Recognition: unknown
Training-Free Tunnel Defect Inspection and Engineering Interpretation via Visual Recalibration and Entity Reconstruction
Pith reviewed 2026-05-07 07:13 UTC · model grok-4.3
The pith
A training-free framework recalibrates coarse defect proposals using visual consistency to produce structured entities for tunnel engineering assessment.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
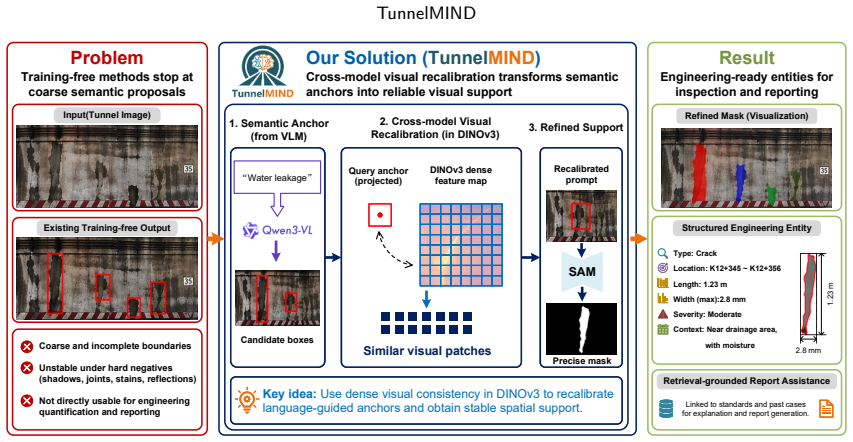
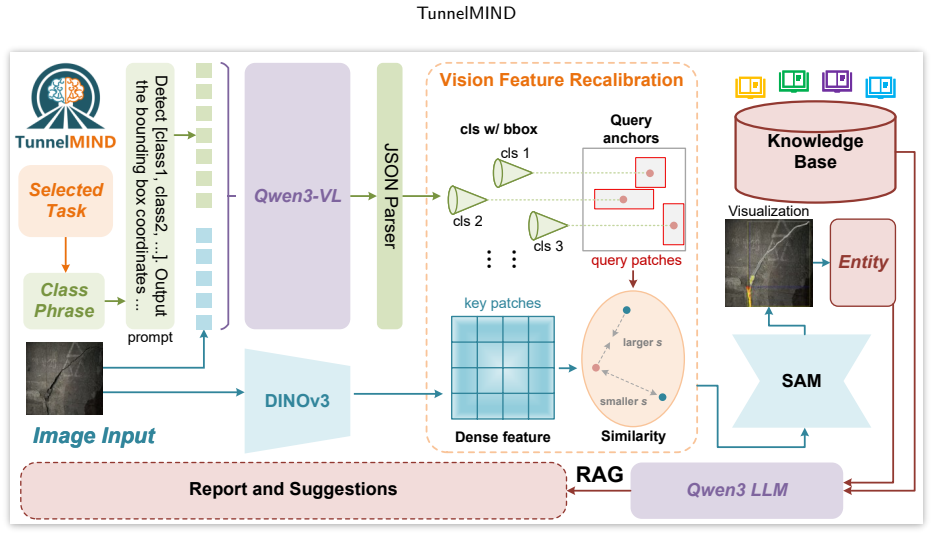
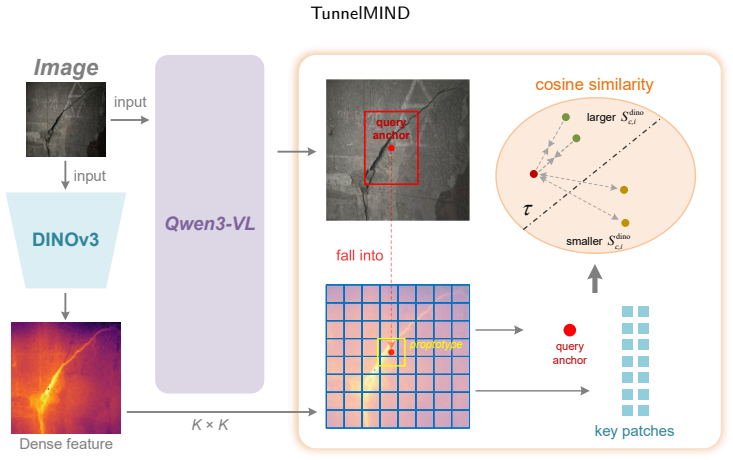
The central claim is that language-guided defect proposals need not be treated as final outputs; instead their spatial support can be recalibrated at inference time through dense visual consistency so that coarse semantic anchors transform into reliable prompts under tunnel-specific hard negatives, after which the resulting masks are reconstructed into structured defect entities equipped with category, location, geometry, severity, and context attributes that enable retrieval-grounded explanation and engineering-readable report generation under expert knowledge constraints.
