Recognition: unknown
When and How AI Should Assist Brainstorming for AI Impact Assessment
Pith reviewed 2026-05-07 07:50 UTC · model grok-4.3
The pith
AI assistance boosts brainstorming quality and perceptions in AI impact assessment for general-purpose applications but not for specialized ones.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central discovery is that AI should only offer hints and not complete solutions during early ideation phases, initiating interactions only when teams experience fixation or saturation; it should help structure ideas during convergence phases; leverage participant expertise to refine ideas; and primarily support tedious process tasks rather than the creative ideation that teams prefer to handle themselves.
What carries the argument
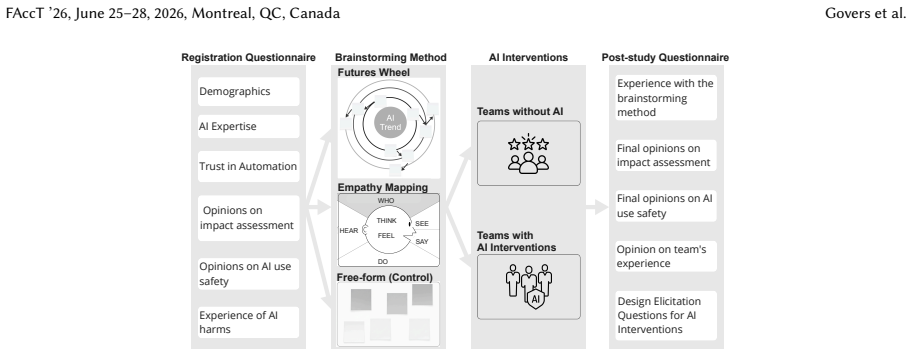
Co-designed AI interventions integrated into two structured methods adapted from strategic foresight, specifically tailored for collaborative brainstorming in AI impact assessment workshops.
Load-bearing premise
That the results observed in the ten workshops with 54 participants using just two specific AI cases will hold for other team configurations, different AI applications, and actual professional impact assessment practices.
What would settle it
Conducting additional workshops or real-world trials with a wider variety of AI applications and team compositions, then checking if the improvement in quality and perceptions appears only for general-purpose cases.
Figures













read the original abstract
A key task in AI practice is to assess potential impacts to prevent harm. Current AI tools assisting AI impact assessment have not been designed or evaluated for collaborative team brainstorming, and they do not capture the range of views in diverse teams. We studied how AI can support team brainstorming during AI impact assessment and made three contributions. First, we adapted two structured methods from strategic foresight and co-designed AI interventions for them in five in-person workshops with 28 participants in total. Second, we evaluated the interventions in ten in-person workshops with 54 participants, finding that AI improved impact assessment quality and brainstorming perceptions for a general-purpose AI use (a chatbot companion) but not for a specialised one (a kidney allocation application). Third, our findings result in broader design guidance for AI assistance in brainstorming: AI should only offer hints and not solutions during early ideation, initiating interaction only when participants face fixation or saturation; it should facilitate structuring ideas during convergence; leverage expertise to refine ideas; and overall, it should serve more in support of tedious brainstorming process tasks, rather than ideation that teams value to do themselves.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript reports an empirical study on AI support for team brainstorming in AI impact assessment. It adapts two structured methods from strategic foresight, co-designs AI interventions in five workshops (28 participants), then evaluates them in ten workshops (54 participants total). The central finding is that AI assistance improved impact assessment quality and brainstorming perceptions for a general-purpose use case (chatbot companion) but not for a specialized one (kidney allocation application). From these results the authors derive design guidance: AI should offer hints rather than solutions in early ideation, initiate interaction only on fixation or saturation, facilitate structuring during convergence, leverage expertise to refine ideas, and primarily support tedious process tasks rather than ideation itself.
