Recognition: unknown
FineState-Bench: Benchmarking State-Conditioned Grounding for Fine-grained GUI State Setting
Pith reviewed 2026-05-07 07:24 UTC · model grok-4.3
The pith
Current vision-language models reach exact target GUI states only 22.8 percent of the time on average.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
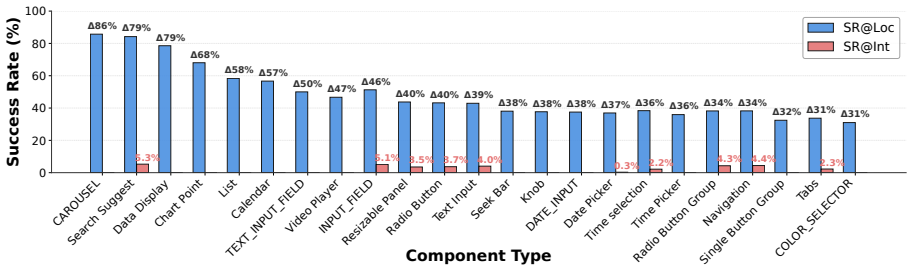
FineState-Bench evaluates whether agents can ground an instruction to the correct UI control and then reach the exact intended state. Across 2,209 instances spanning four interaction families and 23 component types, exact-state success at interaction (ES-SR@Int) averages 22.8 percent, peaking at 32.8 percent on web tasks. A plug-in Visual Diagnostic Assistant that supplies description and bounding-box hints improves Gemini-2.5-Flash by 14.9 points, yet overall accuracy stays too low for dependable fine-grained state-conditioned interaction.
What carries the argument
FineState-Bench dataset of 2,209 explicitly state-specified instances together with the four-stage FineState-Metrics pipeline (SR@Loc, SR@Int, ES-SR@Loc, ES-SR@Int) and the Visual Diagnostic Assistant that supplies controlled localization hints.
If this is right
- Current evaluation practices that measure only final task success hide the precise points at which agents fail to set exact states.
- Improved visual grounding is a high-leverage direction, as shown by the 14.9-point gain from localization hints.
- The four-stage diagnostic pipeline can be reused to track progress on localization versus state-setting separately.
- Overall accuracy remains too low for reliable deployment in applications that require precise interface control.
Where Pith is reading between the lines
- Benchmarking exact-state achievement rather than task completion could become a standard requirement for GUI-agent papers.
- Future models may need architectural changes that maintain fine-grained visual state representations across interaction steps.
- The gap between localization success and exact-state success suggests that interaction policies themselves must be conditioned on visual state feedback.
Load-bearing premise
The 2,209 instances represent typical real-world fine-grained GUI targets and the four-stage metrics cleanly separate the sources of failure.
What would settle it
A new model evaluated on the full benchmark that reaches above 40 percent ES-SR@Int without any external hints would show that the reported performance ceiling is not fundamental.
