Recognition: 2 theorem links
· Lean TheoremFeatMap: Understanding image manipulation in the feature space and its implications for feature space geometry
Pith reviewed 2026-05-13 03:23 UTC · model grok-4.3
The pith
Image manipulations translate into linear mappings in neural network feature space.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
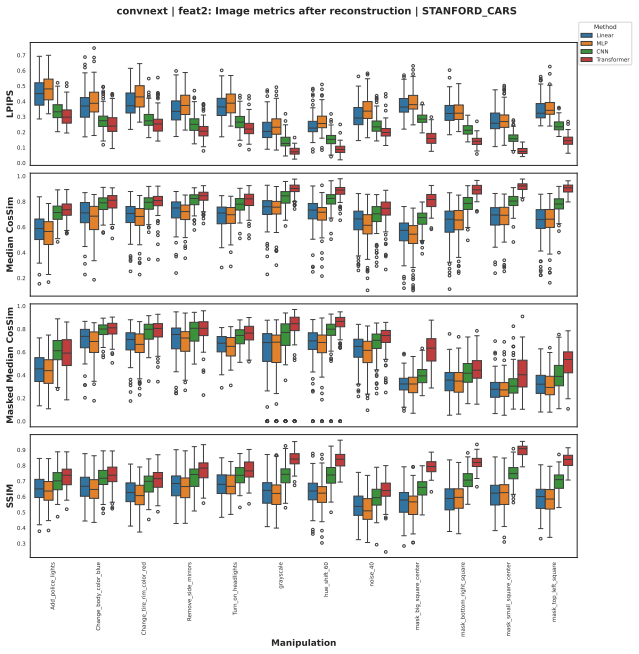
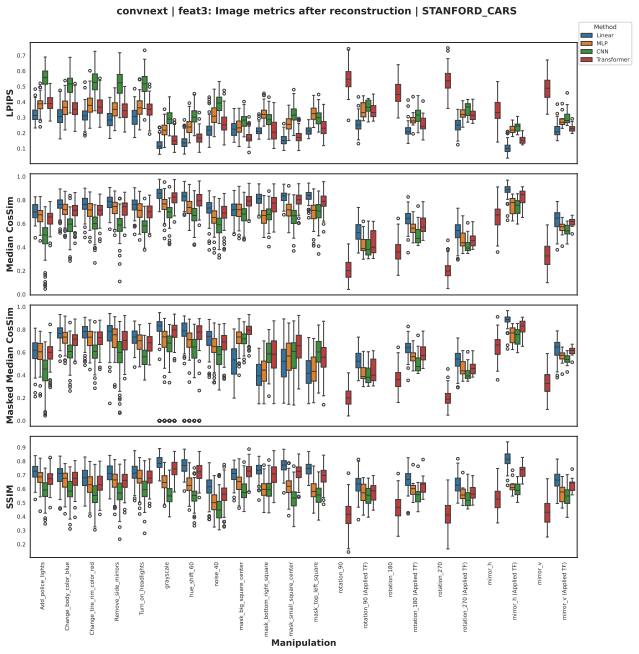
We demonstrate the feasibility of learning such mappings for all considered transformations. While global models that operate on the full feature map often achieve best results, the same can be achieved with a shared linear model operating on a single feature vector typically with very little degradation in reconstruction quality, even for highly non-trivial semantic manipulations. We analyze the corresponding mappings across different feature layers and characterize them according to dominance of weight versus bias and the effective rank of the linear transformations. These results provide hints for the hypothesis that the feature space is to a first degree of approximation organized in lin
What carries the argument
The shared linear transformation applied independently to each feature vector, which maps original features to those of the manipulated image and is analyzed for its weight-bias balance and effective rank per layer.
If this is right
- Linear mappings can be learned successfully for geometric, photometric, masking, and semantic transformations.
- A shared linear model on single feature vectors matches global models with minimal quality loss.
- Mappings differ across layers in weight versus bias dominance and effective rank.
