Recognition: unknown
From Mirage to Grounding: Towards Reliable Multimodal Circuit-to-Verilog Code Generation
Pith reviewed 2026-05-07 05:10 UTC · model grok-4.3
The pith
Multimodal models often generate Verilog code from circuit diagrams by ignoring the visuals and reading module names instead.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Multimodal large language models exhibit the Mirage phenomenon in circuit-to-Verilog generation: replacing a diagram with a blank image leaves or even raises Pass@k scores because the models retrieve canonical RTL templates from semantic clues in the module header rather than processing visual elements. Evaluation on the C2VEVAL benchmark under a Normal/Anony protocol shows sharp drops in Anony mode across eight models, proving prior high scores were largely textual exploitation. VeriGround, a 4B model trained with identifier anonymization, refusal augmentation, and D-ORPO preference alignment that up-weights pivotal generate-or-refuse tokens, reaches Functional Pass@1 of 46.11 percent / 42.
What carries the argument
The Mirage phenomenon, in which models bypass visual circuit content and rely on textual module-header identifiers, countered by VeriGround's training pipeline of identifier anonymization, refusal augmentation, and Decision-Focused ORPO that prioritizes generate-or-refuse token decisions.
If this is right
- Existing vision-to-code benchmarks may systematically overestimate capability whenever textual labels or captions remain available.
- Small multimodal models can match or exceed much larger ones on hardware tasks once training explicitly penalizes reliance on non-visual cues.
- Hardware design flows that use AI for RTL generation will require separate visual-grounding verification stages beyond functional simulation.
- Refusal mechanisms trained with decision-focused alignment can be applied to other safety-critical multimodal code tasks to prevent hallucinated outputs from incomplete inputs.
- The Normal/Anony paired evaluation protocol offers a general template for detecting hidden textual shortcuts in any diagram-to-code setting.
Where Pith is reading between the lines
- The same Mirage pattern is likely present in other visual-to-code domains such as UI mockups to HTML or flowchart to script generation and could be exposed by applying analogous anonymization tests.
- Future model architectures might add explicit visual feature extractors that are forced to contribute to the output even when textual context is present.
- Applying the C2VEVAL-style protocol to general image-captioning or chart-to-code benchmarks could quantify how often current MLLMs ignore pixels in favor of surrounding text.
- Preference alignment focused on early generate-or-refuse tokens may prove useful for reducing over-refusal in domains where partial visual information should still trigger an attempt.
Load-bearing premise
Anonymizing all identifiers in both the diagram and module header cleanly isolates visual grounding without introducing new biases or fundamentally altering the difficulty of the code-generation task.
What would settle it
Run VeriGround on a fresh set of circuit diagrams whose labels and headers have been independently randomized or removed after training; if Pass@1 remains near the reported Anony score while refusal on blank images stays above 92 percent, the claim of genuine visual grounding holds, otherwise the training has not succeeded in forcing diagram use.
Figures



read the original abstract
Multimodal large language models (MLLMs) are increasingly used to translate visual artifacts into code, from UI mockups into HTML to scientific plots into Python scripts. A circuit diagram can be viewed as a visual domain-specific language for hardware: it encodes timing, topology, and bit level semantics that are invisible to casual inspection yet safety critical once fabricated in silicon. Translating such diagrams into register-transfer-level(RTL) code therefore represents an extreme reliability test for vision-to-code generation. We reveal a phenomenon we call Mirage: replacing a circuit diagram with a blank image leaves Pass@k unchanged or even higher, because models bypass the visual input and instead exploit identifier semantics in the module header to retrieve canonical RTL templates. This constitutes a new, highly covert class of defect in AI-assisted code generation that directly undermines MLLMs' trustworthiness. To quantify the effect, we construct C2VEVAL and evaluate eight MLLMs under a paired Normal/Anony protocol in which Anony mode anonymizes all identifiers in both the diagram and the module header; Anony-mode scores drop sharply across all models, confirming that high Normal-mode accuracy is largely a Mirage. We then propose VeriGround (4B), trained with identifier anonymization, refusal augmentation, and D-ORPO (Decision-Focused ORPO) preference alignment that up-weights pivotal generate-or-refuse tokens. VeriGround achieves Functional Pass@1 of 46.11%/42.51%(Normal/Anony) with a False Refusal Rate of only 1.20%/0.00%, while maintaining >92% Refusal Rate on blank images. With only 4B parameters, VeriGround performs on par with GPT-5.4 under Normal and significantly outperforms all baselines under Anony, confirming genuine visual grounding.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper identifies a 'Mirage' effect in which MLLMs for circuit-diagram-to-Verilog generation ignore visual input and exploit module-header identifiers instead. It introduces the C2VEVAL benchmark and a Normal/Anony evaluation protocol (Anony anonymizes all identifiers in both diagram and header), shows sharp Pass@k drops for eight baseline MLLMs under Anony, and presents VeriGround (4B), trained via identifier anonymization, refusal augmentation, and D-ORPO. VeriGround reports Functional Pass@1 of 46.11%/42.51% (Normal/Anony), false-refusal rates of 1.20%/0.00%, and >92% refusal on blank images, matching GPT-5.4 under Normal and outperforming baselines under Anony.
