Recognition: unknown
Decoupled Descent: Exact Test Error Tracking Via Approximate Message Passing
Pith reviewed 2026-05-07 06:27 UTC · model grok-4.3
The pith
Decoupled descent cancels data reuse biases so that training error asymptotically tracks test error in Gaussian mixture models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
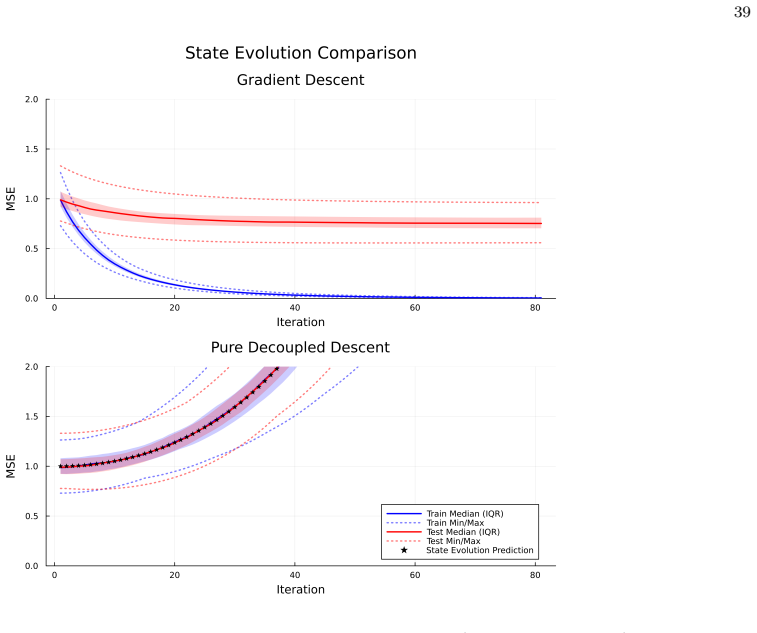
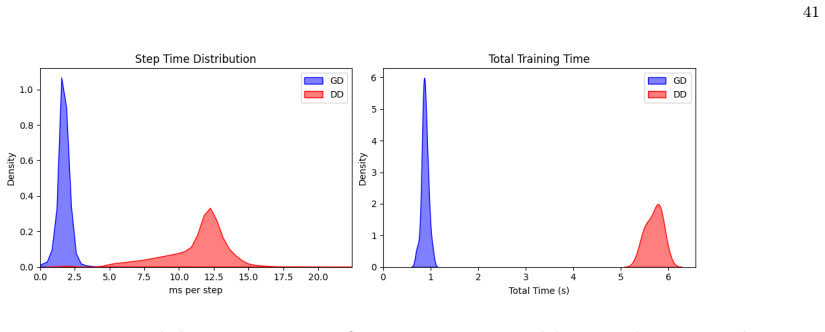
Decoupled descent (DD) is a novel training algorithm that, by leveraging approximate message passing theory, iteratively cancels the biases induced by data reuse in full-batch gradient descent. For stylized Gaussian mixture models, this results in the training error asymptotically tracking the test error, satisfying a train-test identity. The algorithm's dynamics are described by a low-dimensional recursion, and it demonstrates superior performance on tasks like XOR classification compared to standard gradient descent, while narrowing the gap even on more complex datasets like noisy MNIST and CIFAR-10 when assumptions are relaxed.
What carries the argument
The decoupled descent algorithm, which separates parameter updates to enable exact iterative cancellation of data-reuse biases through approximate message passing state evolution.
Load-bearing premise
The data must follow stylized Gaussian mixture models for which approximate message passing theory can exactly cancel all biases arising from data reuse during training.
What would settle it
A simulation on Gaussian mixture data in which decoupled descent is run but the training and test errors fail to converge to the same asymptotic value would falsify the train-test identity.
