Recognition: unknown
NeocorRAG: Less Irrelevant Information, More Explicit Evidence, and More Effective Recall via Evidence Chains
Pith reviewed 2026-05-07 07:12 UTC · model grok-4.3
The pith
NeocorRAG breaks the recall-quality tradeoff in retrieval-augmented generation by mining and applying Evidence Chains, delivering higher reasoning accuracy on far fewer tokens.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
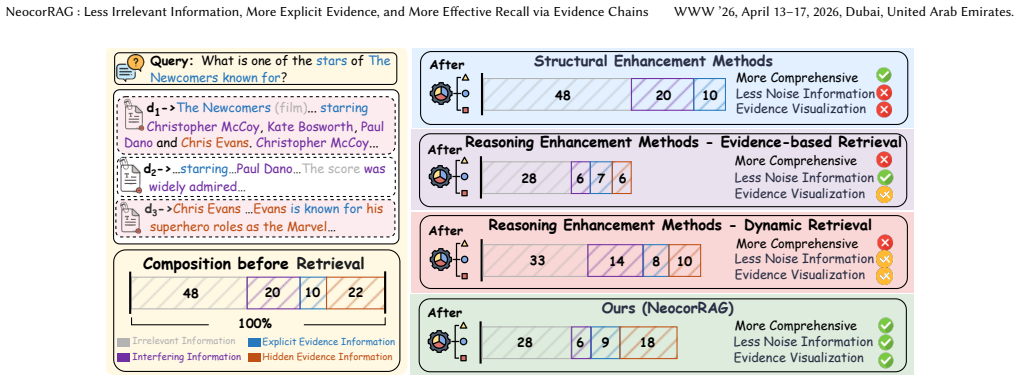
The paper claims that retrieval quality optimization requires explicit Evidence Chains—linked sequences of supporting documents that supply traceable reasoning paths. By first running activated search to shrink the candidate space, then applying constrained decoding to guarantee chain validity, and finally using the resulting chains to re-rank and prune the retrieved set, NeocorRAG simultaneously raises recall and quality. This dual improvement raises the Recall Conversion Rate and produces higher end-task accuracy while consuming dramatically fewer tokens.
What carries the argument
Evidence Chains: sequences of connected evidence documents generated by activated search followed by constrained decoding, which are then used to guide final retrieval optimization.
If this is right
- State-of-the-art accuracy is reached on HotpotQA, 2WikiMultiHopQA, MuSiQue, and NQ for both 3B and 70B models.
- Token usage drops below 20 percent of comparable retrieval-augmented methods while recall stays high.
- The approach is entirely training-free and can be applied on top of existing retrievers and generators.
- The Recall Conversion Rate metric exposes a previously hidden linear decay between recall and reasoning utility in prior RAG systems.
Where Pith is reading between the lines
- Evidence Chains may reduce hallucinations by making the reasoning path between retrieved facts and the final answer more explicit and checkable.
- The activated-search plus constrained-decoding pattern could be reused in other structured-retrieval settings such as legal or medical document chains where traceability matters.
- Because the method keeps the final context short, it may extend more easily to very long-context models that currently hit token limits.
Load-bearing premise
The quality gains from Evidence Chains will translate into higher downstream reasoning accuracy on unseen tasks and model scales without creating new failure modes.
What would settle it
Run NeocorRAG on a fresh multi-hop QA dataset never seen during its design and measure whether accuracy gains disappear even though Recall Conversion Rate still rises.
