Recognition: unknown
Akita: A High Usability Simulation Framework for Computer Architecture
Pith reviewed 2026-05-07 05:48 UTC · model grok-4.3
The pith
A dedicated simulation engine decoupled from hardware models overcomes usability barriers in computer architecture research.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Akita is a dedicated simulation engine that cleanly separates infrastructure from architectural models. Smart Ticking and Availability Backpropagation let developers write straightforward cycle-based code that still achieves event-driven performance. Parallel simulation executes transparently on multiple cores while the model code remains single-threaded. Uniform tracing support provides real-time monitoring and post-simulation visualization. These features are demonstrated through working case studies of a trace-based DNN accelerator simulator and a RISC-V CPU simulator.
What carries the argument
Akita simulation engine, which uses Smart Ticking and Availability Backpropagation to deliver event-driven speed from simple cycle-based hardware models while managing parallelism and tracing transparently.
If this is right
- Developers can write single-threaded cycle-based models and obtain automatic multi-core parallel execution.
- Real-time monitoring and post-run visualization become available without extra instrumentation in every model.
- New architectural components can be prototyped and compared more quickly because infrastructure code is written once in the engine.
- The same engine supports both trace-driven and cycle-accurate styles, as shown by the DNN and RISC-V examples.
Where Pith is reading between the lines
- Other simulation domains outside computer architecture could adopt the same engine-model split to reduce duplicated infrastructure work.
- A shared open engine might make it easier for research groups to exchange and compose hardware models without porting effort.
- The tracing layer could become a standard hook for integrating external analysis tools such as power models or formal checkers.
Load-bearing premise
The separation of simulation engine from hardware models will deliver both high performance and substantially higher developer productivity across realistic workloads without hidden costs to accuracy or scalability.
What would settle it
A head-to-head benchmark where the Akita-based RISC-V simulator runs slower or produces different cycle counts than a comparable established simulator on the same set of programs, or developer effort logs showing no measurable reduction in lines of code or debugging time for new models.
Figures









read the original abstract
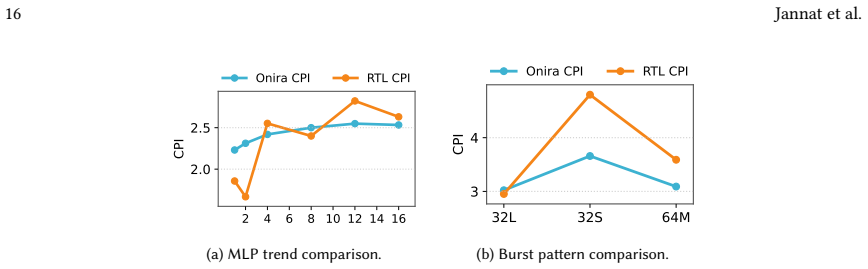
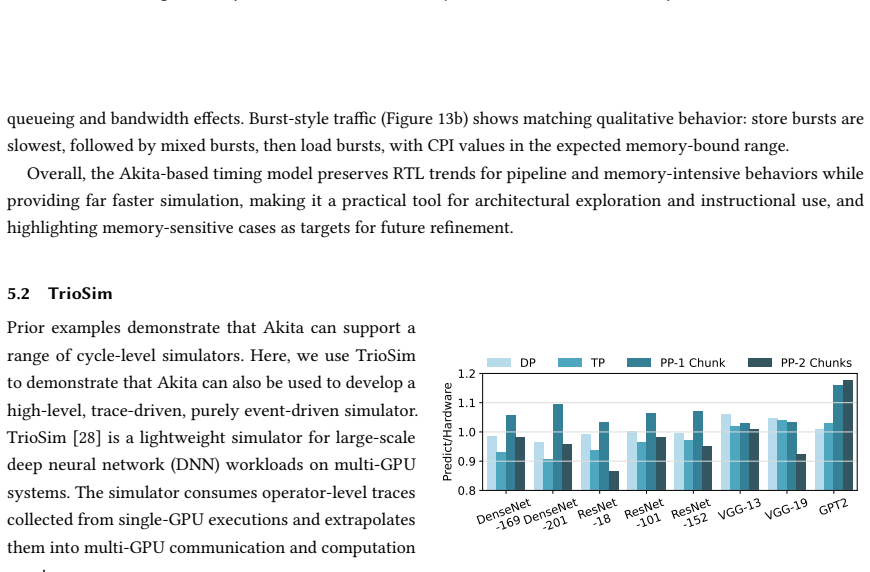
Computer architecture simulation is essential for evaluating new designs without the need for costly tapeout. The community has developed dozens of valuable simulators that have enabled significant architectural advances. However, using and developing simulators remains a major barrier due to ad-hoc component interfaces, strict deployment requirements, the burden of managing performance optimizations like parallelization at the component level, and limited monitoring and visualization capabilities. The root cause of these limitations is the systematic neglect of user and developer experience in favor of technical functionality. We believe that only by separating technical concerns from user and developer experience concerns -- through a dedicated simulation engine decoupled from hardware models -- can the community overcome these