Recognition: unknown
Design Structure Matrix Modularization with Large Language Models
Pith reviewed 2026-05-07 05:21 UTC · model grok-4.3
The pith
Large language models can partition design structure matrices into modules near reference quality using only prompting.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
LLMs prompted with DSM data can solve the module partitioning problem to near-reference quality without custom solvers. Domain knowledge impairs results on complex DSMs because of misalignment between learned functional priors and the purely structural goal, leading to the semantic-alignment hypothesis. Ablations show best practices for input format, objective, and solution management.
What carries the argument
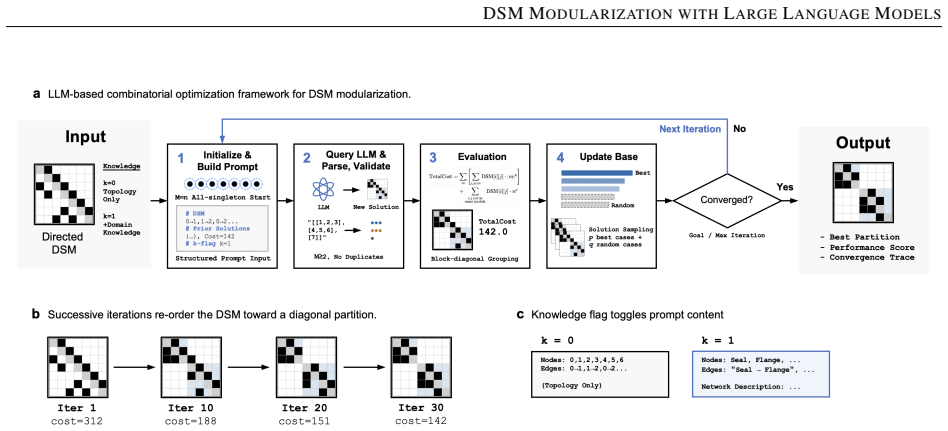
The prompting strategy for LLM-based DSM modularization that iteratively generates and refines module partitions from matrix data.
If this is right
- Engineers can apply LLMs to DSM modularization without developing or running dedicated optimization algorithms.
- High-quality partitions emerge quickly, within about 30 iterations, supporting fast design iterations.
- Domain knowledge should be withheld from prompts for complex structural tasks to avoid performance degradation.
- Careful choices of input representation and objective formulation, identified via ablations, enhance practical results.
- The semantic-alignment hypothesis offers a way to predict when external knowledge will aid or hinder LLM optimization.
Where Pith is reading between the lines
- The approach may generalize to other combinatorial engineering tasks such as clustering or layout optimization.
- LLMs might benefit from additional training to better distinguish semantic content from structural objectives in design problems.
- Testing the method on proprietary DSMs from industry could reveal if the near-reference performance holds outside the studied cases.
- Hybrid LLM-traditional optimizer systems could mitigate any remaining quality gaps.
Load-bearing premise
That an LLM prompted with DSM data can reliably identify good module partitions for the combinatorial task.
What would settle it
If the LLM outputs on the five cases do not approach reference quality after 30 iterations or if adding domain knowledge improves performance on complex DSMs instead of impairing it.