- The results support linear organization of feature space as a first-order description.
- Generative editing models can serve as tools to reveal feature-space geometry via such mappings.
Where Pith is reading between the lines
- Linear feature mappings might support direct image editing by adjusting features linearly without running full generative models each time.
- Many transformations could lie along low-rank linear directions inside the high-dimensional feature space.
- The same linear approximation might be testable in other modalities if analogous input manipulations are defined.
- Combinations of multiple transformations could be composed by adding their linear maps if the structure is truly linear.
Load-bearing premise
The reconstruction quality and semantic preservation metrics used actually reflect meaningful geometric structure rather than superficial correlations in the chosen manipulations and networks.
What would settle it
A concrete counterexample would be an input manipulation for which the linear map produces large reconstruction error or semantic drift while a nonlinear map succeeds, or a set of manipulations where the learned linear maps consistently show high effective rank with no low-dimensional structure.
Figures




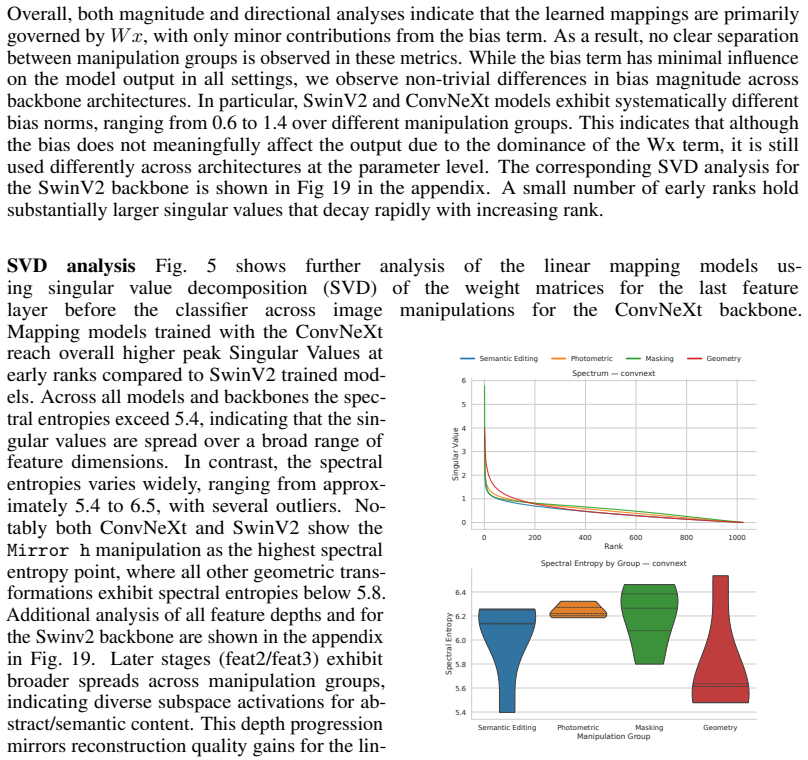










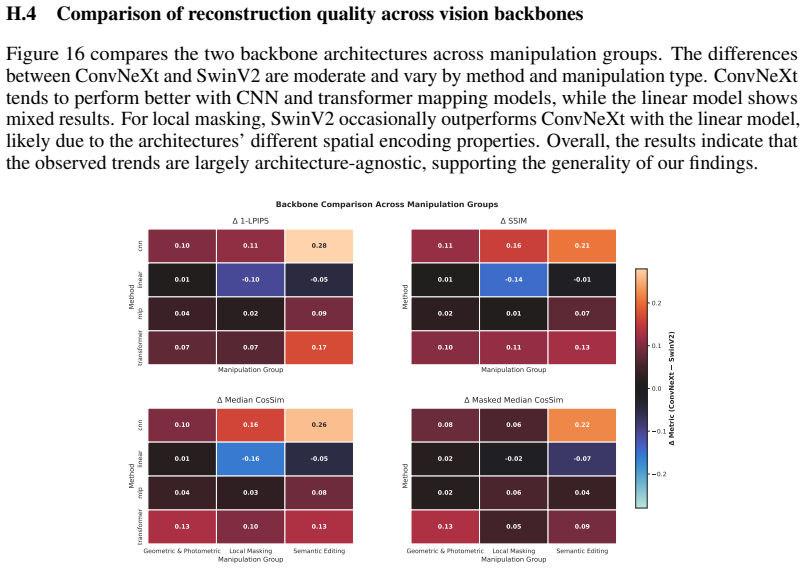
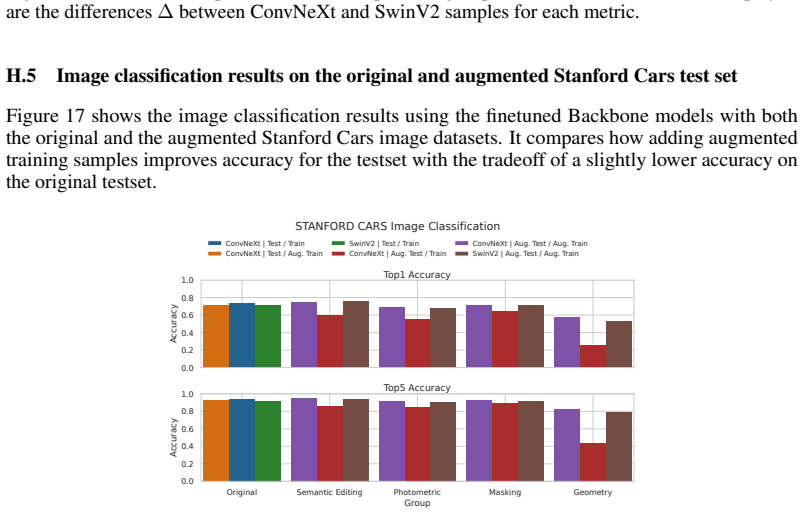



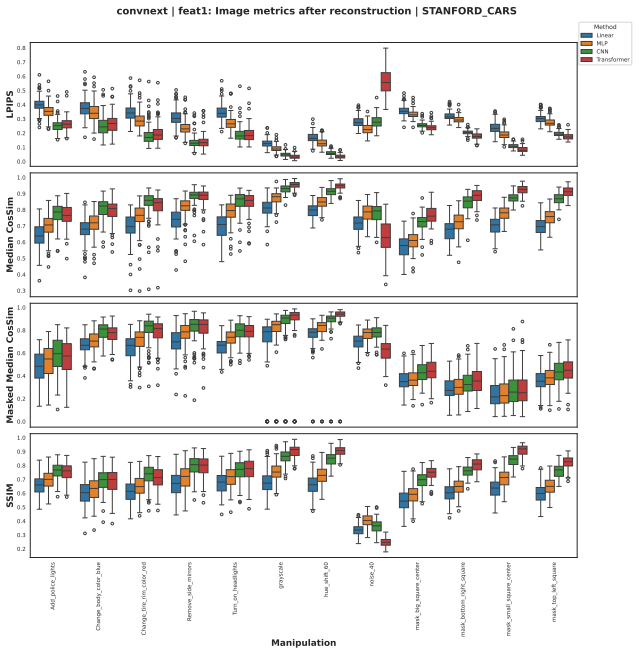

read the original abstract
Intermediate feature representations represent the backbone for the expressivity and adaptability of deep neural networks. However, their geometric structure remains poorly understood. In this submission, we provide indirect insights into this matter by applying a broad selection of manipulations in input space, ranging from geometric and photometric transformations to local masking and semantic manipulations using generative image editing models, and assess the feasibility of learning a mapping in the feature space, mapping from the original to the manipulated feature map. To this end, we devise different types of mappings, from linear to non-linear and local to global mappings and assess both the reconstruction quality of the mapping as well as the semantic content of the mapped representations. We demonstrate the feasibility of learning such mappings for all considered transformations. While global (transformer) models that operate on the full feature