Significance. If the central claim holds, the work is significant because it exposes a covert, high-stakes failure mode in vision-to-code systems for hardware design, where incorrect RTL can lead to silicon errors. The construction of a paired benchmark that forces visual reliance, the refusal mechanisms, and the demonstration that a 4B model can match much larger models when shortcuts are removed are practical contributions. The D-ORPO alignment focused on generate-or-refuse decisions offers a reusable technique for improving grounding in other multimodal code-generation settings.
major comments (3)
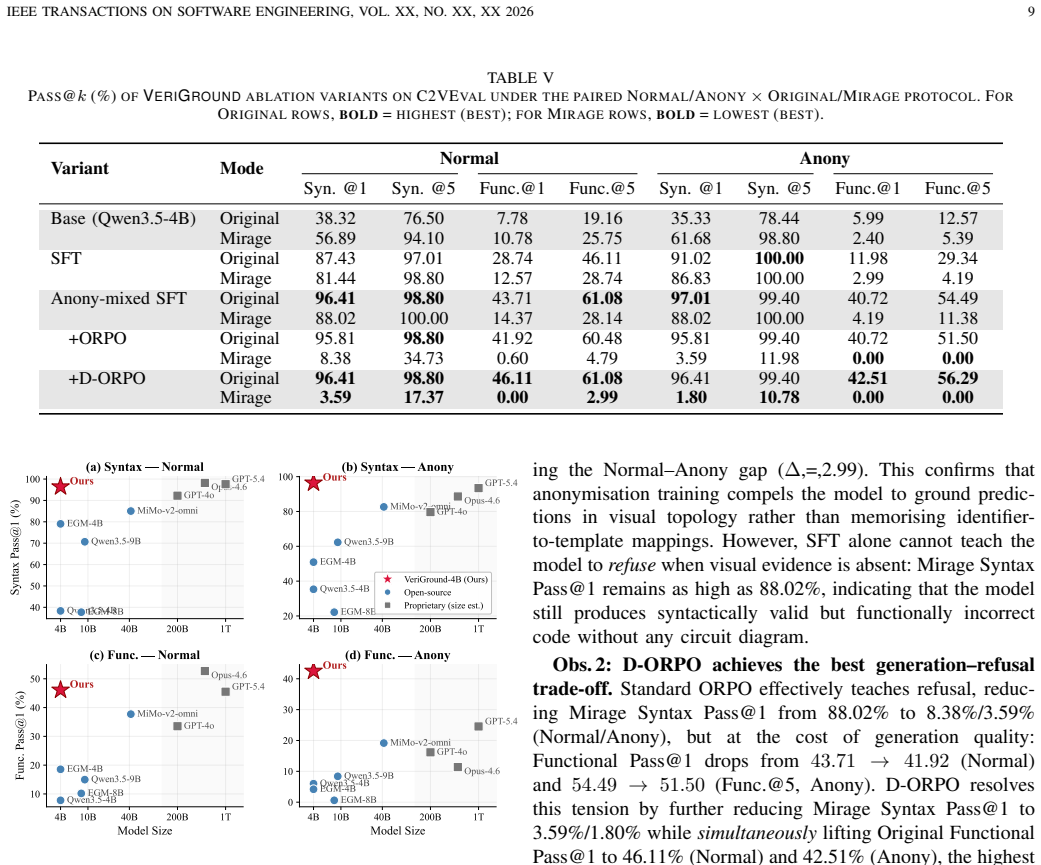
- [§4.1] §4.1 (C2VEVAL and Anony protocol): The claim that Anony mode 'cleanly isolates visual grounding' is load-bearing for the central result, yet the manuscript provides no ablation or analysis showing that identifier anonymization leaves visual parsing difficulty, text rendering in diagrams, and the distribution of plausible RTL topologies unchanged. If anonymization systematically alters any of these factors, VeriGround's maintained 42.51% Anony score may reflect adaptation to the modified training distribution rather than robust diagram-to-RTL grounding.