fundamental obstacles and enable more productive architectural research. Akita embodies this philosophy as a dedicated simulation engine that cleanly separates infrastructure from architectural models. Smart Ticking and Availability Backpropagation let developers write simple cycle-based code while achieving event-driven performance. Parallel simulation happens transparently -- developers write single-threaded code while Akita handles multi-core execution. Akita's simple, uniform, yet powerful simulation tracing support enables real-time monitoring and post-simulation visualization. We demonstrate the flexibility of Akita through case studies, including the development of a trace-based DNN simulation and a RISC-V CPU simulation, showing how prioritizing developer experience accelerates architectural research.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Akita, a dedicated simulation engine for computer architecture that decouples infrastructure concerns from hardware models to improve usability. It proposes Smart Ticking and Availability Backpropagation to let developers write simple cycle-based models while obtaining event-driven performance, with transparent parallelization and uniform tracing support for monitoring and visualization. These features are illustrated via two case studies: a trace-driven DNN simulator and a RISC-V CPU model, with the central thesis that prioritizing developer experience through engine-model separation overcomes longstanding barriers in simulator development and use.
Significance. If the performance and usability claims hold, Akita could meaningfully lower the barrier to entry for architectural experimentation by allowing researchers to focus on models rather than simulation infrastructure, potentially increasing the rate of design-space exploration. The transparent parallelization and tracing features address real pain points in existing tools, and the design philosophy of clean separation is a constructive contribution to the simulator ecosystem.
major comments (3)
- [Case Studies] Case Studies section: the DNN trace and RISC-V CPU case studies describe the modeling process at a high level but report no quantitative results (wall-clock times, event throughput, IPC or power error versus gem5/SST baselines, lines-of-code counts, or developer-time measurements). Without these data the central claim that the engine-model separation plus Smart Ticking/Availability Backpropagation delivers both high performance and substantially improved productivity remains untested.
- [Design of Smart Ticking and Availability Backpropagation] Design section on Smart Ticking and Availability Backpropagation: the mechanisms are presented as enabling event-driven speed from cycle-based code, yet the manuscript supplies neither a formal correctness argument nor an analysis of potential accuracy or scalability costs (e.g., backpropagation overhead under high core counts or deviation from cycle-accurate semantics). This is load-bearing for the performance claim.
- [Evaluation] Evaluation and related-work sections: no systematic benchmark suite, speedup tables, or direct comparisons against gem5, SST, or custom event-driven simulators appear. The assertion that Akita overcomes “fundamental obstacles” therefore rests on qualitative description rather than empirical evidence.
minor comments (2)
- [Abstract] The abstract states that “dozens of valuable simulators” exist but provides no citations; the introduction should reference representative prior frameworks (gem5, SST, ZSim, etc.) to situate the contribution.
