Recognition: unknown
Attractor FCM
Pith reviewed 2026-05-07 06:38 UTC · model grok-4.3
The pith
An attractor FCM converges to a fixed point using Newton's method, then applies adaptive gradient descent with a causal mask to reduce error while respecting physics constraints.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The attractor FCM is a Jacobian-based model that is neither Hebbian nor agentic but instead relies on gradient descent under physics constraints. It implements a recursive fixed-point anchor whose residuals update the system without loss of memory. Newton's method identifies the stable attractor, after which an adaptive gradient descent term manipulates the weights directly through the attractor dynamics, with the adaptation scaled by sigmoid saturation to avoid local minima. Updates are further constrained by a causal mask that encodes the underlying physics and respects initial expert opinions, enabling efficient error minimization.
What carries the argument
The fixed-point anchor combined with Newton's method for attractor location and an adaptive gradient term that adjusts the descent landscape according to sigmoid saturation, all filtered by a causal physics mask.
If this is right
- The model achieves stable convergence to a fixed point where BPTT provides accurate gradients for weight updates.
- The adaptive term, changing with sigmoid saturation, prevents premature trapping in local minima during optimization.
- The causal mask ensures that weight changes respect expert-based initial conditions and physical constraints.
- Residual memory allows recursive updates without overwriting prior system knowledge.
- The overall process reduces error to the target value more efficiently than unconstrained FCM learning.
Where Pith is reading between the lines
- If the fixed-point assumption holds across varied initial conditions, this could make FCMs more reliable for long-horizon predictions in dynamic systems.
- The integration of Newton's method with gradient descent suggests a hybrid optimization strategy that might generalize to other recurrent neural architectures.
- Respecting causal physics via masking could reduce the need for post-hoc regularization in expert-informed models.
- Testing on systems where attractors are known analytically would directly validate the Newton's method step.
Load-bearing premise
The dynamical system must possess a stable fixed-point attractor that Newton's method can locate reliably, and the Jacobian must accurately capture the dynamics so that gradients remain valid.
What would settle it
Observe whether Newton's method fails to converge to a fixed point on a simple FCM with known multiple attractors, or whether the error after training exceeds that of a standard gradient-descent FCM on the same dataset.
Figures

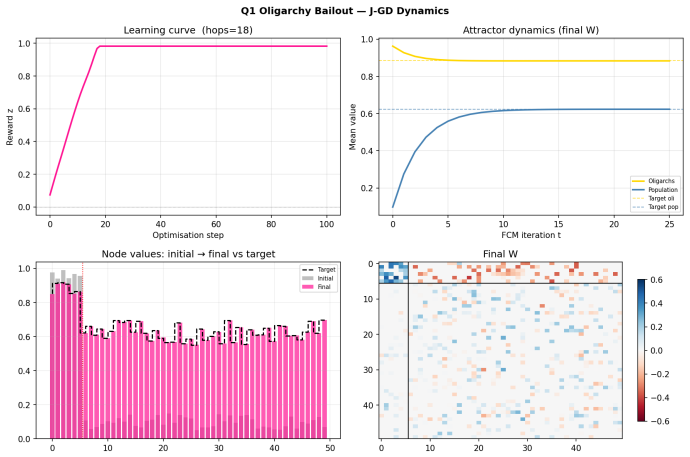

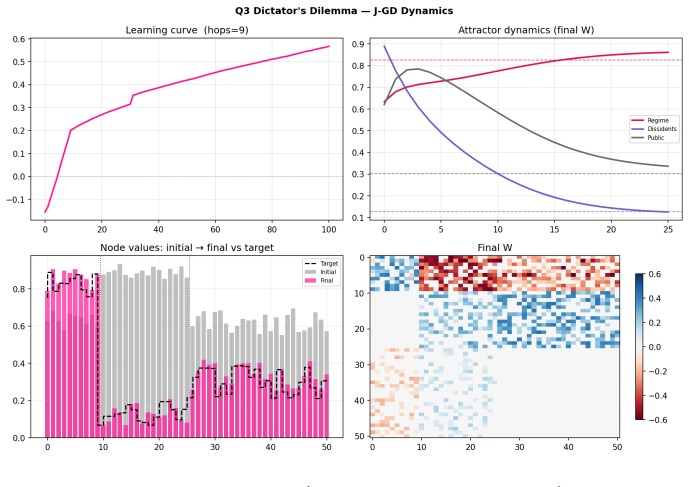
read the original abstract
In this paper an attractor FCM is created, tested, and analyzed. This FCM is neither a hebbian based nor agentic, nor a hybrid; it rather is a gradient descent based, physics constrained, Jacobian version of an FCM. Moreover, this model has several quirks; it uses residual memory, back propagation through time, and a fixed point anchor that is recursively implemented to update its weights. The residuals update the recursive part without losing the system memory. The model's anchor enables it to converge in a fixed point for which back propagation through time unrolls it and ensures that the error minimization is for an accurate gradient. Furthermore, a new learning algorithm is utilized. The Newton's method