- [§5.3] §5.3 (Experimental results): Functional Pass@1, false-refusal, and blank-image refusal rates are reported as point estimates without error bars, statistical significance tests, or details on the number of samples per circuit or prompting templates used for the eight baselines. This makes it impossible to assess whether the small Normal-to-Anony drop for VeriGround (46.11% → 42.51%) is meaningful or whether the outperformance under Anony is robust across random seeds and prompt variations.
- [§3] §3 (Mirage phenomenon): The definition and quantification of the Mirage effect rely on the paired Normal/Anony protocol, but the paper does not report how many circuits were excluded or modified during anonymization, nor any human validation that the anonymized diagrams remain semantically equivalent and visually parseable at the same level of difficulty.
minor comments (3)
- [Abstract] The term 'GPT-5.4' appears in the abstract and results without clarification of the exact model version or API used; this should be specified for reproducibility.
- [§5] Notation for Functional Pass@1 versus syntactic Pass@1 is introduced but not consistently defined in the main text; a short table or equation would improve clarity.
- [§5.2] The description of D-ORPO mentions 'pivotal generate-or-refuse tokens' but does not include the exact loss formulation or the construction of the preference pairs; a short appendix equation would help.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments, which help clarify key aspects of our work on the Mirage effect and VeriGround. We address each major comment point by point below, providing clarifications and committing to revisions that strengthen the manuscript without altering its core claims.
read point-by-point responses
-
Referee: [§4.1] §4.1 (C2VEVAL and Anony protocol): The claim that Anony mode 'cleanly isolates visual grounding' is load-bearing for the central result, yet the manuscript provides no ablation or analysis showing that identifier anonymization leaves visual parsing difficulty, text rendering in diagrams, and the distribution of plausible RTL topologies unchanged. If anonymization systematically alters any of these factors, VeriGround's maintained 42.51% Anony score may reflect adaptation to the modified training distribution rather than robust diagram-to-RTL grounding.
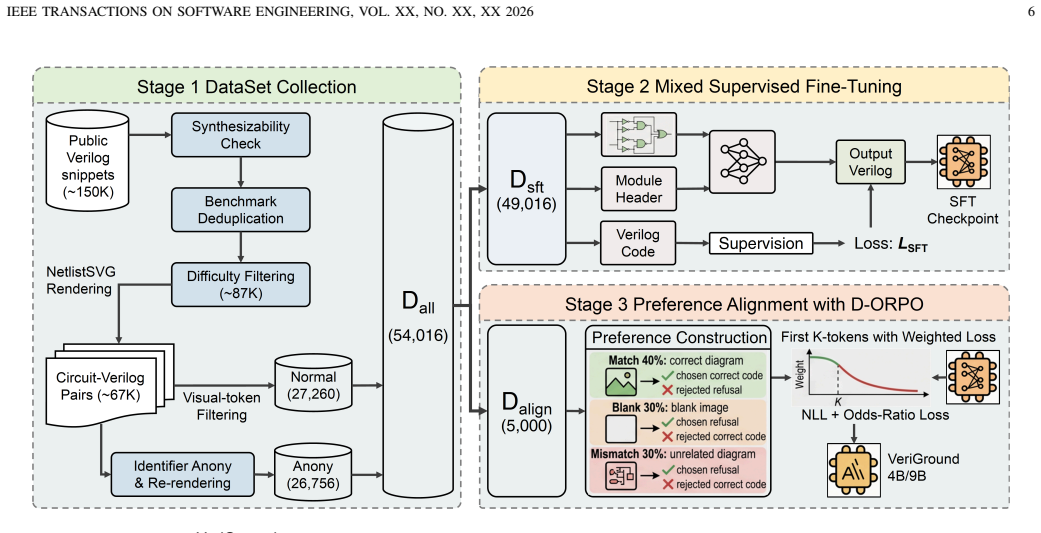
Authors: We agree that explicit validation of the Anony protocol's neutrality is necessary to support the isolation claim. In the revised manuscript, we will add an ablation analysis in §4.1 comparing Normal and Anony versions on visual parsing difficulty (measured via OCR accuracy on rendered text and diagram entropy), text rendering fidelity, and RTL topology distributions (gate counts, fan-in/out, and connectivity graphs). Our internal checks confirm that anonymization targets only identifier strings while preserving schematic visuals, connectivity, and logical structure, with negligible shifts in these metrics. This addition will demonstrate that VeriGround's Anony performance reflects genuine visual grounding rather than adaptation to a shifted distribution. revision: yes
-
Referee: [§5.3] §5.3 (Experimental results): Functional Pass@1, false-refusal, and blank-image refusal rates are reported as point estimates without error bars, statistical significance tests, or details on the number of samples per circuit or prompting templates used for the eight baselines. This makes it impossible to assess whether the small Normal-to-Anony drop for VeriGround (46.11% → 42.51%) is meaningful or whether the outperformance under Anony is robust across random seeds and prompt variations.
