Recognition: unknown
Do Sparse Autoencoders Capture Concept Manifolds?
Pith reviewed 2026-05-07 05:20 UTC · model grok-4.3
The pith
Sparse autoencoders capture concept manifolds either by spanning them globally with few features or tiling them locally, but typically mix both in a diluted and fragmented way.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
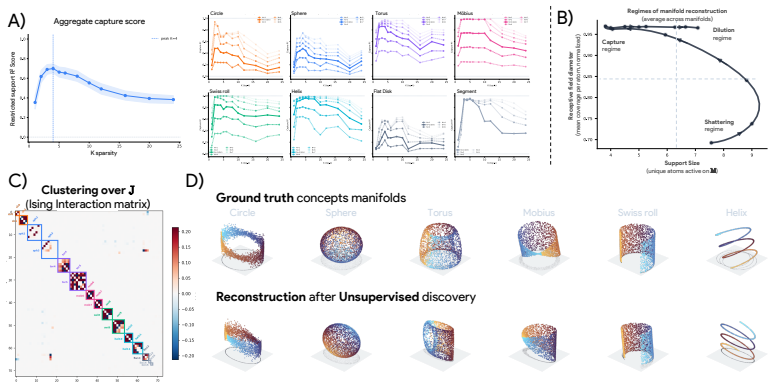
SAEs capture manifolds in two fundamentally different ways: globally, by allocating a compact group of atoms whose linear span contains the entire manifold, or locally, by distributing it across features that each selectively tile a restricted region of the underlying geometry. Empirically, SAEs suboptimally recover continuous structures by mixing the global subspace and local tiling solutions in a fragmented regime called dilution. This explains why manifold structure is rarely visible at the level of individual concepts.
What carries the argument
Global capture via the linear span of a compact group of atoms versus local capture via selective tiling of restricted regions by individual features, which together produce the observed dilution regime.
If this is right
- Manifold structure is rarely visible at the level of individual concepts because of the dilution effect.
- Post-hoc unsupervised discovery methods that search for coherent groups of atoms can recover the manifolds.
- Future representation learning methods should treat geometric objects, not just individual directions, as the basic units of interpretability.
Where Pith is reading between the lines
- Existing SAE dictionaries might contain recoverable manifold structure if features are clustered or grouped rather than examined in isolation.
- The dilution regime could be mitigated by modifying the SAE training objective to penalize fragmentation of continuous structures.
- This distinction between global and local capture may generalize to other sparse coding and dictionary learning approaches.
Load-bearing premise
The theoretical models of how SAEs capture manifolds globally or locally apply to SAEs trained on actual neural network activations from real models.
What would settle it
Training an SAE on activations from a network where concepts are known to form a continuous manifold and checking whether the learned features either form a small spanning set or cleanly tile the manifold without mixing; persistent dilution across multiple such tests would support the claim of suboptimal recovery.
Figures















read the original abstract
Sparse autoencoders (SAEs) are widely used to extract interpretable features from neural network representations, often under the implicit assumption that concepts correspond to independent linear directions. However, a growing body of evidence suggests that many concepts are instead organized along low-dimensional manifolds encoding continuous geometric relationships. This raises three basic questions: what does it mean for an SAE to capture a manifold, when do existing SAE architectures do so, and how? We develop a theoretical framework that answers these questions and show that SAEs can capture manifolds in two fundamentally different ways: globally, by allocating a compact group of atoms whose linear span contains the entire manifold, or locally, by distributing it across features that each selectively tile a restricted region of the underlying geometry. Empirically, we find that SAEs suboptimally recover continuous structures, mixing the global subspace and local tiling solutions in a fragmented regime we call dilution. This explains why manifold structure is rarely visible at the level of individual concepts and motivates post-hoc unsupervised discovery methods that search for coherent groups of atoms rather than isolated directions. More broadly, our results suggest that future representation learning methods should treat geometric objects, not just individual directions, as the basic units of interpretability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper develops a theoretical framework showing that sparse autoencoders (SAEs) can capture low-dimensional concept manifolds in two ways: globally, via a compact group of atoms whose linear span contains the full manifold, or locally, via features that each tile a restricted region of the geometry. It empirically identifies a 'dilution' regime in which standard SAE training (linear decoder + L1 sparsity) mixes these solutions suboptimally, fragmenting recovery of continuous structures. This accounts for the rarity of visible manifold geometry at the level of single features and motivates post-hoc unsupervised methods for discovering coherent atom groups rather than isolated directions. The work concludes that future representation learning should treat geometric objects as basic units of interpretability.
