Recognition: unknown
RuC: HDL-Agnostic Rule Completion Benchmark Generation
Pith reviewed 2026-05-07 08:10 UTC · model grok-4.3
The pith
A grammar-driven framework automatically generates code-completion benchmarks for hardware languages at any chosen level of detail.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
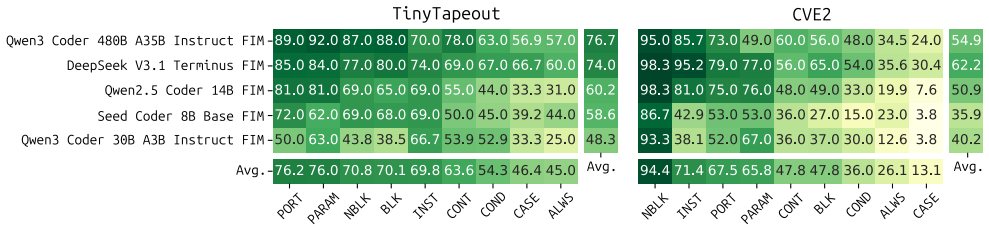
RuC is a language-agnostic benchmark generator that parses HDL source according to its grammar, selects syntactic rules to mask entire code regions, and forms prompt-completion pairs in which a model must reconstruct the masked region from the unmasked context. When applied to SystemVerilog sources from the TT07 shuttle and the CVE2 core, the resulting tasks reveal that completion performance depends on model type, the grammatical structure being completed, and the prompting strategy, with fill-in-the-middle prompting producing the highest scores across the tested models.
What carries the argument
Grammar-driven rule masking, which uses the target HDL grammar to locate and remove syntactically complete code regions, thereby turning existing designs into graded completion tasks of controllable size and syntactic scope.
If this is right
- Completion tasks can be produced at any chosen granularity from single statements to entire blocks.
- The same generator works for any HDL that supplies a formal grammar, without manual task creation.
- Accuracy is shown to depend strongly on the grammatical category of the masked region.
- Fill-in-the-middle prompting outperforms left-to-right and other common strategies on these tasks.
Where Pith is reading between the lines
- Design teams could use RuC scores to choose which model to integrate into their specific RTL workflow based on the syntax they use most often.
- Adding functional or timing verification to the generated completions would turn RuC from a syntax probe into a fuller test of design correctness.
- The method could be run repeatedly on successive versions of a design to track how model assistance improves as the project matures.
Load-bearing premise
Masking regions according to the HDL grammar alone produces completion tasks whose difficulty matches the syntactic and semantic challenges that arise in actual RTL design work.
What would settle it
A direct comparison in which models that score highly on RuC tasks nevertheless fail to produce functionally correct RTL modules when given comparable partial designs from the same source projects would show that the benchmarks do not measure useful code-understanding ability.
Figures




read the original abstract
Large Language Models (LLMs) have rapidly improved in performance across code-related tasks, making their integration into Register Transfer Level (RTL) development increasingly attractive. Mimicking the behavior of inline code assistants, many benchmarks evaluate LLMs' capabilities in code completion, either assessing the generation of entire hardware modules or the completion of a single line within a module. However both of these approaches lack the ability to control the granularity of the code-completion sample size and the syntactic range of completions. To overcome these limitations, we present a framework for language-agnostic rule completion (RuC), a grammar-driven, rule-selectable benchmark generator that automatically produces RTL code-completion tasks from a set of input hardware description sources. RuC uses the target Hardware Description Language (HDL) grammar to mask syntactically defined code regions and prompts a model to regenerate them using the surrounding unmasked code as context, enabling a controlled and scalable evaluation of the domain-specific model's code-understanding capabilities, ranging from assignments to the reconstruction of entire logic blocks. We use RuC to generate two SystemVerilog rule-completion benchmarks from the Tiny Tapeout shuttle TT07 and the CVE2 RISC-V core to demonstrate RuC's applicability to a broad range of designs, and conduct a comparative study of the code completion capabilities of modern open-source LLMs across diverse settings. Results indicate that completion performance strongly depends on the model type, the grammatical structure of the masked region, and the prompting strategy. Specifically, the highest scores are obtained with Fill-in-the-Middle (FIM) prompting. These findings highlight the value of grammar-driven, arbitrarily granular benchmarks for meaningful evaluation of LLM capabilities in RTL development workflows.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents RuC, a grammar-driven, rule-selectable benchmark generator for RTL code-completion tasks in HDLs. It uses the target HDL grammar to mask syntactically defined code regions from input designs like Tiny Tapeout TT07 and CVE2 RISC-V core, then prompts LLMs to regenerate the masked parts from surrounding context. The work generates two SystemVerilog benchmarks and conducts a comparative study of open-source LLMs, finding that completion performance depends on model type, grammatical structure of the masked region, and prompting strategy, with highest scores from Fill-in-the-Middle (FIM) prompting.