Significance. If the results hold after addressing confounds, the work supplies initial empirical evidence on the conditions under which AI can usefully assist collaborative impact assessment, a practically important task in responsible AI development. The in-person workshop format and use of established foresight methods are strengths that ground the design recommendations in observed team behavior. The study is modest in scale but directly addresses a gap in current AI tools for this activity.
major comments (2)
- [Evaluation section and results describing the two applications and differential findings] The central claim that AI assistance is differentially effective for general-purpose versus specialized AI uses rests on a comparison of only two applications. These cases differ simultaneously in domain (consumer chatbot vs. medical/ethical allocation), potential harm, and likely participant domain knowledge, yet the analysis does not isolate generality/specialization from these confounds. No additional matched cases or explicit controls are described that would allow secure attribution of the observed difference to the intended factor. This directly undermines the design guidance derived in the third contribution.
- [Abstract and Evaluation/Methods sections] The abstract and evaluation description provide no details on the operationalization of 'impact assessment quality,' including rubrics or criteria used, inter-rater reliability, blinding procedures, statistical controls, or how post-hoc interpretations of the specialized-case failure were validated. Without these, the reported improvement in one case but not the other cannot be rigorously assessed.
minor comments (2)
- [Abstract] The abstract is information-dense; splitting the contributions and key findings into separate sentences would improve readability.
- [Discussion or Conclusion] The manuscript would benefit from an explicit limitations subsection that directly addresses generalizability beyond the two tested applications and the workshop setting.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We have reviewed each major comment carefully and provide point-by-point responses below, indicating where we will revise the manuscript.
read point-by-point responses
-
Referee: [Evaluation section and results describing the two applications and differential findings] The central claim that AI assistance is differentially effective for general-purpose versus specialized AI uses rests on a comparison of only two applications. These cases differ simultaneously in domain (consumer chatbot vs. medical/ethical allocation), potential harm, and likely participant domain knowledge, yet the analysis does not isolate generality/specialization from these confounds. No additional matched cases or explicit controls are described that would allow secure attribution of the observed difference to the intended factor. This directly undermines the design guidance derived in the third contribution.
Authors: We agree that the study compares only two applications and that these differ along multiple dimensions beyond generality versus specialization, including domain, potential harm, and likely participant domain knowledge. This limits our ability to attribute the differential outcomes solely to the intended factor. The applications were selected to contrast a general-purpose use case with a specialized one in realistic settings using established foresight methods, but we recognize the design does not include matched controls or additional cases. In the revised manuscript we will qualify the third contribution and derived design guidance as preliminary and exploratory rather than broadly generalizable. We will also expand the limitations section to explicitly discuss these confounds and outline how future studies could isolate the factor through additional matched cases or controlled designs. revision: yes
-
Referee: [Abstract and Evaluation/Methods sections] The abstract and evaluation description provide no details on the operationalization of 'impact assessment quality,' including rubrics or criteria used, inter-rater reliability, blinding procedures, statistical controls, or how post-hoc interpretations of the specialized-case failure were validated. Without these, the reported improvement in one case but not the other cannot be rigorously assessed.
Authors: We acknowledge that the abstract and the description in the evaluation section lack sufficient detail on the operationalization of impact assessment quality. While the full manuscript describes the workshop evaluation process, we will revise the abstract to include a concise summary of the quality metrics and substantially expand the Evaluation and Methods sections. The revisions will specify the rubrics and criteria applied, report inter-rater reliability (including any Cohen's kappa or equivalent measures), describe blinding procedures for independent raters, note any statistical controls, and explain how post-hoc interpretations of the specialized-case results were validated through team review and cross-checking. These additions will improve transparency and allow readers to better evaluate the differential findings. revision: yes
- The study is complete and we cannot conduct additional workshops or add matched application cases to better isolate confounds; we will address this limitation by qualifying claims and expanding the discussion of limitations rather than collecting new data.
Circularity Check
Empirical HCI study with no derivation chain or self-referential reduction
full rationale
The paper describes an empirical process: adapting foresight methods, co-designing AI interventions in five workshops (28 participants), then evaluating them in ten workshops (54 participants) across two specific AI applications. Findings on differential effects (improved quality/perceptions for the chatbot case but not the kidney allocation case) and resulting design guidance are drawn directly from new participant observations and workshop data. No equations, fitted parameters, predictions that reduce to inputs by construction, or load-bearing self-citations appear in the reported chain. The central claims rest on fresh empirical evidence rather than tautological re-derivation of prior results. This matches the default case of a self-contained empirical study without circularity.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Structured methods from strategic foresight are appropriate bases for AI impact assessment brainstorming.
