang, Y . Zhang, F. Feng, and X. He, “Boosting parameter efficiency in llm-based recommendation through sophisticated pruning,”arXiv preprint arXiv:2507.07064, 2025
-
[57]
Smoothquant: Accurate and efficient post-training quantization for large language models,
G. Xiao, J. Lin, M. Seznec, H. Wu, J. Demouth, and S. Han, “Smoothquant: Accurate and efficient post-training quantization for large language models,” inInternational conference on machine learning. PMLR, 2023, pp. 38 087–38 099
2023
-
[58]
Inductive generative recom- mendation via retrieval-based speculation,
Y . Ding, J. Li, J. McAuley, and Y . Hou, “Inductive generative recom- mendation via retrieval-based speculation,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 40, no. 17, 2026, pp. 14 675– 14 683
2026
-
[59]
Nezha: A zero-sacrifice and hyperspeed decoding architecture for generative recommendations,
Y . Wang, S. Zhou, J. Lu, Z. Liu, L. Liu, M. Wang, W. Zhang, F. Li, W. Su, P. Wanget al., “Nezha: A zero-sacrifice and hyperspeed decoding architecture for generative recommendations,” inProceedings of the ACM Web Conference 2026, 2026, pp. 8073–8082
2026
-
[60]
Earn: Efficient inference acceleration for llm-based generative recom- mendation by register tokens,
C. Yang, X. Lin, W. Wang, Y . Li, T. Sun, X. Han, and T.-S. Chua, “Earn: Efficient inference acceleration for llm-based generative recom- mendation by register tokens,” inProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V . 2, 2025, pp. 3483–3494
2025
-
[61]
Justifying recommendations using distantly-labeled reviews and fine-grained aspects,
J. Ni, J. Li, and J. McAuley, “Justifying recommendations using distantly-labeled reviews and fine-grained aspects,” inProceedings of the 2019 conference on empirical methods in natural language pro- cessing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP), 2019, pp. 188–197
2019
-
[62]
The llama 3 herd of models,
A. Dubey, A. Jauhri, A. Pandey, A. Kadian, A. Al-Dahle, A. Letman, A. Mathur, A. Schelten, A. Yang, A. Fanet al., “The llama 3 herd of models,”arXiv e-prints, pp. arXiv–2407, 2024
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.