- [Design] Notation for the new primitives (Smart Ticking, Availability Backpropagation) is introduced without a concise summary table or pseudocode listing their interfaces; a small interface table would improve clarity for readers implementing models.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. The comments correctly highlight that the current manuscript relies primarily on qualitative descriptions in the case studies and design sections, which leaves the performance and usability claims insufficiently supported by empirical data. We agree that adding quantitative results, formal reasoning, and systematic comparisons is necessary to substantiate the central thesis. We outline revisions below to address each point.
read point-by-point responses
-
Referee: [Case Studies] Case Studies section: the DNN trace and RISC-V CPU case studies describe the modeling process at a high level but report no quantitative results (wall-clock times, event throughput, IPC or power error versus gem5/SST baselines, lines-of-code counts, or developer-time measurements). Without these data the central claim that the engine-model separation plus Smart Ticking/Availability Backpropagation delivers both high performance and substantially improved productivity remains untested.
Authors: We acknowledge that the case studies as currently written emphasize the modeling workflow and separation of concerns to illustrate usability benefits, without accompanying performance or productivity metrics. This leaves the central claim under-supported. In the revised manuscript we will extend both case studies with quantitative data: wall-clock simulation times and event throughput for the DNN trace simulator; IPC, power estimation error, and wall-clock times versus gem5 for the RISC-V model; lines-of-code counts for the Akita-based models; and, where feasible, qualitative notes on developer effort drawn from our implementation experience. These additions will directly test the performance and productivity assertions. revision: yes
-
Referee: [Design of Smart Ticking and Availability Backpropagation] Design section on Smart Ticking and Availability Backpropagation: the mechanisms are presented as enabling event-driven speed from cycle-based code, yet the manuscript supplies neither a formal correctness argument nor an analysis of potential accuracy or scalability costs (e.g., backpropagation overhead under high core counts or deviation from cycle-accurate semantics). This is load-bearing for the performance claim.
Authors: We agree that the absence of a formal correctness argument and cost analysis is a gap, given that these mechanisms underpin the performance claims. The current text presents the algorithms at a high level to focus on the usability philosophy. In revision we will add a dedicated subsection containing (1) a proof sketch demonstrating that Smart Ticking and Availability Backpropagation preserve the observable cycle-accurate semantics of the original models, (2) an asymptotic and empirical analysis of backpropagation overhead as core count increases, and (3) a discussion of any bounded deviations from strict cycle accuracy together with mitigation strategies. These will be supported by measurements from the expanded case studies. revision: yes
-
Referee: [Evaluation] Evaluation and related-work sections: no systematic benchmark suite, speedup tables, or direct comparisons against gem5, SST, or custom event-driven simulators appear. The assertion that Akita overcomes “fundamental obstacles” therefore rests on qualitative description rather than empirical evidence.
Authors: We concur that the evaluation section is currently limited to descriptive case studies and lacks systematic benchmarks or head-to-head comparisons. This weakens the empirical grounding of the claim that the engine-model separation overcomes longstanding obstacles. We will revise the evaluation section to include a benchmark suite drawn from standard architectural workloads, speedup tables versus single-threaded and parallel baselines, and direct wall-clock and accuracy comparisons against gem5 and SST on the RISC-V model. Related-work discussion will also be expanded to contextualize these results against other event-driven and parallel simulators. revision: yes
Circularity Check
No circularity; descriptive framework with no derivations or fits
full rationale
The paper presents a software simulation framework (Akita) whose core claims rest on design philosophy, separation of engine from models, and qualitative case-study descriptions. No equations, fitted parameters, predictions, or mathematical derivation chain exist in the abstract or described content. Claims about Smart Ticking, Availability Backpropagation, and transparent parallelization are presented as engineering choices, not derived results. No self-citations load-bear on any result, and no ansatz or renaming of known results occurs. This is a standard non-circular software-framework paper whose evidence (or lack thereof) is a separate question of empirical support, not circularity.