What carries the argument
Dense visual consistency recalibration that converts coarse language-guided semantic anchors into accurate segmentation prompts, paired with reconstruction of masks into structured defect entities carrying multiple engineering attributes.
If this is right
- Defect inspection can operate across visible, ground-penetrating radar, and road surface imagery without any task-specific training.
- Outputs include structured attributes that feed directly into severity grading and documentation workflows.
- The pipeline generates explanations and reports grounded in expert knowledge constraints.
- Inspection can shift from coarse localization to structured defect evidence in training-free settings.
Where Pith is reading between the lines
- The recalibration step may apply to other confined, interference-heavy environments such as mines or pipelines where labeled data is scarce.
- Structured entity outputs could integrate with digital-twin or asset-management platforms to reduce manual review steps.
- Avoiding training lowers deployment barriers for specialized inspection tasks where collecting new labeled datasets is costly or impractical.
Load-bearing premise
Dense visual consistency can reliably turn coarse semantic proposals into accurate prompts inside tunnel scenes full of interference and hard negatives without creating new localization errors.
What would settle it
A collection of tunnel images with pixel-level ground-truth defect boundaries in regions of strong lighting changes, debris, or similar-looking non-defects; the method would be falsified if the recalibrated masks match the ground truth less accurately than the original unrefined proposals.
Figures








read the original abstract
Tunnel inspection requires outputs that can support defect localization, measurement, severity grading, and engineering documentation. Existing training-free foundation-model pipelines usually stop at coarse open-vocabulary proposals, which are difficult to use directly in interference-heavy tunnel scenes. We propose a training-free framework TunnelMIND. Specifically, language-guided defect proposals are not treated as final outputs; instead, their spatial support is recalibrated at inference time through dense visual consistency, so that coarse semantic anchors can be transformed into more reliable prompts under tunnel-specific hard negatives. The resulting masks are further reconstructed into structured defect entities with category, location, geometry, severity, and context attributes, which are then mapped to retrieval-grounded explanation and engineering-readable report generation under expert knowledge constraints. On visible, GPR, and road defect tasks, TunnelMIND achieves F1 scores of 0.68, 0.78, and 0.72, respectively. Overall, TunnelMIND shows that training-free tunnel inspection can move beyond coarse localization toward structured defect evidence for engineering assessment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes TunnelMIND, a training-free framework for tunnel defect inspection and engineering interpretation. Language-guided defect proposals are recalibrated using dense visual consistency to create reliable prompts in challenging tunnel scenes, then reconstructed into structured entities with attributes like category, location, geometry, severity, and context. These are used to generate retrieval-grounded explanations and reports. The framework achieves F1 scores of 0.68, 0.78, and 0.72 on visible, GPR, and road defect tasks, respectively, aiming to provide structured defect evidence beyond coarse localization.
Significance. Should the evaluation details and ablations confirm the effectiveness of the recalibration and reconstruction steps, this work would offer a valuable contribution to training-free computer vision methods for industrial applications. It tackles the practical challenge of generating engineering-usable outputs from foundation models in environments with significant interference, potentially reducing the need for task-specific training data in tunnel inspection.
major comments (3)
- [Abstract] The abstract reports F1 scores of 0.68, 0.78, and 0.72 but provides no information on the evaluation protocol, datasets used, number of samples, baselines, or error analysis. This is a load-bearing issue for the central claim, as the reported performance cannot be assessed for reliability or attribution to the proposed components without these details.
- [Visual Recalibration] The dense visual consistency recalibration is claimed to transform coarse semantic anchors into accurate prompts under tunnel-specific hard negatives, but the manuscript lacks any ablation study, before-and-after performance metrics, or specification of the consistency metric and thresholds. This prevents determining whether the step improves or potentially harms localization accuracy in interference-heavy scenes.