Figures


read the original abstract
Design Structure Matrix (DSM) modularization, the task of partitioning system elements into cohesive modules, is a fundamental combinatorial challenge in engineering design. Traditional methods treat modularization as a pure graph optimization, without access to the engineering context embedded in the system. Building on prior work on LLM-based combinatorial optimization for DSM sequencing, this paper extends the method to modularization across five cases and three backbone LLMs. Our method achieves near-reference quality within 30 iterations without requiring specialized optimization code. Counterintuitively, domain knowledge, beneficial in sequencing, consistently impairs performance on more complex DSMs. We attribute this to semantic misalignment between the LLM's functional priors and the purely structural optimization objective, and propose the semantic-alignment hypothesis as a testable condition governing knowledge effectiveness with LLMs. Ablation studies identify the most effective input representation, objective formulation, and solution pool design for practical deployment. These findings offer practical guidance for deploying LLMs in engineering design optimization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that large language models (LLMs) can perform Design Structure Matrix (DSM) modularization—a combinatorial partitioning task—by direct prompting with DSM data. Extending prior LLM sequencing work, experiments across five cases and three LLMs reportedly reach near-reference quality within 30 iterations without specialized optimization code. Domain knowledge is found to impair performance on complex DSMs (opposite to sequencing), which the authors attribute to semantic misalignment between LLM functional priors and structural objectives; they propose the semantic-alignment hypothesis as a governing condition. Ablation studies identify optimal input representations, objective formulations, and solution-pool designs for deployment.
Significance. If the results hold, the work supplies practical guidance for applying LLMs to engineering design optimization without custom solvers, with actionable ablation findings on prompting. The counterintuitive domain-knowledge effect and the proposed testable hypothesis could stimulate research on when and why LLMs succeed or fail at structural combinatorial tasks. Multi-case, multi-LLM evaluation is a strength, as is the focus on reproducible deployment conditions.
major comments (2)
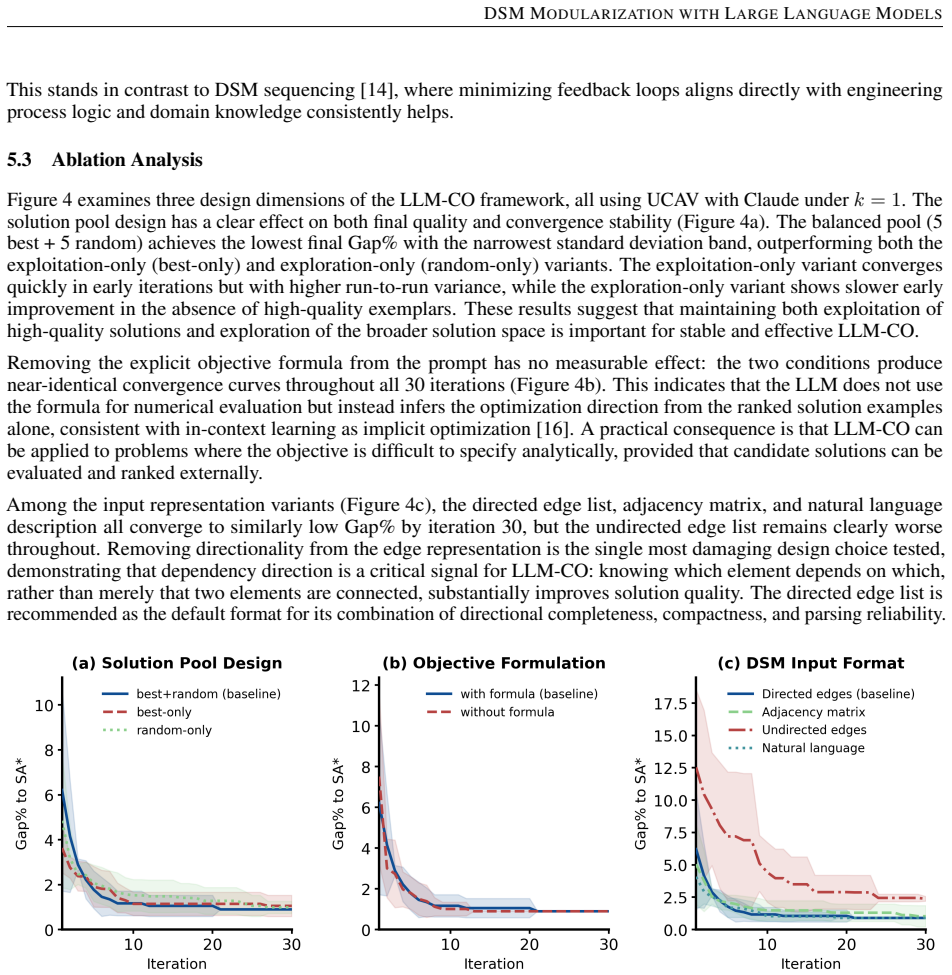
- Results section (five cases, three LLMs): the claim of reliable near-reference quality within 30 iterations is load-bearing for the central contribution, yet no repeated trials, error bars, or variance statistics are reported. Given LLM stochasticity, single-run or best-case outcomes per configuration cannot establish consistency or reproducibility, directly weakening the assertion that the method can be deployed without specialized code.