Axiom & Free-Parameter Ledger
invented entities (3)
-
Smart Ticking
no independent evidence
-
Availability Backpropagation
no independent evidence
-
Dedicated simulation engine decoupled from hardware models
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Louis-Noel Pouchet: The Polyhedral Benchmark Suite
2018. Louis-Noel Pouchet: The Polyhedral Benchmark Suite. https://sourceforge.net/projects/polybench/
2018
-
[2]
Pablo Abad, Pablo Prieto, Lucia G Menezo, Valentin Puente, José-Ángel Gregorio, et al. 2012. Topaz: An open-source interconnection network simulator for chip multiprocessors and supercomputers. In2012 IEEE/ACM Sixth International Symposium on Networks-on-Chip. IEEE, 99–106. doi:10.1109/NOCS.2012.19
-
[3]
Ayaz Akram and Lina Sawalha. 2016. × 86 computer architecture simulators: A comparative study. In2016 IEEE 34th International Conference on Computer Design (ICCD). IEEE, 638–645. doi:10.1109/ICCD.2016.7753351
-
[4]
Ayaz Akram and Lina Sawalha. 2019. A survey of computer architecture simulation techniques and tools.Ieee Access7 (2019), 78120–78145
2019
-
[5]
Aaron Ariel, Wilson WL Fung, Andrew E Turner, and Tor M Aamodt. 2010. Visualizing complex dynamics in many-core accelerator architectures. In2010 IEEE International Symposium on Performance Analysis of Systems & Software (ISPASS). IEEE, 164–174
2010
-
[6]
Ali Bakhoda, George L Yuan, Wilson WL Fung, Henry Wong, and Tor M Aamodt. 2009. Analyzing CUDA workloads using a detailed GPU simulator. In2009 IEEE international symposium on performance analysis of systems and software. IEEE, 163–174. doi:10.1109/ISPASS.2009.4919648
-
[7]
Yuhui Bao, Yifan Sun, Zlatan Feric, Michael Tian Shen, Micah Weston, José L Abellán, Trinayan Baruah, John Kim, Ajay Joshi, and David Kaeli
-
[8]
InProceedings of the International Conference on Parallel Architectures and Compilation Techniques
Navisim: A highly accurate GPU simulator for AMD RDNA GPUs. InProceedings of the International Conference on Parallel Architectures and Compilation Techniques. 333–345. doi:10.1145/3559009.3569666
-
[9]
Yaniv Ben-Itzhak, Eitan Zahavi, Israel Cidon, and Avinoam Kolodny. 2011. NoCs simulation framework for OMNeT++. InProceedings of the Fifth ACM/IEEE International Symposium on Networks-on-Chip. 265–266. doi:10.1145/1999946.1999993
-
[10]
Nathan Binkert, Bradford Beckmann, Gabriel Black, Steven K Reinhardt, Ali Saidi, Arkaprava Basu, Joel Hestness, Derek R Hower, Tushar Krishna, Somayeh Sardashti, et al. 2011. The gem5 simulator.ACM SIGARCH computer architecture news39, 2 (2011), 1–7. doi:10.1145/2024716.2024718
-
[11]
Trevor E Carlson, Wim Heirman, and Lieven Eeckhout. 2011. Sniper: Exploring the level of abstraction for scalable and accurate parallel multi-core simulation. InProceedings of 2011 International Conference for High Performance Computing, Networking, Storage and Analysis. 1–12. Manuscript submitted to ACM 20 Jannat et al. doi:10.1145/2063384.2063454
-
[12]
Martijn Coenen, Srinivasan Murali, Andrei Ruadulescu, Kees Goossens, and Giovanni De Micheli. 2006. A buffer-sizing algorithm for networks on chip using TDMA and credit-based end-to-end flow control. InProceedings of the 4th international conference on Hardware/software codesign and system synthesis. 130–135
2006
-
[13]
Jason Cong, Mohammad Ali Ghodrat, Michael Gill, Beayna Grigorian, and Glenn Reinman. 2014. Architecture support for domain-specific accelerator-rich cmps.ACM Transactions on Embedded Computing Systems (TECS)13, 4s (2014), 1–26