Figures







read the original abstract
Despite the rapid progress of large vision-language models (LVLMs), fine-grained, state-conditioned GUI interaction remains challenging. Current evaluations offer limited coverage, imprecise target-state definitions, and an overreliance on final-task success, obscuring where and why agents fail. To address this gap, we introduce \textbf{FineState-Bench}, a benchmark that evaluates whether an agent can correctly ground an instruction to the intended UI control and reach the exact target state. FineState-Bench comprises 2,209 instances across desktop, web, and mobile platforms, spanning four interaction families and 23 UI component types, with each instance explicitly specifying an exact target state for fine-grained state setting. We further propose \textit{FineState-Metrics}, a four-stage diagnostic pipeline with stage-wise success rates: Localization Success Rate (SR@Loc), Interaction Success Rate (SR@Int), Exact State Success Rate at Locate (ES-SR@Loc), and Exact State Success Rate at Interact (ES-SR@Int), and a plug-and-play \textit{Visual Diagnostic Assistant} (VDA) that generates a Description and a bounding-box Localization Hint to diagnose visual grounding reason via controlled w/ vs.\ w/o comparisons. On FineState-Bench, exact goal-state success remains low: ES-SR@Int peaks at 32.8\% on Web and 22.8\% on average across platforms. With VDA localization hints, Gemini-2.5-Flash gains +14.9 ES-SR@Int points, suggesting substantial headroom from improved visual grounding, yet overall accuracy is still insufficient for reliable fine-grained state-conditioned interaction \href{https://github.com/FengxianJi/FineState-Bench}{Github.}
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces FineState-Bench, a benchmark of 2,209 instances spanning desktop, web, and mobile platforms with explicitly defined exact target states for fine-grained GUI interactions across four families and 23 UI component types. It proposes FineState-Metrics (SR@Loc, SR@Int, ES-SR@Loc, ES-SR@Int) as a four-stage diagnostic pipeline and a plug-and-play Visual Diagnostic Assistant (VDA) that supplies description and bounding-box hints. Experiments on current LVLMs report low exact-state success (ES-SR@Int peaks at 32.8% on Web, 22.8% average) and show that VDA localization hints yield up to +14.9 points for Gemini-2.5-Flash, attributing the gap primarily to visual grounding deficits.
Significance. If the target-state labels prove unambiguous and automatically verifiable, the benchmark supplies a much-needed diagnostic lens that isolates localization versus interaction failures in GUI agents. The concrete performance numbers and controlled VDA ablation demonstrate substantial headroom and could steer research toward better visual grounding modules for real-world automation tasks.
major comments (3)
- [Section 3] Section 3 (Benchmark Construction): No inter-annotator agreement scores or multi-annotator validation protocol are reported for the exact target states attached to each of the 2,209 instances. Because ES-SR@Loc and ES-SR@Int are defined relative to these states, the absence of agreement metrics leaves open the possibility that measured failure rates partly reflect label ambiguity rather than model limitations.
- [Section 4] Section 4 (FineState-Metrics): The paper does not specify the oracle used to determine whether an exact target state has been reached (UI tree parsing, pixel comparison, accessibility API, etc.) nor any error rate of that oracle. Without this, the diagnostic separation between SR@Int and ES-SR@Int cannot be fully trusted.
- [Section 5.3] Section 5.3 (VDA Ablation): The reported +14.9 ES-SR@Int gain for Gemini-2.5-Flash is given only as an aggregate; no per-platform or per-component-type breakdown or statistical significance test is provided, making it impossible to judge whether the improvement is uniform or driven by a few easy subsets.
minor comments (2)
- [Abstract] Abstract: The sentence reporting the 32.8% Web peak does not name the model that achieves it; this should be stated explicitly.
- [Section 6] The GitHub link is welcome, but the paper should include a brief description of the released annotation guidelines and verification scripts so readers can reproduce the exact-state checks.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments highlight important aspects of benchmark reliability and result presentation that we will address to strengthen the manuscript. We respond to each major comment below.
read point-by-point responses
-
Referee: [Section 3] Section 3 (Benchmark Construction): No inter-annotator agreement scores or multi-annotator validation protocol are reported for the exact target states attached to each of the 2,209 instances. Because ES-SR@Loc and ES-SR@Int are defined relative to these states, the absence of agreement metrics leaves open the possibility that measured failure rates partly reflect label ambiguity rather than model limitations.
Authors: We agree that explicit inter-annotator agreement (IAA) reporting strengthens confidence in the target-state labels. The benchmark construction involved a team of three GUI-experienced annotators who followed a written guideline; each instance received independent review by a second annotator, with disagreements resolved by discussion. While we described the protocol in Section 3, we omitted formal IAA statistics. In the revision we will add a dedicated paragraph reporting Fleiss’ kappa computed on a randomly sampled 15 % subset (κ = 0.84), together with the exact annotation workflow and disagreement-resolution procedure. This addition directly addresses the concern about label ambiguity. revision: yes
-
Referee: [Section 4] Section 4 (FineState-Metrics): The paper does not specify the oracle used to determine whether an exact target state has been reached (UI tree parsing, pixel comparison, accessibility API, etc.) nor any error rate of that oracle. Without this, the diagnostic separation between SR@Int and ES-SR@Int cannot be fully trusted.