- domain assumption Participant perceptions and observed behaviors in workshops validly indicate real impact assessment quality and brainstorming effectiveness.
Reference graph
Works this paper leans on
-
[1]
2025.Risk Management Software
4strat. 2025.Risk Management Software. https://www.4strat.com/risk-management/
2025
-
[2]
Saleema Amershi, Maya Cakmak, William Bradley Knox, and Todd Kulesza. 2014. Power to the people: The role of humans in interactive machine learning.AI magazine35, 4 (2014), 105–120
2014
-
[3]
Amir Reza Asadi. 2023. LLMs in Design Thinking: Autoethnographic Insights and Design Implications. InProceedings of the 2023 5th World Symposium on Software Engineering(Tokyo, Japan)(WSSE ’23). Association for Computing Machinery, New York, NY, USA, 55–60. doi:10.1145/3631991.3631999
-
[4]
Carolyn Ashurst, Emmie Hine, Paul Sedille, and Alexis Carlier. 2022. AI ethics statements: analysis and lessons learnt from neurips broader impact statements. InProceedings of the 2022 ACM conference on fairness, accountability, and transparency. 2047–2056
2022
-
[5]
Frank Bagehorn, Kristina Brimijoin, Elizabeth M. Daly, Jessica He, Michael Hind, Luis Garces-Erice, Christopher Giblin, Ioana Giurgiu, Jacquelyn Martino, Rahul Nair, David Piorkowski, Ambrish Rawat, John Richards, Sean Rooney, Dhaval Salwala, Seshu Tirupathi, Peter Urbanetz, Kush R. Varshney, Inge Vejsbjerg, and Mira L. Wolf-Bauwens. 2025. AI Risk Atlas: ...
-
[6]
Stephanie Ballard, Karen M. Chappell, and Kristen Kennedy. 2019. Judgment Call the Game: Using Value Sensitive Design and Design Fiction to Surface Ethical Concerns Related to Technology. InProceedings of the 2019 on Designing Interactive Systems Conference(San Diego, CA, USA)(DIS ’19). Association for Computing Machinery, New York, NY, USA, 421–433. doi:...
-
[7]
Eva Bittner, Sarah Oeste-Reiß, and Jan Marco Leimeister. 2019. Where is the Bot in our Team? Toward a Taxonomy of Design Option Combinations for Conversational Agents in Collaborative Work. doi:10.24251/HICSS.2019.035
-
[8]
Edyta Bogucka, Marios Constantinides, Sanja Šćepanović, and Daniele Quercia. 2024. Co-designing an AI impact assessment report template with AI practitioners and AI compliance experts. InProceedings of the AAAI/ACM Conference on AI, Ethics, and Society, Vol. 7. 168–180
2024
-
[9]
Edyta Bogucka, Marios Constantinides, Sanja Šćepanović, and Daniele Quercia. 2024. AI Design: A Responsible Artificial Intelligence Framework for Prefilling Impact Assessment Reports.IEEE Internet Computing28, 5 (Sept. 2024), 37–45. doi:10.1109/MIC.2024.3451351
-
[10]
Edyta Bogucka, Sanja Šćepanović, and Daniele Quercia. 2024. Atlas of AI risks: Enhancing public understanding of AI risks. In Proceedings of the AAAI Conference on Human Computation and Crowdsourcing, Vol. 12. 33–43
2024
-
[11]
Bouschery, Vera Blazevic, and Frank T
Sebastian G. Bouschery, Vera Blazevic, and Frank T. Piller. 2024. Artificial Intelligence-Augmented Brainstorming: How Humans and AI Beat Humans Alone. (April 2024). doi:10.2139/ssrn.4724068 SSRN Working Paper, posted April 3, 2024
-
[12]
2025.We Need an Interventionist Mindset
Danah Boyd. 2025.We Need an Interventionist Mindset. Tech Policy Press. https://www.techpolicy.press/we-need-an-interventionist- mindset/
2025
-
[13]
Virginia Braun and Victoria Clarke. 2006. Using thematic analysis in psychology.Qualitative Research in Psychology3, 2 (2006), 77–101. doi:10.1191/1478088706qp063oa
-
[14]
John Brooke et al. 1996. SUS: A Quick and Dirty Usability Scale.Usability Evaluation in Industry189, 194 (1996), 4–7. When and How AI Should Assist Brainstorming for AI Impact Assessment FAccT ’26, June 25–28, 2026, Montreal, QC, Canada