Figures
read the original abstract
In modern parametric model training, full-batch gradient descent (and its variants) suffers due to progressively stronger biasing towards the exact realization of training data; this drives the systematic ``generalization gap'', where the train error becomes an unreliable proxy for test error. Existing approaches either argue this gap is benign through complex analysis or sacrifice data to a validation set. In contrast, we introduce decoupled descent (DD), a novel theory-based training algorithm that satisfies a train-test identity -- enforcing the train error to asymptotically track the test error for stylized Gaussian mixture models. Within this specific regime, leveraging approximate message passing theory, DD iteratively cancels the biases due to data reuse, rigorously demonstrating the feasibility of zero-cost validation and $100\%$ data utilization. Moreover, DD is governed by a low-dimensional state evolution recursion, rendering the dynamics of the algorithm transparent and tractable. We validate DD on XOR classification, yielding superior performance compared to GD; additionally, we implement noisy MNIST and non-linear probing of CIFAR-10, demonstrating that even when our stylized assumptions are relaxed, DD narrows the generalization gap compared to GD.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces decoupled descent (DD), a novel training algorithm that leverages approximate message passing (AMP) theory to iteratively cancel biases arising from data reuse in gradient descent. For stylized Gaussian mixture models, DD is claimed to enforce an asymptotic train-test error identity, governed by a low-dimensional state evolution recursion that renders the dynamics tractable. Empirical results on XOR classification, noisy MNIST, and non-linear probing of CIFAR-10 are presented to show that DD narrows the generalization gap relative to standard GD, even when the GMM assumptions are relaxed.
Significance. If the central claim holds, the work offers a theoretically grounded approach to zero-cost validation and full data utilization in high-dimensional parametric training, with the AMP-derived state evolution providing a transparent, low-dimensional description of the dynamics. The grounding in established AMP literature is a strength, as it supplies independent justification for the recursions rather than ad-hoc fitting. The empirical narrowing of the gap on real data suggests broader applicability, though the primary value lies in the stylized regime where the identity is rigorously derived.
major comments (2)
- [§4] §4, the state evolution derivation: the claim that the train-error recursion is identical to the test-error recursion after each DD iteration requires explicit verification that the Onsager correction exactly equates the effective noise variances in the reused-training view and the independent-test view. Without this matching shown for the GMM loss and gradient, the asymptotic identity does not follow from standard AMP assumptions.
- [§3.2] §3.2, the decoupled update rule: the construction introduces model-dependent correlations between the gradient steps and the data; it is not shown that these correlations vanish in the high-dimensional limit with fixed aspect ratio, which is necessary to preserve the independence assumptions underlying the closed state evolution.
minor comments (2)
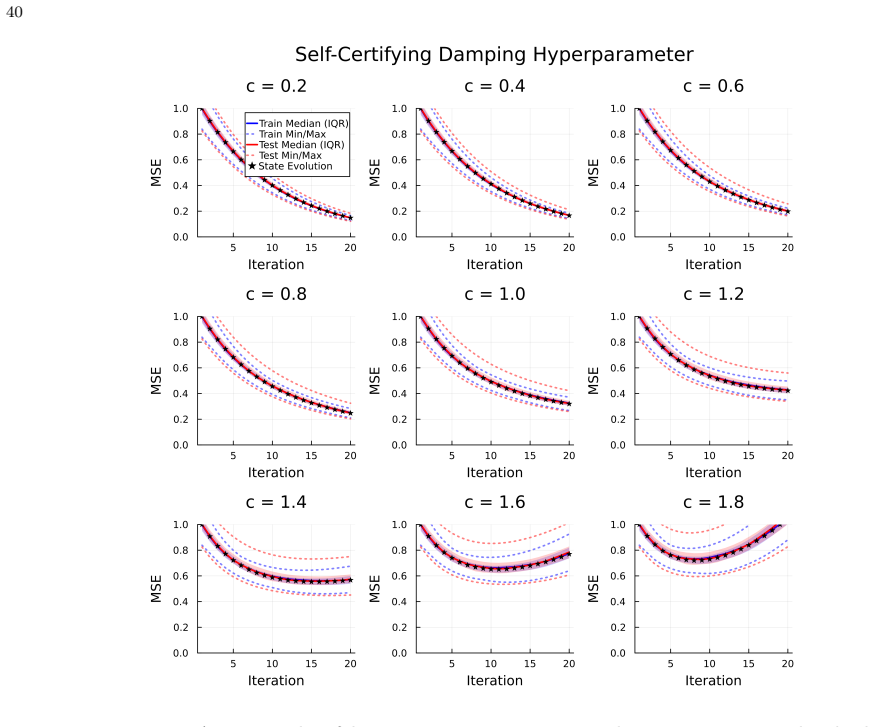
- [Experimental section] The experimental section should report the precise procedure used to initialize or fit the state-evolution parameters on the real-data tasks (noisy MNIST, CIFAR-10), including any sensitivity analysis.