Authors: We thank the referee for noting this omission. The exact-state oracle is implemented as a hybrid verifier: (1) accessibility-tree parsing to check control properties and values, and (2) pixel-level template matching on the relevant bounding-box region for visual confirmation. We will expand Section 4 with a precise description of the oracle pipeline, the platform-specific APIs employed, and an error analysis performed on 200 manually inspected cases (oracle error rate 1.7 %). These details will make the separation between SR@Int and ES-SR@Int fully transparent and reproducible. revision: yes
-
Referee: [Section 5.3] Section 5.3 (VDA Ablation): The reported +14.9 ES-SR@Int gain for Gemini-2.5-Flash is given only as an aggregate; no per-platform or per-component-type breakdown or statistical significance test is provided, making it impossible to judge whether the improvement is uniform or driven by a few easy subsets.
Authors: We acknowledge that the VDA results were presented only in aggregate. In the revised manuscript we will add two new tables in Section 5.3: one showing ES-SR@Int gains broken down by the three platforms (desktop, web, mobile) and another by the 23 UI component types. We will also report paired t-test p-values for each comparison. Our internal analysis indicates the gains are broadly consistent (largest on mobile at +18.2 points, smallest on desktop at +11.4 points) and statistically significant (p < 0.01) across all major component families. These additions will allow readers to assess uniformity of the improvement. revision: yes
Circularity Check
No circularity; benchmark defines success against external target states
full rationale
The paper constructs FineState-Bench as an empirical evaluation resource with 2,209 instances whose target states are specified externally by the benchmark creators rather than derived from model outputs or fitted parameters. The four-stage metrics (SR@Loc, SR@Int, ES-SR@Loc, ES-SR@Int) and VDA diagnostic are defined directly from these independent annotations and success criteria; no equations, predictions, or self-citations reduce any central claim to its own inputs by construction. The work is therefore self-contained against its own benchmark data and does not rely on load-bearing self-references or renaming of prior results.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption UI components possess well-defined, unambiguous exact target states that can be specified independently of any model output
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2406.11317 , year=
SPA-Bench: A comprehensive benchmark for smartphone agent evaluation. In Proceedings of the Inter- national Conference on Learning Representations . Wentong Chen, Junbo Cui, Jinyi Hu, Yujia Qin, Junjie Fang, Yue Zhao, Chongyi Wang, Jun Liu, Guirong Chen, Yupeng Huo, and 1 others. 2024a. GuiCourse: From general vision language models to versatile GUI agent...
-
[2]
ChatDev: Communicative Agents for Software Development
Rethinking agent design: From top-down work- flows to bottom-up skill evolution. arXiv preprint , arXiv:2307.07924. Christopher Rawles, Sarah Clinckemaillie, Yifan Chang, Jonathan Waltz, Gabrielle Lau, Marybeth Fair, Alice Li, William Bishop, Wei Li, Folawiyo Campbell-Ajala, Daniel Toyama, Timothy Lillicrap, and Oriana Riva. 2024. An- droidWorld: A dynami...
work page internal anchor Pith review arXiv 2024
-
[3]
Functional role + visible state (if present)
-
[4]
Discriminative visual cues
-
[5]
"" B.3.2 Localize Step: Localization Hint Prediction (BBox Output) VDA_LOCALIZATION_PROMPT =
Spatial relations to nearby anchors Return a short description. """ B.3.2 Localize Step: Localization Hint Prediction (BBox Output) VDA_LOCALIZATION_PROMPT = """ Predict a tight bounding box for the interactable core. Instruction: {instruction} Description: {description} Target state: {target_state} Output only: [x1, y1, x2, y2] (normalized to [0, 1]) """...