Authors: We acknowledge that the current results lack the statistical rigor needed for robust interpretation. In the revision, we will expand §5.3 to report error bars (standard deviation across 5 random seeds), the exact evaluation setup (200 circuits in C2VEVAL, each evaluated with 5 prompting templates per baseline model), and paired statistical tests (e.g., McNemar's test or t-tests) between Normal and Anony conditions. These additions will show that VeriGround's small drop is not statistically significant while its Anony outperformance remains consistent across variations. revision: yes
-
Referee: [§3] §3 (Mirage phenomenon): The definition and quantification of the Mirage effect rely on the paired Normal/Anony protocol, but the paper does not report how many circuits were excluded or modified during anonymization, nor any human validation that the anonymized diagrams remain semantically equivalent and visually parseable at the same level of difficulty.
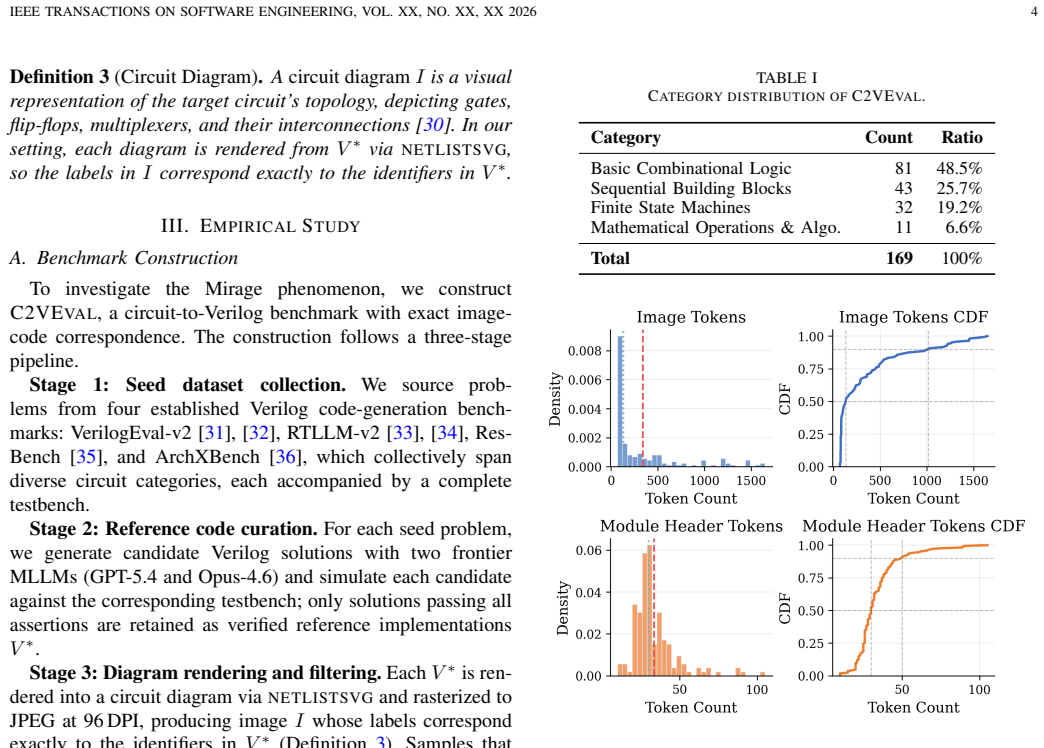
Authors: We will revise §3 to include full details on the anonymization pipeline and validation. From an initial pool of 250 circuits sourced from open repositories, 50 were excluded due to rendering failures or identifier conflicts, resulting in the final 200-circuit C2VEVAL set. We will also report a human validation study involving three RTL engineers who rated semantic equivalence and visual parseability of 100 sampled anonymized diagrams on 5-point Likert scales (average scores: 4.7 for equivalence, 4.5 for parseability, with inter-rater kappa > 0.8). These additions confirm that the Mirage quantification rests on diagrams of equivalent difficulty. revision: yes
Circularity Check
No significant circularity in empirical evaluation and training pipeline
full rationale
The paper's central claims rest on direct experimental measurements: construction of the C2VEVAL benchmark, paired Normal/Anony evaluations across eight MLLMs, and training of the 4B VeriGround model via identifier anonymization, refusal augmentation, and D-ORPO preference alignment. Reported Functional Pass@1, False Refusal Rate, and blank-image refusal statistics are obtained from model inference and human/functional verification on held-out test cases; they are not computed from any fitted parameters, self-referential equations, or derivations that loop back to the inputs. The Anony-mode anonymization is an explicit methodological control whose effect is measured rather than assumed by construction. No load-bearing step reduces to a tautology, self-citation chain, or renamed known result. The work is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Anonymization of identifiers in both diagram and header isolates visual input without introducing confounding changes to task semantics
invented entities (1)
-
Mirage effect
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Auto-icon: An automated code generation tool for icon designs assisting in ui development,
S. Feng, S. Ma, J. Yu, C. Chen, T. Zhou, and Y . Zhen, “Auto-icon: An automated code generation tool for icon designs assisting in ui development,” inProceedings of the 26th International Conference on Intelligent User Interfaces, 2021, pp. 59–69
2021
-
[2]
Prototype2code: End-to-end front-end code generation from ui design prototypes,