map often achieve best results, we show that the same can be achieved with a shared linear model operating on a single feature vector typically with very little degradation in reconstruction quality, even for highly non-trivial semantic manipulations. We analyze the corresponding mappings across different feature layers and characterize them according to dominance of weight vs. bias and the effective rank of the linear transformations. These results provide hints for the hypothesis that the feature space is to a first degree of approximation organized in linear structures. From a broader perspective, the study demonstrates that generative image editing models might open the door to a deeper understanding of the feature space through input manipulation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents an empirical study on the geometric structure of feature representations in deep neural networks. By applying a range of input-space manipulations—from geometric and photometric transformations to local masking and semantic edits generated by image editing models—the authors learn mappings that transform original feature maps to those of the manipulated inputs. They compare linear, non-linear, local, and global mappings, evaluating both reconstruction fidelity and semantic preservation. The key finding is that a shared linear model applied to individual feature vectors performs nearly as well as more complex global non-linear models, even for semantic manipulations, leading to the hypothesis that feature spaces are approximately linearly organized to a first approximation. Analysis of the linear mappings' weights, biases, and effective ranks across layers supports this view.
Significance. If the central claim holds after addressing potential confounds, this would be a significant contribution to understanding DNN internals, suggesting that feature spaces have a simple linear structure that could simplify interpretability, editing, and theoretical analysis of neural networks. The approach of using generative models for controlled semantic manipulations is innovative and could open new avenues for probing representations. The paper provides reproducible empirical evidence through its mapping experiments, though the strength depends on the robustness of the semantic metrics and controls for network-specific effects.
major comments (2)