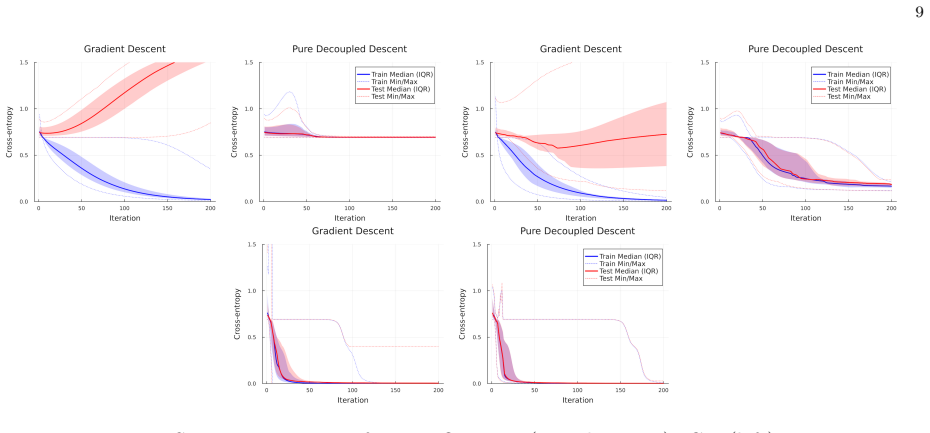
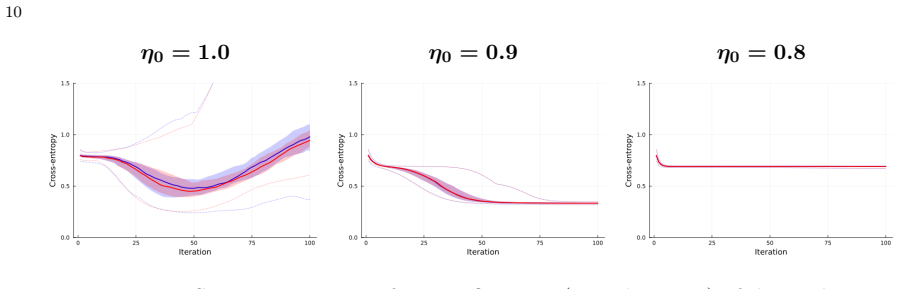
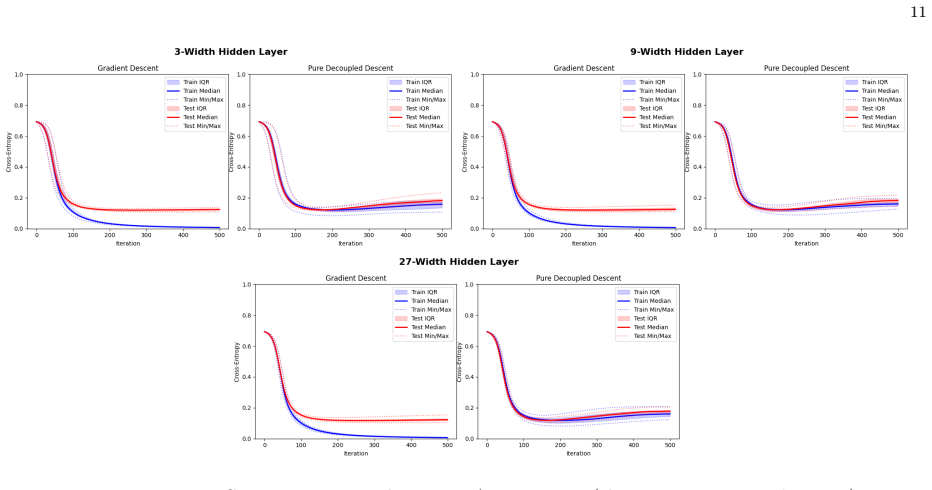
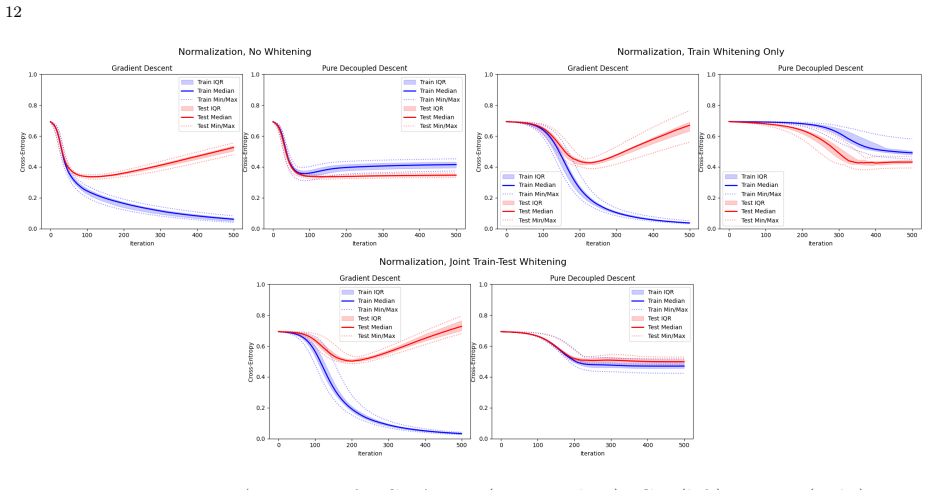
- [Figures] Figure captions for the XOR and MNIST results should explicitly state the number of independent runs and the precise definition of the plotted error quantities (e.g., whether they are averaged over the state-evolution trajectory).
