Recognition: unknown
Prediction-powered Inference by Mixture of Experts
Pith reviewed 2026-05-07 05:28 UTC · model grok-4.3
The pith
A mixture-of-experts approach automatically selects the best combination of predictors to tighten semi-supervised confidence intervals.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Given a collection of predictors, the MOE-powered semi-supervised inference framework built upon prediction-powered inference seeks the mixture of experts that achieves the smallest possible variance. This adapts to the unknown performance of individual predictors, benefits from their collective predictive power, and enjoys a best-expert guarantee. Non-asymptotic theory establishes upper bounds on the coverage error of the resulting confidence intervals, and the framework applies to mean estimation, linear regression, quantile estimation, and general M-estimation.
What carries the argument
The variance-minimizing mixture of experts formed from the available predictors in the prediction-powered inference setup
If this is right
- The framework applies to mean estimation, linear regression, quantile estimation, and general M-estimation.
- It provides non-asymptotic upper bounds on the coverage error of the resulting confidence intervals.
- It adapts to the unknown performance of individual predictors and enjoys a best-expert guarantee.
- Numerical experiments confirm practical effectiveness and support the theoretical coverage bounds.
Where Pith is reading between the lines
- This approach could enable practitioners to combine predictions from multiple independently trained models without first determining which one is most accurate on the target distribution.
- Similar variance-minimizing mixtures might be incorporated into other semi-supervised methods that rely on auxiliary predictors.
- The framework suggests that ensemble weighting strategies can be derived directly from unlabeled data alone, potentially reducing the need for labeled validation sets.
Load-bearing premise
A fixed collection of predictors is available and their predictions on the unlabeled data can be used to form a variance-minimizing mixture under standard i.i.d. sampling and bounded moment conditions.
What would settle it
A simulation study in which the empirical coverage of the MOE-powered intervals falls short of the nominal level by more than the derived upper bound when the predictors have heterogeneous accuracies would falsify the coverage guarantee.
Figures





read the original abstract
The rapidly expanding artificial intelligence (AI) industry has produced diverse yet powerful prediction tools, each with its own network architecture, training strategy, data-processing pipeline, and domain-specific strengths. These tools create new opportunities for semi-supervised inference, in which labeled data are limited and expensive to obtain, whereas unlabeled data are abundant and widely available. Given a collection of predictors, we treat them as a mixture of experts (MOE) and introduce an MOE-powered semi-supervised inference framework built upon prediction-powered inference (PPI). Motivated by the variance reduction principle underlying PPI, the proposed framework seeks the mixture of experts that achieves the smallest possible variance. Compared with standard PPI, the MOE-powered inference framework adapts to the unknown performance of individual predictors, benefits from their collective predictive power, and enjoys a best-expert guarantee. The framework is flexible and applies to mean estimation, linear regression, quantile estimation, and general M-estimation. We develop non-asymptotic theory for the MOE-powered inference framework and establish upper bounds on the coverage error of the resulting confidence intervals. Numerical experiments demonstrate the practical effectiveness of MOE-powered inference and corroborate our theoretical findings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces an MOE-powered semi-supervised inference framework that extends prediction-powered inference (PPI) by treating a collection of predictors as experts and selecting the variance-minimizing mixture. It claims that this approach adapts to unknown predictor performance, benefits from collective predictive power, enjoys a best-expert guarantee, and applies to mean estimation, linear regression, quantile estimation, and general M-estimation. Non-asymptotic theory is developed with upper bounds on coverage error of the resulting confidence intervals, supported by numerical experiments.