- [Abstract and Results] Abstract and experimental results on linear vs. non-linear mappings: the claim that shared linear models achieve 'very little degradation' in reconstruction quality and semantic content (even for generative semantic edits) is central to the linear-organization hypothesis, but the abstract and results provide no quantitative details on how semantic content was measured (e.g., specific similarity metrics, human evaluation protocols, or post-hoc choices) or the exact performance gaps, undermining assessment of whether the linear approximability reflects intrinsic geometry.
- [Experimental Design and Analysis] Experimental design and analysis sections: the interpretation that results imply feature space is 'to a first degree of approximation organized in linear structures' is load-bearing, yet no controls for random/non-semantic perturbations, cross-architecture consistency, or generalization to unseen content/different editors are described. This leaves open the possibility that linear success arises from convolutional linearity or latent properties of the specific backbones and chosen manipulations rather than general geometric structure.
minor comments (2)
- [Methods] Clarify early in the methods how 'local' vs. 'global' mappings are formally defined and how the shared linear model is applied across feature vectors.
- [Results] The discussion of weight/bias dominance and effective rank across layers would benefit from explicit references to the relevant figures or tables showing these quantities.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback, which highlights important opportunities to strengthen the clarity and robustness of our claims about the approximate linear organization of feature spaces. We address each major comment below and outline specific revisions to the manuscript.
read point-by-point responses
-
Referee: [Abstract and Results] Abstract and experimental results on linear vs. non-linear mappings: the claim that shared linear models achieve 'very little degradation' in reconstruction quality and semantic content (even for generative semantic edits) is central to the linear-organization hypothesis, but the abstract and results provide no quantitative details on how semantic content was measured (e.g., specific similarity metrics, human evaluation protocols, or post-hoc choices) or the exact performance gaps, undermining assessment of whether the linear approximability reflects intrinsic geometry.