2014
-
[14]
Anthony Danalis, Gabriel Marin, Collin McCurdy, Jeremy S Meredith, Philip C Roth, Kyle Spafford, Vinod Tipparaju, and Jeffrey S Vetter. 2010. The scalable heterogeneous computing (SHOC) benchmark suite. InProceedings of the 3rd workshop on general-purpose computation on graphics processing units. 63–74. doi:10.1145/1735688.1735702
-
[15]
Nathaniel J Davis IV, David L Mannix, Wade H Shaw, and Thomas C Hartrum. 1990. Distributed discrete-event simulation using null message algorithms on hypercube architectures.J. Parallel and Distrib. Comput.8, 4 (1990), 349–357
1990
-
[16]
Shi Dong and David Kaeli. 2017. Dnnmark: A deep neural network benchmark suite for gpus. InProceedings of the General Purpose GPUs. 63–72. doi:10.1145/3038228.3038239
-
[17]
Richard M Fujimoto. 1990. Parallel discrete event simulation.Commun. ACM33, 10 (1990), 30–53. doi:10.1145/84537.84545
-
[18]
Thomas J Giuli and Mary Baker. 2002. Narses: A scalable flow-based network simulator.arXiv preprint cs/0211024(2002)
work page internal anchor Pith review arXiv 2002
-
[19]
Go standard library. [n. d.]. pprof package. https://pkg.go.dev/net/http/pprof
-
[20]
Xun Gong, Rafael Ubal, and David Kaeli. 2017. Multi2Sim Kepler: A detailed architectural GPU simulator. In2017 IEEE International Symposium on Performance Analysis of Systems and Software (ISPASS). IEEE, 269–278. doi:10.1109/ISPASS.2017.7975298
-
[21]
Anthony Gutierrez, Bradford M Beckmann, Alexandru Dutu, Joseph Gross, Michael LeBeane, John Kalamatianos, Onur Kayiran, Matthew Poremba, Brandon Potter, Sooraj Puthoor, et al. 2018. Lost in abstraction: Pitfalls of analyzing GPUs at the intermediate language level. In2018 IEEE International Symposium on High Performance Computer Architecture (HPCA). IEEE,...
-
[22]
2010.Digital design and computer architecture
David Harris and Sarah Harris. 2010.Digital design and computer architecture. Morgan Kaufmann
2010
-
[23]
Nan Jiang, George Michelogiannakis, Daniel Becker, Brian Towles, and William J Dally. 2010. Booksim 2.0 user’s guide.Standford University(2010), q1
2010
-
[24]
Mahmoud Khairy, Zhesheng Shen, Tor M Aamodt, and Timothy G Rogers. 2020. Accel-Sim: An extensible simulation framework for validated GPU modeling. In2020 ACM/IEEE 47th Annual International Symposium on Computer Architecture (ISCA). IEEE, 473–486. doi:10.1109/ISCA45697.2020.00047
-
[25]
Gregor Kiczales, John Lamping, Anurag Mendhekar, Chris Maeda, Cristina Lopes, Jean-Marc Loingtier, and John Irwin. 1997. Aspect-oriented programming. InECOOP’97—Object-Oriented Programming: 11th European Conference Jyväskylä, Finland, June 9–13, 1997 Proceedings 11. Springer, 220–242
1997
-
[26]
Yoongu Kim, Weikun Yang, and Onur Mutlu. 2015. Ramulator: A fast and extensible DRAM simulator.IEEE Computer architecture letters15, 1 (2015), 45–49
2015
-
[27]
Seonho Lee, Amar Phanishayee, and Divya Mahajan. 2025. Forecasting GPU performance for deep learning training and inference. InProceedings of the 30th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 1. 493–508
2025
-
[28]
Shang Li, Zhiyuan Yang, Dhiraj Reddy, Ankur Srivastava, and Bruce Jacob. 2020. DRAMsim3: A cycle-accurate, thermal-capable DRAM simulator. IEEE Computer Architecture Letters19, 2 (2020), 106–109. doi:10.1109/LCA.2020.2973991
-
[29]
