Recognition: unknown
Learning to Reason: Targeted Knowledge Discovery and Fuzzy Logic Update for Robust Image Recognition
Pith reviewed 2026-05-07 06:13 UTC · model grok-4.3
The pith
A Differentiable Knowledge Unit modulates classifier logits with fuzzy inference on implicit concepts learned without labels.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central discovery is that a Differentiable Knowledge Unit can modulate classifier logits through fuzzy inference on implicit concepts learned entirely from main task supervision. By constructing a rule base of bidirectional logical relations and enforcing distinctness between concepts and classes, the method creates a clean supervision signal. This allows the concept classifiers to be trained implicitly, leading to refined class probabilities that improve recognition performance across multiple datasets.
What carries the argument
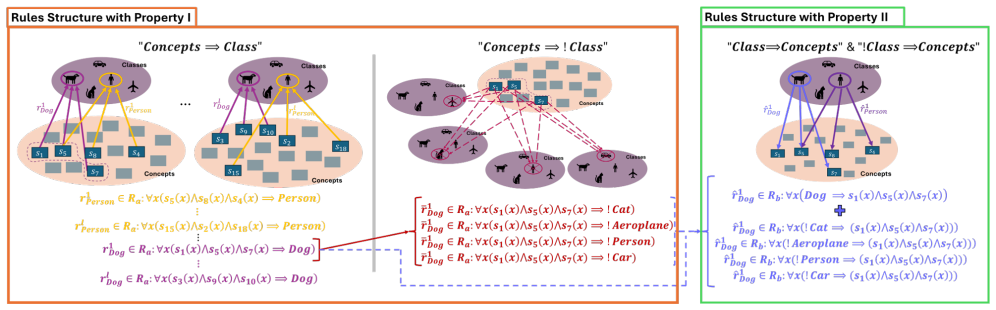
The Differentiable Knowledge Unit (DKU) that takes primary class probabilities and concept probabilities, computes a logic-based adjustment vector via fuzzy inference on implication rules, and modulates the class logits.
If this is right
- Refined class probabilities result from the fuzzy adjustments.
- Performance improves on PASCAL-VOC, COCO, and MedMNIST datasets.
- Better results in domain generalization experiments.
- Hard samples are handled more effectively due to the knowledge integration.
- Concept classifiers receive implicit training signals from the main loss.
Where Pith is reading between the lines
- The approach might generalize to tasks where logical relations between hidden factors and outputs can be defined.
- Hand-crafting the rule base could be replaced by learning rules if the method scales.
- Enforcing distinctness prevents the concepts from collapsing into the class representations.
Load-bearing premise
Implicitly learned concepts will form useful bidirectional logical relations with the classes, making the fuzzy adjustments beneficial rather than harmful to the loss minimization.
What would settle it
A direct comparison where the DKU module is ablated or replaced with random adjustments on the PASCAL-VOC dataset showing no accuracy gain would indicate the knowledge integration does not contribute.
Figures






read the original abstract
Integrating domain knowledge into deep neural networks is a promising way to improve generalization. Existing methods either encode prior knowledge in the loss function or apply post-processing modules, but both depend on identifying useful symbolic knowledge to integrate. Since such rules are often unavailable in real-world vision tasks, we propose a method for targeted knowledge discovery. We propose a Differentiable Knowledge Unit (DKU) that enables modulating the classifier logits, yielding refined class probabilities. The DKU uses implication rules to represent relationships between task classes and implicit concepts learned entirely from the main task supervision, without requiring concept labels. Concepts are identified by dedicated classifiers, whose probabilities are passed to DKU alongside the primary class probabilities. DKU computes a logic-based adjustment vector via fuzzy inference, which modulates the primary class logits to yield refined class probabilities. When concept classifiers represent concepts that do not support the logical rule structure, the resulting adjustments to the class probabilities do not directly minimize the supervision loss. Consequently, optimizing the supervision loss on these adjusted class probabilities implicitly trains the concept classifiers. We construct the rule base so that bidirectional logical relations connect concepts and classes. We enforce the concepts to be distinct from each other and with respect to the classes. This design enforces a clean supervision signal for concept learning. We evaluate our methods on the PASCAL-VOC, COCO, and MedMNIST datasets. We demonstrate improvement through our knowledge integration across these datasets. We conduct domain generalization and hard-sample ablation studies and find that our implicit knowledge discovery and integration outperforms the baseline.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a Differentiable Knowledge Unit (DKU) that modulates primary classifier logits via fuzzy inference over probabilities from implicit concept classifiers. Concepts are learned end-to-end from the main-task supervision loss applied to the DKU-adjusted class probabilities, using a hand-constructed rule base of bidirectional logical implications between classes and concepts together with a distinctness regularizer. The authors claim this yields refined probabilities that improve recognition on PASCAL-VOC, COCO, and MedMNIST, with additional gains in domain-generalization and hard-sample regimes, all without any concept-level labels.