- [Entity Reconstruction and Experiments] No comparisons are made to the base language-guided proposals without recalibration or to other training-free methods. The F1 scores are presented only for the complete system, making it impossible to isolate the contributions of recalibration and entity reconstruction to the overall performance.
minor comments (2)
- [Abstract] The acronym 'TunnelMIND' is not expanded, which may confuse readers unfamiliar with the framework.
- [Throughout] The manuscript would benefit from more precise definitions of terms like 'dense visual consistency' and 'hard negatives' to aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and will revise the manuscript to incorporate additional evaluation details, ablations, and comparisons as requested.
read point-by-point responses
-
Referee: [Abstract] The abstract reports F1 scores of 0.68, 0.78, and 0.72 but provides no information on the evaluation protocol, datasets used, number of samples, baselines, or error analysis. This is a load-bearing issue for the central claim, as the reported performance cannot be assessed for reliability or attribution to the proposed components without these details.
Authors: We agree that the abstract should be more self-contained to support the central claims. In the revised version, we will expand the abstract to briefly describe the evaluation protocol (including how F1 is computed on defect masks), the datasets for visible, GPR, and road defect tasks with approximate sample counts, the main baselines, and a high-level note on error analysis. Full details already appear in the Experiments section, but this change will make the abstract more informative without altering its length significantly. revision: yes
-
Referee: [Visual Recalibration] The dense visual consistency recalibration is claimed to transform coarse semantic anchors into accurate prompts under tunnel-specific hard negatives, but the manuscript lacks any ablation study, before-and-after performance metrics, or specification of the consistency metric and thresholds. This prevents determining whether the step improves or potentially harms localization accuracy in interference-heavy scenes.
Authors: We acknowledge that explicit ablations are needed to validate this component. We will add a dedicated ablation study in the Experiments section reporting before-and-after F1 scores on the three defect tasks to quantify the impact of recalibration. We will also specify the dense visual consistency metric (cosine similarity over dense patch features from the vision encoder) and the exact thresholds applied for prompt refinement in the Methods section. This will allow readers to assess whether the step improves localization in hard-negative tunnel scenes. revision: yes
-
Referee: [Entity Reconstruction and Experiments] No comparisons are made to the base language-guided proposals without recalibration or to other training-free methods. The F1 scores are presented only for the complete system, making it impossible to isolate the contributions of recalibration and entity reconstruction to the overall performance.
Authors: We agree that component-wise analysis is required. In the revised manuscript, we will add experiments comparing the full TunnelMIND pipeline against (i) the base language-guided proposals without recalibration or entity reconstruction and (ii) other training-free methods (e.g., direct application of SAM or CLIP-based open-vocabulary detectors). These results will be presented alongside the existing F1 scores for the complete system, enabling isolation of each module's contribution while preserving the focus on the end-to-end framework. revision: yes
Circularity Check
No circularity: purely procedural pipeline with no derivations or self-referential reductions
full rationale
The paper presents TunnelMIND as a training-free procedural framework consisting of language-guided proposals, dense visual consistency recalibration, entity reconstruction, and report generation. No equations, first-principles derivations, fitted parameters, or mathematical claims appear in the provided text. The F1 scores (0.68/0.78/0.72) are reported as empirical outcomes on specific tasks rather than quantities obtained by construction from inputs. No self-citations are invoked to justify uniqueness theorems or ansatzes. The central steps (recalibration transforming coarse anchors, reconstruction into structured entities) are described as inference-time operations without reducing to self-definition or fitted-input renaming. This is a standard honest non-finding for a methods paper whose claims rest on implementation and evaluation rather than closed-form derivation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Qwen technical report. arXiv preprint arXiv:2309.16609 . Bai,S.,Cai,Y.,Chen,R.,Chen,K.,Chen,X.,Cheng,Z.,Deng,L.,Ding,W.,Gao,C.,Ge,C.,etal.,2025. Qwen3-vltechnicalreport. arXivpreprint arXiv:2511.21631 . Bao, W., Wang, K., Luo, S., Li, X.,
work page internal anchor Pith review arXiv 2025
-
[2]
Permitted knowledge boundary: Evaluating the knowledge-constrained responsiveness of large language models, in: EMNLP 2025-2025 Conference on Empirical Methods in Natural Language Processing, Findings of EMNLP 2025, Association for Computational Linguistics (ACL). pp. 13390–13405. Carion, N., Gustafson, L., Hu, Y.T., Debnath, S., Hu, R., Suris, D., Ryali,...