1996
- [15]
-
[16]
2025.Brainstorming
Cambridge Dictionary. 2025.Brainstorming. Retrieved August 1, 2025 from https://dictionary.cambridge.org/dictionary/english/ brainstorming/
2025
-
[17]
Heloisa Candello, Muneeza Azmat, Uma Sushmitha Gunturi, Raya Horesh, Rogerio Abreu de Paula, Heloisa Pimentel, Marcelo Carpinette Grave, Aminat Adebiyi, Tiago Machado, and Maysa Malfiza Garcia de Macedo. 2025. Exploring Human Perceptions of AI Responses: Insights from a Mixed-Methods Study on Risk Mitigation in Generative Models. arXiv:2512.01892 [cs.CL] ...
-
[18]
2024.character.ai: Personalized AI for every moment of your day
Character Technologies, Inc. 2024.character.ai: Personalized AI for every moment of your day. https://character.ai/about/
2024
-
[19]
Council of the European Union. 2024. Regulation (EU) 2024/1689 of the European Parliament and of the Council of 25 July 2024.Official Journal of the European UnionL 168 (2024), 1–15. https://eur-lex.europa.eu/legal-content/EN/TXT/?uri=OJ:L_202401689 Accessed: 2025-07-29
2024
-
[20]
Alwin de Rooij and Michael Mose Biskjaer. 2025. Has AI Surpassed Humans in Creative Idea Generation? A Meta-Analysis. (2025)
2025
-
[21]
Douglas L. Dean, Jillian M. Hender, Thomas L. Rodgers, and Eric L. Santanen. 2006. Identifying Quality, Novel, and Creative Ideas: Constructs and Scales for Idea Evaluation.Journal of the Association for Information Systems7, 10 (2006), 646–699. doi:10.17705/1jais.00106
-
[22]
Fernando Delgado, Stephen Yang, Michael Madaio, and Qian Yang. 2023. The Participatory Turn in AI Design: Theoretical Foundations and the Current State of Practice. InProceedings of the 3rd ACM Conference on Equity and Access in Algorithms, Mechanisms, and Optimization(Boston, MA, USA)(EAAMO ’23). Association for Computing Machinery, New York, NY, USA, Ar...
-
[23]
2025.Elon Musk’s Grok releases two new ‘AI companions, ’ including an anime girlfriend
Anna Desmarais. 2025.Elon Musk’s Grok releases two new ‘AI companions, ’ including an anime girlfriend. Euronews. https://www. euronews.com/next/2025/07/17/elon-musks-grok-releases-two-new-ai-companions-including-an-anime-girlfriend
2025
-
[24]
Nicholas Diakopoulos and Deborah Johnson. 2021. Anticipating and addressing the ethical implications of deepfakes in the context of elections.New Media & Society23, 7 (2021), 2072–2098. doi:10.1177/1461444820925811
-
[25]
Michael Diehl and Wolfgang Stroebe. 1987. Productivity loss in brainstorming groups: Toward the solution of a riddle.Journal of Personality and Social Psychology53, 3 (1987), 497–509. doi:10.1037/0022-3514.53.3.497
-
[26]
Amy Wenxuan Ding and Shibo Li. 2025. Generative AI lacks the human creativity to achieve scientific discovery from scratch.Scientific Reports15, 1 (2025), 9587
2025
-
[27]
Anil R Doshi and Oliver P Hauser. 2024. Generative AI enhances individual creativity but reduces the collective diversity of novel content.Science advances10, 28 (2024), eadn5290
2024
-
[28]
Eisenberg, Lucía Gamboa, and Eli Sherman
Ian W. Eisenberg, Lucía Gamboa, and Eli Sherman. 2025. The Unified Control Framework: Establishing a Common Foundation for Enterprise AI Governance, Risk Management and Regulatory Compliance. arXiv:2503.05937 [cs.CY] https://arxiv.org/abs/2503.05937
-
[29]
Salma Elsayed-Ali, Sara E Berger, Vagner Figueredo De Santana, and Juana Catalina Becerra Sandoval. 2023. Responsible & Inclusive Cards: An Online Card Tool to Promote Critical Reflection in Technology Industry Work Practices. InProceedings of the 2023 CHI Conference on Human Factors in Computing Systems(Hamburg, Germany)(CHI ’23). Association for Computi...