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive major comments. These points highlight areas where additional explicit verification will strengthen the rigor of the derivations. We address each comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [§4] §4, the state evolution derivation: the claim that the train-error recursion is identical to the test-error recursion after each DD iteration requires explicit verification that the Onsager correction exactly equates the effective noise variances in the reused-training view and the independent-test view. Without this matching shown for the GMM loss and gradient, the asymptotic identity does not follow from standard AMP assumptions.
Authors: We agree that an explicit verification of the noise-variance matching is required to complete the argument. In the revised manuscript we will insert a dedicated calculation in §4 that computes the effective noise variances for the GMM loss and gradient under both the reused-training and independent-test views. We will show that the Onsager correction term arising from the decoupled descent update exactly equates these variances, thereby confirming that the train-error and test-error recursions coincide asymptotically from the standard AMP assumptions. revision: yes
-
Referee: [§3.2] §3.2, the decoupled update rule: the construction introduces model-dependent correlations between the gradient steps and the data; it is not shown that these correlations vanish in the high-dimensional limit with fixed aspect ratio, which is necessary to preserve the independence assumptions underlying the closed state evolution.
Authors: We acknowledge that the vanishing of the model-dependent correlations introduced by the decoupled update was not shown explicitly. In the revision we will add a short lemma (or remark) in §3.2 that invokes standard AMP concentration and self-averaging results to prove that, in the high-dimensional limit with fixed aspect ratio, these correlations become o(1) and therefore do not affect the independence assumptions required for the closed state evolution. revision: yes
Circularity Check
No significant circularity; central claim follows from external AMP theory applied to a constructed algorithm
full rationale
The paper defines decoupled descent (DD) explicitly to cancel data-reuse biases using the Onsager correction terms and state-evolution recursions supplied by established approximate message passing (AMP) literature. The train-test identity is then shown to hold asymptotically because the effective noise variances and correlation terms in the low-dimensional state evolution match between the adjusted training iterates and an independent test view; this matching is a derived consequence of the AMP analysis rather than an input assumption or a fitted parameter renamed as a prediction. No load-bearing step reduces to a self-citation chain, self-definition, or ansatz smuggled from the authors' prior work. The derivation therefore remains self-contained once the external AMP results (which are independently verifiable and not dependent on the present paper's target identity) are granted.