Figures





read the original abstract
Although precise recall is a core objective in Retrieval-Augmented Generation (RAG), a critical oversight persists in the field: improvements in retrieval performance do not consistently translate to commensurate gains in downstream reasoning. To diagnose this gap, we propose the Recall Conversion Rate (RCR), a novel evaluation metric to quantify the contribution of retrieval to reasoning accuracy. Our quantitative analysis of mainstream RAG methods reveals that as Recall@5 improves, the RCR exhibits a near-linear decay. We identify the neglect of retrieval quality in these methods as the underlying cause. In contrast, approaches that focus solely on quality optimization often suffer from inferior recall performance. Both categories lack a comprehensive understanding of retrieval quality optimization, resulting in a trade-off dilemma. To address these challenges, we propose comprehensive retrieval quality optimization criteria and introduce the NeocorRAG framework. This framework achieves holistic retrieval quality optimization by systematically mining and utilizing Evidence Chains. Specifically, NeocorRAG first employs an innovative activated search algorithm to obtain a refined candidate space. Then it ensures precise evidence chain generation through constrained decoding. Finally, the retrieved set of evidence chains guides the retrieval optimization process. Evaluated on benchmarks including HotpotQA, 2WikiMultiHopQA, MuSiQue, and NQ, NeocorRAG achieves SOTA performance on both 3B and 70B parameter models, while consuming less than 20% of tokens used by comparable methods. This study presents an efficient, training-free paradigm for RAG enhancement that effectively optimizes retrieval quality while maintaining high recall. Our code is released at https://github.com/BUPT-Reasoning-Lab/NeocorRAG.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Recall Conversion Rate (RCR) metric to quantify how much retrieval contributes to downstream reasoning accuracy in RAG. It reports that RCR exhibits near-linear decay as Recall@5 rises across mainstream methods, attributing this to insufficient attention to retrieval quality, and contrasts this with quality-focused methods that sacrifice recall. To resolve the trade-off, the authors propose NeocorRAG, a training-free framework that (1) uses activated search to refine the candidate pool, (2) applies constrained decoding to mine Evidence Chains, and (3) leverages the resulting chains to guide retrieval optimization. The framework is evaluated on HotpotQA, 2WikiMultiHopQA, MuSiQue, and NQ, claiming SOTA results for both 3B and 70B models while consuming less than 20% of the tokens used by comparable baselines.
Significance. If the empirical results and the reliability of Evidence Chain generation are confirmed, NeocorRAG would offer a practical, training-free route to improving RAG reasoning by explicitly structuring high-quality evidence rather than relying on raw recall. The RCR metric provides a useful diagnostic tool for future work. The public code release supports reproducibility. The significance is currently limited by the absence of detailed verification that the core mechanisms (especially constrained decoding) function reliably across model scales.
major comments (3)
- [Abstract and §4] Abstract and §4 (Experimental Evaluation): The central claim that NeocorRAG achieves SOTA performance on 3B-parameter models rests on the assumption that constrained decoding reliably produces usable Evidence Chains. No per-model decoding success rates, fallback procedures, or ablations that remove or isolate failed chains are reported. Because smaller models are known to have weaker instruction-following under constraints, the 3B gains could be artifacts of selective evaluation or implicit fallbacks to weaker retrieval, directly undermining the 'no new failure modes' and 'works on both 3B and 70B' assertions.
- [§2] §2 (Motivation and RCR Analysis): The observation of near-linear RCR decay is presented as the key motivation for the framework. However, the text supplies no numerical tables, data points, or statistical tests supporting the decay claim or the causal attribution to 'neglect of retrieval quality.' Without these, it is impossible to assess whether the decay is robust or whether the proposed quality criteria actually address the diagnosed problem.
- [§3] §3 (NeocorRAG Framework): The description of how Evidence Chains are integrated into the final retrieval optimization step is high-level. It is unclear how the 'comprehensive retrieval quality optimization criteria' are formally defined, how conflicts between chain quality and recall are resolved, and whether the process introduces new biases. This mechanism is load-bearing for the claim that the method simultaneously improves quality and maintains high recall.
minor comments (2)
- [Abstract] Abstract: Adding one or two concrete performance deltas or RCR values would make the SOTA claim more informative without lengthening the abstract excessively.
- [§4] The paper would benefit from an explicit comparison table that includes recent multi-hop RAG baselines (e.g., those using iterative retrieval or chain-of-thought prompting) rather than only 'comparable methods.'
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. These highlight important areas for improving transparency and rigor. We address each major comment point-by-point below, committing to revisions that add the requested data, formalizations, and analyses without altering the core claims or results.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Experimental Evaluation): The central claim that NeocorRAG achieves SOTA performance on 3B-parameter models rests on the assumption that constrained decoding reliably produces usable Evidence Chains. No per-model decoding success rates, fallback procedures, or ablations that remove or isolate failed chains are reported. Because smaller models are known to have weaker instruction-following under constraints, the 3B gains could be artifacts of selective evaluation or implicit fallbacks to weaker retrieval, directly undermining the 'no new failure modes' and 'works on both 3B and 70B' assertions.