- Ablation studies: the identification of 'most effective' input representation, objective formulation, and solution pool design lacks any indication of multiple runs per variant or statistical significance testing. Without these, the ranking of designs and the practical recommendations rest on unquantified differences.
minor comments (2)
- Abstract: the phrase 'near-reference quality' is used without defining the reference method, the quantitative metric (e.g., modularity score or partition similarity), or baseline values, making the headline claim difficult to evaluate at first reading.
- The semantic-alignment hypothesis is offered as an interpretive explanation rather than a quantity derived from the fitted parameters; a short clarifying sentence distinguishing interpretation from data would improve precision.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback emphasizing reproducibility and statistical rigor in our LLM-based DSM modularization experiments. We address each major comment below and commit to revisions that strengthen the evidence for our claims without altering the core findings or methodology.
read point-by-point responses
-
Referee: Results section (five cases, three LLMs): the claim of reliable near-reference quality within 30 iterations is load-bearing for the central contribution, yet no repeated trials, error bars, or variance statistics are reported. Given LLM stochasticity, single-run or best-case outcomes per configuration cannot establish consistency or reproducibility, directly weakening the assertion that the method can be deployed without specialized code.
Authors: We agree that the stochasticity of LLMs necessitates repeated trials and variance reporting to substantiate consistency claims. The original experiments used single runs per configuration to efficiently explore a broad space of prompting strategies across five cases and three models while managing API costs. Performance trends were stable in these runs, supporting the reported near-reference quality. In the revised manuscript, we will conduct multiple independent trials (minimum of five per key case-LLM pair) for the primary results, reporting mean performance metrics with standard deviations and error bars. This will directly address reproducibility and bolster the deployment assertion. revision: yes
-
Referee: Ablation studies: the identification of 'most effective' input representation, objective formulation, and solution pool design lacks any indication of multiple runs per variant or statistical significance testing. Without these, the ranking of designs and the practical recommendations rest on unquantified differences.
Authors: We concur that the ablation rankings would be more robust with repeated runs and statistical validation. The ablations systematically compared input formats, objective phrasings, and pool designs, with selected variants demonstrating consistent advantages across the evaluated cases. To quantify these differences, the revised version will rerun each ablation variant with multiple trials and incorporate statistical tests (such as paired comparisons with confidence intervals) to confirm the superiority of the recommended configurations. This will provide stronger justification for the practical guidance offered. revision: yes
Circularity Check
No significant circularity in empirical LLM prompting experiments
full rationale