Significance. If the generated tasks indeed evaluate code-understanding capabilities as claimed, RuC offers a valuable, scalable, and controllable method for benchmarking LLMs in hardware design, overcoming limitations of existing benchmarks that lack granularity control. The use of real-world designs and grammar-based approach provides a foundation for more meaningful evaluations in RTL development workflows. The paper also demonstrates applicability across designs and highlights the importance of prompting strategies.
major comments (3)
- [Abstract] Abstract: The central claim that RuC enables 'controlled and scalable evaluation of the domain-specific model's code-understanding capabilities' lacks supporting evidence or validation. Specifically, there is no analysis showing that grammar-based masking produces tasks requiring non-local semantic reasoning (e.g., signal dependencies, timing) rather than local syntactic patterns or grammar rules.
- [Experimental results] Experimental results (as summarized): The abstract reports comparative results on model performance but provides no details on experimental methodology, statistical analysis, benchmark validation, error handling, or how the masking rules were selected. This makes it difficult to assess the reliability of claims about performance dependencies on model type, structure, and prompting.
- [Benchmark generation description] Benchmark generation description: While the framework relies on external HDL grammars and public designs, there is no discussion or empirical check (e.g., expert ratings or comparison to manual completion tasks) to confirm that the masked regions are representative of real-world RTL challenges, as opposed to being solvable via surface-level syntax.
minor comments (2)
- [Abstract] The abstract mentions 'language-agnostic' but all examples are SystemVerilog; clarify if the grammar-driven approach has been tested on other HDLs like VHDL.
- [Abstract] Consider adding a brief mention of the number of generated tasks or specific metrics used in the comparative study for better context.
Simulated Author's Rebuttal
We thank the referee for the constructive and positive review, which highlights both the potential of RuC and areas where additional evidence would strengthen the claims. We address each major comment below with clarifications from the full manuscript and proposed revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that RuC enables 'controlled and scalable evaluation of the domain-specific model's code-understanding capabilities' lacks supporting evidence or validation. Specifically, there is no analysis showing that grammar-based masking produces tasks requiring non-local semantic reasoning (e.g., signal dependencies, timing) rather than local syntactic patterns or grammar rules.
Authors: We acknowledge that the abstract's phrasing would benefit from more direct support. The full manuscript shows that performance varies substantially with the grammatical category of the masked region and with prompting strategy (FIM outperforming others), which would be unexpected for purely local syntactic completion. To provide explicit evidence of non-local reasoning, we will add a qualitative analysis subsection with concrete examples drawn from the Tiny Tapeout and CVE2 benchmarks. These examples will highlight masked regions whose correct completion requires tracking signal dependencies or timing relationships across the surrounding context, rather than local grammar rules alone. We will also note the grammar productions selected to target such structures. revision: partial
-
Referee: [Experimental results] Experimental results (as summarized): The abstract reports comparative results on model performance but provides no details on experimental methodology, statistical analysis, benchmark validation, error handling, or how the masking rules were selected. This makes it difficult to assess the reliability of claims about performance dependencies on model type, structure, and prompting.
Authors: The full manuscript (Sections 3 and 4) already describes the grammar-driven masking process, the specific SystemVerilog productions used for rule selection, the open-source models evaluated, the prompting variants (including FIM), and the exact benchmark sizes generated from TT07 and CVE2. However, the abstract is overly concise and the results section would benefit from greater statistical transparency. In revision we will (1) expand the abstract to reference the methodology, (2) report standard deviations and confidence intervals across repeated prompt samplings, (3) add an error-analysis breakdown of common failure modes, and (4) include a supplementary table listing the distribution of selected masking rules and their frequencies. These additions will allow readers to better judge the reliability of the reported performance dependencies. revision: yes
-
Referee: [Benchmark generation description] Benchmark generation description: While the framework relies on external HDL grammars and public designs, there is no discussion or empirical check (e.g., expert ratings or comparison to manual completion tasks) to confirm that the masked regions are representative of real-world RTL challenges, as opposed to being solvable via surface-level syntax.