Authors: We agree that explicit verification of constrained decoding reliability is necessary, particularly for the 3B model. In the revised manuscript, we will add a new subsection in §4.2 reporting per-model success rates (percentage of queries yielding valid Evidence Chains) for both 3B and 70B models across all four datasets, along with the exact fallback procedure: on decoding failure, the system uses the top-5 passages from activated search without chain optimization. We will also include an ablation table isolating performance on successful-chain queries versus fallback queries, showing that overall gains remain consistent and no new failure modes are introduced beyond those of standard retrieval. These additions directly address the concern and confirm the claims hold across scales. revision: yes
-
Referee: [§2] §2 (Motivation and RCR Analysis): The observation of near-linear RCR decay is presented as the key motivation for the framework. However, the text supplies no numerical tables, data points, or statistical tests supporting the decay claim or the causal attribution to 'neglect of retrieval quality.' Without these, it is impossible to assess whether the decay is robust or whether the proposed quality criteria actually address the diagnosed problem.
Authors: The referee correctly identifies that §2 would be strengthened by explicit supporting data. Although the near-linear decay was observed across our experiments, we will revise §2 to include a new table (Table 1) with Recall@5 and RCR values for multiple mainstream methods on HotpotQA and 2WikiMultiHopQA. We will also add a figure with a scatter plot of RCR versus Recall@5, a fitted linear regression, and the associated R² value plus correlation coefficient to quantify the trend. A short paragraph will discuss how the quality-focused criteria in NeocorRAG target the diagnosed cause. These changes make the motivation fully verifiable. revision: yes
-
Referee: [§3] §3 (NeocorRAG Framework): The description of how Evidence Chains are integrated into the final retrieval optimization step is high-level. It is unclear how the 'comprehensive retrieval quality optimization criteria' are formally defined, how conflicts between chain quality and recall are resolved, and whether the process introduces new biases. This mechanism is load-bearing for the claim that the method simultaneously improves quality and maintains high recall.
Authors: We acknowledge the description in §3 is high-level and will expand it substantially. In the revision, §3.3 will include formal definitions: the optimization criteria as a constrained multi-objective function maximizing chain coherence + coverage subject to recall@5 ≥ τ (with explicit formulas for each term). We will add pseudocode for the full optimization step and explain conflict resolution via a recall-first lexicographic ordering (quality improvements are accepted only if recall does not drop below threshold). A new paragraph will analyze potential biases, supported by results on the single-hop NQ dataset showing no degradation relative to baselines. These clarifications will make the mechanism transparent while preserving the quality-recall balance claim. revision: yes
Circularity Check
No circularity; new metric and algorithmic framework are independently defined and empirically tested
full rationale
The paper defines Recall Conversion Rate (RCR) as a fresh metric quantifying retrieval's contribution to downstream accuracy, reports an empirical observation of near-linear RCR decay versus Recall@5 on mainstream methods, and introduces NeocorRAG as a distinct training-free procedure (activated search + constrained decoding + evidence-chain guidance). No equations, parameters, or predictions are shown to reduce by construction to prior fitted values or self-citations; the SOTA claims on 3B/70B models rest on benchmark evaluations of the new procedure rather than tautological re-labeling of inputs. The derivation chain is therefore self-contained.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Retrieval quality improvements will produce commensurate gains in downstream reasoning accuracy
- ad hoc to paper Evidence Chains mined via activated search and constrained decoding constitute higher-quality retrieval sets
invented entities (2)
-
Evidence Chains
no independent evidence
-
Recall Conversion Rate (RCR)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Muhammad Arslan, Hussam Ghanem, Saba Munawar, and Christophe Cruz. 2024. A Survey on RAG with LLMs.Procedia Computer Science246 (2024), 3781–3790. doi:10.1016/j.procs.2024.09.178 28th International Conference on Knowledge Based and Intelligent information and Engineering Systems (KES 2024)
-
[2]
Akari Asai, Zeqiu Wu, Yizhong Wang, Avirup Sil, and Hannaneh Hajishirzi
-
[3]
InThe Twelfth International Conference on Learning Representations
Self-RAG: Learning to Retrieve, Generate, and Critique through Self- Reflection. InThe Twelfth International Conference on Learning Representations. https://openreview.net/forum?id=hSyW5go0v8
-
[4]
Michael Buckland and Fredric Gey. 1994. The relationship between Recall and Precision.Journal of the American Society for Information Science45, 1 (1994), 12–19. doi:10.1002/(SICI)1097-4571(199401)45:1<12::AID-ASI2>3.0.CO;2-L
-
[5]
Tong Chen, Hongwei Wang, Sihao Chen, Wenhao Yu, Kaixin Ma, Xinran Zhao, Hongming Zhang, and Dong Yu. 2024. Dense X Retrieval: What Retrieval Granu- larity Should We Use?. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen (Eds.). Association for Computational Linguist...