Significance. If the implicit training dynamic can be shown to reliably induce concept representations that participate in the intended logical relations rather than arbitrary logit corrections, the approach would constitute a meaningful advance in neuro-symbolic vision methods by enabling knowledge integration when explicit symbolic rules are unavailable. The differentiable fuzzy engine and the bidirectional-plus-distinctness design are technically interesting mechanisms for closing the supervision loop. The multi-dataset evaluation and generalization ablations are appropriate for assessing practical utility.
major comments (3)
- [§3.2] §3.2 (DKU training dynamic): The assertion that 'when concept classifiers represent concepts that do not support the logical rule structure, the resulting adjustments to the class probabilities do not directly minimize the supervision loss' is load-bearing for the knowledge-discovery claim, yet no formal argument, counter-example analysis, or ablation isolating the fuzzy engine is supplied. Because the DKU implements a fixed but non-injective mapping from concept probabilities to an adjustment vector, gradient descent on the refined cross-entropy loss can in principle discover any concept-to-modulation function that numerically boosts correct-class logits, regardless of whether the concepts align with the authors' bidirectional implications.
- [§3.1] §3.1 (Rule-base construction): The rule base is described as being 'constructed so that bidirectional logical relations connect concepts and classes,' but the manuscript provides no explicit procedure, dataset-specific examples, or sensitivity analysis for how these rules are chosen. If rule selection incorporates dataset-specific domain knowledge, the method no longer discovers knowledge 'entirely from the main task supervision' and the central novelty claim is weakened.
- [§4.2] §4.2 (Domain-generalization and hard-sample ablations): The paper states that the method 'outperforms the baseline' in these regimes, yet the reported results lack (i) quantitative tables with exact metrics, standard deviations, and baseline comparisons (e.g., plain cross-entropy, other neuro-symbolic modules), (ii) description of the precise domain shifts tested, and (iii) controls that disable the fuzzy component while retaining the concept heads. Without these, the contribution of the DKU versus auxiliary capacity cannot be isolated.
minor comments (3)
- [Abstract] Abstract: The abstract asserts 'improvement through our knowledge integration' and 'outperforms the baseline' but supplies no numerical deltas, dataset-specific metrics, or baseline names. Including at least the headline accuracy or mAP gains would strengthen the summary.
- [§3] Notation in §3: The mapping from concept probabilities through the fuzzy inference engine to the final adjustment vector is described only in prose; an explicit equation (e.g., defining the t-norm, implication operator, and aggregation) would improve reproducibility and allow readers to verify differentiability.
- [§2] Related-work section: Prior differentiable fuzzy-logic and neuro-symbolic vision papers that also learn implicit predicates should be cited to clarify the precise novelty relative to existing implicit-rule approaches.
Simulated Author's Rebuttal
We thank the referee for the insightful and constructive comments, which will help strengthen the rigor and clarity of the manuscript. We address each major comment below and describe the planned revisions.
read point-by-point responses
-
Referee: [§3.2] §3.2 (DKU training dynamic): The assertion that 'when concept classifiers represent concepts that do not support the logical rule structure, the resulting adjustments to the class probabilities do not directly minimize the supervision loss' is load-bearing for the knowledge-discovery claim, yet no formal argument, counter-example analysis, or ablation isolating the fuzzy engine is supplied. Because the DKU implements a fixed but non-injective mapping from concept probabilities to an adjustment vector, gradient descent on the refined cross-entropy loss can in principle discover any concept-to-modulation function that numerically boosts correct-class logits, regardless of whether the concepts align with the authors' bidirectional implications.