Significance. If the non-asymptotic coverage bounds hold with data-driven mixture weights, the work would meaningfully extend PPI to heterogeneous predictor collections common in modern AI, offering adaptive variance reduction and a best-expert property without requiring oracle knowledge of individual predictor quality. The flexibility across estimation problems and emphasis on finite-sample guarantees are potentially valuable contributions to semi-supervised inference.
major comments (2)
- [§3 and §4] §3 (MOE-PPI construction) and §4 (non-asymptotic theory): The coverage-error bounds are stated for the MOE estimator, yet the mixture weights are chosen by minimizing an empirical variance that depends on the finite labeled sample. The provided bounds appear to treat the weights as fixed/oracle rather than estimated; the additional term arising from weight estimation error is not controlled, which can cause the coverage guarantee to fail at the claimed rate when the labeled set is small or the number of experts grows. This directly affects the adaptation and best-expert claims emphasized in the abstract.
- [§4, Theorem 1] Theorem 1 (or the main coverage theorem in §4): The best-expert guarantee is asserted, but it is unclear whether the result is for the oracle-optimal weights or the data-driven weights actually used in the procedure. If the latter, the proof must include a uniform deviation bound between the empirical and population variance minimizers; without it the guarantee reduces to an oracle statement that does not support the practical method.
minor comments (2)
- [§4] The precise regularity conditions (moment bounds, boundedness of predictors, etc.) required for the non-asymptotic results should be stated explicitly in the main text rather than only in the appendix.
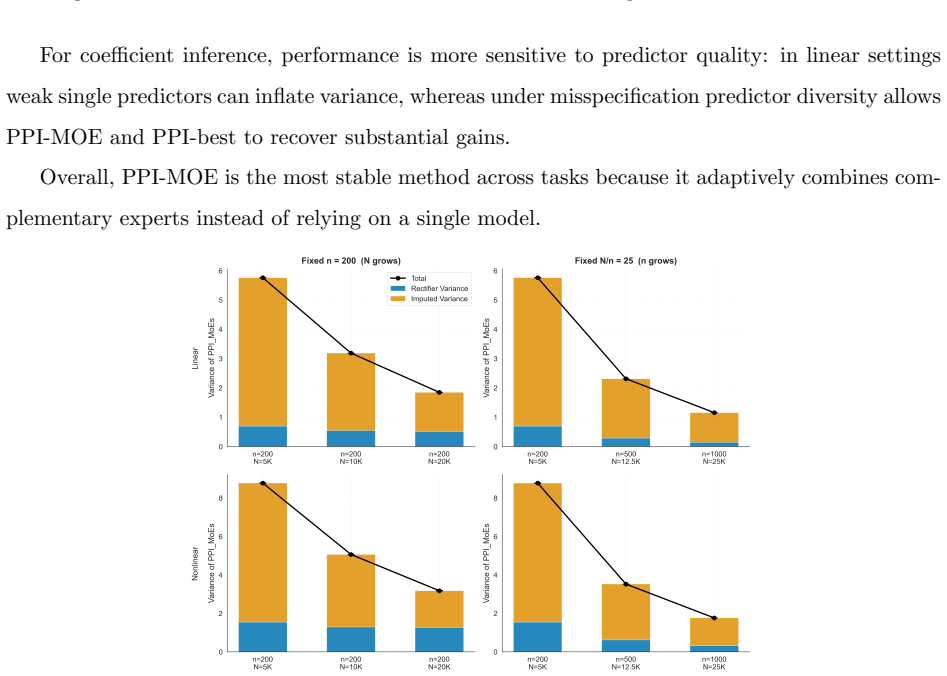
- [§5] Figure 1 and the experimental protocol: more detail is needed on how the labeled-set size interacts with the number of experts and whether empirical coverage is reported for the data-driven weights (not just oracle weights).
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive comments on our manuscript. The points raised correctly identify that the current non-asymptotic analysis assumes fixed weights and that the best-expert guarantee is stated for oracle weights. We address both issues below by outlining additional analysis that will be incorporated in the revision. We believe these clarifications will strengthen the paper without altering its core contributions.
read point-by-point responses
-
Referee: [§3 and §4] The coverage-error bounds are stated for the MOE estimator, yet the mixture weights are chosen by minimizing an empirical variance that depends on the finite labeled sample. The provided bounds appear to treat the weights as fixed/oracle rather than estimated; the additional term arising from weight estimation error is not controlled, which can cause the coverage guarantee to fail at the claimed rate when the labeled set is small or the number of experts grows. This directly affects the adaptation and best-expert claims emphasized in the abstract.