Axiom & Free-Parameter Ledger
free parameters (1)
- state evolution parameters
axioms (1)
- domain assumption Approximate message passing theory accurately describes the iterative dynamics of decoupled descent on Gaussian mixture models
Reference graph
Works this paper leans on
-
[1]
Z. D. Bai and Y. Q. Yin. Limit of the smallest eigenvalue of a large dimensional sample covariance matrix.The Annals of Probability, 21(3), July 1993. ISSN 0091-1798. DOI: https://doi.org/10.1214/aop/1176989118. URL http://dx.doi.org/10.1214/aop/1176989118
-
[2]
Zhigang Bao, Qiyang Han, and Xiaocong Xu. A leave-one-out approach to approximate message passing.The Annals of Applied Probability, 35(4), August 2025. ISSN 1050-5164. DOI: https://doi.org/10.1214/25-aap2186. URL http://dx.doi.org/10.1214/25-aap2186
-
[3]
Mohsen Bayati, Marc Lelarge, and Andrea Montanari. Universality in polytope phase transitions and message passing algorithms.The Annals of Applied Probability, 25(2), apr 2015. DOI: https://doi.org/10.1214/14-aap1010
-
[4]
Raphaël Berthier, Andrea Montanari, and Phan-Minh Nguyen. State evolution for approximate message passing with non-separable functions.Information and Inference: A Journal of the IMA, 9(1):33–79, January 2019. ISSN 2049-8772. DOI: https://doi.org/10.1093/imaiai/iay021. URL http://dx.doi.org/10.1093/imaiai/iay021
-
[5]
Wei-Kuo Chen and Wai-Kit Lam. Universality of approximate message passing algo- rithms.Electronic Journal of Probability, 26(none), January 2021. ISSN 1083-6489. DOI: https://doi.org/10.1214/21-ejp604. URL http://dx.doi.org/10.1214/21-ejp604
-
[6]
Sequential dynamics in ising spin glasses, 2025
Yatin Dandi, David Gamarnik, Francisco Pernice, and Lenka Zdeborová. Sequential dynamics in ising spin glasses, 2025
2025
-
[7]
Donoho, Arian Maleki, and Andrea Montanari
David L. Donoho, Arian Maleki, and Andrea Montanari. Message passing algorithms for compressed sensing: I. motivation and construction. InIEEE Information Theory Workshop 2010 (ITW 2010), page 1–5. IEEE, January 2010. DOI: https://doi.org/10.1109/itwksps.2010.5503193. URL http://dx.doi.org/10.1109/itwksps.2010.5503193
-
[8]
Zhou Fan. Approximate message passing algorithms for rotationally invariant matrices.The Annals of Statistics, 50(1), February 2022. ISSN 0090-5364. DOI: https://doi.org/10.1214/21- aos2101. URL http://dx.doi.org/10.1214/21-aos2101
work page doi:10.1214/21- 2022
-
[9]
High-dimensional learning dynamics of multi-pass stochastic gradient descent in multi-index models, 2026
Zhou Fan and Leda Wang. High-dimensional learning dynamics of multi-pass stochastic gradient descent in multi-index models, 2026
2026
-
[10]
Feng, Ramji Venkataramanan, Cynthia Rush, and Richard J
Oliver Y. Feng, Ramji Venkataramanan, Cynthia Rush, and Richard J. Samworth.A Unifying Tutorial on Approximate Message Passing. Now Publishers, 2022. ISBN 9781638280057. DOI: https://doi.org/10.1561/9781638280057. URL http://dx.doi.org/10.1561/9781638280057
-
[11]
Cédric Gerbelot and Raphaël Berthier. Graph-based approximate message passing it- erations.Information and Inference: A Journal of the IMA, 12(4):2562–2628, Sep- tember 2023. ISSN 2049-8772. DOI: https://doi.org/10.1093/imaiai/iaad020. URL http://dx.doi.org/10.1093/imaiai/iaad020
-
[12]
The gaussian equivalence of generative models for learning with shal- low neural networks
Sebastian Goldt, Bruno Loureiro, Galen Reeves, Florent Krzakala, Marc M’ezard, and Lenka Zdeborov’a. The gaussian equivalence of generative models for learning with shal- low neural networks. InMathematical and Scientific Machine Learning, 2020. URL https://api.semanticscholar.org/CorpusID:235165686. 14
2020
-
[13]
A. Javanmard and A. Montanari. State evolution for general approximate message pass- ing algorithms, with applications to spatial coupling.Information and Inference, 2(2): 115–144, October 2013. ISSN 2049-8772. DOI: https://doi.org/10.1093/imaiai/iat004. URL http://dx.doi.org/10.1093/imaiai/iat004
-
[14]
Agnan Kessy, Alex Lewin, and Korbinian Strimmer. Optimal whitening and decorrelation.The American Statistician, 72(4):309–314, January 2018. ISSN 1537-2731. DOI: https://doi.org/10.1080/00031305.2016.1277159. URL http://dx.doi.org/10.1080/00031305.2016.1277159
-
[15]