Significance. If the dilution finding and the global/local distinction hold on real data, the result would be significant for mechanistic interpretability. It supplies a coherent explanation for why SAEs often fail to surface continuous relationships and gives a concrete rationale for shifting from single-feature analysis to group-based discovery. The framework is conceptually clean and the empirical observation, if robust, directly informs both SAE training objectives and post-processing pipelines. Credit is due for grounding the claims in a new theoretical analysis rather than purely observational fitting.
major comments (2)
- [Empirical Evaluation] Empirical section (details implied by abstract and experiments on synthetic manifolds): the central claim that SAEs 'suboptimally recover continuous structures' in a dilution regime rests on toy manifold constructions (e.g., circles or lines with uniform sampling). Real neural activations are high-dimensional, noisy, non-uniform, and entangled; without explicit experiments showing that the same global/local fragmentation appears when SAEs are trained on actual model activations (e.g., from language-model residual streams), the 'suboptimal' characterization and the motivation for post-hoc group discovery remain unsupported for the motivating use case. This is load-bearing for the empirical contribution.
- [Theoretical Framework] Theoretical framework (section introducing global vs. local capture): the distinction is plausible under idealized low-dimensional, noise-free assumptions, but the paper does not derive or bound how dilution necessarily arises from standard SAE training on data whose statistics match real activations. A concrete test (e.g., a theorem or controlled ablation showing fragmentation persists when noise and entanglement are added) would strengthen the claim that dilution is a general property rather than an artifact of the synthetic setup.
minor comments (2)
- The term 'dilution' is introduced as a new regime mixing global span and local tiling; a formal metric or equation quantifying the degree of mixing (e.g., in terms of atom allocation or reconstruction error decomposition) would make the concept more precise and reproducible.
- Provide the exact SAE training hyperparameters, manifold sampling procedures, and quantitative metrics used to identify dilution (e.g., any tables or figures reporting R² or reconstruction quality per regime) so that the empirical observation can be directly replicated.
Simulated Author's Rebuttal
We thank the referee for the constructive and insightful report. The comments correctly highlight the need to connect our synthetic analysis more directly to real neural activations and to further test the robustness of the dilution regime. We will revise the manuscript accordingly by adding experiments on language-model activations and controlled ablations with noise and non-uniform sampling. Point-by-point responses to the major comments are provided below.
read point-by-point responses
-
Referee: [Empirical Evaluation] Empirical section (details implied by abstract and experiments on synthetic manifolds): the central claim that SAEs 'suboptimally recover continuous structures' in a dilution regime rests on toy manifold constructions (e.g., circles or lines with uniform sampling). Real neural activations are high-dimensional, noisy, non-uniform, and entangled; without explicit experiments showing that the same global/local fragmentation appears when SAEs are trained on actual model activations (e.g., from language-model residual streams), the 'suboptimal' characterization and the motivation for post-hoc group discovery remain unsupported for the motivating use case. This is load-bearing for the empirical contribution.
Authors: We agree that validation on real activations is important for the motivating application in mechanistic interpretability. The synthetic manifolds were chosen to isolate the global subspace and local tiling mechanisms and to quantify dilution precisely under controlled geometry. In the revised manuscript we will add experiments training SAEs on residual-stream activations from a language model (e.g., GPT-2 small) and evaluate recovery of known continuous structures such as positional or syntactic manifolds. This will test whether fragmentation patterns analogous to the dilution regime appear on real data and thereby support the motivation for post-hoc group discovery. revision: yes
-
Referee: [Theoretical Framework] Theoretical framework (section introducing global vs. local capture): the distinction is plausible under idealized low-dimensional, noise-free assumptions, but the paper does not derive or bound how dilution necessarily arises from standard SAE training on data whose statistics match real activations. A concrete test (e.g., a theorem or controlled ablation showing fragmentation persists when noise and entanglement are added) would strengthen the claim that dilution is a general property rather than an artifact of the synthetic setup.
Authors: The framework establishes that both global (compact spanning set) and local (selective tiling) capture are feasible for low-dimensional manifolds and that standard L1-regularized training can produce a mixture. Dilution is characterized empirically as the fragmented outcome of this mixture. While a general theorem for arbitrary real activation statistics is not derived, the revised manuscript will include controlled ablations that add Gaussian noise, non-uniform sampling, and mild entanglement to the synthetic manifolds. These will show that the fragmentation persists, providing the concrete test requested and indicating that dilution is not an artifact of the idealized uniform case. revision: partial
Circularity Check
No significant circularity; theoretical framework and dilution regime are independently derived.
full rationale
The paper introduces a new theoretical distinction between global (compact atoms spanning the full manifold via linear span) and local (region-tiling atoms) manifold capture by SAEs, then empirically identifies dilution as the observed mixing of these strategies in trained models on both synthetic and real activations. No derivation step reduces by construction to its inputs, self-defines a key quantity, renames a fitted parameter as a prediction, or relies on a load-bearing self-citation chain whose prior result is unverified. The framework provides independent mathematical content, and the central claims remain falsifiable via external experiments rather than tautological. This aligns with the default expectation that most papers exhibit no circularity.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Concepts in neural network representations are organized along low-dimensional manifolds that encode continuous geometric relationships.