-
[30]
European Union. 2025. EU AI Act, Article 55: Obligations for Providers of General-Purpose AI Models with Systemic Risk. https: //artificialintelligenceact.eu/article/55/. Part of Chapter V: General-Purpose AI Models, Section 3: Obligations of Providers of General-Purpose AI Models with Systemic Risk. In force from 2 August 2025, according to Article 113(b)
2025
-
[31]
Deng, Zachary C
Michael Feffer, Anusha Sinha, Wesley H. Deng, Zachary C. Lipton, and Hoda Heidari. 2025.Red-Teaming for Generative AI: Silver Bullet or Security Theater?AAAI Press, 421–437
2025
-
[32]
Shangbin Feng, Chan Young Park, Yuhan Liu, and Yulia Tsvetkov. 2023. From Pretraining Data to Language Models to Downstream Tasks: Tracking the Trails of Political Biases Leading to Unfair NLP Models. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 11737–11762
2023
-
[33]
Kazuma Fukumura and Takayuki Ito. 2025. Can LLM-Powered Multi-Agent Systems Augment Human Creativity? Evidence from Brainstorming Tasks. InProceedings of the ACM Collective Intelligence Conference (CI ’25). Association for Computing Machinery, New York, NY, USA, 20–29. doi:10.1145/3715928.3737479
-
[34]
2025.The Future of AI-Driven Strategic Foresight: Insights from Experts
Futures Platform. 2025.The Future of AI-Driven Strategic Foresight: Insights from Experts. https://www.futuresplatform.com/blog/future- of-ai-strategic-foresight
2025
-
[35]
2025.Generative AI and the Future of Foresight
Futures Platform. 2025.Generative AI and the Future of Foresight. https://www.futuresplatform.com/blog/future-of-generative-ai- foresight
2025
-
[36]
2025.Trend Cards on Futures Platform and How to Use Them
Futures Platform. 2025.Trend Cards on Futures Platform and How to Use Them. https://www.futuresplatform.com/blog/trend-cards- futures-platform-and-how-use-them
2025
-
[37]
Jerome C. Glenn. 2009. The Futures Wheel. InFutures Research Methodology, Version 3.0, Jerome C. Glenn and Theodore J. Gordon (Eds.). The Millennium Project, 245–263. FAccT ’26, June 25–28, 2026, Montreal, QC, Canada Govers et al
2009
-
[38]
Glenn and Theodore J
Jerome C. Glenn and Theodore J. Gordon (Eds.). 2009.Futures Research Methodology, Version 3.0. The Millennium Project, Washington, DC. https://www.millennium-project.org/ CD-ROM, 1300 pages. Contains 39 peer-reviewed chapters on futures research methods
2009
-
[39]
Jarod Govers, Philip Feldman, Aaron Dant, and Panos Patros. 2023. Prompt-GAN–Customisable Hate Speech and Extremist Datasets via Radicalised Neural Language Models. InProceedings of the 2023 9th International Conference on Computing and Artificial Intelligence (Tianjin, China)(ICCAI ’23). Association for Computing Machinery, New York, NY, USA, 515–522. do...
