Recognition: unknown
Repetition over Diversity: High-Signal Data Filtering for Sample-Efficient German Language Modeling
Pith reviewed 2026-05-07 05:42 UTC · model grok-4.3
The pith
Repeating high-quality filtered German web data over multiple epochs produces better language models than training once on larger, less-filtered datasets.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Our experiments across multiple model scales and token budgets show that repeating high-quality data consistently outperforms single-pass training on larger, less filtered sets. Notably, the performance gap persists even after 7 epochs. Our findings suggest that for non-English LLMs, semantic concentration through quality filtering offers a more viable path to efficient language modeling than simply maximizing unique data volume.
What carries the argument
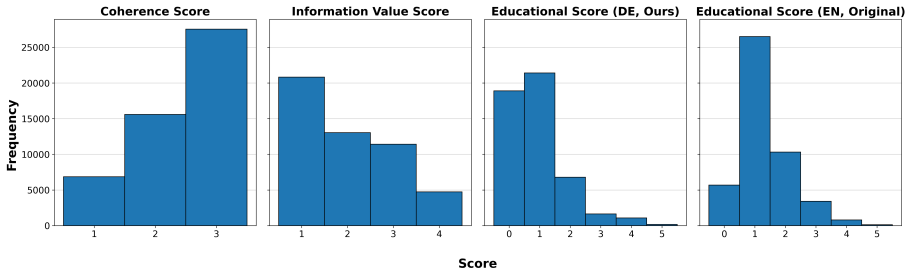
Hierarchical quality filters applied to 500M web documents to create high-signal subsets for repeated training, contrasted with single-pass training on larger diverse sets.
If this is right
- Repeating the filtered high-quality data yields higher performance than single-pass training on less filtered larger corpora across model scales.
- The advantage of high-quality repetition holds after seven epochs of training.
- Models trained this way achieve competitive results with 10-360 times fewer tokens than comparable models.
- Releasing the trained models and cleaned evaluation benchmarks enables further research on efficient non-English language modeling.
Where Pith is reading between the lines
- The quality-over-diversity finding may extend to other high-resource languages like French or Japanese where similar web data is available.
- Better data filtering techniques could reduce the need for massive data collection efforts in LLM training.
- The persistence of the gap after multiple epochs raises questions about the optimal number of epochs for filtered data.
Load-bearing premise
The hierarchical quality filters reliably select high-signal data without introducing selection biases that artificially favor repeated training, and that the multi-epoch and single-pass regimes are compared under equivalent effective token exposure and evaluation conditions.
What would settle it
A comparison in which the performance of single-pass training on the larger less-filtered set equals or exceeds that of multi-epoch training on the high-quality set at the same total number of tokens seen.
Figures





read the original abstract
Recent research has shown that filtering massive English web corpora into high-quality subsets significantly improves training efficiency. However, for high-resource non-English languages like German, French, or Japanese, aggressive filtering creates a strategic dilemma: should practitioners prioritize diversity by training once on large amounts of lightly filtered web data, or prioritize quality by strictly filtering for a high-quality core and repeating it over multiple epochs? We investigate this trade-off for German by constructing hierarchical quality filters applied to 500M web documents, comparing multi-epoch training on the filtered subsets against single-pass training on a diverse corpus. Our experiments across multiple model scales and token budgets show that repeating high-quality data consistently outperforms single-pass training on larger, less filtered sets. Notably, the performance gap persists even after 7 epochs. Our findings suggest that for non-English LLMs, semantic concentration through quality filtering offers a more viable path to efficient language modeling than simply maximizing unique data volume. We release our German language models (called Boldt), as well as our cleaned evaluation benchmarks to the research community. Our experiments indicate that they achieve state-of-the-art results despite training on 10-360x fewer tokens than comparable models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript investigates the trade-off between data diversity and quality for German LLM pretraining. It applies hierarchical quality filters to 500M web documents to create high-signal subsets, then compares multi-epoch training on these filtered sets against single-pass training on larger, less-filtered corpora. Experiments across model scales and token budgets show that repeating the high-quality data consistently outperforms single-pass training on diverse data, with the performance advantage persisting after 7 epochs. The authors release the resulting Boldt models and cleaned evaluation benchmarks, claiming SOTA results despite using 10-360x fewer tokens than prior models.