Ying Li, Yuhui Bao, Gongyu Wang, Xinxin Mei, Pranav Vaid, Anandaroop Ghosh, Adwait Jog, Darius Bunandar, Ajay Joshi, and Yifan Sun. 2025. TrioSim: A Lightweight Simulator for Large-Scale DNN Workloads on Multi-GPU Systems. InProceedings of the 52nd Annual International Symposium on Computer Architecture. 1524–1538
2025
-
[30]
Ying Li, Yifan Sun, and Adwait Jog. 2023. Path Forward Beyond Simulators: Fast and Accurate GPU Execution Time Prediction for DNN Workloads. InProceedings of the 56th Annual IEEE/ACM International Symposium on Microarchitecture. 380–394
2023
-
[31]
Mieszko Lis, Keun Sup Shim, Myong Hyon Cho, Pengju Ren, Omer Khan, and Srinivas Devadas. 2010. DARSIM: a parallel cycle-level NoC simulator. (2010)
2010
-
[32]
Changxi Liu, Yifan Sun, and Trevor E Carlson. 2023. Photon: A Fine-grained Sampled Simulation Methodology for GPU Workloads. InProceedings of the 56th Annual IEEE/ACM International Symposium on Microarchitecture. 1227–1241
2023
- [33]
-
[34]
Haocong Luo, Yahya Can Tu, F Nisa Bostancı, Ataberk Olgun, A Giray Ya, Onur Mutlu, et al. 2023. Ramulator 2.0: A Modern, Modular, and Extensible DRAM Simulator.IEEE Computer Architecture Letters(2023)
2023
-
[35]
2009.Clean code: a handbook of agile software craftsmanship
Robert C Martin. 2009.Clean code: a handbook of agile software craftsmanship. Pearson Education
2009
-
[36]
Alian Mohammad, Umur Darbaz, Gabor Dozsa, Stephan Diestelhorst, Daehoon Kim, and Nam Sung Kim. 2017. dist-gem5: Distributed simulation of computer clusters. In2017 IEEE International Symposium on Performance Analysis of Systems and Software (ISPASS). IEEE, 153–162
2017
-
[37]
Ali Mosallaei and YIFAN SUN. 2023. Looking into the Black Box: Monitoring Computer Architecture Simulations in Real-Time with AkitaRTM. (2023)
2023
-
[38]
Francisco Muñoz-Martínez, José L Abellán, Manuel E Acacio, and Tushar Krishna. 2021. Stonne: Enabling cycle-level microarchitectural simulation for dnn inference accelerators. In2021 IEEE International Symposium on Workload Characterization (IISWC). IEEE, 201–213. Manuscript submitted to ACM Akita: A High Usability Simulation Framework for Computer Archit...
2021
-
[39]
Avadh Patel, Furat Afram, Shunfei Chen, and Kanad Ghose. 2011. MARSS: A full system simulator for multicore x86 CPUs. InProceedings of the 48th Design Automation Conference. 1050–1055
2011
-
[40]
Michael Pellauer, Michael Adler, Michel Kinsy, Angshuman Parashar, and Joel Emer. 2011. HAsim: FPGA-based high-detail multicore simulation using time-division multiplexing. In2011 IEEE 17th International Symposium on High Performance Computer Architecture. IEEE, 406–417
2011
-
[41]
Jason Power, Joel Hestness, Marc S Orr, Mark D Hill, and David A Wood. 2014. gem5-gpu: A heterogeneous cpu-gpu simulator.IEEE Computer Architecture Letters14, 1 (2014), 34–36
2014
-
[42]
Saeed Rashidi, Srinivas Sridharan, Sudarshan Srinivasan, and Tushar Krishna. 2020. Astra-sim: Enabling sw/hw co-design exploration for distributed dl training platforms. In2020 IEEE International Symposium on Performance Analysis of Systems and Software (ISPASS). IEEE, 81–92
2020
-
[43]
Arun F Rodrigues, K Scott Hemmert, Brian W Barrett, Chad Kersey, Ron Oldfield, Marlo Weston, Rolf Risen, Jeanine Cook, Paul Rosenfeld, Elliot Cooper-Balis, et al. 2011. The structural simulation toolkit.ACM SIGMETRICS Performance Evaluation Review38, 4 (2011), 37–42
2011
-
[44]