Authors: We agree that an empirical check of representativeness would increase confidence in the benchmark's relevance. The current work already starts from two publicly available, industrially relevant designs and applies grammar rules that produce syntactically valid but context-dependent completions. To address the referee's concern directly, we will add a new subsection that (a) maps the chosen grammar productions to typical RTL coding patterns (state machines, datapaths, interface logic) and (b) reports a manual inspection of a random sample of 50 generated tasks, classifying each by the dominant reasoning type required (local syntax versus cross-signal or timing dependencies). While a full expert-rating study lies outside the scope of this revision, the added analysis will provide initial evidence that the tasks align with real-world HDL challenges rather than surface syntax alone. revision: partial
Circularity Check
No circularity: RuC is an explicit grammar-based benchmark generator using external inputs
full rationale
The paper defines RuC as a procedure that takes HDL grammars and source designs (TT07, CVE2) as inputs, applies syntactic masking to produce completion tasks, and then empirically measures LLM performance on those tasks. No equations, fitted parameters, or first-principles derivations appear; results are direct outputs of applying the described procedure to public designs and open models. The method is self-contained against external benchmarks and grammars, with no load-bearing self-citations or reductions of claims to their own definitions. The reader's noted assumption about task representativeness is an empirical question, not a circularity in the derivation chain.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The grammar of the target HDL can be used to precisely identify and mask syntactically meaningful code regions for completion tasks.
invented entities (1)
-
RuC benchmark generator
no independent evidence
Reference graph
Works this paper leans on
-
[1]
A survey on large language models for code generation,
J. Jiang, F. Wang, J. Shen, S. Kim, and S. Kim, “A survey on large language models for code generation,”ACM Trans. Softw. Eng. Methodol., vol. 35, no. 2, Jan. 2026. [Online]. Available: https://doi.org/10.1145/3747588
-
[2]
J. Pan, G. Zhou, C.-C. Chang, I. Jacobson, J. Hu, and Y . Chen, “A survey of research in large language models for electronic design automation,”ACM Trans. Des. Autom. Electron. Syst., vol. 30, no. 3, Feb. 2025. [Online]. Available: https://doi.org/10.1145/3715324
-
[3]
Large language models for eda: Future or mirage?
Z. He, Y . Pu, H. Wu, T. Qiu, and B. Yu, “Large language models for eda: Future or mirage?”ACM Trans. Des. Autom. Electron. Syst., vol. 30, no. 6, Oct. 2025. [Online]. Available: https://doi.org/10.1145/3736167
-
[4]
Large language models (llms) for verification, testing, and design,
C. K. Jha, M. Hassan, K. Qayyum, S. Ahmadi-Pour, K. Xu, R. Qiu, J. Blocklove, L. Collini, A. Nakkab, U. Schlichtmann, G. Li Zhang, R. Karri, B. Li, S. Garg, and R. Drechsler, “Large language models (llms) for verification, testing, and design,” in2025 IEEE European Test Symposium (ETS), 2025, pp. 1–10
2025
-
[5]
Large language models (llms) for electronic design automation (eda),
K. Xu, D. Schwachhofer, J. Blocklove, I. Polian, P. Domanski, D. Pfl ¨uger, S. Garg, R. Karri, O. Sinanoglu, J. Knechtel, Z. Zhao, U. Schlichtmann, and B. Li, “Large language models (llms) for electronic design automation (eda),” 2025. [Online]. Available: https://arxiv.org/abs/2508.20030
-
[6]
Rtl-repo: A benchmark for evaluating llms on large-scale rtl design projects,
A. Allam and M. Shalan, “Rtl-repo: A benchmark for evaluating llms on large-scale rtl design projects,” pp. 1–5, 2024
2024
-
[7]
Notsotiny: A large, living benchmark for rtl code generation,
R. M. Ghorab, E. Parisi, C. Gutierrez, M. Alberti-Binimelis, M. Moreto, D. Garcia-Gasulla, and G. Kestor, “Notsotiny: A large, living benchmark for rtl code generation,” 2025. [Online]. Available: https://arxiv.org/abs/2512.20823
-
[8]
Verilogeval: Evaluating large language models for verilog code generation,
M. Liu, N. Pinckney, B. Khailany, and H. Ren, “Verilogeval: Evaluating large language models for verilog code generation,” in2023 IEEE/ACM International Conference on Computer Aided Design (ICCAD). IEEE, 2023, pp. 1–8
2023
-
[9]
N. Pinckney, C. Deng, C.-T. Ho, Y .-D. Tsai, M. Liu, W. Zhou, B. Khailany, and H. Ren, “Comprehensive verilog design problems: A next-generation benchmark dataset for evaluating large language models and agents on rtl design and verification,” 2025. [Online]. Available: https://arxiv.org/abs/2506.14074 2https://github.com/HPAI-BSC/RuC 3https://huggingface...