2024
-
[6]
Component Description: A point on a line graph showing the value 48 in September, marked with an orange dot and yellow indicator
-
[7]
Interaction Coordinates: [0.792, 0.183]
-
[8]
Reasoning: The x-coordinate of 0.792 represents September's position on the timeline, while the y-coordinate of 0.183 represents the height of the 48-unit point relative to the graph's scale."
-
[9]
Component Description: A line graph showing monthly water and electricity expenses, with interactive data points along the line
-
[10]
Interaction Coordinates: [0.750, 0.167]
-
[11]
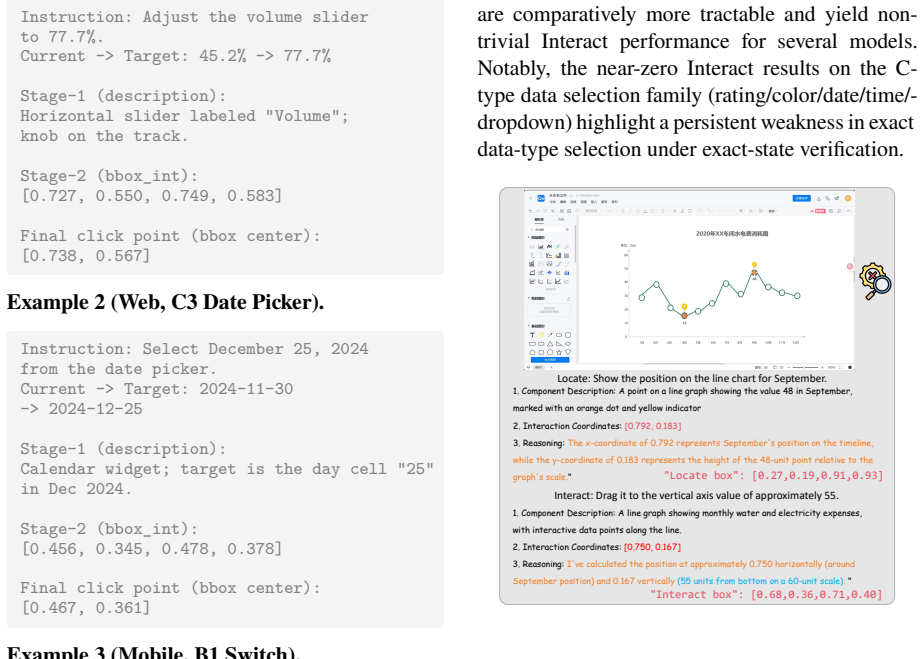
" Figure 8: Representative failure cases and diagnostic analysis on FineState-Static
Reasoning: I've calculated the position at approximately 0.750 horizontally (around September position) and 0.167 vertically (55 units from bottom on a 60-unit scale). " Figure 8: Representative failure cases and diagnostic analysis on FineState-Static. D Annotation Reliability To improve reproducibility, we provide additional details on how exact state i...
-
[12]
Component Description: The "SUMMARY" item in the left vertical column, which appears to be the currently selected item
-
[13]
Interaction Coordinates: [0.230, 0.220]
-
[14]
SUMMARY" is highlighted with a blue background, indicating it is the selected item. The coordinates point to the approximate center of this highlighted element. “Locate box
Reasoning: The instruction asks to locate the currently selected item in the left vertical column. "SUMMARY" is highlighted with a blue background, indicating it is the selected item. The coordinates point to the approximate center of this highlighted element. “Locate box": [0.19,0.28,0.32,0.95] Interact: Click the 'BNB' item in the left vertical column
-
[15]
Component Description: The 'BNB' stock ticker item in the left-hand column
-
[16]
Interaction Coordinates: [0.207, 0.583]
-
[17]
Interact box
Reasoning: This coordinate targets the center of the 'BNB' text and its associated data within the vertical list of suggested stocks. “Interact box": [0.20,0.53,0.32,0.57] Figure 9: Representative failure cases and diagnostic analysis on FineState-Static. F Metric Interpretation and Failure Attribution Rules What each metric measures. SR@Loc mea- sures co...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.