Paul Rosenfeld, Elliott Cooper-Balis, and Bruce Jacob. 2011. DRAMSim2: A cycle accurate memory system simulator.IEEE computer architecture letters10, 1 (2011), 16–19
2011
-
[45]
Daniel Sanchez and Christos Kozyrakis. 2013. ZSim: Fast and accurate microarchitectural simulation of thousand-core systems.ACM SIGARCH Computer architecture news41, 3 (2013), 475–486
2013
-
[46]
Yakun Sophia Shao, Brandon Reagen, Gu-Yeon Wei, and David Brooks. 2014. Aladdin: A pre-rtl, power-performance accelerator simulator enabling large design space exploration of customized architectures.ACM SIGARCH Computer Architecture News42, 3 (2014), 97–108
2014
-
[47]
AMD Staff. 2014. Opencl and the AMD App SDK v2. 4
2014
-
[48]
Yifan Sun, Trinayan Baruah, Saiful A Mojumder, Shi Dong, Xiang Gong, Shane Treadway, Yuhui Bao, Spencer Hance, Carter McCardwell, Vincent Zhao, et al. 2019. MGPUSim: enabling multi-GPU performance modeling and optimization. InProceedings of the 46th International Symposium on Computer Architecture. 197–209
2019
-
[49]
Yifan Sun, Xiang Gong, Amir Kavyan Ziabari, Leiming Yu, Xiangyu Li, Saoni Mukherjee, Carter McCardwell, Alejandro Villegas, and David Kaeli
-
[50]
In2016 IEEE International Symposium on Workload Characterization (IISWC)
Hetero-mark, a benchmark suite for CPU-GPU collaborative computing. In2016 IEEE International Symposium on Workload Characterization (IISWC). IEEE, 1–10
-
[51]
Yifan Sun, Yixuan Zhang, Ali Mosallaei, Michael D Shah, Cody Dunne, and David Kaeli. 2021. Daisen: a framework for visualizing detailed GPU execution. InComputer Graphics Forum, Vol. 40. Wiley Online Library, 239–250
2021
-
[52]
Rafael Ubal, Byunghyun Jang, Perhaad Mistry, Dana Schaa, and David Kaeli. 2012. Multi2Sim: A simulation framework for CPU-GPU computing. In Proceedings of the 21st international conference on Parallel architectures and compilation techniques. 335–344
2012
-
[53]
Rafael Ubal, Julio Sahuquillo, Salvador Petit, and Pedro Lopez. 2007. Multi2sim: A simulation framework to evaluate multicore-multithreaded processors. In19th International Symposium on Computer Architecture and High Performance Computing (SBAC-PAD’07). IEEE, 62–68
2007
-
[54]
Richard A Uhlig and Trevor N Mudge. 1997. Trace-driven memory simulation: A survey.ACM Computing Surveys (CSUR)29, 2 (1997), 128–170. doi:10.1145/254180.254184
-
[55]
Oreste Villa, Daniel Lustig, Zi Yan, Evgeny Bolotin, Yaosheng Fu, Niladrish Chatterjee, Nan Jiang, and David Nellans. 2021. Need for speed: Experiences building a trustworthy system-level gpu simulator. In2021 IEEE International Symposium on High-Performance Computer Architecture (HPCA). IEEE, 868–880. doi:10.1109/HPCA51647.2021.00077
-
[56]
David Wang, Brinda Ganesh, Nuengwong Tuaycharoen, Kathleen Baynes, Aamer Jaleel, and Bruce Jacob. 2005. Dramsim: a memory system simulator.ACM SIGARCH Computer Architecture News33, 4 (2005), 100–107
2005
-
[57]
Thomas F Wenisch, Roland E Wunderlich, Michael Ferdman, Anastassia Ailamaki, Babak Falsafi, and James C Hoe. 2006. SimFlex: statistical sampling of computer system simulation.IEEE Micro26, 4 (2006), 18–31. doi:10.1109/MM.2006.79
-
[58]
Amir Kavyan Ziabari, Rafael Ubal, Dana Schaa, and David Kaeli. 2015. Visualization of OpenCL application execution on CPU-GPU systems. In Proceedings of the Workshop on Computer Architecture Education. 1–8. Manuscript submitted to ACM
2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.