S. Xiao, Y . Chen, J. Li, L. Chen, L. Sun, and T. Zhou, “Prototype2code: End-to-end front-end code generation from ui design prototypes,” in International Design Engineering Technical Conferences and Computers and Information in Engineering Conference, vol. 88353. American Society of Mechanical Engineers, 2024, p. V02BT02A038
2024
-
[3]
Uicopilot: Automating ui synthesis via hierarchical code generation from webpage designs,
Y . Gui, Y . Wan, Z. Li, Z. Zhang, D. Chen, H. Zhang, Y . Su, B. Chen, X. Zhou, W. Jianget al., “Uicopilot: Automating ui synthesis via hierarchical code generation from webpage designs,” inProceedings of the ACM on Web Conference 2025, 2025, pp. 1846–1855
2025
-
[4]
Declarui: Bridging design and development with automated declarative ui code generation,
T. Zhou, Y . Zhao, X. Hou, X. Sun, K. Chen, and H. Wang, “Declarui: Bridging design and development with automated declarative ui code generation,”Proceedings of the ACM on Software Engineering, vol. 2, no. FSE, pp. 219–241, 2025
2025
-
[5]
Interaction2code: Benchmarking mllm-based interactive webpage code generation from interactive prototyping,
J. Xiao, Y . Wan, Y . Huo, Z. Wang, X. Xu, W. Wang, Z. Xu, Y . Wang, and M. R. Lyu, “Interaction2code: Benchmarking mllm-based interactive webpage code generation from interactive prototyping,” in2025 40th IEEE/ACM International Conference on Automated Software Engineer- ing (ASE). IEEE, 2025, pp. 241–253
2025
-
[6]
Divide-and-conquer: Generating ui code from screenshots,
Y . Wan, C. Wang, Y . Dong, W. Wang, S. Li, Y . Huo, and M. Lyu, “Divide-and-conquer: Generating ui code from screenshots,”Proceed- ings of the ACM on Software Engineering, vol. 2, no. FSE, pp. 2099– 2122, 2025. IEEE TRANSACTIONS ON SOFTW ARE ENGINEERING, VOL. XX, NO. XX, XX 2026 13
2099
-
[7]
Plot2code: A comprehensive benchmark for evaluating multi- modal large language models in code generation from scientific plots,
C. Wu, Z. Liang, Y . Ge, Q. Guo, Z. Lu, J. Wang, Y . Shan, and P. Luo, “Plot2code: A comprehensive benchmark for evaluating multi- modal large language models in code generation from scientific plots,” inFindings of the Association for Computational Linguistics: NAACL 2025, 2025, pp. 3006–3028
2025
-
[8]
Chartcoder: Advancing multimodal large language model for chart- to-code generation,
X. Zhao, X. Luo, Q. Shi, C. Chen, S. Wang, Z. Liu, and M. Sun, “Chartcoder: Advancing multimodal large language model for chart- to-code generation,” inProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2025, pp. 7333–7348
2025
-
[9]
Dscodebench: A realistic benchmark for data science code generation,
S. Ouyang, D. Huang, J. Guo, Z. Sun, Q. Zhu, and J. M. Zhang, “Dscodebench: A realistic benchmark for data science code generation,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 40, no. 38, 2026, pp. 32 628–32 636
2026
-
[10]
Vgv: Verilog generation using visual capabilities of multi-modal large language models,
S.-Z. Wong, G.-W. Wan, D. Liu, and X. Wang, “Vgv: Verilog generation using visual capabilities of multi-modal large language models,” in2024 IEEE LLM Aided Design Workshop (LAD). IEEE, 2024, pp. 1–5
2024
-
[11]
Mgemmv: A multimodal llm framework for gemm verilog generation from circuit diagrams,
G. Zhang, M. Wang, and Z. Wang, “Mgemmv: A multimodal llm framework for gemm verilog generation from circuit diagrams,”IEEE Transactions on Circuits and Systems I: Regular Papers, 2026
2026
-
[12]
Large language model for verilog code generation: Literature review and the road ahead,