Authors: We agree that the abstract and results sections would benefit from explicit quantitative details to support the central claim. In the revised manuscript, we will expand the abstract to report key numerical findings, including exact degradation levels (e.g., average increase in reconstruction MSE and semantic similarity drop for linear versus non-linear models across manipulation categories). We will also specify the semantic metrics employed (e.g., cosine similarity in a pre-trained CLIP embedding space for global semantic preservation, combined with local feature reconstruction error) and confirm that no post-hoc selection was applied. The results section will include additional tables with per-layer and per-manipulation performance gaps to enable direct evaluation of the linear approximability. revision: yes
-
Referee: [Experimental Design and Analysis] Experimental design and analysis sections: the interpretation that results imply feature space is 'to a first degree of approximation organized in linear structures' is load-bearing, yet no controls for random/non-semantic perturbations, cross-architecture consistency, or generalization to unseen content/different editors are described. This leaves open the possibility that linear success arises from convolutional linearity or latent properties of the specific backbones and chosen manipulations rather than general geometric structure.
Authors: We acknowledge that explicit controls would further isolate the contribution of structured manipulations to the observed linear success. We will add a new subsection with experiments applying random non-semantic perturbations (e.g., Gaussian noise and random pixel shuffling) to demonstrate that linear mappings exhibit substantially larger degradation in these cases, supporting that performance is tied to the geometric structure rather than generic convolutional properties. For cross-architecture consistency, we will include results on an additional backbone (e.g., a CNN variant alongside the primary architecture). For generalization, we will report performance on held-out image content and test mappings trained on one editor with an alternative generative editing model. These additions will address potential confounds while preserving the core empirical findings. revision: partial
Circularity Check
Empirical study of learned mappings with no definitional or self-citation reduction
full rationale
The paper applies input manipulations, learns linear/non-linear mappings from original to manipulated feature maps, and evaluates reconstruction quality plus semantic metrics on held-out cases. The claim that linear models suffice is an empirical performance comparison, not a quantity defined in terms of itself or renamed from a fit. No equations reduce results to inputs by construction, and no load-bearing uniqueness theorem or ansatz is imported via self-citation. The derivation chain consists of data-driven fitting followed by independent evaluation, making the study self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Feature representations extracted by standard vision networks are structured enough that input-space manipulations induce predictable changes in feature space.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We show that the same can be achieved with a shared linear model operating on a single feature vector typically with very little degradation in reconstruction quality, even for highly non-trivial semantic manipulations. ... hints for the hypothesis that the feature space is to a first degree of approximation organized in linear structures.
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanembed_injective unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
the feature space is to a first degree of approximation organized in linear structures
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Daking Rai, Yilun Zhou, Shi Feng, Abulhair Saparov, and Ziyu Yao. A practical review of mechanistic interpretability for transformer-based language models.arXiv preprint arXiv:2407.02646, 2024