-
[40]
Jarod Govers, Cherie Sew, Eduardo Velloso, Vassilis Kostakos, and Jorge Goncalves. 2026. Narratives and Perspectives: How AI Summaries Steer Users’ Opinions and Engagement on Social Media. InProceedings of the 2026 CHI Conference on Human Factors in Computing Systems (CHI ’26). Association for Computing Machinery, New York, NY, USA, Article 1398, 19 pages...
-
[41]
Jarod Govers, Eduardo Velloso, Vassilis Kostakos, and Jorge Goncalves. 2024. AI-Driven Mediation Strategies for Audience Depolarisation in Online Debates. InProceedings of the CHI Conference on Human Factors in Computing Systems (CHI ’24), May 11–16, 2024, Honolulu, HI, USA(Honolulu, HI, USA)(CHI ’24). Association for Computing Machinery, New York, NY, US...
-
[42]
D. Gray, S. Brown, and J. Macanufo. 2010.Gamestorming: A Playbook for Innovators, Rulebreakers, and Changemakers. O’Reilly Media
2010
-
[43]
Richard Hackman and Neil Vidmar
J. Richard Hackman and Neil Vidmar. 1970. Effects of Size and Task Type on Group Performance and Member Reactions.Sociometry 33, 1 (1970), 37–54. doi:10.2307/2786271
-
[44]
Gonzalez, Darío Andrés Silva Moran, Steven I
Jessica He, Stephanie Houde, Gabriel E. Gonzalez, Darío Andrés Silva Moran, Steven I. Ross, Michael Muller, and Justin D. Weisz. 2024. AI and the Future of Collaborative Work: Group Ideation with an LLM in a Virtual Canvas. InProceedings of the 3rd Annual Meeting of the Symposium on Human-Computer Interaction for Work(Newcastle upon Tyne, United Kingdom)(...
-
[45]
2025.ExploreGen: Large Language Models for Envisioning the Uses and Risks of AI Technologies
Viviane Herdel, Sanja Sćepanović, Edyta Bogucka, and Daniele Quercia. 2025.ExploreGen: Large Language Models for Envisioning the Uses and Risks of AI Technologies. AAAI Press, 584–596
2025
-
[46]
Peter A. Heslin. 2009. Better than brainstorming? Potential contextual boundary conditions to brainwriting for idea generation in organizations.Journal of Occupational and Organizational Psychology82, 1 (2009), 129–145. arXiv:https://bpspsychub.onlinelibrary.wiley.com/doi/pdf/10.1348/096317908X285642 doi:10.1348/096317908X285642
-
[47]
Jennifer L Heyman, Steven R Rick, Gianni Giacomelli, Haoran Wen, Robert Laubacher, Nancy Taubenslag, Max Knicker, Younes Jeddi, Pranav Ragupathy, Jared Curhan, and Thomas Malone. 2024. Supermind Ideator: How Scaffolding Human-AI Collaboration Can Increase Creativity. InProceedings of the ACM Collective Intelligence Conference(Boston, MA, USA)(CI ’24). Ass...
-
[48]
2006.Thinking about the future: Guidelines for strategic foresight
Andy Hines, Peter Jason Bishop, and Richard A Slaughter. 2006.Thinking about the future: Guidelines for strategic foresight. Social Technologies Washington, DC
2006
-
[49]
Michel Hohendanner, Chiara Ullstein, Bukola Abimbola Onyekwelu, Amelia Katirai, Jun Kuribayashi, Olusola Babalola, Arisa Ema, and Jens Grossklags. 2025. Initiating the Global AI Dialogues: Laypeople Perspectives on the Future Role of genAI in Society from Nigeria, Germany and Japan. InProceedings of the 2025 CHI Conference on Human Factors in Computing Sy...
-
[50]
Eric Horvitz. 1999. Principles of mixed-initiative user interfaces. InProceedings of the SIGCHI Conference on Human Factors in Computing Systems(Pittsburgh, Pennsylvania, USA)(CHI ’99). Association for Computing Machinery, New York, NY, USA, 159–166. doi:10.1145/302979.303030
-
[51]
Yihan Hou, Manling Yang, Hao Cui, Lei Wang, Jie Xu, and Wei Zeng. 2024. C2Ideas: Supporting Creative Interior Color Design Ideation with a Large Language Model. InProceedings of the 2024 CHI Conference on Human Factors in Computing Systems(Honolulu, HI, USA) (CHI ’24). Association for Computing Machinery, New York, NY, USA, Article 172, 18 pages. doi:10.1...