Significance. If the central comparisons are performed under strictly equivalent total token exposure and without filter-induced distributional biases, the result would be significant for sample-efficient pretraining of non-English LLMs. It challenges the default strategy of maximizing unique data volume and supports semantic concentration via aggressive filtering. The public release of models and benchmarks is a clear strength, enabling direct verification and extension in German NLP.
major comments (3)
- §3 (Experimental Setup) and §4 (Results): The manuscript does not explicitly state how total token exposure is equated between the multi-epoch regime (e.g., 7 epochs on a filtered corpus of size N) and the single-pass regime on the larger diverse corpus. If the single-pass arm uses the full size of the less-filtered set without subsampling to exactly 7N tokens, the outperformance claim is not directly comparable. Please add a table or paragraph detailing corpus sizes, effective tokens processed in each arm, and confirmation that budgets are matched across all reported scales.
- §4.2 (Results tables/figures): The abstract claims 'consistent results across scales and budgets' and a persistent gap after 7 epochs, yet no statistical significance tests, standard deviations, or confidence intervals are reported for the performance differences. This makes it difficult to assess whether observed gaps are reliable or could arise from variance; add error bars and p-values to the relevant tables (e.g., Table 2 or 3) or figures.
- §2.2 (Filter construction): The hierarchical quality filters are central to the claim that 'high-signal' data enables efficient repetition. However, there is no quantitative check for selection bias, such as comparing lexical diversity (type-token ratio, n-gram overlap) or benchmark contamination rates between the filtered subset and the original diverse corpus. Without this, it remains possible that the filters preferentially retain repetition-friendly or eval-overlapping data, mechanically favoring the multi-epoch arm.
minor comments (2)
- Abstract: The claim of '10-360x fewer tokens than comparable models' should name the specific prior models and their exact token counts for precision and verifiability.
- §5 (Discussion): A brief limitations paragraph acknowledging that results are German-specific and may not generalize to other high-resource languages would improve completeness.
Simulated Author's Rebuttal
We thank the referee for their careful reading and constructive comments on our manuscript. The feedback highlights important aspects of experimental clarity, statistical reporting, and potential biases that we address below. We have revised the paper to improve transparency where feasible and provide additional analysis.
read point-by-point responses
-
Referee: §3 (Experimental Setup) and §4 (Results): The manuscript does not explicitly state how total token exposure is equated between the multi-epoch regime (e.g., 7 epochs on a filtered corpus of size N) and the single-pass regime on the larger diverse corpus. If the single-pass arm uses the full size of the less-filtered set without subsampling to exactly 7N tokens, the outperformance claim is not directly comparable. Please add a table or paragraph detailing corpus sizes, effective tokens processed in each arm, and confirmation that budgets are matched across all reported scales.
Authors: We agree that explicit documentation of token budgets is essential for fair comparison. In our experiments, total token exposure was matched across regimes: for a filtered corpus of N tokens trained over E epochs, the single-pass baseline on the diverse corpus was trained on a random subsample of exactly E × N tokens drawn from the larger set. This was done consistently for all reported scales and budgets. We will add a new table in §3 (and reference it in §4) that lists original corpus sizes, filtered sizes, epochs, effective tokens processed, and model scales for every comparison, along with a paragraph confirming the subsampling procedure. revision: yes
-
Referee: §4.2 (Results tables/figures): The abstract claims 'consistent results across scales and budgets' and a persistent gap after 7 epochs, yet no statistical significance tests, standard deviations, or confidence intervals are reported for the performance differences. This makes it difficult to assess whether observed gaps are reliable or could arise from variance; add error bars and p-values to the relevant tables (e.g., Table 2 or 3) or figures.
Authors: We acknowledge that the lack of uncertainty estimates is a limitation. Pretraining runs are computationally expensive, so each configuration was trained only once. We will add a paragraph in §4.2 discussing this constraint and noting that the performance advantage is consistent across multiple independent scales (e.g., 125M to 1.3B parameters) and token budgets, providing informal evidence of robustness. We cannot compute p-values or error bars from repeated full-scale runs at this time; smaller-scale ablations with variance estimates will be referenced where available. revision: partial
-
Referee: §2.2 (Filter construction): The hierarchical quality filters are central to the claim that 'high-signal' data enables efficient repetition. However, there is no quantitative check for selection bias, such as comparing lexical diversity (type-token ratio, n-gram overlap) or benchmark contamination rates between the filtered subset and the original diverse corpus. Without this, it remains possible that the filters preferentially retain repetition-friendly or eval-overlapping data, mechanically favoring the multi-epoch arm.