Authors: We acknowledge that the non-injective mapping permits, in principle, arbitrary logit boosts. However, the fixed fuzzy-inference structure (bidirectional implications) plus the distinctness regularizer constrains which concept probability vectors can produce loss-reducing adjustments; arbitrary modulations are penalized because they fail to exploit the rule-defined fuzzy operations. We agree a formal argument and isolating ablation are missing. In revision we will add a brief theoretical sketch of the constrained optimization landscape, a counter-example analysis, and an ablation replacing the fuzzy engine with a direct MLP modulator (retaining concept heads and regularizer) to isolate the logic component. revision: partial
-
Referee: [§3.1] §3.1 (Rule-base construction): The rule base is described as being 'constructed so that bidirectional logical relations connect concepts and classes,' but the manuscript provides no explicit procedure, dataset-specific examples, or sensitivity analysis for how these rules are chosen. If rule selection incorporates dataset-specific domain knowledge, the method no longer discovers knowledge 'entirely from the main task supervision' and the central novelty claim is weakened.
Authors: We agree that explicit documentation is required. The rules are manually defined from obvious semantic implications between dataset classes and candidate concepts (e.g., 'car' ↔ 'has_wheels' for PASCAL-VOC). While this uses high-level category knowledge, no concept labels are provided; the concepts are still discovered end-to-end via the main-task loss on the DKU-adjusted probabilities. We will add to the revised manuscript: (i) a step-by-step construction procedure, (ii) the complete rule lists for each dataset in an appendix, and (iii) a sensitivity study under rule perturbations. This clarifies that rule setup is lightweight while concept discovery remains supervision-driven. revision: yes
-
Referee: [§4.2] §4.2 (Domain-generalization and hard-sample ablations): The paper states that the method 'outperforms the baseline' in these regimes, yet the reported results lack (i) quantitative tables with exact metrics, standard deviations, and baseline comparisons (e.g., plain cross-entropy, other neuro-symbolic modules), (ii) description of the precise domain shifts tested, and (iii) controls that disable the fuzzy component while retaining the concept heads. Without these, the contribution of the DKU versus auxiliary capacity cannot be isolated.
Authors: We accept that the current experimental reporting is insufficient. The revised manuscript will include: (i) full tables with mean accuracies, standard deviations over 3–5 runs, and comparisons against plain cross-entropy plus representative neuro-symbolic baselines; (ii) explicit descriptions of the domain shifts (e.g., specific corruption types or cross-dataset protocols) and hard-sample selection; (iii) control experiments that retain the concept heads and regularizer but replace fuzzy inference with a non-logical linear modulator. These additions will isolate the DKU contribution from added capacity. revision: yes
Circularity Check
No significant circularity in the derivation chain
full rationale
The paper's core mechanism defines a fixed, author-constructed rule base and a differentiable DKU module that modulates logits via fuzzy inference on concept probabilities; the concept heads receive gradients from the main classification loss applied to the modulated outputs. This is a standard end-to-end differentiable architecture rather than a self-referential loop in which any claimed result (e.g., refined probabilities or discovered concepts) is substituted back into the definition of the inputs or rules. The abstract explicitly states that the rule base is constructed by the authors and that distinctness is enforced by design; the implicit training claim follows directly from back-propagation through the fixed module and does not reduce any equation or prediction to its own fitted values by construction. Empirical results on PASCAL-VOC, COCO, and MedMNIST are reported as external validation, rendering the central claims falsifiable outside the training loop itself.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Fuzzy implication rules can represent relationships between task classes and implicit concepts
- ad hoc to paper Bidirectional logical relations plus distinctness enforcement yield a clean supervision signal for concept learning
invented entities (2)
-
Differentiable Knowledge Unit (DKU)
no independent evidence
-
Implicit concepts
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Fast algorithms for mining association rules in large databases