G. Yang, W. Zheng, X. Chen, D. Liang, P. Hu, Y . Yang, S. Peng, Z. Li, J. Feng, X. Weiet al., “Large language model for verilog code generation: Literature review and the road ahead,”arXiv preprint arXiv:2512.00020, 2025
-
[13]
A survey of research in large language models for electronic design automation,
J. Pan, G. Zhou, C.-C. Chang, I. Jacobson, J. Hu, and Y . Chen, “A survey of research in large language models for electronic design automation,” ACM Transactions on Design Automation of Electronic Systems, vol. 30, no. 3, pp. 1–21, 2025
2025
-
[14]
Mirage the illusion of visual understanding.arXiv preprint arXiv:2603.21687, 2026
M. Asadi, J. W. O’Sullivan, F. Cao, T. Nedaee, K. Fardi, F.-F. Li, E. Adeli, and E. Ashley, “Mirage the illusion of visual understanding,” arXiv preprint arXiv:2603.21687, 2026
-
[15]
Orpo: Monolithic preference optimiza- tion without reference model,
J. Hong, N. Lee, and J. Thorne, “Orpo: Monolithic preference optimiza- tion without reference model,” inProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, 2024, pp. 11 170– 11 189
2024
-
[16]
Multimodal large language models: A survey,
J. Wu, W. Gan, Z. Chen, S. Wan, and P. S. Yu, “Multimodal large language models: A survey,” in2023 IEEE International Conference on Big Data (BigData). IEEE, 2023, pp. 2247–2256
2023
-
[17]
A survey on multimodal large language models,
S. Yin, C. Fu, S. Zhao, K. Li, X. Sun, T. Xu, and E. Chen, “A survey on multimodal large language models,”National Science Review, vol. 11, no. 12, p. nwae403, 2024
2024
-
[18]
A survey on vision transformer,
K. Han, Y . Wang, H. Chen, X. Chen, J. Guo, Z. Liu, Y . Tang, A. Xiao, C. Xu, Y . Xuet al., “A survey on vision transformer,”IEEE transactions on pattern analysis and machine intelligence, vol. 45, no. 1, pp. 87–110, 2022
2022
-
[19]
Swin transformer: Hierarchical vision transformer using shifted windows,
Z. Liu, Y . Lin, Y . Cao, H. Hu, Y . Wei, Z. Zhang, S. Lin, and B. Guo, “Swin transformer: Hierarchical vision transformer using shifted windows,” inProceedings of the IEEE/CVF international conference on computer vision, 2021, pp. 10 012–10 022
2021
-
[20]
Transformers in vision: A survey,
S. Khan, M. Naseer, M. Hayat, S. W. Zamir, F. S. Khan, and M. Shah, “Transformers in vision: A survey,”ACM computing surveys (CSUR), vol. 54, no. 10s, pp. 1–41, 2022
2022
-
[21]
Llava-onevision: Easy visual task transfer,
B. Li, Y . Zhang, D. Guo, R. Zhang, F. Li, H. Zhang, K. Zhang, P. Zhang, Y . Li, Z. Liuet al., “Llava-onevision: Easy visual task transfer,”Transactions on Machine Learning Research
-
[22]
Llava-med: Training a large language-and-vision assistant for biomedicine in one day,
C. Li, C. Wong, S. Zhang, N. Usuyama, H. Liu, J. Yang, T. Naumann, H. Poon, and J. Gao, “Llava-med: Training a large language-and-vision assistant for biomedicine in one day,”Advances in Neural Information Processing Systems, vol. 36, pp. 28 541–28 564, 2023
2023
-
[23]
Llava-more: A comparative study of llms and visual backbones for enhanced visual instruction tuning,
F. Cocchi, N. Moratelli, D. Caffagni, S. Sarto, L. Baraldi, M. Cornia, and R. Cucchiara, “Llava-more: A comparative study of llms and visual backbones for enhanced visual instruction tuning,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2025, pp. 4278–4288
2025
-
[24]
Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks,
Z. Chen, J. Wu, W. Wang, W. Su, G. Chen, S. Xing, M. Zhong, Q. Zhang, X. Zhu, L. Luet al., “Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2024, pp. 24 185–24 198