Learning multiple layers of features from tiny images
Alex Krizhevsky, Geoffrey Hinton, et al. Learning multiple layers of features from tiny images. Technical report, University of Toronto, 2009
2009
-
[16]
Gradient-based learning applied to document recognition.Proceedings of the IEEE, 86(11):2278–2324, 1998
Yann LeCun, Léon Bottou, Yoshua Bengio, and Patrick Haffner. Gradient-based learning applied to document recognition.Proceedings of the IEEE, 86(11):2278–2324, 1998
1998
-
[17]
A non-asymptotic framework for approximate message passing in spiked models, 2023
Gen Li and Yuting Wei. A non-asymptotic framework for approximate message passing in spiked models, 2023
2023
-
[18]
Unifying amp algorithms for rotationally-invariant models, 2024
Songbin Liu and Junjie Ma. Unifying amp algorithms for rotationally-invariant models, 2024
2024
-
[19]
On universality of non-separable approximate message passing algorithms, 2025
Max Lovig, Tianhao Wang, and Zhou Fan. On universality of non-separable approximate message passing algorithms, 2025
2025
-
[20]
Francesca Mignacco, Florent Krzakala, Pierfrancesco Urbani, and Lenka Zdeborová. Dynamical mean-field theory for stochastic gradient descent in gaussian mixture classification*.Journal of Statistical Mechanics: Theory and Experiment, 2021(12):124008, December 2021. ISSN 1742-
2021
-
[21]
URL http://dx.doi.org/10.1088/1742- 5468/ac3a80
DOI: https://doi.org/10.1088/1742-5468/ac3a80. URL http://dx.doi.org/10.1088/1742- 5468/ac3a80
-
[22]
Dynamical decoupling of generalization and overfitting in large two-layer networks, 2025
Andrea Montanari and Pierfrancesco Urbani. Dynamical decoupling of generalization and overfitting in large two-layer networks, 2025
2025
-
[23]
High-dimensional limit of stochastic gradient flow via dynamical mean-field theory, 2026
Sota Nishiyama and Masaaki Imaizumi. High-dimensional limit of stochastic gradient flow via dynamical mean-field theory, 2026
2026
-
[24]
Dimension-free bounds for generalized first-order methods via gaussian coupling, 2025
Galen Reeves. Dimension-free bounds for generalized first-order methods via gaussian coupling, 2025
2025
-
[25]
Cynthia Rush and Ramji Venkataramanan. Finite sample analysis of approximate message passing algorithms.IEEE Transactions on Information Theory, 64(11):7264–7286, nov 2018. DOI: https://doi.org/10.1109/tit.2018.2816681
-
[26]
Sophia Sklaviadis, Thomas Moellenhoff, Andre F. T. Martins, Mario A. T. Figueiredo, and Mohammad Emtiyaz Khan. A stein identity for q-gaussians with bounded support, 2026
2026
-
[27]
Tianhao Wang, Xinyi Zhong, and Zhou Fan. Universality of approximate message passing algorithms and tensor networks.The Annals of Applied Probability, 34(4), August 2024. ISSN 1050-5164. DOI: https://doi.org/10.1214/24-aap2056. URL http://dx.doi.org/10.1214/24- aap2056
-
[28]
Approxi- mate message passing for multi-layer estimation in rotationally invariant mod- els
Yizhou Xu, TianQi Hou, ShanSuo Liang, and Marco Mondelli. Approxi- mate message passing for multi-layer estimation in rotationally invariant mod- els. In2023 IEEE Information Theory Workshop (ITW), page 294–298. IEEE, April 2023. DOI: https://doi.org/10.1109/itw55543.2023.10160238. URL http://dx.doi.org/10.1109/itw55543.2023.10160238. 15
-
[29]
Greg Yang and Edward J. Hu. Tensor programs iv: Feature learning in infinite-width neural networks. InInternational Conference on Machine Learning (ICML), pages 11727–11737. PMLR, 2021
2021
-
[30]
Xinyi Zhong, Tianhao Wang, and Zhou Fan. Approximate message passing for orthogo- nally invariant ensembles: multivariate non-linearities and spectral initialization.Infor- mation and Inference: A Journal of the IMA, 13(3), July 2024. ISSN 2049-8772. DOI: https://doi.org/10.1093/imaiai/iaae024. URL http://dx.doi.org/10.1093/imaiai/iaae024. AppendixA.Defer...
-
[31]
wall clock
= (1 −η 0)2 + 2η0(1 −η 0), and using the inequality ⟨M1, M2⟩ ≤ ∥M 1∥F ∥M2∥F to absorb term(A.28) using the η2 1 prefactor. This second argument is allowed by the assumed boundedness of∥E[∇2 hΨ(mj,t + Gt, Yj,¯at)]∥F (Assumption A.3 (4) (b)), the boundedness of∥ωt∥F, ∥Σt[t, t]∥F independent of time t∈ [T ]and recognizing that ∥ℓk,tℓ⊤ k′,t∥F ≤ ∥ℓ k,t∥F ∥ℓk′,...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.