Authors: We agree that the coverage bounds in Section 4 are currently derived for fixed (oracle) mixture weights. The procedure in Section 3 uses data-driven weights obtained by minimizing the empirical variance on the labeled sample. To close this gap, we will add a new lemma that controls the weight estimation error via concentration inequalities on the empirical variance estimates. Under the standard boundedness assumption on the predictors (already implicit in PPI analyses), the deviation between the empirical and population variance minimizers is O_p(1/sqrt(m)) with m the labeled sample size. This term will be inserted into the coverage-error bound, preserving the overall rate. We will revise the statement of the main theorem and the discussion in Sections 3 and 4 to make explicit that the guarantees apply to the data-driven weights with this additional (vanishing) term. The adaptation and best-expert claims will be restated with the appropriate qualification. revision: yes
-
Referee: [§4, Theorem 1] The best-expert guarantee is asserted, but it is unclear whether the result is for the oracle-optimal weights or the data-driven weights actually used in the procedure. If the latter, the proof must include a uniform deviation bound between the empirical and population variance minimizers; without it the guarantee reduces to an oracle statement that does not support the practical method.
Authors: We acknowledge that the best-expert guarantee in the current Theorem 1 applies to the oracle weights. For the data-driven weights actually used, we will augment the proof with a uniform deviation bound between the empirical and population variance objectives. Because the mixture weights lie in the probability simplex and the variance functional is Lipschitz continuous under bounded predictors, standard empirical-process arguments (or a direct application of Hoeffding's inequality to the finite number of experts) yield a uniform deviation of order O(sqrt(log K / m)) with high probability, where K is the number of experts. Consequently, the data-driven MOE achieves a variance within this additive term of the best expert. We will insert this lemma into the proof of Theorem 1, update the theorem statement, and clarify in the text that the practical method inherits an approximate best-expert property. This directly supports the claims in the abstract. revision: yes
Circularity Check
MOE-PPI derivation remains self-contained; weights estimated from data and non-asymptotic bounds derived under standard conditions without reduction to inputs
full rationale
The abstract and provided context describe a framework that extends PPI by selecting mixture weights to minimize empirical variance on the labeled sample, then derives non-asymptotic coverage bounds for the resulting intervals under i.i.d. sampling and bounded-moment assumptions. No quoted equations or sections exhibit self-definition (e.g., a quantity defined in terms of itself), a fitted parameter relabeled as a prediction, or a load-bearing self-citation that collapses the central claim. The best-expert guarantee follows directly from the variance-minimization objective applied to the given collection of predictors, which is an independent modeling choice rather than a tautology. The theory is presented as building on but not presupposing the target result, satisfying the criteria for a self-contained derivation.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Data points are i.i.d. samples from an unknown distribution
- domain assumption A fixed collection of predictors is available whose outputs on unlabeled data can be observed
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774,
work page internal anchor Pith review arXiv
-
[2]
arXiv preprint arXiv:2311.01453 , year=
Anastasios N Angelopoulos, Stephen Bates, Clara Fannjiang, Michael I Jordan, and Tijana Zrnic. Prediction-powered inference.Science, 382(6671):669–674, 2023a. Anastasios N Angelopoulos, John C Duchi, and Tijana Zrnic. Ppi++: Efficient prediction-powered inference.arXiv preprint arXiv:2311.01453, 2023b. Olivier Bousquet. A bennett concentration inequality ...