The paper presents results from prompting experiments that extend prior LLM-based DSM sequencing work to the modularization task across five cases and three backbone models. All central claims—near-reference quality within 30 iterations, counterintuitive effects of domain knowledge, and the semantic-alignment hypothesis—are grounded in reported ablation outcomes and observed performance rather than any mathematical derivation, fitted parameter, or self-referential definition that reduces to the inputs by construction. The citation to the authors' earlier sequencing paper supplies methodological context but does not bear the load of the new empirical findings, which remain independently replicable through repeated prompting trials. No equations, uniqueness theorems, or ansatzes are invoked that would create a closed loop.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Eppinger and Tyson R
Steven D. Eppinger and Tyson R. Browning.Design Structure Matrix Methods and Applications. MIT Press, Cambridge, MA, 2012
2012
-
[2]
Donald V . Steward. The design structure system: A method for managing the design of complex systems.IEEE Transactions on Engineering Management, EM-28:71–74, 1981. doi: 10.1109/TEM.1981.6448589
-
[3]
Christoph Langner, Yevheniya Paliyenko, Dominik Roth, and Matthias Kreimeyer. Utilizing DSM and SysML for modeling data flows in complex networks – a case study on autonomous public transportation. InProceedings of the 27th International DSM Conference (DSM 2025), DS 141, pages 11–20, 2025. doi: 10.35199/dsm2025.02
-
[4]
A simulation-based method to evaluate the impact of product architecture on product evolvability
Jianxi Luo. A simulation-based method to evaluate the impact of product architecture on product evolvability. Research in Engineering Design, 26:355–371, 2015. doi: 10.1007/s00163-015-0202-3
-
[5]
Factored dependency structure matrix for representation of multi-connection systems
Hongman Roh, Lena Etzenbach, Alexandre Oltramare, Jonas Norheim, and Olivier de Weck. Factored dependency structure matrix for representation of multi-connection systems. InProceedings of the 27th International DSM Conference (DSM 2025), DS 141, pages 31–40, 2025. doi: 10.35199/dsm2025.04
-
[6]
DSMs for organization design: Incorporating additional criteria in clustering algorithms
Ragnar Solberg, Ali Yassine, Nicolay Worren, Kjetil Soldal, and Thomas Christiansen. DSMs for organization design: Incorporating additional criteria in clustering algorithms. InProceedings of the 27th International DSM Conference (DSM 2025), DS 141, pages 89–98, 2025. doi: 10.35199/dsm2025.10
-
[7]
Tyson R. Browning. Design structure matrix extensions and innovations: A survey and new opportunities.IEEE Transactions on Engineering Management, 63:27–52, 2016. doi: 10.1109/TEM.2015.2491283
-
[8]
Eppinger and Karl T
Steven D. Eppinger and Karl T. Ulrich.Product Design and Development. McGraw-Hill Education, New York, NY , 6th edition, 2016
2016
-
[9]
Thomas U. Pimmler and Steven D. Eppinger. Integration analysis of product decompositions. InProceedings of the ASME Design Theory and Methodology Conference, pages 343–351, 1994. doi: 10.1115/DETC1994-0034
-
[10]
Russell E. Thebeau. Knowledge management of system interfaces and interactions for product development processes. Master’s thesis, Massachusetts Institute of Technology, 2001
2001
-
[11]
Improved clustering algorithm for design structure matrix
Fredrik Börjesson and Katja Hölttä-Otto. Improved clustering algorithm for design structure matrix. InProceedings of the ASME 2012 International Design Engineering Technical Conferences & Computers and Information in Engineering Conference (IDETC/CIE 2012), pages 921–930, 2012. doi: 10.1115/DETC2012-70076
-
[12]
Yassine, and David E
Tian-Li Yu, Ali A. Yassine, and David E. Goldberg. An information theoretic method for developing modular architectures using genetic algorithms.Research in Engineering Design, 18:91–109, 2007. doi: 10.1007/ s00163-007-0030-1
2007
-
[13]
Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D
Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D. Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-V oss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christo- pher Hesse, Mark Chen, Eric Sigler, Mateusz ...
