Recognition: unknown
WindowsWorld: A Process-Centric Benchmark of Autonomous GUI Agents in Professional Cross-Application Environments
Pith reviewed 2026-05-07 07:30 UTC · model grok-4.3
The pith
GUI agents succeed on under 21 percent of multi-application professional tasks
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
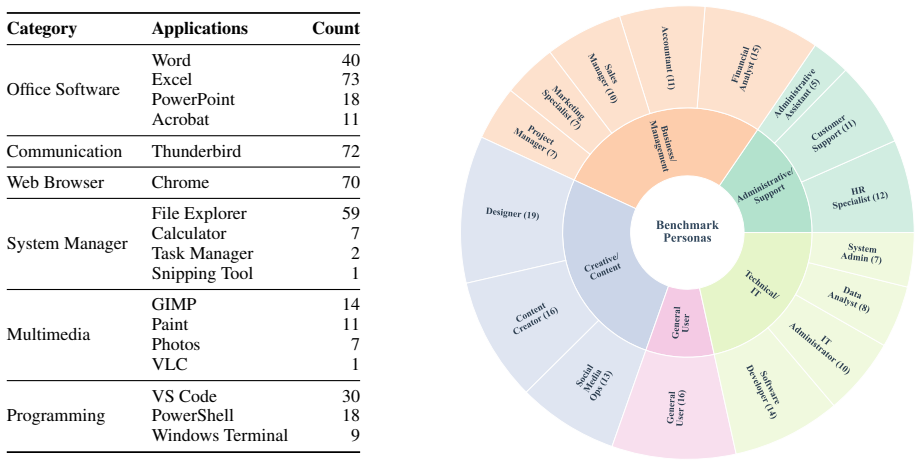
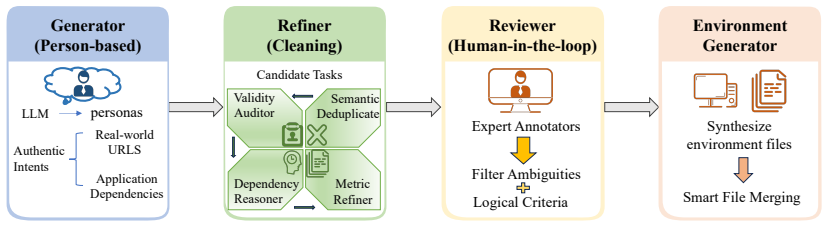
WindowsWorld is a process-centric benchmark containing 181 tasks across 17 desktop applications, of which 78 percent require coordination between multiple apps. It was constructed via a multi-agent framework steered by 16 occupations that produces four difficulty levels with intermediate inspection points, followed by human refinement and execution in a simulated environment. Evaluations of current leading GUI agents establish that they achieve success rates below 21 percent on the multi-application subset, stall at early sub-goals when conditional judgment across three or more applications is required, and follow execution paths that exceed human step counts while still failing to complete
What carries the argument
The WindowsWorld benchmark of 181 tasks, generated by a multi-agent framework steered by 16 occupations to create four difficulty levels with intermediate inspection, then refined by human review and run in a simulated environment.
If this is right
- Current agents cannot reliably complete professional workflows that require switching and reasoning between applications.
- Conditional judgment across three or more applications forms a major unsolved bottleneck for existing models.
- Execution paths must become far more efficient to approach human step counts while still succeeding.
- Single-application benchmarks give an incomplete view of agent readiness for integrated desktop work.
Where Pith is reading between the lines
- Future agent training could use the task-generation method from occupational perspectives to target coordination skills more directly.
- If agents reach higher success rates on this benchmark, that may indicate greater readiness for deployment in actual office productivity settings.
- The simulated multi-application structure could be adapted to create parallel benchmarks for other operating systems or specialized software domains.
- Persistent early stalling suggests that planning architectures may need explicit mechanisms for cross-app state tracking rather than sequential action prediction alone.
Load-bearing premise
The tasks generated by the occupation-steered multi-agent framework and refined by human review accurately mirror real-world professional cross-application workflows.