-
[6]
Nadezhda Chirkova, Thibault Formal, Vassilina Nikoulina, and Stéphane CLIN- CHANT. 2025. Provence: efficient and robust context pruning for retrieval- augmented generation. InThe Thirteenth International Conference on Learning Representations. https://openreview.net/forum?id=TDy5Ih78b4
2025
-
[7]
Yang, and Anton Tsitsulin
Jialin Dong, Bahare Fatemi, Bryan Perozzi, Lin F. Yang, and Anton Tsitsulin
-
[8]
Don’t Forget to Connect! Improving RAG with Graph-based Reranking. arXiv:2405.18414 [cs.CL] https://arxiv.org/abs/2405.18414
-
[9]
Wenqi Fan, Yujuan Ding, Liangbo Ning, Shijie Wang, Hengyun Li, Dawei Yin, Tat-Seng Chua, and Qing Li. 2024. A Survey on RAG Meeting LLMs: Towards Retrieval-Augmented Large Language Models. InProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining(Barcelona, Spain) (KDD ’24). Association for Computing Machinery, New York, NY, U...
-
[10]
Jinyuan Fang, Zaiqiao Meng, and Craig MacDonald. 2024. TRACE the Evidence: Constructing Knowledge-Grounded Reasoning Chains for Retrieval-Augmented Generation. InFindings of the Association for Computational Linguistics: EMNLP 2024, Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen (Eds.). Association for Computational Linguistics, Miami, Florida, USA, 84...
-
[11]
Edward Fredkin. 1960. Trie memory.Commun. ACM3, 9 (Sept. 1960), 490–499. doi:10.1145/367390.367400
-
[12]
Markus Freitag and Yaser Al-Onaizan. 2017. Beam Search Strategies for Neural Machine Translation. InProceedings of the First Workshop on Neural Machine Translation, Thang Luong, Alexandra Birch, Graham Neubig, and Andrew Finch (Eds.). Association for Computational Linguistics, Vancouver, 56–60. doi:10. 18653/v1/W17-3207
2017
-
[13]
Yunfan Gao, Yun Xiong, Xinyu Gao, Kangxiang Jia, Jinliu Pan, Yuxi Bi, Yi Dai, Jiawei Sun, Meng Wang, and Haofen Wang. 2024. Retrieval-Augmented Generation for Large Language Models: A Survey. arXiv:2312.10997 [cs.CL] https://arxiv.org/abs/2312.10997
work page internal anchor Pith review arXiv 2024
-
[14]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, Amy Yang, Angela Fan, et al . 2024. The Llama 3 Herd of Models. arXiv:2407.21783 [cs.AI] https://arxiv.org/abs/2407.21783
work page internal anchor Pith review arXiv 2024
-
[15]
Bernal Jiménez Gutiérrez, Yiheng Shu, Yu Gu, Michihiro Yasunaga, and Yu Su
-
[16]
HippoRAG: Neurobiologically Inspired Long-Term Memory for Large Lan- guage Models. InAdvances in Neural Information Processing Systems, A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang (Eds.), Vol. 37. Curran Associates, Inc., 59532–59569. doi:10.52202/079017-1902
-
[17]
Bernal Jiménez Gutiérrez, Yiheng Shu, Weijian Qi, Sizhe Zhou, and Yu Su
-
[18]
InProceedings of the 42nd International Conference on Ma- chine Learning (Proceedings of Machine Learning Research, Vol
From RAG to Memory: Non-Parametric Continual Learning for Large Language Models. InProceedings of the 42nd International Conference on Ma- chine Learning (Proceedings of Machine Learning Research, Vol. 267), Aarti Singh, Maryam Fazel, Daniel Hsu, Simon Lacoste-Julien, Felix Berkenkamp, Tegan Maharaj, Kiri Wagstaff, and Jerry Zhu (Eds.). PMLR, 21497–21515....