1901
-
[14]
Shuo Jiang, Min Xie, and Jianxi Luo. Large language models for combinatorial optimization of design structure matrix.Proceedings of the Design Society, 5, 2025. doi: 10.1017/pds.2025.10234. 9 DSM MODULARIZATION WITHLARGELANGUAGEMODELS
-
[15]
Tyson R. Browning. Applying the design structure matrix to system decomposition and integration problems: A review and new directions.IEEE Transactions on Engineering Management, 48:292–306, 2001. doi: 10.1109/17. 946528
work page doi:10.1109/17 2001
-
[16]
Le, Denny Zhou, and Xinyun Chen
Chengrun Yang, Xuezhi Wang, Yifeng Lu, Hanxiao Liu, Quoc V . Le, Denny Zhou, and Xinyun Chen. Large language models as optimizers. InInternational Conference on Learning Representations (ICLR 2024), 2024
2024
-
[17]
Mathematical discoveries from program search with large language models
Bernardino Romera-Paredes, Mohammadamin Barekatain, Alexander Novikov, Matej Balog, M. Pawan Kumar, Emilien Dupont, Francisco J. R. Ruiz, Jordan S. Ellenberg, Pengming Wang, Omar Fawzi, Pushmeet Kohli, and Alhussein Fawzi. Mathematical discoveries from program search with large language models.Nature, 625: 468–475, 2024. doi: 10.1038/s41586-023-06924-6
-
[18]
Edwin C. Y . Koh. Auto-DSM: Using a large language model to generate a design structure matrix.Natural Language Processing Journal, 9:100103, 2024. doi: 10.1016/j.nlp.2024.100103
-
[19]
Edwin C. Y . Koh. From text to DSM: Evaluating the impact of writing style and entity naming on LLM-based retrieval of asymmetrical indirect design dependencies.Research in Engineering Design, 37:13, 2026. doi: 10.1007/s00163-026-00476-2
-
[20]
Browning.Modeling and Analyzing Cost, Schedule, and Performance in Complex System Product Development
Tyson R. Browning.Modeling and Analyzing Cost, Schedule, and Performance in Complex System Product Development. PhD thesis, Sloan School of Management, Massachusetts Institute of Technology, 1998
1998
-
[21]
Black, Charles H
Thomas A. Black, Charles H. Fine, and Emanuel M. Sachs. A method for systems design using precedence relationships: An application to automotive brake systems. Working paper, Sloan School of Management, Massachusetts Institute of Technology, 1990
1990
-
[22]
Matching design tasks to knowledge-based software tools: When intuition does not suffice
Rafael Amen, Ingvar Rask, and Staffan Sunnersjö. Matching design tasks to knowledge-based software tools: When intuition does not suffice. InProceedings of the ASME International Design Engineering Technical Conferences and Computers and Information in Engineering Conference (IDETC/CIE 1999), pages 1165–1174. ASME, 1999
1999
-
[23]
John Clarkson, Caroline Simons, and Claudia Eckert
P. John Clarkson, Caroline Simons, and Claudia Eckert. Predicting change propagation in complex design.Journal of Mechanical Design, 126:788–797, 2004. doi: 10.1115/1.1765117
-
[24]
Claude Sonnet 4.6 System Card
Anthropic. Claude Sonnet 4.6 System Card. https://www.anthropic.com/news/claude-sonnet-4-6 , 2026
2026
-
[25]
GPT-5.2 system card
OpenAI. GPT-5.2 system card. https://openai.com/index/gpt-5-system-card-update-gpt-5-2/ , 2025
2025
-
[26]
Qwen3.5: Towards native multimodal agents.https://qwen.ai/blog?id=qwen3.5, 2026
Qwen Team. Qwen3.5: Towards native multimodal agents.https://qwen.ai/blog?id=qwen3.5, 2026
2026
-
[27]
Manuel E. Sosa, Steven D. Eppinger, and Craig M. Rowles. The misalignment of product architecture and organizational structure in complex product development.Management Science, 50:1674–1689, 2004. doi: 10.1287/mnsc.1040.0289
-
[28]
E. A. Leicht and M. E. J. Newman. Community structure in directed networks.Physical Review Letters, 100: 118703, 2008. doi: 10.1103/PhysRevLett.100.118703. A Implementation Details A.1 Prompt Details Each LLM query consists of a system message and a user message. The system message establishes the task context: the LLM is instructed to act as a DSM modula...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.