-
[3]
URL https://doi.org/10.1214/17-AOS1594
doi: 10.1214/17-AOS1594. URL https://doi.org/10.1214/17-AOS1594. Olivier Chapelle, Bernhard Scholkopf, and Alexander Zien. Semi-supervised learning (chapelle, o. et al., eds.; 2006)[book reviews].IEEE Transactions on Neural Networks, 20(3):542–542,
-
[4]
Vladimir Koltchinskii.Oracle inequalities in empirical risk minimization and sparse recovery prob- lems: Ecole D’Et´ e de Probabilit´ es de Saint-Flour XXXVIII-2008, volume
2008
-
[5]
On the maximal perimeter of a convex set in with respect to a gaussian measure
Fedor Nazarov. On the maximal perimeter of a convex set in with respect to a gaussian measure. In Geometric Aspects of Functional Analysis: Israel Seminar 2001-2002, pages 169–187. Springer,
2001
-
[6]
Gemini: A Family of Highly Capable Multimodal Models
Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, Katie Millican, et al. Gemini: a family of highly capable multimodal models.arXiv preprint arXiv:2312.11805,
work page internal anchor Pith review arXiv
-
[7]
Zichun Xu, Daniela Witten, and Ali Shojaie. A unified framework for semiparametrically efficient semi-supervised learning.arXiv preprint arXiv:2502.17741,
-
[8]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388,
work page internal anchor Pith review arXiv
-
[9]
URLhttps://doi.org/10.1214/18-AOS1756
doi: 10.1214/ 18-AOS1756. URLhttps://doi.org/10.1214/18-AOS1756. Yuqian Zhang and Jelena Bradic. High-dimensional semi-supervised learning: in search of optimal inference of the mean.Biometrika, 109(2):387–403,
-
[10]
Moreover, by Bernstein inequality, there exists an eventE 3 withP(E 3)≥ 1−n −10 on which, ¯m(β∗)−M(β ∗) ≤C 2U r logn n , for some constantC 2 >0
On eventE 2, we have ¯m(bβn)− ¯m(β∗) − M(bβn)−M(β ∗) ≤C 1∥bβn −β ∗∥τ1 · r pq n + r plog(Dn) n , assumingn≫plog(Dn). Moreover, by Bernstein inequality, there exists an eventE 3 withP(E 3)≥ 1−n −10 on which, ¯m(β∗)−M(β ∗) ≤C 2U r logn n , for some constantC 2 >0. It implies, in the eventE 2 ∩ E3, that ¯m(bβn)−M( bβn) ≤C 1∥bβn −β ∗∥τ1 · r pq n + r plog(Dn) n...
2019
-
[11]
Applying Bousquet’s version of Talagrand’s concentration inequality (Bousquet, 2002), with prob- ability at least 1−e −t for allt >0, γn(δj)≤2Eγ n(δj) + 2τ1U δj r t n + t n
Similarly, sup β∈B∗(δj) Var g(β)−g(β ∗) ≤sup β∈B∗(δj) E g(β)−g(β ∗) 2 ≤4τ 2 1 U 2δ2 j . Applying Bousquet’s version of Talagrand’s concentration inequality (Bousquet, 2002), with prob- ability at least 1−e −t for allt >0, γn(δj)≤2Eγ n(δj) + 2τ1U δj r t n + t n . 41 It suffices to upper boundEγ n(δj). By the symmerization inequality (Koltchinskii, 2011), E...
2002
-
[12]
1 n nX i=1 bε2 i − 1 n nX i=1 (ε∗ i )2 # +
Sincem θ(β, X, Y) is bounded, by matrix Bernstein inequality, there exist an eventE 2 withP(E 2)≥1−n −10, on which max ( n−1 nX i=1 mθ∗(β∗, Xi, Yi)⊗2 −Em θ∗(β∗, X, Y) ⊗2 h n−1 nX i=1 mθ∗(β∗, Xi, Yi) i⊗2 − h Emθ∗(β∗, X, Y) i⊗2 ) =O r plogn n . (44) Combining (43) and (44), we conclude that cWθ∗,Y−F bβn −W θ∗,Y−F β∗ =O r plog(Dn) n . 45 For alls∈[p], √ne ⊤ ...