-
[10]
Turtle: A unified evaluation of llms for rtl generation,
D. Garcia-Gasulla, G. Kestor, E. Parisi, M. Albert ´ı-Binimelis, C. Gutier- rez, R. M. Ghorab, O. Montenegro, B. Homs, and M. Moreto, “Turtle: A unified evaluation of llms for rtl generation,” in2025 ACM/IEEE 7th Symposium on Machine Learning for CAD (MLCAD), 2025, pp. 1–12
2025
-
[11]
Available: https://tinytapeout.com/
(2026) Tinytapeout :: Quicker, easier and cheaper to make your own chip! [Online]. Available: https://tinytapeout.com/
2026
-
[12]
Slow and steady wins the race? a comparison of ultra-low-power risc-v cores for internet-of-things applications,
P. Davide Schiavone, F. Conti, D. Rossi, M. Gautschi, A. Pullini, E. Fla- mand, and L. Benini, “Slow and steady wins the race? a comparison of ultra-low-power risc-v cores for internet-of-things applications,” in 2017 27th International Symposium on Power and Timing Modeling, Optimization and Simulation (PATMOS), 2017, pp. 1–8
2017
-
[13]
J. E. Hopcroft, R. Motwani, and J. D. Ullman,Introduction to Automata Theory, Languages, and Computation. Pearson, 2012
2012
-
[14]
Incoder: A generative model for code infilling and synthesis,
D. Fried, A. Aghajanyan, J. Lin, S. Wang, E. Wallace, F. Shi, R. Zhong, S. Yih, L. Zettlemoyer, and M. Lewis, “Incoder: A generative model for code infilling and synthesis,” inThe Eleventh International Conference on Learning Representations, 2023. [Online]. Available: https://openreview.net/forum?id=hQwb-lbM6EL
2023
-
[15]
Efficient training of language models to fill in the middle
M. Bavarian, H. Jun, N. Tezak, J. Schulman, C. McLeavey, J. Tworek, and M. Chen, “Efficient training of language models to fill in the middle,” 2022. [Online]. Available: https://arxiv.org/abs/2207.14255
-
[16]
Temporal induction by incremental sat solving,
N. E ´en and N. S ¨orensson, “Temporal induction by incremental sat solving,”Electronic Notes in Theoretical Computer Science, vol. 89, no. 4, pp. 543–560, 2003, bMC’2003, First International Workshop on Bounded Model Checking. [Online]. Available: https: //www.sciencedirect.com/science/article/pii/S1571066105825423
2003
-
[17]
Ll(*): the foundation of the antlr parser generator,
T. Parr and K. Fisher, “Ll(*): the foundation of the antlr parser generator,” inProceedings of the 32nd ACM SIGPLAN Conference on Programming Language Design and Implementation, ser. PLDI ’11. New York, NY , USA: Association for Computing Machinery, 2011, p. 425–436. [Online]. Available: https://doi.org/10.1145/1993498.1993548
-
[18]
Yosys-a free Verilog synthesis suite,
C. Wolf, J. Glaser, and J. Kepler, “Yosys-a free Verilog synthesis suite,” inProceedings of the 21st Austrian Workshop on Microelectronics (Austrochip), vol. 97, 2013
2013
-
[19]
Z. Sun, C. Yang, C. Peng, P. Gao, X. Du, L. Li, and D. Lo, “Bridging developer instructions and code completion through instruction-aware fill-in-the-middle paradigm,”CoRR, vol. abs/2509.24637, September
-
[20]
[Online]. Available: https://doi.org/10.48550/arXiv.2509.24637
-
[21]
Verigen: A large language model for verilog code generation,
S. Thakur, B. Ahmad, H. Pearce, B. Tan, B. Dolan-Gavitt, R. Karri, and S. Garg, “Verigen: A large language model for verilog code generation,” ACM Transactions on Design Automation of Electronic Systems, vol. 29, no. 3, pp. 1–31, 2024
2024
-
[22]
Rtllm: An open-source benchmark for design rtl generation with large language model,
Y . Lu, S. Liu, Q. Zhang, and Z. Xie, “Rtllm: An open-source benchmark for design rtl generation with large language model,” in2024 29th Asia and South Pacific Design Automation Conference (ASP-DAC). IEEE, 2024, pp. 722–727
2024
-
[23]
Codescore: Evaluating code generation by learning code execution,
Y . Dong, J. Ding, X. Jiang, G. Li, Z. Li, and Z. Jin, “Codescore: Evaluating code generation by learning code execution,”ACM Trans. Softw. Eng. Methodol., vol. 34, no. 3, Feb. 2025. [Online]. Available: https://doi.org/10.1145/3695991
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.