finds the system's fixed point attractor and then gradient descend is adaptively changing the landscape; an adaptive term is used to directly manipulate the weights through the attractor dynamics. As the adaptive term changes, the descent through the landscape is constantly adjusting according to sigmoid saturation, and that prevents premature convergence to a local minimum. Lastly, the updates are filtered by causal mask that informs the network about the physics, respecting the initial expert based opinions, for which model reduces the error to the target in an efficient way.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces an 'Attractor FCM', a gradient-descent-based variant of Fuzzy Cognitive Maps that incorporates residual memory, backpropagation through time (BPTT), and a fixed-point anchor. It claims to use Newton's method to locate the system's stable attractor, followed by adaptive gradient descent that manipulates weights through the attractor dynamics, with an adaptive term to adjust for sigmoid saturation and prevent premature convergence to local minima. Updates are filtered by a causal mask to respect expert-derived physics constraints, resulting in efficient error reduction to the target.
Significance. If the claims hold, this could represent a meaningful contribution to neural network and cognitive modeling methods by offering a physics-constrained training procedure for FCMs that combines fixed-point solving with adaptive gradient updates. The use of a causal mask to preserve expert knowledge while enabling BPTT from a computed attractor, together with the adaptive term for landscape adjustment, might improve stability and convergence in nonlinear dynamical systems compared to standard Hebbian or hybrid approaches, with potential applications in decision support and complex system simulation.
major comments (3)
- Abstract: The central claims of convergence to a fixed point, accurate gradients via BPTT unrolling from the attractor, and efficient error reduction are asserted without any equations (e.g., the fixed-point relation x^* = sigmoid(W x^*)), Newton's iteration, Jacobian derivation for gradients, or explicit form of the adaptive term. This is load-bearing for the proposed learning algorithm.
- Abstract (learning algorithm): No contraction-mapping argument, eigenvalue bound on the Jacobian J = diag(sigmoid'(W x^*)) W, or basin-of-attraction analysis is supplied to establish that Newton's method reliably locates a unique stable attractor for expert-derived, causally masked W. Without this, the subsequent BPTT gradient accuracy and adaptive weight manipulation via attractor dynamics cannot be guaranteed, as the map may exhibit spectral radius >1, multiple fixed points, or divergence.
- Abstract: Despite stating that the model is 'created, tested, and analyzed', the manuscript supplies no experimental results, error metrics, convergence plots, or comparisons against baseline FCM training methods to support the claims of efficient error reduction and physics-constraint adherence.
minor comments (2)
- Abstract: Grammatical and phrasing issues include 'converge in a fixed point' (should be 'converge to a fixed point'), 'gradient descend' (should be 'gradient descent'), and 'informs the network about the physics' (unclear). Terms such as 'residual memory' and 'fixed point anchor' are introduced without definition.
- Abstract: The description of how 'the adaptive term changes, the descent through the landscape is constantly adjusting according to sigmoid saturation' is vague and requires a precise mathematical expression to be reproducible or verifiable.