-
[2]
Leonard Bereska and Stratis Gavves. Mechanistic interpretability for AI safety - a review.Transactions on Machine Learning Research, 2024. ISSN 2835-8856. URL https://openreview.net/forum?id= ePUVetPKu6. Survey Certification, Expert Certification
work page 2024
-
[3]
Florian Bordes, Randall Balestriero, and Pascal Vincent. High fidelity visualization of what your self- supervised representation knows about.Transactions on Machine Learning Research, 2022. ISSN 2835-8856. URLhttps://openreview.net/forum?id=urfWb7VjmL
work page 2022
-
[4]
Nils Neukirch, Johanna Vielhaben, and Nils Strodthoff. Featinv: Spatially resolved mapping from feature space to input space using conditional diffusion models.Transactions on Machine Learning Research,
-
[5]
URLhttps://openreview.net/forum?id=UtE1YnPNgZ
ISSN 2835-8856. URLhttps://openreview.net/forum?id=UtE1YnPNgZ
-
[6]
The geometry of categorical and hierarchical con- cepts in large language models
Kiho Park, Yo Joong Choe, Yibo Jiang, and Victor Veitch. The geometry of categorical and hierarchical con- cepts in large language models. InThe Thirteenth International Conference on Learning Representations,
-
[7]
URLhttps://openreview.net/forum?id=bVTM2QKYuA
-
[8]
Been Kim, Martin Wattenberg, Justin Gilmer, Carrie Cai, James Wexler, Fernanda Viegas, and Rory Sayres. Interpretability beyond feature attribution: Quantitative testing with concept activation vectors (tcav), 2018. URLhttps://arxiv.org/abs/1711.11279
work page Pith review arXiv 2018
-
[9]
Craft: Concept recursive activation factorization for explainability, 2023
Thomas Fel, Agustin Picard, Louis Bethune, Thibaut Boissin, David Vigouroux, Julien Colin, Rémi Cadène, and Thomas Serre. Craft: Concept recursive activation factorization for explainability, 2023. URL https://arxiv.org/abs/2211.10154
-
[10]
Trenton Bricken, Adly Templeton, Joshua Batson, Brian Chen, Adam Jermyn, Tom Conerly, Nick Turner, Cem Anil, Carson Denison, Amanda Askell, Robert Lasenby, Yifan Wu, Shauna Kravec, Nicholas Schiefer, Tim Maxwell, Nicholas Joseph, Zac Hatfield-Dodds, Alex Tamkin, Karina Nguyen, Brayden McLean, Josiah E Burke, Tristan Hume, Shan Carter, Tom Henighan, and Ch...
-
[11]
https://transformer-circuits.pub/2023/monosemantic-features/index.html
work page 2023
-
[12]
Sparse autoen- coders find highly interpretable features in language models
Robert Huben, Hoagy Cunningham, Logan Riggs Smith, Aidan Ewart, and Lee Sharkey. Sparse autoen- coders find highly interpretable features in language models. InThe Twelfth International Conference on Learning Representations, 2024. URLhttps://openreview.net/forum?id=F76bwRSLeK
work page 2024
-
[13]
Thomas Fel, Ekdeep Singh Lubana, Jacob S Prince, Matthew Kowal, Victor Boutin, Isabel Papadimitriou, Binxu Wang, Martin Wattenberg, Demba E Ba, and Talia Konkle. Archetypal sae: Adaptive and stable dictionary learning for concept extraction in large vision models. InF orty-second International Conference on Machine Learning
-
[14]
Johanna Vielhaben, Stefan Blücher, and Nils Strodthoff. Multi-dimensional concept discovery (MCD): A unifying framework with completeness guarantees.Transactions on Machine Learning Research, 2023. URLhttps://openreview.net/forum?id=KxBQPz7HKh. 10
work page 2023
-
[15]
Thomas Fel, Binxu Wang, Michael A. Lepori, Matthew Kowal, Andrew Lee, Randall Balestriero, Sonia Joseph, Ekdeep Singh Lubana, Talia Konkle, Demba E. Ba, and Martin Wattenberg. Into the rabbit hull: From task-relevant concepts in DINO to minkowski geometry. InThe F ourteenth International Conference on Learning Representations, 2026. URLhttps://openreview....
work page 2026
-
[16]
Beyond scalars: Concept-based alignment analysis in vision transformers
Johanna Vielhaben, Dilyara Bareeva, Jim Berend, Wojciech Samek, and Nils Strodthoff. Beyond scalars: Concept-based alignment analysis in vision transformers. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
work page 2025
-
[17]
Do Sparse Autoencoders Capture Concept Manifolds?
