Recognition: unknown
Machine Unlearning for Class Removal through SISA-based Deep Neural Network Architectures
Pith reviewed 2026-05-07 06:58 UTC · model grok-4.3
The pith
A modified SISA framework with reinforced replay and gating enables CNNs to unlearn specific classes without full retraining.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
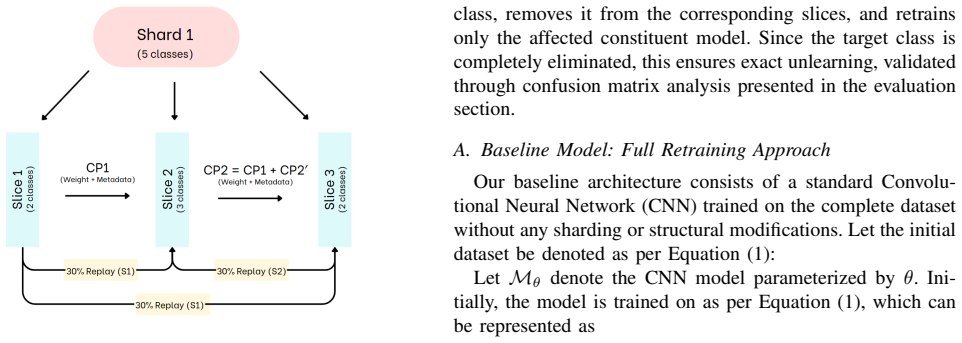
The authors present a modified SISA architecture for class-level machine unlearning in CNNs. By incorporating a reinforced replay mechanism and a gating network, the framework shards training data, isolates class contributions, and selectively forgets specified classes. Experimental results across image datasets demonstrate that this enables effective removal of class-specific knowledge while preserving overall model performance on retained classes and substantially reducing the computational cost of retraining.
What carries the argument
Modified SISA framework augmented with a reinforced replay mechanism and gating network that isolates and selectively erases class contributions in CNN training.
If this is right
- Class removal requests can be handled by updating only affected shards instead of full retraining.
- Model accuracy on retained classes stays close to the original level after unlearning.
- Computational overhead drops compared with retraining from scratch across tested CNNs.
- The method scales to multiple standard image datasets without architecture-specific redesign.
Where Pith is reading between the lines
- The same isolation principle could be tested on sequential data or non-image modalities if the replay and gating components are adapted.
- Combining this SISA variant with other forgetting techniques might further lower the cost of repeated unlearning operations.
- Deployment in regulated environments would still require checking whether the gating network fully prevents leakage of the removed class in edge cases.
Load-bearing premise
The reinforced replay and gating components can remove class-specific knowledge without causing unintended accuracy loss on the classes that should remain.
What would settle it
Measure accuracy on the unlearned class after the procedure; if it remains high or if accuracy on retained classes drops noticeably below the original model, the selective unlearning claim would fail.
Figures







read the original abstract
The rapid proliferation of image generation models and other artificial intelligence (AI) systems has intensified concerns regarding data privacy and user consent. As the availability of public datasets declines, major technology companies increasingly rely on proprietary or private user data for model training, raising ethical and legal challenges when users request the deletion of their data after it has influenced a trained model. Machine unlearning seeks to address this issue by enabling the removal of specific data from models without complete retraining. This study investigates a modified SISA (Sharded, Isolated, Sliced, and Aggregated) framework designed to achieve class-level unlearning in Convolutional Neural Network (CNN) architectures. The proposed framework incorporates a reinforced replay mechanism and a gating network to enhance selective forgetting efficiency. Experimental evaluations across multiple image datasets and CNN configurations demonstrate that the modified SISA approach enables effective class unlearning while preserving model performance and reducing retraining overhead. The findings highlight the potential of SISA-based unlearning for deployment in privacy-sensitive AI applications. The implementation is publicly available at https://github.com/SiamFS/ sisa-class-unlearning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a modified SISA (Sharded, Isolated, Sliced, and Aggregated) framework for class-level machine unlearning in CNNs. It augments standard SISA with a reinforced replay mechanism and a gating network to selectively erase a target class while preserving accuracy on retained classes and lowering retraining cost. Experiments across multiple image datasets and CNN architectures are claimed to demonstrate effective unlearning with maintained performance.