What would settle it
An independent run of the same agents on a matched set of professional tasks performed on actual physical computers, checking whether success rates stay below 21 percent and whether stalling patterns on three-plus-application tasks remain consistent with the simulated results.
Figures














read the original abstract
While GUI agents have shown impressive capabilities in common computer-use tasks such as OSWorld, current benchmarks mainly focus on isolated and single-application tasks. This overlooks a critical real-world requirement of coordinating across multiple applications to accomplish complex profession-specific workflows. To bridge this gap, we present a computer-use benchmark in cross-application workflows, named WindowsWorld, designed to systematically assess GUI Agents on complex multi-step tasks that mirror real-world professional activities. Our methodology uses a multi-agent framework steered by 16 occupations to generate four difficulty-level tasks with intermediate inspection, which are then refined by human review and executed in a simulated environment. The resulting benchmark contains 181 tasks with an average of 5.0 sub-goals across 17 common desktop applications, of which 78% are inherently multi-application. Experimental results of leading large models and agents show that: 1) All computer-use agents perform poorly on multi-application tasks (< 21% success rate), far below the performance of simple single-app tasks; 2) They largely fail at tasks requiring conditional judgment and reasoning across $\geq$ 3 applications, stalling at early sub-goals; 3) Low execution efficiency, where tasks often fail despite far exceeding human step limits. Code, benchmark data, and evaluation resources are available at github.com/HITsz-TMG/WindowsWorld.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces WindowsWorld, a benchmark of 181 tasks for GUI agents performing cross-application professional workflows in a simulated Windows environment. Tasks are generated via an LLM multi-agent framework steered by 16 occupations, with intermediate inspection and human review, yielding an average of 5.0 sub-goals across 17 applications (78% multi-application). Experiments on leading models and agents report success rates below 21% on multi-app tasks, frequent stalling on conditional reasoning across ≥3 applications, and low execution efficiency relative to human step limits. Code, data, and evaluation resources are released.
Significance. If the generated tasks accurately capture real professional cross-application workflows, the results demonstrate that current GUI agents remain far from capable of handling the coordination and conditional reasoning required in typical office settings, providing a clear empirical signal for future work on multi-app planning and state tracking. The open release of the benchmark, code, and resources is a concrete strength that supports reproducibility and community follow-up.
major comments (3)
- [§3] §3 (Benchmark Construction), Task Generation subsection: The multi-agent LLM framework with 16 occupations plus human review is presented as producing tasks that 'mirror real-world professional activities,' yet no external validation is described—no comparison against usage telemetry, no blinded ratings by practitioners outside the review team, and no ablation of how the LLM scaffolding influences sub-goal distributions or conditional-branch frequency. Because the headline claims (all agents <21% success, failure on ≥3-app conditional tasks) are only interpretable if the 181 tasks reflect genuine coordination friction, this absence is load-bearing for the central contribution.
- [§4.2] §4.2 (Evaluation Protocol) and associated tables: Exact success criteria for sub-goal completion, the precise definition of 'conditional judgment,' and the quantitative impact of human review on the final task distribution are not fully specified. Without these details it is difficult to verify the reported failure patterns or to reproduce the <21% multi-app success threshold.
- [§4.3] §4.3 (Results), breakdown by application count: The claim that agents 'largely fail at tasks requiring conditional judgment and reasoning across ≥3 applications' is supported only by aggregate statistics; a per-bucket table (2-app vs. 3-app vs. 4+-app) with success rates and early-stall rates is missing. This granularity is necessary to substantiate the specific cross-application reasoning failure mode.
minor comments (3)
- [Introduction] Introduction: The positioning relative to OSWorld and other single-app benchmarks would benefit from a short table contrasting task characteristics (single vs. multi-app, presence of conditional branches).
- [Figure 2] Figure 2 (task examples): Some UI screenshots are low-resolution; higher-resolution versions or annotated callouts would improve readability of the sub-goal sequences.