Rakesh Agrawal and Ramakrishnan Srikant. Fast algorithms for mining association rules in large databases. InProceed- ings of the 20th International Conference on Very Large Data Bases, page 487–499, San Francisco, CA, USA, 1994. Mor- gan Kaufmann Publishers Inc. 2, 6
1994
-
[2]
Optuna: A next-generation hyperparameter optimization framework
Takuya Akiba, Shotaro Sano, Toshihiko Yanase, Takeru Ohta, and Masanori Koyama. Optuna: A next-generation hyperparameter optimization framework. InProceedings of the 25th ACM SIGKDD International Conference on Knowl- edge Discovery and Data Mining, page 2623–2631, 2019. 6
2019
-
[3]
Logic tensor networks.Artificial In- telligence, 303:103649, 2022
Samy Badreddine, Artur d’Avila Garcez, Luciano Serafini, and Michael Spranger. Logic tensor networks.Artificial In- telligence, 303:103649, 2022. 2, 6
2022
-
[4]
Logic tensor networks for semantic image interpretation,
Ivan Donadello, Luciano Serafini, and Artur d’Avila Garcez. Logic tensor networks for semantic image interpretation,
-
[5]
The pascal visual object classes (voc) challenge.International journal of computer vision, 88(2):303–338, 2010
Mark Everingham, Luc Van Gool, Christopher KI Williams, John Winn, and Andrew Zisserman. The pascal visual object classes (voc) challenge.International journal of computer vision, 88(2):303–338, 2010. 6
2010
-
[6]
Artur d’Avila Garcez, Marco Gori, Luis C Lamb, Luciano Serafini, Michael Spranger, and Son N Tran. Neural- symbolic computing: An effective methodology for princi- pled integration of machine learning and reasoning.arXiv preprint arXiv:1905.06088, 2019. 2
work page Pith review arXiv 1905
-
[7]
Springer Sci- ence & Business Media, 2001
Petr H ´ajek.Metamathematics of fuzzy logic. Springer Sci- ence & Business Media, 2001. 4
2001
-
[8]
Mining frequent pat- terns without candidate generation
Jiawei Han, Jian Pei, and Yiwen Yin. Mining frequent pat- terns without candidate generation. InProceedings of the 2000 ACM SIGMOD International Conference on Manage- ment of Data, page 1–12, New York, NY , USA, 2000. Asso- ciation for Computing Machinery. 2
2000
-
[9]
Harnessing deep neural networks with logic rules,
Zhiting Hu, Xuezhe Ma, Zhengzhong Liu, Eduard Hovy, and Eric Xing. Harnessing deep neural networks with logic rules,
-
[10]
Concept bottleneck models
Pang Wei Koh, Thao Nguyen, Yew Siang Tang, Stephen Mussmann, Emma Pierson, Been Kim, and Percy Liang. Concept bottleneck models. InProceedings of the 37th In- ternational Conference on Machine Learning, pages 5338–
-
[11]
Logicseg: Parsing visual semantics with neural logic learning and reasoning
Liulei Li, Wenguan Wang, and Yi Yang. Logicseg: Parsing visual semantics with neural logic learning and reasoning. In Proceedings of the IEEE/CVF international conference on computer vision, pages 4122–4133, 2023. 2
2023
-
[12]
Neuro- symbolic spatial reasoning in segmentation, 2025
Jiayi Lin, Jiabo Huang, and Shaogang Gong. Neuro- symbolic spatial reasoning in segmentation, 2025. 2
2025
-
[13]
Lawrence Zitnick
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Doll´ar, and C. Lawrence Zitnick. Microsoft coco: Common objects in context. In Computer Vision – ECCV 2014, pages 740–755, Cham,
2014
-
[14]
Springer International Publishing. 6
-
[15]
Mining association rules with multiple minimum supports
Bing Liu, Wynne Hsu, and Yiming Ma. Mining association rules with multiple minimum supports. InProceedings of the Fifth ACM SIGKDD International Conference on Knowl- edge Discovery and Data Mining, page 337–341, New York, NY , USA, 1999. Association for Computing Machinery. 2
1999
-
[16]
Swin transformer v2: Scaling up capacity and resolution
Ze Liu, Han Hu, Yutong Lin, Zhuliang Yao, Zhenda Xie, Yixuan Wei, Jia Ning, Yue Cao, Zheng Zhang, Li Dong, et al. Swin transformer v2: Scaling up capacity and resolution. In Proceedings of the IEEE/CVF conference on computer vi- sion and pattern recognition, pages 12009–12019, 2022. 6
2022
-
[17]
Deepproblog: Neu- ral probabilistic logic programming
Robin Manhaeve, Sebastijan Dumancic, Angelika Kimmig, Thomas Demeester, and Luc De Raedt. Deepproblog: Neu- ral probabilistic logic programming. InAdvances in Neural Information Processing Systems (NeurIPS), 2018. 2, 5
2018
-
[18]
Faster-ltn: a neuro-symbolic, end-to- end object detection architecture
Francesco Manigrasso, Filomeno Davide Miro, Lia Morra, and Fabrizio Lamberti. Faster-ltn: a neuro-symbolic, end-to- end object detection architecture. InArtificial Neural Net- works and Machine Learning–ICANN 2021: 30th Interna- tional Conference on Artificial Neural Networks, Bratislava, Slovakia, September 14–17, 2021, Proceedings, Part II 30, pages 40–...