Significance. If the reinforced replay and gating components provably isolate and remove class-specific representations without leakage or unintended degradation, the method would supply a practical, shard-based alternative to full retraining for privacy compliance. The public GitHub implementation is a clear strength that supports reproducibility. However, the current evaluation, which relies primarily on accuracy retention/drop, does not yet establish that class knowledge has been erased from internal features, limiting the immediate significance for privacy-sensitive applications.
major comments (3)
- [Experimental evaluations] Experimental section: unlearning effectiveness is assessed solely via top-1 accuracy on the removed class versus retained classes. This metric does not confirm erasure of class-specific knowledge; internal representations may still encode the class (detectable by linear probes on penultimate features or loss-based membership inference attacks). The central claim that the replay+gating mechanism truly isolates the target class therefore rests on an unverified assumption.
- [Proposed framework] Method description of reinforced replay and gating network: replay strength and gating threshold are free parameters whose selection is not accompanied by ablation studies or sensitivity analysis. Without such controls, it is unclear whether performance preservation on retained classes is robust or the result of dataset-specific tuning, weakening the claim of reduced retraining overhead relative to vanilla SISA.
- [Experiments] Comparison and baseline section: the paper reports results on multiple CNNs and datasets but does not include quantitative comparisons against other class-unlearning baselines (e.g., gradient-ascent unlearning or simple fine-tuning on retained data). This omission makes it difficult to isolate the contribution of the replay+gating additions.
minor comments (2)
- [Abstract] Abstract: states positive outcomes but supplies no numerical results, effect sizes, or baseline comparisons, which is atypical for an empirical study and hinders quick assessment of the claims.
- [Abstract] GitHub link in abstract contains a space: 'https://github.com/SiamFS/ sisa-class-unlearning'. Correct to 'https://github.com/SiamFS/sisa-class-unlearning'.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. The comments identify key areas where additional evidence would strengthen the claims regarding unlearning effectiveness, robustness, and comparative performance. We have revised the manuscript to incorporate the suggested evaluations, ablations, and baselines. Point-by-point responses follow.
read point-by-point responses
-
Referee: Experimental section: unlearning effectiveness is assessed solely via top-1 accuracy on the removed class versus retained classes. This metric does not confirm erasure of class-specific knowledge; internal representations may still encode the class (detectable by linear probes on penultimate features or loss-based membership inference attacks). The central claim that the replay+gating mechanism truly isolates the target class therefore rests on an unverified assumption.
Authors: We agree that top-1 accuracy alone is an indirect proxy and does not rigorously confirm the removal of class-specific information from internal representations. This is a substantive limitation in the original evaluation for privacy-focused claims. In the revised manuscript we have added linear probing experiments on penultimate-layer features to measure residual class detectability, along with membership-inference attack success rates (both loss-based and shadow-model variants) on the target class. The new results show that the reinforced-replay plus gating approach reduces probe accuracy and attack success on the removed class to near-random levels while preserving retained-class performance, providing stronger empirical support for isolation. These additions appear in the updated Experimental Evaluations section with corresponding figures and tables. revision: yes
-
Referee: Method description of reinforced replay and gating network: replay strength and gating threshold are free parameters whose selection is not accompanied by ablation studies or sensitivity analysis. Without such controls, it is unclear whether performance preservation on retained classes is robust or the result of dataset-specific tuning, weakening the claim of reduced retraining overhead relative to vanilla SISA.