- [§5] §5 (Limitations): The discussion of simulated-environment fidelity is brief; adding a short paragraph on how Windows API state mismatches or timing differences might affect measured step counts would be useful.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback, which has helped us identify areas to strengthen the clarity, reproducibility, and substantiation of our claims. We address each major comment point by point below, proposing targeted revisions where they improve the manuscript without misrepresenting our work. We believe these changes will make the benchmark's contributions more robust.
read point-by-point responses
-
Referee: [§3] §3 (Benchmark Construction), Task Generation subsection: The multi-agent LLM framework with 16 occupations plus human review is presented as producing tasks that 'mirror real-world professional activities,' yet no external validation is described—no comparison against usage telemetry, no blinded ratings by practitioners outside the review team, and no ablation of how the LLM scaffolding influences sub-goal distributions or conditional-branch frequency. Because the headline claims (all agents <21% success, failure on ≥3-app conditional tasks) are only interpretable if the 181 tasks reflect genuine coordination friction, this absence is load-bearing for the central contribution.
Authors: We acknowledge the value of external validation for strengthening claims of realism. Our generation process relies on occupation-steered multi-agent LLM prompting followed by human review to capture professional coordination patterns, but we did not perform telemetry comparisons (due to lack of access to proprietary logs) or external blinded practitioner ratings beyond the internal team. In the revision, we will: (1) expand §3 with a detailed description of the human review protocol, reviewer expertise, and inter-reviewer consistency; (2) add an ablation comparing LLM scaffolding variants on sub-goal and conditional-branch statistics; and (3) include a limitations paragraph explicitly noting the absence of telemetry validation while outlining plans for future practitioner surveys. These additions address the concern directly while preserving the existing task set. revision: partial
-
Referee: [§4.2] §4.2 (Evaluation Protocol) and associated tables: Exact success criteria for sub-goal completion, the precise definition of 'conditional judgment,' and the quantitative impact of human review on the final task distribution are not fully specified. Without these details it is difficult to verify the reported failure patterns or to reproduce the <21% multi-app success threshold.
Authors: We agree that precise specifications are necessary for reproducibility. In the revised manuscript, we will expand §4.2 to include: (1) formal success criteria for sub-goal completion based on simulator state checks (e.g., exact UI element presence, file system changes, and application output matching); (2) a clear definition of 'conditional judgment' as sub-goals requiring dynamic if-then evaluation of cross-application states; and (3) quantitative statistics on human review effects, such as the fraction of tasks revised (approximately 35%), categories of modifications (e.g., added conditionals), and agreement rates. Examples and pseudocode will be added to allow exact reproduction of the reported success rates. revision: yes
-
Referee: [§4.3] §4.3 (Results), breakdown by application count: The claim that agents 'largely fail at tasks requiring conditional judgment and reasoning across ≥3 applications' is supported only by aggregate statistics; a per-bucket table (2-app vs. 3-app vs. 4+-app) with success rates and early-stall rates is missing. This granularity is necessary to substantiate the specific cross-application reasoning failure mode.
Authors: We appreciate this recommendation for greater granularity. We will add a new table in §4.3 (Table 4) providing a breakdown by application count: success rates, average steps, early-stall rates (failures before 50% sub-goals), and conditional judgment failure percentages for 2-app, 3-app, and 4+-app buckets. The experimental data already supports this analysis, and we will include a short discussion of the observed performance drop for tasks with ≥3 applications to better substantiate the cross-application reasoning failure mode. revision: yes
Circularity Check
No circularity: direct empirical measurements on new benchmark
full rationale
The paper constructs WindowsWorld via a multi-agent LLM framework steered by 16 occupations plus human review, then reports raw success rates of existing GUI agents on the resulting 181 tasks. No equations, fitted parameters, predictions, or derivations appear in the abstract or described methodology. Claims such as '<21% success rate' on multi-application tasks are direct experimental outcomes on the defined benchmark, not reductions of any output to the generation process by construction. No self-citations are invoked as load-bearing uniqueness theorems or ansatzes. The derivation chain is therefore self-contained empirical reporting; concerns about real-world fidelity of the generated tasks affect external validity but do not constitute circularity per the specified patterns.
Axiom & Free-Parameter Ledger
free parameters (3)
- Number of occupations
- Difficulty levels
- Application set
axioms (2)
- domain assumption A multi-agent framework steered by occupation descriptions can generate realistic professional tasks.