2012
-
[13]
These bounds imply that bσ2 Y−f ∗ −σ 2 Y−f ∗ = eOp r K4 logn n and bσY−f ∗ −σ Y−f ∗ bσY−f ∗ = eOp r K4 logn n , where the second inequality holds assumingσ 2 Y−f ∗ >0 andn≫K 4 logn. Observe that √n(bθMOE −θ ∗) bσY−f ∗ = √n(bθMOE −θ ∗) σY−f ∗ · 1 + σY−f ∗ −bσY−f ∗ bσY−f ∗ .(53) Applying Bernstein inequality toZ n,f∗ in (50), we get that there exists an eve...
2012
-
[14]
Consequently, we haveES 2 h(θ∗ −Y) Sh(θ∗ −f ⊤β)−S h(θ∗ −f ⊤β∗) 2 ≲h −1U 2∥β−β ∗∥2. This indicates that there exists an constantC 1 >0 such that Var Sh(θ∗ −Y) Sh(θ∗ −f ⊤β)−S h(θ∗ −f ⊤β∗) ≤ C1U 2 h ∥β−β ∗∥2,∀β∈ B ∗(δ).(55) Applying Bousquet’s version of Talagrand’s concentration inequality (Bousquet, 2002), with probability at least 1−e −t for allt >0, γn(δ...
2002
-
[15]
For the left tail termT 1n, ify≤θ ∗ −δ, then θ∗ −y h ≥ δ h
=O(h 2). For the left tail termT 1n, ify≤θ ∗ −δ, then θ∗ −y h ≥ δ h . 58 SinceSis a sigmoid function, sup y≤θ∗−δ Sh(θ∗ −y)−1 = 1− 1 1 +e −δ/h ≤exp − δ h , and consequently|T 1n| ≤qexp{−δ/h}. Similarly, for the right tail termT 3n follows|T 3n| ≤ (1−q) exp{−δ/h}. Combining the above bounds, we obtain |J1|≲h 2 +e −δ/h =O(h 2).(67) ForJ 2, we write|J 2|as E ...
2012
-
[16]
Then, on eventE 1 ∩ E4, we get √nJ2 =Σ −1 · 1√n nX i=1 Yi −f ∗(Xi)−X ⊤ i δf∗ Xi + eOp s dlog 2 n n Based on (82) and (83), we get √n(bθPPI f∗ −θ ∗) =Σ −1 · 1√n nX i=1 Yi −f ∗(Xi)−X ⊤ i δf∗ Xi + eOp r dnlogn N + s dlog 2 n n . By the multivariate Berry-Esseen theorem (Raiˇ c, 2019), we get sup U P √n bθPPI f∗ −θ ∗ ∈ U −P Tf∗ ∈ U =O r d2nlogn N + s d2 log2 ...
2019
-
[17]
concerning the Gaussian surface area of convex sets. Moreover, for a fixed indexs∈[d], we can also get sup t∈R P √n bθPPI f∗,s −θ ∗,s V∗,s ≤t −Φ(t) =O r dnlogn N + s dlog 2 n n ,(85) whereV 2 ∗,s :=e ⊤ s Σ−1 E(Y−f ∗(X)−X ⊤δf∗)2XX ⊤ Σ−1es. Step 3: Berry-Esseen bound for √n bθMOE −θ ∗ .Combining (81) and (85), we get sup t∈R P √n bθMOE s −θ ∗,s V∗,s ≤t −Φ(t...
2012
-
[18]
Task Data ModenMethod Cov. Width Ratio Code Mean inference Mean Linear 200 Conventional 0.934 45.9838 1.000 ** Mean Linear 200 PPI-best 0.956 9.6054 0.209 *** Mean Linear 200 PPI-mean 0.953 11.5188 0.250 *** Mean Linear 200 PPI-worst 0.954 16.7861 0.365 *** Mean Linear 200PPI-MOE0.952 9.4184 0.205 *** Mean Linear 500 Conventional 0.960 29.1178 1.000 ** Me...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.