2025
-
[3]
SAM 3: Segment Anything with Concepts
Sam 3: Segment anything with concepts. arXiv preprint arXiv:2511.16719 . Carion, N., Massa, F., Synnaeve, G., Usunier, N., Kirillov, A., Zagoruyko, S.,
work page internal anchor Pith review arXiv
-
[4]
ACM transactions on intelligent systems and technology 15, 1–45
A survey on evaluation of large language models. ACM transactions on intelligent systems and technology 15, 1–45. Chen,K.,Liu,Z.,Hong,L.,Xu,H.,Li,Z.,Yeung,D.Y.,2023. Mixedautoencoderforself-supervisedvisualrepresentationlearning,in:Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 22742–22751. Cho, J., Lee, J., So, B.D...
2023
-
[5]
Automation in Construction 182, 106710
Bim-driven digital risk twins for tunnel reinforcement maintenance. Automation in Construction 182, 106710. Feng,S.J.,Feng,Y.,Zhang,X.L.,Chen,Y.H.,2023. Deeplearningwithvisualexplanationsforleakagedefectsegmentationofmetroshieldtunnel. Tunnelling and Underground Space Technology 136, 105107. Gao, Y., Xiong, Y., Gao, X., Jia, K., Pan, J., Bi, Y., Dai, Y., ...
2023
-
[6]
Retrieval-Augmented Generation for Large Language Models: A Survey
Retrieval-augmented generation for large language models: A survey. arXiv preprint arXiv:2312.10997 2,
work page internal anchor Pith review arXiv
-
[7]
arXiv preprint arXiv:2509.20787
Real-time object detection meets dinov3. arXiv preprint arXiv:2509.20787 . Jiang,Q.,Huo,J.,Chen,X.,Xiong,Y.,Zeng,Z.,Chen,Y.,Ren,T.,Yu,J.,Zhang,L.,2025. Detectanythingvianextpointprediction. arXivpreprint arXiv:2510.12798 . Khanam, R., Hussain, M.,
-
[8]
YOLOv11: An Overview of the Key Architectural Enhancements
Yolov11: An overview of the key architectural enhancements. arXiv preprint arXiv:2410.17725 . Kirillov,A.,Mintun,E.,Ravi,N.,Mao,H.,Rolland,C.,Gustafson,L.,Xiao,T.,Whitehead,S.,Berg,A.C.,Lo,W.Y.,etal.,2023. Segmentanything, in: Proceedings of the IEEE/CVF international conference on computer vision, pp. 4015–4026. Lewis, P., Perez, E., Piktus, A., Petroni,...
work page internal anchor Pith review arXiv 2023
-
[9]
Advances in neural information processing systems 33, 9459–9474
Retrieval- augmented generation for knowledge-intensive nlp tasks. Advances in neural information processing systems 33, 9459–9474. Li,F.,Zhang,H.,Sun,P.,Zou,X.,Liu,S.,Li,C.,Yang,J.,Zhang,L.,Gao,J.,2024. Segmentandrecognizeanythingatanygranularity,in:European Conference on Computer Vision, Springer. pp. 467–484. Li, L.H., Zhang, P., Zhang, H., Yang, J., L...
2024
-
[10]
arXiv preprint arXiv:2510.25257
Rt-detrv4: Painlessly furthering real-time object detection with vision foundation models. arXiv preprint arXiv:2510.25257 . Lin, T.Y., Maire, M., Belongie, S., Hays, J., Perona, P., Ramanan, D., Dollár, P., Zitnick, C.L.,
-
[11]
Microsoft coco: Common objects in context, in: European conference on computer vision, Springer. pp. 740–755. Liu, A., Feng, B., Xue, B., Wang, B., Wu, B., Lu, C., Zhao, C., Deng, C., Zhang, C., Ruan, C., et al., 2024a. Deepseek-v3 technical report. arXiv preprint arXiv:2412.19437 . Liu,S.,Zeng,Z.,Ren,T.,Li,F.,Zhang,H.,Yang,J.,Jiang,Q.,Li,C.,Yang,J.,Su,H....
work page internal anchor Pith review arXiv
-
[12]
Simple open-vocabulary object detection, in: European conference on computer vision, Springer. pp. 728–755. Myers,D.,Mohawesh,R.,Chellaboina,V.I.,Sathvik,A.L.,Venkatesh,P.,Ho,Y.H.,Henshaw,H.,Alhawawreh,M.,Berdik,D.,Jararweh,Y.,2024. Foundation and large language models: fundamentals, challenges, opportunities, and social impacts. Cluster Computing 27, 1–2...