2021
-
[19]
Hans reichenbach
Ernest Nagel. Hans reichenbach. note on probability impli- cation. bulletin of the american mathematical society, vol. 47 (1941), pp. 265–267.Journal of Symbolic Logic, 6(2):66–66,
1941
-
[20]
Logical neural networks, 2020
Ryan Riegel, Alexander Gray, Francois Luus, Naweed Khan, Ndivhuwo Makondo, Ismail Yunus Akhalwaya, Haifeng Qian, Ronald Fagin, Francisco Barahona, Udit Sharma, Sha- jith Ikbal, Hima Karanam, Sumit Neelam, Ankita Likhyani, and Santosh Srivastava. Logical neural networks, 2020. 2
2020
-
[21]
Logic Tensor Networks: Deep Learning and Logical Reasoning from Data and Knowledge
Luciano Serafini and Artur d’Avila Garcez. Logic tensor net- works: Deep learning and logical reasoning from data and knowledge.arXiv preprint arXiv:1606.04422, 2016. 2
work page Pith review arXiv 2016
-
[22]
Knowledge-based artificial neural networks.Artificial intelligence, 70(1-2): 119–165, 1994
Geoffrey G Towell and Jude W Shavlik. Knowledge-based artificial neural networks.Artificial intelligence, 70(1-2): 119–165, 1994. 2
1994
-
[23]
Analyzing differentiable fuzzy logic operators.Artificial In- telligence, 302:103602, 2022
Emile Van Krieken, Erman Acar, and Frank Van Harmelen. Analyzing differentiable fuzzy logic operators.Artificial In- telligence, 302:103602, 2022. 4, 5
2022
-
[24]
Towards data-and knowledge-driven ai: A survey on neuro-symbolic comput- ing.IEEE Transactions on Pattern Analysis and Machine Intelligence, 47(2):878–899, 2025
Wenguan Wang, Yi Yang, and Fei Wu. Towards data-and knowledge-driven ai: A survey on neuro-symbolic comput- ing.IEEE Transactions on Pattern Analysis and Machine Intelligence, 47(2):878–899, 2025. 2
2025
-
[25]
A semantic loss function for deep learning with symbolic knowledge
Jingyi Xu, Zilu Zhang, Tal Friedman, Yitao Liang, and Guy Van den Broeck. A semantic loss function for deep learning with symbolic knowledge. InProceedings of the 35th In- ternational Conference on Machine Learning, pages 5502–
-
[26]
Ronald R. Yager. On a general class of fuzzy connectives. Fuzzy Sets and Systems, 4(3):235–242, 1980. 4
1980
-
[27]
Medm- nist v2-a large-scale lightweight benchmark for 2d and 3d biomedical image classification.Scientific Data, 10(1):41,
Jiancheng Yang, Rui Shi, Donglai Wei, Zequan Liu, Lin Zhao, Bilian Ke, Hanspeter Pfister, and Bingbing Ni. Medm- nist v2-a large-scale lightweight benchmark for 2d and 3d biomedical image classification.Scientific Data, 10(1):41,
-
[28]
Sergey Zagoruyko and Nikos Komodakis. Wide residual net- works.arXiv preprint arXiv:1605.07146, 2016. 6
work page internal anchor Pith review arXiv 2016
-
[29]
M.J. Zaki. Scalable algorithms for association mining.IEEE Transactions on Knowledge and Data Engineering, 12(3): 372–390, 2000. 2 Learning to Reason: Targeted Knowledge Discovery and Fuzzy Logic Update for Robust Image Recognition Supplementary Material
2000
-
[30]
, sT },Y: Classes{y 1,
Synthetic Rule Base Generation Algorithm 1:Constructing Rule BaseR Input:T: Number of implicit concepts,K: Target classes,S: Concepts{s 1, . . . , sT },Y: Classes{y 1, . . . , yK},l: Rules per category (i.e.concepts⇒class), andq min, qmax: min/max concept combination set size 1ProcedureMain(S, Y, l, q min, qmax) 2R a ← ∅,R b ← ∅; 3O← {s7→0| ∀s∈S}; // Phas...
-
[31]
Positive Cases Table 6 highlights the qualitative benefits of integrating the KLUE bottleneck into the WideResNet-101 (WRN-101) ar- chitecture for multi-label classification
Qualitative Results 7.1. Positive Cases Table 6 highlights the qualitative benefits of integrating the KLUE bottleneck into the WideResNet-101 (WRN-101) ar- chitecture for multi-label classification. We compare the baseline WRN-101 against two KLUE variants: the stan- dard KLUE and KLUE +L SAT . Both variants utilize WRN-101 as their backbone. The KLUE +L...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.