-
[19]
Haoyu Han, Yu Wang, Harry Shomer, Kai Guo, Jiayuan Ding, Yongjia Lei, Ma- hantesh Halappanavar, Ryan A. Rossi, Subhabrata Mukherjee, Xianfeng Tang, Qi He, Zhigang Hua, Bo Long, Tong Zhao, Neil Shah, Amin Javari, Yinglong Xia, and Jiliang Tang. 2025. Retrieval-Augmented Generation with Graphs (GraphRAG). arXiv:2501.00309 [cs.IR] https://arxiv.org/abs/2501.00309
-
[20]
Chawla, Thomas Laurent, Yann LeCun, Xavier Bresson, and Bryan Hooi
Xiaoxin He, Yijun Tian, Yifei Sun, Nitesh V. Chawla, Thomas Laurent, Yann LeCun, Xavier Bresson, and Bryan Hooi. 2024. G-Retriever: Retrieval-Augmented Gener- ation for Textual Graph Understanding and Question Answering. InAdvances in Neural Information Processing Systems, A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang (...
-
[21]
Xanh Ho, Anh-Khoa Duong Nguyen, Saku Sugawara, and Akiko Aizawa. 2020. Constructing A Multi-hop QA Dataset for Comprehensive Evaluation of Reason- ing Steps. InProceedings of the 28th International Conference on Computational Linguistics, Donia Scott, Nuria Bel, and Chengqing Zong (Eds.). International Committee on Computational Linguistics, Barcelona, Sp...
-
[22]
Gautier Izacard, Mathilde Caron, Lucas Hosseini, Sebastian Riedel, Piotr Bo- janowski, Armand Joulin, and Edouard Grave. 2022. Unsupervised Dense Infor- mation Retrieval with Contrastive Learning.Transactions on Machine Learning Research(2022). https://openreview.net/forum?id=jKN1pXi7b0
2022
-
[23]
Soyeong Jeong, Jinheon Baek, Sukmin Cho, Sung Ju Hwang, and Jong Park
-
[24]
Adaptive-RAG: Learning to Adapt Retrieval-Augmented Large Language Models through Question Complexity. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), Kevin Duh, Helena Gomez, and Steven Bethard (Eds.). Association for Computational Li...
-
[25]
Gary Klein, Brian Moon, and Robert R. Hoffman. 2006. Making Sense of Sense- making 1: Alternative Perspectives .IEEE Intelligent Systems21, 04 (July 2006), 70–73. doi:10.1109/MIS.2006.75
-
[26]
and Uszkoreit, Jakob and Le, Quoc and Petrov, Slav
Tom Kwiatkowski, Jennimaria Palomaki, Olivia Redfield, Michael Collins, Ankur Parikh, Chris Alberti, Danielle Epstein, Illia Polosukhin, Jacob Devlin, Kenton Lee, Kristina Toutanova, Llion Jones, Matthew Kelcey, Ming-Wei Chang, Andrew M. Dai, Jakob Uszkoreit, Quoc Le, and Slav Petrov. 2019. Natural Questions: A Benchmark for Question Answering Research.Tr...
-
[27]
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. 2020. Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. InAdvances in Neural Information Processing Systems, H. Larochelle, M. Ranzato, R. Hadsell, M.F...
2020
-
[28]
Xiaoxi Li, Jiajie Jin, Yujia Zhou, Yongkang Wu, Zhonghua Li, Ye Qi, and Zhicheng Dou. 2025. RetroLLM: Empowering Large Language Models to Retrieve Fine- grained Evidence within Generation. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and M...