- domain assumption SAE atoms can be allocated such that their linear combinations either globally span or locally tile manifold geometry.
invented entities (1)
-
dilution regime
no independent evidence
Forward citations
Cited by 1 Pith paper
-
FeatMap: Understanding image manipulation in the feature space and its implications for feature space geometry
Linear mappings in feature space can reconstruct a wide range of image manipulations including semantic edits, suggesting that feature representations are approximately linearly organized.
Reference graph
Works this paper leans on
-
[1]
URLhttps://arxiv.org/abs/2511.05541. Sid Black, Lee Sharkey, Leo Grinsztajn, Eric Winsor, Dan Braun, Jacob Merizian, Kip Parker, Carlos Ramón Guevara, Beren Millidge, Gabriel Alfour, et al. Interpreting neural networks through the polytope lens.ArXiv e-print, 2022. Trenton Bricken, Adly Templeton, Joshua Batson, Brian Chen, Adam Jermyn, Tom Conerly, Nick ...
-
[2]
onion-like
nonlinearities. Archetypal SAEs (Fel et al., 2025a) address the algorithmic instability of SAEs, and Matryoshka SAEs (Bussmann et al., 2025) and MP-SAEs (Costa et al., 2025) learn hierarchical concept dictionaries. TFA (Lubana et al., 2025) and T-SAEs (Bhalla et al., 2026) incorporate temporal information into dictionary learning methods, allowing for rec...
2025
-
[3]
But this point does not correspond to any observation on the data manifold: 1 2 m1 + 1 2 m′ 1 is generically not a point on M1 (it is a chord, not an arc), and likewise for M2
is a valid reconstruction. But this point does not correspond to any observation on the data manifold: 1 2 m1 + 1 2 m′ 1 is generically not a point on M1 (it is a chord, not an arc), and likewise for M2. The convex hull of landmarks that tile the joint manifold M1 +M 2 is therefore fundamentally different from the Minkowski sum conv(M1) +conv(M 2) that wo...
-
[4]
=0, hence ∥Pj −m ′ 1∥ ≥ ∥Π V2(Pj −m ′ 1)∥=∥m 2 + ΠV2(r)∥ ≥ ∥m 2∥ −ε.(8) Taking the infimum overm′ 1 ∈ M1 on the left and over m2 ∈ M2 on the right yields the result. Point-based dictionary learning tiles the joint manifold.This observation effectively closes the door, for the purposes of this paper, on point-based SAEs as a model offactormanifold recovery...
2004
-
[5]
Encode the full evaluation set{x (j)}through the SAE to obtain codes{z (j)}
-
[6]
For each manifold instance i, select the rows where i is active (using the ground-truth active masks) to obtain the manifold-specific codes Zi ∈R ni×c and the corresponding true contributionsM i ∈R ni×d
-
[7]
At each step, the selected atom’s projection is removed from the residual before selecting the next
Greedily select n atoms by iteratively choosing the decoder direction dj that explains the most residual variance of Mi. At each step, the selected atom’s projection is removed from the residual before selecting the next. 29
-
[8]
Mask the codes to retain only the n selected atoms: Z(n) i =Z i ⊙e selected, where eselected is a binary mask
-
[9]
Decode: ˆM (n) i =Z (n) i W ⊤ dec
-
[10]
An R2 near 1 at n=k i indicates compact subspace capture
Compute the restrictedR 2: R2(i, k, n) = 1− P j ∥m(j) i − ˆm(j,n) i ∥2 P j ∥m(j) i − ¯mi∥2 ,(14) where ¯mi is the mean of the true contributions. An R2 near 1 at n=k i indicates compact subspace capture. We report R2 for n ranging from max(1, ki −2) to ki + 2to visualize how capture improves around the embedding dimension. Note that the greedy selection o...
2014
-
[11]
SAE codes, however, are not Gaussian
and neighborhood selection (Meinshausen & Bühlmann, 2006). SAE codes, however, are not Gaussian. They are sparse (most entries zero), non-negative (due to ReLU or TopK), and their support is constrained (TopK enforces ∥z∥0 =k ). Applying Gaussian graphical model selection to such data would yield inconsistent estimates of the conditional inde- pendence st...
2006
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.