Authors: We acknowledge that the original manuscript presented replay strength and gating threshold as selected values without systematic sensitivity analysis. In the revision we have added a dedicated ablation subsection that sweeps replay strength over [0.1, 0.5, 1.0] and gating threshold over [0.3, 0.5, 0.7] on all three datasets and both CNN architectures. The results demonstrate that accuracy on retained classes remains stable within a broad operating range and that the computational savings relative to vanilla SISA are consistent across these settings. We also report the specific values used in the main experiments together with the selection criterion (validation-set trade-off between unlearning and retention). This material is now included in the revised Method and Experiments sections. revision: yes
-
Referee: the paper reports results on multiple CNNs and datasets but does not include quantitative comparisons against other class-unlearning baselines (e.g., gradient-ascent unlearning or simple fine-tuning on retained data). This omission makes it difficult to isolate the contribution of the replay+gating additions.
Authors: We agree that direct quantitative comparisons to established class-unlearning baselines would better isolate the benefit of the replay and gating components. The revised manuscript now includes two additional baselines: (1) gradient-ascent unlearning applied to the target class and (2) fine-tuning on the retained data only. We report unlearning effectiveness (target-class accuracy drop), retained-class accuracy, and wall-clock retraining cost for all methods under identical hardware and data-partition settings. The results show that the proposed SISA variant achieves a more favorable accuracy–cost trade-off than the two baselines while requiring substantially less retraining than full retraining from scratch. These comparisons are presented in a new table in the Experiments section. revision: yes
Circularity Check
No circularity: purely empirical proposal with experimental validation only
full rationale
The manuscript proposes a modified SISA architecture augmented with a reinforced replay mechanism and gating network for class-level unlearning in CNNs. All load-bearing claims rest on experimental results across image datasets and CNN configurations (accuracy on retained vs. removed classes, retraining overhead). No equations, derivations, or predictions appear that reduce by construction to fitted parameters or self-citations; the framework is presented as an engineering modification whose effectiveness is measured directly rather than derived from prior self-referential results. The work is therefore self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
free parameters (2)
- Shard count
- Replay strength / gating threshold
axioms (2)
- domain assumption Sharded training isolates class information sufficiently that only affected shards need updating
- ad hoc to paper Replay plus gating can maintain performance on retained classes while erasing the target class
invented entities (2)
-
Reinforced replay mechanism
no independent evidence
-
Gating network
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Machine learning and games,
M. Bowling, J. F ¨urnkranz, T. Graepel, and R. Musick, “Machine learning and games,”Machine Learning, vol. 63, pp. 211–215, 2006
2006
-
[2]
Deep learning,
Y . LeCun, Y . Bengio, and G. Hinton, “Deep learning,”Nature, vol. 521, no. 7553, pp. 436–444, 2015
2015
-
[3]
A survey of convo- lutional neural networks: Analysis, applications, and prospects,
Z. Li, F. Liu, W. Yang, S. Peng, and J. Zhou, “A survey of convo- lutional neural networks: Analysis, applications, and prospects,”IEEE Transactions on Neural Networks and Learning Systems, vol. 33, pp. 6999–7019, 2020
2020
-
[4]
Avoiding overfitting: A survey on regu- larization methods for convolutional neural networks,
C. F. G. Santos and J. Papa, “Avoiding overfitting: A survey on regu- larization methods for convolutional neural networks,”ACM Computing Surveys (CSUR), vol. 54, pp. 1 – 25, 2022
2022
-
[5]
Towards making systems forget with machine unlearning,