2024
-
[25]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
W. Wang, Z. Gao, L. Gu, H. Pu, L. Cui, X. Wei, Z. Liu, L. Jing, S. Ye, J. Shaoet al., “Internvl3. 5: Advancing open-source multi- modal models in versatility, reasoning, and efficiency,”arXiv preprint arXiv:2508.18265, 2025
work page internal anchor Pith review arXiv 2025
-
[26]
Gemini: A Family of Highly Capable Multimodal Models
G. Team, R. Anil, S. Borgeaud, J.-B. Alayrac, J. Yu, R. Soricut, J. Schalkwyk, A. M. Dai, A. Hauth, K. Millicanet al., “Gemini: a family of highly capable multimodal models,”arXiv preprint arXiv:2312.11805, 2023
work page internal anchor Pith review arXiv 2023
-
[27]
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
G. Team, P. Georgiev, V . I. Lei, R. Burnell, L. Bai, A. Gulati, G. Tanzer, D. Vincent, Z. Pan, S. Wanget al., “Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context,”arXiv preprint arXiv:2403.05530, 2024
work page internal anchor Pith review arXiv 2024
-
[28]
A. Hurst, A. Lerer, A. P. Goucher, A. Perelman, A. Ramesh, A. Clark, A. Ostrow, A. Welihinda, A. Hayes, A. Radfordet al., “Gpt-4o system card,”arXiv preprint arXiv:2410.21276, 2024
work page internal anchor Pith review arXiv 2024
-
[29]
Navabi,Verilog digital system design
Z. Navabi,Verilog digital system design. McGraw-Hill, 1999
1999
-
[30]
R. W. Mehler,Digital integrated circuit design using verilog and systemverilog. Elsevier, 2014
2014
-
[31]
Verilogeval: Evaluating large language models for verilog code generation,
M. Liu, N. Pinckney, B. Khailany, and H. Ren, “Verilogeval: Evaluating large language models for verilog code generation,” in2023 IEEE/ACM International Conference on Computer Aided Design (ICCAD). IEEE, 2023, pp. 1–8
2023
-
[32]
Revisiting verilogeval: A year of improvements in large-language models for hardware code generation,
N. Pinckney, C. Batten, M. Liu, H. Ren, and B. Khailany, “Revisiting verilogeval: A year of improvements in large-language models for hardware code generation,”ACM Transactions on Design Automation of Electronic Systems, vol. 30, no. 6, pp. 1–20, 2025
2025
-
[33]
Rtllm: An open-source benchmark for design rtl generation with large language model,
Y . Lu, S. Liu, Q. Zhang, and Z. Xie, “Rtllm: An open-source benchmark for design rtl generation with large language model,” in2024 29th Asia and South Pacific Design Automation Conference (ASP-DAC). IEEE, 2024, pp. 722–727
2024
-
[34]
Openllm-rtl: Open dataset and benchmark for llm-aided design rtl generation(invited),
S. Liu, Y . Lu, W. Fang, M. Li, and Z. Xie, “Openllm-rtl: Open dataset and benchmark for llm-aided design rtl generation(invited),” in Proceedings of 2024 IEEE/ACM International Conference on Computer- Aided Design (ICCAD). ACM, 2024
2024
-
[35]
Resbench: A resource-aware benchmark for llm- generated fpga designs,
C. Guo and T. Zhao, “Resbench: A resource-aware benchmark for llm- generated fpga designs,” inProceedings of the 15th International Sympo- sium on Highly Efficient Accelerators and Reconfigurable Technologies, 2025, pp. 25–34
2025
-
[36]
Archxbench: A complex digital systems benchmark suite for llm driven rtl synthesis,
S. Purini, S. Garg, M. Gaur, S. Bhat, S. Mupparapu, and A. Ravindran, “Archxbench: A complex digital systems benchmark suite for llm driven rtl synthesis,” in2025 ACM/IEEE 7th Symposium on Machine Learning for CAD (MLCAD). IEEE, 2025, pp. 1–10