-
[52]
David G. Jansson and Steven M. Smith. 1991. Design fixation.Design Studies12, 1 (1991), 3–11. doi:10.1016/0142-694X(91)90003-F
-
[53]
M. G. Kendall and B. Babington Smith. 1939. The Problem of 𝑚 Rankings.The Annals of Mathematical Statistics10, 3 (1939), 275 – 287. doi:10.1214/aoms/1177732186
-
[54]
Kimon Kieslich, Natali Helberger, and Nicholas Diakopoulos. 2025. Scenario-based Sociotechnical Envisioning (SSE): An Approach to Enhance Systemic Risk Assessments.OSF Preprints(2025). doi:10.31235/osf.io/ertsj_v1
-
[55]
1986.An overview of innovation
Stephen J Kline, Nathan Rosenberg, et al. 1986.An overview of innovation. World Scientific
1986
-
[56]
Harsh Kumar, Jonathan Vincentius, Ewan Jordan, and Ashton Anderson. 2025. Human Creativity in the Age of LLMs: Randomized Experiments on Divergent and Convergent Thinking. InProceedings of the 2025 CHI Conference on Human Factors in Computing Systems (CHI ’25). Association for Computing Machinery, New York, NY, USA, Article 23, 18 pages. doi:10.1145/37065...
-
[57]
Franc Lavrič and Andrej Škraba. 2023. Brainstorming Will Never Be the Same Again—A Human Group Supported by Artificial Intelligence.Machine Learning and Knowledge Extraction5, 4 (2023), 1282–1301. doi:10.3390/make5040065
-
[58]
Ryan Lee. 2016. Threatcasting .Computer49, 10 (Oct. 2016), 94–95. doi:10.1109/MC.2016.305
-
[59]
Lewis and Jeff Sauro
James R. Lewis and Jeff Sauro. 2009. The Factor Structure of the System Usability Scale. InHuman Centered Design, Masaaki Kurosu (Ed.). Springer Berlin Heidelberg, Berlin, Heidelberg, 94–103
2009
- [60]
-
[61]
2025.UN DESA Policy Brief No
Prabin Maharjan. 2025.UN DESA Policy Brief No. 174: Leveraging strategic foresight to mitigate artificial intelligence (AI) risk in public sectors. United Nations Project Office on Governance, Division for Public Institutions and Digital Government. https: //desapublications.un.org/policy-briefs/un-desa-policy-brief-no-174-leveraging-strategic-foresight-m...
2025
-
[62]
David Manheim. 2023. Building a culture of safety for AI: Perspectives and challenges.A vailable at SSRN 4491421(2023)
2023
-
[63]
J Nathan Matias and Megan Price. 2025. How public involvement can improve the science of AI.Proceedings of the National Academy of Sciences122, 48 (2025), e2421111122
2025
-
[64]
Peter McCullagh. 1980. Regression models for ordinal data.Journal of the Royal Statistical Society: Series B (Methodological)42, 2 (1980), 109–127
1980
-
[65]
Sean McGregor. 2021. Preventing Repeated Real World AI Failures by Cataloging Incidents: The AI Incident Database.Proceedings of the AAAI Conference on Artificial Intelligence35, 17 (May 2021), 15458–15463. doi:10.1609/aaai.v35i17.17817
-
[66]
Lennart Meincke, Gideon Nave, and Christian Terwiesch. 2025. ChatGPT decreases idea diversity in brainstorming.Nature Human Behaviour9, 6 (2025), 1107–1109. doi:10.1038/s41562-025-02173-x
-
[67]
Lucas Memmert and Navid Tavanapour. 2023. Towards human-AI-collaboration in brainstorming: Empirical insights into the perception of working with a generative AI.European Conference on Information Systems(2023)
2023
-
[68]
2022.Responsible AI Impact Assessment Template and Guide