- domain assumption Human review after generation sufficiently ensures task quality and realism.
Reference graph
Works this paper leans on
-
[1]
The unsolved challenges of LLMs as general- ist web agents: A case study . In Proc. of the 37th Int. Conf. on NeurIPS: F oundation Models for Decision Making Workshop, New Orleans, LA, USA. Curran Associates, Inc. Shuai Bai, Y uxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, and 1 others. 2025. Qwen3-vl t...
work page internal anchor Pith review arXiv 2025
-
[2]
GUI-WORLD: A dataset for GUI-oriented multimodal LLM-based agents. arXiv preprint. Jingxuan Chen, Derek Y uen, Bin Xie, Y uhao Y ang, Gongwei Chen, Zhihao Wu, Li Yixing, Xurui Zhou, Weiwen Liu, Shuai Wang, Kaiwen Zhou, Rui Shao, Liqiang Nie, Y asheng Wang, Jianye HAO, Jun Wang, and Kun Shao. 2025. Spa-bench: A com- prehensive benchmark for smartphone agen...
-
[3]
Springer. Jing Y u Koh, Robert Lo, Lawrence Jang, Vikram Duvvur, Ming Lim, Po-Y u Huang, Graham Neu- big, Shuyan Zhou, Russ Salakhutdinov, and Daniel Fried. 2024. Visualwebarena: Evaluating multi- modal agents on realistic visual web tasks. In Pro- ceedings of the 62nd Annual Meeting of the Associa- tion for Computational Linguistics (V olume 1: Long Pape...
-
[4]
arXiv preprint arXiv:2511.04307
Gui-360: A comprehensive dataset and bench- mark for computer-using agents. arXiv preprint arXiv:2511.04307. Y ujia Qin, Yining Y e, Junjie Fang, Haoming Wang, Shihao Liang, Shizuo Tian, Junda Zhang, Jiahao Li, 10 Y unxin Li, Shijue Huang, and 1 others. 2025. Ui- tars: Pioneering automated gui interaction with na- tive agents. arXiv preprint arXiv:2501.12...
-
[5]
Set-of-Mark Prompting Unleashes Extraordinary Visual Grounding in GPT-4V
Osworld: Benchmarking multimodal agents for open-ended tasks in real computer environments. Advances in Neural Information Processing Systems, 37:52040–52094. Jianwei Y ang, Hao Zhang, Feng Li, Xueyan Zou, Chun- yuan Li, and Jianfeng Gao. 2023. Set-of-mark prompting unleashes extraordinary visual grounding in gpt-4v. arXiv preprint arXiv:2310.11441. Leyan...
work page internal anchor Pith review arXiv 2023
-
[6]
arXiv preprint arXiv:2511.09157
Probench: Benchmarking gui agents with accurate process information. arXiv preprint arXiv:2511.09157. Shunyu Y ao, Howard Chen, John Y ang, and Karthik Narasimhan. 2022. Webshop: Towards scalable real-world web interaction with grounded language agents. Advances in Neural Information Processing Systems, 35:20744–20757. Henry Hengyuan Zhao, Kaiming Y ang, ...
-
[7]
WebArena: A Realistic Web Environment for Building Autonomous Agents
Webarena: A realistic web environment for building autonomous agents. arXiv preprint arXiv:2307.13854. A Details of WindowsWorld Environment A.1 Observation Modalities Diverging from prior works that rely on text-only (A11y) settings, we strictly focus on vision-centric modalities. This approach addresses the limita- tions of structural metadata, which is...
work page internal anchor Pith review arXiv 2024
-
[8]
success_criterion: Concise success determination description
-
[9]
intermediate_checks: List of intermediate state checkpoints (retain and optimize original content)
-
[10]
assertions: List of programmable assertions (using pseudo-code function format)
-
[11]
path/to/file.xlsx
expected_final_state: Expected final system state Assertion Function Examples: • file_exists("path/to/file.xlsx") - Check if file exists • file_contains("file.xlsx", "keyword") - Check file content • window_active("Application Name") - Check if window is active • email_sent_to("recipient@email.com") - Check email sent • clipboard_contains("text") - Check ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.