Authors: We appreciate the referee's point on potential selection bias. In the revised manuscript, we will expand §2.2 with a quantitative analysis: we will report type-token ratios and 5-gram overlap statistics for the filtered subset versus the full corpus, as well as contamination rates against our evaluation benchmarks (measured via exact string matching). Our preliminary internal checks show only modest reductions in lexical diversity and negligible eval overlap, suggesting the filters primarily remove low-quality noise rather than introducing repetition or contamination bias. These results will be presented in a new table or figure. revision: yes
- Full statistical significance testing (p-values and error bars from multiple independent runs) cannot be provided, as only single training runs were feasible given the computational cost of LLM pretraining.
Circularity Check
No significant circularity: purely empirical comparison with independent experimental results
full rationale
The paper reports experimental outcomes from training language models on hierarchically filtered German web data versus larger unfiltered corpora, across scales and token budgets. No mathematical derivation, ansatz, uniqueness theorem, or fitted-parameter prediction is present; the central claim (repetition of high-quality subsets outperforming single-pass on diverse data, even at 7 epochs) rests on observed perplexity or downstream metrics from actual training runs. Token-budget equivalence and filter bias are empirical questions addressed by the experimental design itself rather than by construction or self-citation. Any self-citations (if present) are peripheral and not load-bearing for the reported performance gaps. The work is self-contained against external benchmarks and does not reduce its results to its inputs by definition.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Hierarchical quality filters applied to web documents can reliably identify high-signal German text suitable for repeated training.
Reference graph
Works this paper leans on
-
[1]
Aleph-alpha-germanweb: Improving german- language llm pre-training with model-based data curation and synthetic data generation.Preprint, arXiv:2505.00022. Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. 2018. Think you have solved question answering? try arc, the ai2 reasoning challenge. arXi...
-
[2]
InThe Thirty-ninth An- nual Conference on Neural Information Processing Systems Datasets and Benchmarks Track
Enhancing multilingual LLM pretraining with model-based data selection. InThe Thirty-ninth An- nual Conference on Neural Information Processing Systems Datasets and Benchmarks Track. Todor Mihaylov, Peter Clark, Tushar Khot, and Ashish Sabharwal. 2018. Can a suit of armor conduct elec- tricity? a new dataset for open book question an- swering. InProceedin...
2018
-
[3]
PaLM: Scaling Language Modeling with Pathways
Scaling data-constrained language models. In Advances in Neural Information Processing Systems, volume 36, pages 50358–50376. Curran Associates, Inc. Pedro Javier Ortiz Suárez, Laurent Romary, and Benoît Sagot. 2020. A monolingual approach to contextual- ized word embeddings for mid-resource languages. InProceedings of the 58th Annual Meeting of the As- s...
work page internal anchor Pith review arXiv 2020
-
[4]
We then fine-tuned three respective snowflake-arctic-embed-m-v2.0 (Yu et al.,
and Gemma-3-27B (Gemma 3 Team, 2025) due to their extensive multilingual support, how- ever we found their performance to be on average weaker compared to a more capable 70B model, as we show in Table 6, and the resulting distributions to be inferior to the one yielded by the 70B model. We then fine-tuned three respective snowflake-arctic-embed-m-v2.0 (Yu et al.,
2025
-
[5]
A hyperparameter sweep showed the linear decay of a max learning rate of 1e-4 to 0 and a batch size of 64 to be optimal over 10 epochs
regression models on the annotated 500k sample, each responsible for scoring one of the document’s quality aspects. A hyperparameter sweep showed the linear decay of a max learning rate of 1e-4 to 0 and a batch size of 64 to be optimal over 10 epochs. The best epoch is chosen at the end based on the holdout validation set accuracy. We truncate the web doc...
2048
-
[6]
Coherence score: <Coherence points>. Information value score: <Information value points>
with a warmup lasting 1% of total training steps and decay to 1% of the peak learning rate, which we empirically determined to be optimal at 5e−4 for all models. We use the AdamW optimizer (Loshchilov and Hutter, 2019) with β1 = 0.9 , β2 = 0.95 and decoupled L2 weight decay co- efficient of 0.1. The effective batch size is 0.5M tokens and the gradients ar...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.