Y . Cao and J. Yang, “Towards making systems forget with machine unlearning,” in2015 IEEE Symposium on Security and Privacy, 2015, pp. 463–480
2015
-
[6]
The partial information decomposition of generative neural network models,
T. M. S. Tax, P. Mediano, and M. Shanahan, “The partial information decomposition of generative neural network models,”Entropy, vol. 19, p. 474, 2017
2017
-
[7]
Machine unlearning,
L. Bourtoule, V . Chandrasekaran, C. A. Choquette-Choo, H. Jia, A. Travers, B. Zhang, D. Lie, and N. Papernot, “Machine unlearning,” in2021 IEEE Symposium on Security and Privacy (SP), 2021, pp. 141– 159
2021
-
[8]
Membership Inference Attacks against Machine Learning Models
R. Shokri, M. Stronati, C. Song, and V . Shmatikov, “Membership inference attacks against machine learning models,” 2017. [Online]. Available: https://arxiv.org/abs/1610.05820
work page Pith review arXiv 2017
-
[9]
Scaling laws for autoregressive generative modeling,
T. Henighan, J. Kaplan, M. Katz, M. Chen, C. Hesse, J. Jackson, H. Jun, T. B. Brown, P. Dhariwal, S. Gray, C. Hallacy, B. Mann, A. Radford, A. Ramesh, N. Ryder, D. M. Ziegler, J. Schulman, D. Amodei, and S. McCandlish, “Scaling laws for autoregressive generative modeling,”
-
[10]
Scaling Laws for Autoregressive Generative Modeling
[Online]. Available: https://arxiv.org/abs/2010.14701
work page internal anchor Pith review arXiv 2010
-
[11]
Machine unlearning: Solutions and challenges,
J. Xu, Z. Wu, C. Wang, and X. Jia, “Machine unlearning: Solutions and challenges,”IEEE Transactions on Emerging Topics in Computational Intelligence, vol. 8, no. 3, pp. 2150–2168, 2024
2024
-
[12]
Fast yet effective machine unlearning,
A. K. Tarun, V . S. Chundawat, M. Mandal, and M. Kankanhalli, “Fast yet effective machine unlearning,”IEEE Transactions on Neural Networks and Learning Systems, vol. 35, no. 9, p. 13046–13055, Sep. 2024. [Online]. Available: http://dx.doi.org/10.1109/TNNLS.2023.3266233
-
[13]
KGA: A general machine unlearning framework based on knowledge gap alignment,
L. Wang, T. Chen, W. Yuan, X. Zeng, K.-F. Wong, and H. Yin, “KGA: A general machine unlearning framework based on knowledge gap alignment,” inProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), A. Rogers, J. Boyd-Graber, and N. Okazaki, Eds. Toronto, Canada: Association for Computational Linguis...
2023
-
[14]
Continual learning and private unlearning,
B. Liu, Q. Liu, and P. Stone, “Continual learning and private unlearning,” 2022. [Online]. Available: https://arxiv.org/abs/2203.12817
-
[15]
arXiv preprint arXiv:2310.12508 (2023)
C. Fan, J. Liu, Y . Zhang, E. Wong, D. Wei, and S. Liu, “Salun: Empowering machine unlearning via gradient-based weight saliency in both image classification and generation,” 2024. [Online]. Available: https://arxiv.org/abs/2310.12508
-
[16]
V . S. Chundawat, A. K. Tarun, M. Mandal, and M. Kankanhalli, “Zero-shot machine unlearning,”IEEE Transactions on Information Forensics and Security, vol. 18, p. 2345–2354, 2023. [Online]. Available: http://dx.doi.org/10.1109/TIFS.2023.3265506
-
[17]
Eternal sunshine of the spotless net: Selective forgetting in deep networks,
A. Golatkar, A. Achille, and S. Soatto, “Eternal sunshine of the spotless net: Selective forgetting in deep networks,” in2020 IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (CVPR), 2020, pp. 9301–9309
2020
-
[18]
Few- shot unlearning by model inversion,
Y . Yoon, J. Nam, H. Yun, J. Lee, D. Kim, and J. Ok, “Few- shot unlearning by model inversion,” 2023. [Online]. Available: https://arxiv.org/abs/2205.15567
-
[19]
Making ai forget you: Data deletion in machine learning,
A. Ginart, M. Y . Guan, G. Valiant, and J. Zou, “Making ai forget you: Data deletion in machine learning,” 2019. [Online]. Available: https://arxiv.org/abs/1907.05012
-
[20]
Descent-to-delete: Gradient-based methods for machine unlearning,
S. Neel, A. Roth, and S. Sharifi-Malvajerdi, “Descent-to-delete: Gradient-based methods for machine unlearning,” 2020. [Online]. Available: https://arxiv.org/abs/2007.02923
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.