2024
-
[13]
U-net: Convolutional networks for biomedical image segmentation, in: International Conference on Medical image computing and computer-assisted intervention, Springer. pp. 234–241. Shi,S.s.,Li,S.c.,Li,L.p.,Zhou,Z.q.,Wang,J.,2014. Advanceoptimizedclassificationandapplicationofsurroundingrockbasedonfuzzyanalytic hierarchy process and tunnel seismic predictio...
2014
-
[14]
arXiv preprint arXiv:2109.14279
Localizing objects with self-supervised transformers and no labels. arXiv preprint arXiv:2109.14279 . S. Liu et al.:Preprint submitted to ElsevierPage 26 of 27 TunnelMIND Siméoni, O., Vo, H.V., Seitzer, M., Baldassarre, F., Oquab, M., Jose, C., Khalidov, V., Szafraniec, M., Yi, S., Ramamonjisoa, M., et al.,
-
[15]
Dinov3. arXiv preprint arXiv:2508.10104 . Sjölander, A., Belloni, V., Ansell, A., Nordström, E.,
work page internal anchor Pith review arXiv
-
[16]
Kimi K2: Open Agentic Intelligence
Team,K.,Bai,Y.,Bao,Y.,Charles,Y.,Chen,C.,Chen,G.,Chen,H.,Chen,H.,Chen,J.,Chen,N.,etal.,2025. Kimik2:Openagenticintelligence. arXiv preprint arXiv:2507.20534 . Tian, Y., Ye, Q., Doermann, D.,
work page internal anchor Pith review arXiv 2025
-
[17]
YOLOv12: Attention-Centric Real-Time Object Detectors
Yolov12: Attention-centric real-time object detectors. arXiv preprint arXiv:2502.12524 . Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A.N., Kaiser, Ł., Polosukhin, I.,
work page internal anchor Pith review arXiv
-
[18]
Genericcomplianceofindustrialppebyusingdeep learning techniques
Vukicevic,A.M.,Djapan,M.,Isailovic,V.,Milasinovic,D.,Savkovic,M.,Milosevic,P.,2022. Genericcomplianceofindustrialppebyusingdeep learning techniques. Safety science 148, 105646. Wang, Y.,Shen, X., Hu,S.X., Yuan, Y.,Crowley, J.L., Vaufreydaz, D.,2022. Self-supervised transformers forunsupervised object discovery using normalized cut, in: Proceedings of the ...
2022
-
[19]
Multimodal large language models: A survey, in: 2023 IEEE International Conference on Big Data (BigData), IEEE. pp. 2247–2256. Xu, Z., Yuan, K., Wang, H., Wang, Y., Song, M., Song, J.,
2023
-
[20]
Qwen3 technical report. arXiv preprint arXiv:2505.09388 . Yu,J.,Jiang,J.,Fichera,S.,Paoletti,P.,Layzell,L.,Mehta,D.,Luo,S.,2024. Roadsurfacedefectdetection—fromimage-basedtonon-image-based: A survey. IEEE transactions on intelligent transportation Systems 25, 10581–10603. Zhang, H., Li, F., Zou, X., Liu, S., Li, C., Yang, J., Zhang, L.,
work page internal anchor Pith review arXiv 2024
-
[21]
Journal of Computing in Civil Engineering 39, 04025098
Multimodal fusion of ground-penetrating radar signals and images for tunnel lining defects detection. Journal of Computing in Civil Engineering 39, 04025098. Zhao,S.,Zhang,D.M.,Huang,H.W.,2020.Deeplearning–basedimageinstancesegmentationformoisturemarksofshieldtunnellining.Tunnelling and Underground Space Technology 95, 103156. Zhong,Y.,Yang,J.,Zhang,P.,Li...
2020
-
[22]
Construction and Building Materials 449, 138240
Tunnel lining quality detection based on the yolo-ld algorithm. Construction and Building Materials 449, 138240. Zhu,C.,Chen,L.,2024. Asurveyonopen-vocabularydetectionandsegmentation:Past,present,andfuture. IEEETransactionsonPatternAnalysis and Machine Intelligence 46, 8954–8975. Zou, X., Yang, J., Zhang, H., Li, F., Li, L., Wang, J., Wang, L., Gao, J., L...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.