Microsoft Office of Responsible AI. 2022.Responsible AI Impact Assessment Template and Guide. Technical Report. Microsoft. https: //msblogs.thesourcemediaassets.com/sites/5/2022/06/Microsoft-RAI-Impact-Assessment-Template.pdf Practical templates, facilitation guidance, and example activities for internal impact assessments
2022
-
[69]
2025.Miro Web SDK
Miro. 2025.Miro Web SDK. https://developers.miro.com/docs/miro-web-sdk-introduction/
2025
-
[70]
2024.AI Red Teaming: Advancing Safe and Secure AI Systems
MITRE Corporation. 2024.AI Red Teaming: Advancing Safe and Secure AI Systems. Technical Report. MITRE. https://www.mitre.org/ sites/default/files/2024-07/PR-24-01820-4-AI-Red-Teaming-Advancing-Safe-Secure-AI-Systems.pdf
2024
-
[71]
Eduardo Mosqueira-Rey, Elena Hernández-Pereira, David Alonso-Ríos, José Bobes-Bascarán, and Ángel Fernández-Leal. 2023. Human- in-the-loop machine learning: a state of the art.Artificial Intelligence Review56, 4 (2023), 3005–3054. doi:10.1007/s10462-022-10246-w
-
[72]
Fabio Motoki, Valdemar Pinho Neto, and Victor Rodrigues. 2024. More human than human: measuring ChatGPT political bias.Public Choice198, 1 (2024), 3–23. doi:10.1007/s11127-023-01097-2
-
[73]
Muhammad Faraz Mubarak, Giedrius Jucevicius, Mubarra Shabbir, Monika Petraite, Morteza Ghobakhloo, and Richard Evans. 2025. Strategic foresight, knowledge management, and open innovation: Drivers of new product development success.Journal of Innovation & Knowledge10, 2 (2025), 100654. doi:10.1016/j.jik.2025.100654
-
[74]
Michael Muller, Stephanie Houde, Gabriel Gonzalez, Kristina Brimijoin, Steven I Ross, Dario Andres Silva Moran, and Justin D Weisz
-
[75]
InInternational conference on computational creativity
Group brainstorming with an ai agent: Creating and selecting ideas. InInternational conference on computational creativity. 10
-
[76]
Gary D. Lopez Munoz, Amanda J. Minnich, Roman Lutz, Richard Lundeen, Raja Sekhar Rao Dheekonda, Nina Chikanov, Bolor-Erdene Jagdagdorj, Martin Pouliot, Shiven Chawla, Whitney Maxwell, Blake Bullwinkel, Katherine Pratt, Joris de Gruyter, Charlotte Siska, Pete Bryan, Tori Westerhoff, Chang Kawaguchi, Christian Seifert, Ram Shankar Siva Kumar, and Yonatan Zu...
-
[77]
2023.Artificial Intelligence Risk Management Framework (AI RMF) 1.0
NIST AI. 2023.Artificial Intelligence Risk Management Framework (AI RMF) 1.0. Technical Report. National Institute of Standards and Technology (NIST). https://nvlpubs.nist.gov/nistpubs/ai/NIST.AI.100-1.pdf Cross-sectoral risk management framework widely used to structure AI impact assessment workshops and documentation
2023
-
[78]
Moeka Nomura, Takayuki Ito, and Shiyao Ding. 2024. Towards Collaborative Brain-storming among Humans and AI Agents: An Implementation of the IBIS-based Brainstorming Support System with Multiple AI Agents. InProceedings of the ACM Collective Intelligence Conference(Boston, MA, USA)(CI ’24). Association for Computing Machinery, New York, NY, USA, 1–9. doi:...
-
[79]
Carsten Orwat, Jascha Bareis, Anja Folberth, Jutta Jahnel, and Christian Wadephul. 2024. Normative Challenges of Risk Regulation of Artificial Intelligence.NanoEthics18, 2 (Aug. 2024), 11. doi:10.1007/s11569-024-00454-9
-
[80]
2012.Applied imagination-principles and procedures of creative writing
Alex Osborn. 2012.Applied imagination-principles and procedures of creative writing. Read Books Ltd
2012
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.