2025
-
[29]
Linhao Luo, Zicheng Zhao, Gholamreza Haffari, Yuan-Fang Li, Chen Gong, and Shirui Pan. 2025. Graph-constrained Reasoning: Faithful Reasoning on Knowl- edge Graphs with Large Language Models. InProceedings of the 42nd Interna- tional Conference on Machine Learning (Proceedings of Machine Learning Research, Vol. 267), Aarti Singh, Maryam Fazel, Daniel Hsu, ...
2025
-
[30]
Alex Mallen, Akari Asai, Victor Zhong, Rajarshi Das, Daniel Khashabi, and Hannaneh Hajishirzi. 2023. When Not to Trust Language Models: Investigating Effectiveness of Parametric and Non-Parametric Memories. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Anna Rogers, Jordan Boyd-Graber, an...
2023
-
[31]
Jianmo Ni, Chen Qu, Jing Lu, Zhuyun Dai, Gustavo Hernandez Abrego, Ji Ma, Vincent Zhao, Yi Luan, Keith Hall, Ming-Wei Chang, and Yinfei Yang. 2022. Large Dual Encoders Are Generalizable Retrievers. InProceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, Yoav Goldberg, Zornitsa Kozareva, and Yue Zhang (Eds.). Association f...
-
[32]
Tong Niu, Shafiq Joty, Ye Liu, Caiming Xiong, Yingbo Zhou, and Semih Yavuz
-
[33]
JudgeRank: Leveraging Large Language Models for Reasoning-Intensive Reranking. arXiv:2411.00142 [cs.CL] https://arxiv.org/abs/2411.00142
-
[34]
Qwen, :, An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jingren Zhou, Junyang Lin, Kai Dang, Keming Lu, Keqin Bao, Kexin Yang, Le Yu, Mei Li, Mingfeng Xue, Pei Zhang, Qin Zhu, Rui Men, Runji Lin, Tianhao Li,...
work page internal anchor Pith review arXiv 2025
-
[35]
1995.Okapi at TREC-3
Stephen E Robertson, Steve Walker, Susan Jones, Micheline M Hancock-Beaulieu, Mike Gatford, et al. 1995.Okapi at TREC-3. British Library Research and Devel- opment Department
1995
- [36]
-
[37]
Keshav Santhanam, Omar Khattab, Jon Saad-Falcon, Christopher Potts, and Matei Zaharia. 2022. ColBERTv2: Effective and Efficient Retrieval via Lightweight Late Interaction. InProceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Marine Carpuat, Marie-Catherine de Marn...
2022
-
[38]
doi:10.18653/v1/2022.naacl-main.272
-
[39]
Parth Sarthi, Salman Abdullah, Aditi Tuli, Shubh Khanna, Anna Goldie, and Christopher D Manning. 2024. RAPTOR: Recursive Abstractive Processing for Tree-Organized Retrieval. InThe Twelfth International Conference on Learning Representations. https://openreview.net/forum?id=GN921JHCRw
2024
-
[40]
Sara Sherif Daoud Saad and Stephanie Silva. 2025. Graph-Enhanced RAG: A Survey of Methods, Architectures, and Performance
2025
-
[41]
Wendy A. Suzuki. 2005. Associative Learning and the Hippocampus. doi:10.1037/ e400222005-005
2005
-
[43]
M u S i Q ue: Multihop questions via single-hop question composition
MuSiQue: Multihop Questions via Single-hop Question Composition. Transactions of the Association for Computational Linguistics10 (2022), 539–554. doi:10.1162/tacl_a_00475
-
[44]
Harsh Trivedi, Niranjan Balasubramanian, Tushar Khot, and Ashish Sabharwal
-
[45]
Interleaving Retrieval with Chain-of-Thought Reasoning for Knowledge-Intensive Multi-Step Questions
Interleaving Retrieval with Chain-of-Thought Reasoning for Knowledge- Intensive Multi-Step Questions. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Anna Rogers, Jordan Boyd-Graber, and Naoaki Okazaki (Eds.). Association for Computational Linguistics, Toronto, Canada, 10014–10037. doi:10....