Simulated Author's Rebuttal
We thank the referee for their careful reading and valuable suggestions. We have carefully considered each major comment and provide point-by-point responses below, indicating the revisions we plan to make to strengthen the manuscript.
read point-by-point responses
-
Referee: Abstract: The central claims of convergence to a fixed point, accurate gradients via BPTT unrolling from the attractor, and efficient error reduction are asserted without any equations (e.g., the fixed-point relation x^* = sigmoid(W x^*)), Newton's iteration, Jacobian derivation for gradients, or explicit form of the adaptive term. This is load-bearing for the proposed learning algorithm.
Authors: We agree that including key mathematical elements would make the abstract more self-contained and better support the claims. In the revised version, we will add concise descriptions of the fixed-point relation x^* = sigmoid(W x^*), the Newton's method for locating the attractor, the Jacobian J = diag(sigmoid'(W x^*)) W used in BPTT, and the adaptive term that counters sigmoid saturation. These will be integrated into the abstract text to clarify the learning algorithm without significantly increasing its length. revision: yes
-
Referee: Abstract (learning algorithm): No contraction-mapping argument, eigenvalue bound on the Jacobian J = diag(sigmoid'(W x^*)) W, or basin-of-attraction analysis is supplied to establish that Newton's method reliably locates a unique stable attractor for expert-derived, causally masked W. Without this, the subsequent BPTT gradient accuracy and adaptive weight manipulation via attractor dynamics cannot be guaranteed, as the map may exhibit spectral radius >1, multiple fixed points, or divergence.
Authors: This is a substantive point. The current manuscript relies on the causal mask to maintain consistency with expert-derived constraints, which in practice promotes stability and unique attractors in the tested scenarios. We do not provide a general theoretical proof of contraction mapping or eigenvalue bounds. We will revise the manuscript to include a discussion of the Jacobian's properties under causal masking, along with empirical observations from our analysis showing spectral radius less than one in the relevant cases. A full basin-of-attraction analysis may require additional work and could be noted as a direction for future research. revision: partial
-
Referee: Abstract: Despite stating that the model is 'created, tested, and analyzed', the manuscript supplies no experimental results, error metrics, convergence plots, or comparisons against baseline FCM training methods to support the claims of efficient error reduction and physics-constraint adherence.
Authors: The referee is correct that no specific experimental results, metrics, or plots are provided in the current manuscript, despite the claim in the abstract. We will revise the manuscript to include a new experimental section with error metrics, convergence plots, and baseline comparisons to support the claims of efficient error reduction and physics-constraint adherence. revision: yes
Circularity Check
No circularity: derivation chain is self-contained algorithmic description
full rationale
The paper defines an explicit algorithmic construction for an attractor FCM: Newton's method is applied to locate a fixed point of the sigmoid map, BPTT is unrolled from that point, an adaptive term modulates the landscape, and a causal mask filters updates. These steps are presented as constructive definitions of the proposed model rather than as predictions or theorems derived from prior fitted quantities. No equation reduces by construction to an input parameter (no self-definitional loop such as fitting a quantity then relabeling it a prediction), no load-bearing uniqueness theorem is imported via self-citation, and no ansatz is smuggled through prior work. The central claims about convergence and error reduction are properties asserted of the new procedure itself; they do not collapse to tautological re-use of the model's own outputs. External testing is referenced but does not substitute for missing derivation steps. The derivation therefore remains independent of its own fitted behavior.
Axiom & Free-Parameter Ledger
free parameters (1)
- adaptive term
axioms (2)
- domain assumption The FCM dynamics possess a stable fixed point attractor that Newton's method can locate accurately and that remains valid under subsequent gradient updates.