2025
-
[37]
Openai api docs: Gpt-4o,
OpenAI, “Openai api docs: Gpt-4o,” 2024. [Online]. Available: https://developers.openai.com/api/docs/models/gpt-4o
2024
-
[38]
Openai api docs: Gpt-5.4,
——, “Openai api docs: Gpt-5.4,” 2026. [Online]. Available: https://developers.openai.com/api/docs/models/gpt-5.4
2026
-
[39]
Introducing claude opus 4.6,
Anthropic, “Introducing claude opus 4.6,” 2026. [Online]. Available: https://www.anthropic.com/news/claude-opus-4-6
2026
-
[40]
Xiaomi mimo-v2-omni,
Xiaomi MiMo Team, “Xiaomi mimo-v2-omni,” March 2026. [Online]. Available: https://mimo.xiaomi.com/mimo-v2-omni
2026
-
[41]
Egm: Efficient visual grounding language models,
G. Zhan, C. Li, Z. Liu, Y . Lu, Y . Wu, S. Han, and L. Zhu, “Egm: Efficient visual grounding language models,” 2026
2026
-
[42]
Qwen3.5: Towards native multimodal agents,
Qwen Team, “Qwen3.5: Towards native multimodal agents,” February
-
[43]
Available: https://qwen.ai/blog?id=qwen3.5
[Online]. Available: https://qwen.ai/blog?id=qwen3.5
-
[44]
Evaluating Large Language Models Trained on Code
M. Chen, J. Tworek, H. Jun, Q. Yuan, H. P. de Oliveira Pinto, J. Kaplan, H. Edwards, Y . Burda, N. Joseph, G. Brockman, A. Ray, R. Puri, G. Krueger, M. Petrov, H. Khlaaf, G. Sastry, P. Mishkin, B. Chan, S. Gray, N. Ryder, M. Pavlov, A. Power, L. Kaiser, M. Bavarian, C. Winter, P. Tillet, F. P. Such, D. Cummings, M. Plappert, F. Chantzis, E. Barnes, A. Her...
work page internal anchor Pith review arXiv 2021
-
[45]
Semantic consensus decod- ing: Backdoor defense for verilog code generation,
G. Yang, X. Hu, X. Chen, and X. Xia, “Semantic consensus decod- ing: Backdoor defense for verilog code generation,”arXiv preprint arXiv:2602.04195, 2026
-
[46]
Qimeng-codev-r1: Reasoning-enhanced verilog generation,
Y . Zhu, D. Huang, H. Lyu, X. Zhang, C. Li, W. Shi, Y . Wu, J. Mu, J. Wang, P. Jinet al., “Qimeng-codev-r1: Reasoning-enhanced verilog generation,” inThe Thirty-ninth Annual Conference on Neural Informa- tion Processing Systems
-
[47]
Yosys-a free verilog synthesis suite,
C. Wolf, J. Glaser, and J. Kepler, “Yosys-a free verilog synthesis suite,” inProceedings of the 21st Austrian Workshop on Microelectronics (Austrochip), vol. 97, 2013, pp. 1–6
2013
-
[48]
Rouge: A package for automatic evaluation of summaries,
C.-Y . Lin, “Rouge: A package for automatic evaluation of summaries,” inText summarization branches out, 2004, pp. 74–81
2004
-
[49]
Direct preference optimization: Your language model is secretly a reward model,
R. Rafailov, A. Sharma, E. Mitchell, C. D. Manning, S. Ermon, and C. Finn, “Direct preference optimization: Your language model is secretly a reward model,”Advances in neural information processing systems, vol. 36, pp. 53 728–53 741, 2023
2023
-
[50]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Z. Shao, P. Wang, Q. Zhu, R. Xu, J. Song, X. Bi, H. Zhang, M. Zhang, Y . Liet al., “Deepseekmath: Pushing the limits of mathematical reason- ing in open language models,”arXiv preprint arXiv:2402.03300, 2024. IEEE TRANSACTIONS ON SOFTW ARE ENGINEERING, VOL. XX, NO. XX, XX 2026 14
work page internal anchor Pith review arXiv 2024
-
[51]
Lora: Low-rank adaptation of large language models
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, W. Chenet al., “Lora: Low-rank adaptation of large language models.” Iclr, vol. 1, no. 2, p. 3, 2022
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.