-
[46]
Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc V Le, Ed H. Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. 2023. Self-Consistency Im- proves Chain of Thought Reasoning in Language Models. InThe Eleventh Inter- national Conference on Learning Representations. https://openreview.net/forum? id=1PL1NIMMrw
2023
-
[47]
Yining Wang, Liwei Wang, Yuanzhi Li, Di He, and Tie-Yan Liu. 2013. A Theoretical Analysis of NDCG Type Ranking Measures. InProceedings of the 26th Annual Conference on Learning Theory (Proceedings of Machine Learning Research, Vol. 30), Shai Shalev-Shwartz and Ingo Steinwart (Eds.). PMLR, Princeton, NJ, USA, 25–54. https://proceedings.mlr.press/v30/Wang13.html
2013
- [48]
- [49]
-
[50]
Ian H. Witten, Stefan J. Boddie, David Bainbridge, and Rodger J. McNab. 2000. Greenstone: a comprehensive open-source digital library software system. InPro- ceedings of the Fifth ACM Conference on Digital Libraries(San Antonio, Texas, USA) (DL ’00). Association for Computing Machinery, New York, NY, USA, 113–121. doi:10.1145/336597.336650
-
[51]
Ian H. Witten, Gordon W. Paynter, Eibe Frank, Carl Gutwin, and Craig G. Nevill- Manning. 1999. KEA: practical automatic keyphrase extraction. InProceedings of the Fourth ACM Conference on Digital Libraries(Berkeley, California, USA) (DL ’99). Association for Computing Machinery, New York, NY, USA, 254–255. doi:10.1145/313238.313437
-
[52]
Shitao Xiao, Zheng Liu, Peitian Zhang, Niklas Muennighoff, Defu Lian, and Jian-Yun Nie. 2024. C-Pack: Packed Resources For General Chinese Embed- dings. InProceedings of the 47th International ACM SIGIR Conference on Re- search and Development in Information Retrieval(Washington DC, USA)(SI- GIR ’24). Association for Computing Machinery, New York, NY, USA...
-
[53]
Xin Xie, Ningyu Zhang, Zhoubo Li, Shumin Deng, Hui Chen, Feiyu Xiong, Mosha Chen, and Huajun Chen. 2022. From Discrimination to Generation: Knowledge Graph Completion with Generative Transformer. InCompanion Proceedings of the Web Conference 2022(Virtual Event, Lyon, France)(WWW ’22). Association for Computing Machinery, New York, NY, USA, 162–165. doi:10...
-
[54]
Derong Xu, Pengyue Jia, Xiaopeng Li, Yingyi Zhang, Maolin Wang, Qidong Liu, Xiangyu Zhao, Yichao Wang, Huifeng Guo, Ruiming Tang, Enhong Chen, and Tong Xu. 2026. Align-GRAG: Anchor and Rationale Guided Dual Alignment for Graph Retrieval-Augmented Generation. arXiv:2505.16237 [cs.CL] https: //arxiv.org/abs/2505.16237
-
[55]
Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William Cohen, Ruslan Salakhutdinov, and Christopher D. Manning. 2018. HotpotQA: A Dataset for Diverse, Explainable Multi-hop Question Answering. InProceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Ellen Riloff, David Chiang, Julia Hockenmaier, and Jun’ichi Tsujii (...
-
[56]
Peitian Zhang, Zheng Liu, Shitao Xiao, Zhicheng Dou, and Jian-Yun Nie. 2024. A Multi-Task Embedder For Retrieval Augmented LLMs. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Lun-Wei Ku, Andre Martins, and Vivek Srikumar (Eds.). Association for Computational Linguistics, Bangkok, Thailan...
-
[57]
Penghao Zhao, Hailin Zhang, Qinhan Yu, Zhengren Wang, Yunteng Geng, Fangcheng Fu, Ling Yang, Wentao Zhang, Jie Jiang, and Bin Cui. 2026. Retrieval- Augmented Generation for AI-Generated Content: A Survey.Data Science and Engineering(02 Jan 2026). doi:10.1007/s41019-025-00335-5
-
[58]
Fantastic Four
Tolga Şakar and Hakan Emekci. 2025. Maximizing RAG efficiency: A comparative analysis of RAG methods.Natural Language Processing31, 1 (2025), 1–25. doi:10. 1017/nlp.2024.53 A Dataset Details In our experiments withNeocorRAG, we adopt the same Wikipedia snapshot and retrieval pipeline asHippoRAG2. Each sampled ques- tion is matched against the identical do...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.