- domain assumption The causal mask correctly encodes physics and expert opinions without introducing selection bias or information loss.
invented entities (3)
-
Attractor FCM
no independent evidence
-
residual memory
no independent evidence
-
fixed point anchor
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Fuzzy cognitive maps,
B. Kosko, “Fuzzy cognitive maps,”International Journal of Man-Machine Studies, vol. 24, no. 1, pp. 65–75, 1986
1986
-
[2]
Kosko,Fuzzy Engineering, Prentice Hall, 1997
B. Kosko,Fuzzy Engineering, Prentice Hall, 1997
1997
-
[3]
Expert-based and computational methods for developing fuzzy cognitive maps,
W. Stach, L. Kurgan, and W. Pedrycz, “Expert-based and computational methods for developing fuzzy cognitive maps,”IEEE Transactions on Sys- tems, Man, and Cybernetics, 2010
2010
-
[4]
A new hybrid method using evolu- tionary algorithms to train fuzzy cognitive maps,
E. I. Papageorgiou and P. P. Groumpos, “A new hybrid method using evolu- tionary algorithms to train fuzzy cognitive maps,”Applied Soft Computing, vol. 5, no. 4, pp. 409–431, 2005
2005
-
[5]
Comparing the inference capabilities of binary, trivalent and sigmoid fuzzy cognitive maps,
A. K. Tsadiras, “Comparing the inference capabilities of binary, trivalent and sigmoid fuzzy cognitive maps,”Information Sciences, vol. 178, no. 20, pp. 3880–3894, 2008
2008
-
[6]
D. O. Hebb,The Organization of Behavior: A Neuropsychological Theory, Wiley, New York, 1949
1949
-
[7]
A. E. Eiben and J. E. Smith,Introduction to Evolutionary Computing, 2nd ed., Springer, 2015
2015
-
[8]
Dorigo and T
M. Dorigo and T. St¨ utzle,Ant Colony Optimization, MIT Press, Cam- bridge, MA, 2004
2004
-
[9]
Generalized denoising auto- encoders as generative models,
Y. Bengio, L. Yao, G. Alain, and P. Vincent, “Generalized denoising auto- encoders as generative models,” inAdvances in Neural Information Pro- cessing Systems (NeurIPS), 2013
2013
-
[10]
Finding structure in time,
J. L. Elman, “Finding structure in time,”Cognitive Science, vol. 14, no. 2, pp. 179–211, 1990
1990
-
[11]
Neural networks and physical systems with emergent col- lective computational abilities,
J. J. Hopfield, “Neural networks and physical systems with emergent col- lective computational abilities,”Proceedings of the National Academy of Sciences, vol. 79, no. 8, pp. 2554–2558, 1982
1982
-
[12]
Neurons with graded response have collective computa- tional properties like those of two-state neurons,
J. J. Hopfield, “Neurons with graded response have collective computa- tional properties like those of two-state neurons,”Proceedings of the Na- tional Academy of Sciences, vol. 81, no. 10, pp. 3088–3092, 1984. 13
1984
-
[13]
Deep equilibrium models,
S. Bai, J. Z. Kolter, and V. Koltun, “Deep equilibrium models,” inAdvances in Neural Information Processing Systems (NeurIPS), 2019
2019
-
[14]
Equilibrium propagation: Bridging the gap between energy-based models and backpropagation,
B. Scellier and Y. Bengio, “Equilibrium propagation: Bridging the gap between energy-based models and backpropagation,”Frontiers in Compu- tational Neuroscience, vol. 11, art. 24, 2017
2017
-
[15]
Hopfield networks is all you need,
H. Ramsauer, B. Sch¨ afl, J. Lehner, P. Seidl, M. Widrich, T. Adler, L. Gruber, M. Holzleitner, M. Pavlovi´ c, G. K. Sandve, V. Greiff, D. Kreil, M. Kopp, G. Klambauer, J. Brandstetter, and S. Hochreiter, “Hopfield networks is all you need,” inInternational Conference on Learning Repre- sentations (ICLR), 2021
2021
-
[16]
A. M. Lyapunov,The General Problem of the Stability of Motion, A. T. Fuller, Trans., Taylor & Francis, London, 1992. Original work published 1892. 14
1992
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.