Usha Bhalla, Thomas Fel, Can Rager, Sheridan Feucht, Tal Haklay, Daniel Wurgaft, Siddharth Boppana, Matthew Kowal, Vasudev Shyam, Jack Merullo, Atticus Geiger, and Ekdeep Singh Lubana. Do sparse autoencoders capture concept manifolds?arXiv preprint 2604.28119, 2026. URL https://arxiv.org/ abs/2604.28119
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[18]
3d object representations for fine-grained categorization
Jonathan Krause, Michael Stark, Jia Deng, and Li Fei-Fei. 3d object representations for fine-grained categorization. In4th International IEEE Workshop on 3D Representation and Recognition of Riemannian Surfaces (3DPR 2013), 2013
work page 2013
-
[19]
C. Wah, S. Branson, P. Welinder, P. Perona, and S. Belongie. The caltech-ucsd birds-200-2011 dataset. Technical Report CNS-TR-2011-001, California Institute of Technology, 2011
work page 2011
-
[20]
Feature inversion as a lens on vision encoders
Eduard Allakhverdov, Dmitrii Tarasov, Elizaveta Goncharova, and Andrey Kuznetsov. Feature inversion as a lens on vision encoders. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 3598–3605, 2026
work page 2026
-
[21]
Efficient Estimation of Word Representations in Vector Space
Tomas Mikolov, Kai Chen, Greg Corrado, and Jeffrey Dean. Efficient estimation of word representations in vector space, 2013. URLhttps://arxiv.org/abs/1301.3781
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[22]
Pick the cube and place it on [desc.]
Matthew Trager, Pramuditha Perera, Luca Zancato, Alessandro Achille, Parminder Bhatia, and Stefano Soatto. Linear spaces of meanings: Compositional structures in vision-language models, 2024. URL https://arxiv.org/abs/2302.14383
-
[23]
Implicit semantic data augmentation for deep networks, 2020
Yulin Wang, Xuran Pan, Shiji Song, Hong Zhang, Cheng Wu, and Gao Huang. Implicit semantic data augmentation for deep networks, 2020. URLhttps://arxiv.org/abs/1909.12220
-
[24]
Chenfei Wu, Jiahao Li, Jingren Zhou, Junyang Lin, Kaiyuan Gao, Kun Yan, Sheng ming Yin, Shuai Bai, Xiao Xu, Yilei Chen, Yuxiang Chen, Zecheng Tang, Zekai Zhang, Zhengyi Wang, An Yang, Bowen Yu, Chen Cheng, Dayiheng Liu, Deqing Li, Hang Zhang, Hao Meng, Hu Wei, Jingyuan Ni, Kai Chen, Kuan Cao, Liang Peng, Lin Qu, Minggang Wu, Peng Wang, Shuting Yu, Tingkun...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
The Unreasonable Effectiveness of Deep Features as a Perceptual Metric
Richard Zhang, Phillip Isola, Alexei A. Efros, Eli Shechtman, and Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric.CoRR, abs/1801.03924, 2018. URL http://arxiv. org/abs/1801.03924
work page Pith review arXiv 2018
-
[26]
Zhou Wang, A.C. Bovik, H.R. Sheikh, and E.P. Simoncelli. Image quality assessment: from error visibility to structural similarity.IEEE Transactions on Image Processing, 13(4):600–612, 2004. doi: 10.1109/TIP.2003.819861
-
[27]
Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, and Saining Xie. A convnet for the 2020s. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11976–11986, 2022
work page 2022
-
[28]
Swin transformer v2: Scaling up capacity and resolution, 2022
Ze Liu, Han Hu, Yutong Lin, Zhuliang Yao, Zhenda Xie, Yixuan Wei, Jia Ning, Yue Cao, Zheng Zhang, Li Dong, Furu Wei, and Baining Guo. Swin transformer v2: Scaling up capacity and resolution, 2022. URLhttps://arxiv.org/abs/2111.09883
-
[29]
Battle of the backbones: A large-scale comparison of pretrained models across computer vision tasks
Micah Goldblum, Hossein Souri, Renkun Ni, Manli Shu, Viraj Uday Prabhu, Gowthami Somepalli, Prithvijit Chattopadhyay, Mark Ibrahim, Adrien Bardes, Judy Hoffman, Rama Chellappa, Andrew Gordon Wilson, and Tom Goldstein. Battle of the backbones: A large-scale comparison of pretrained models across computer vision tasks. InThirty-seventh Conference on Neural ...
work page 2023
-
[30]
How learning by reconstruction produces uninformative features for perception
Randall Balestriero and Yann Lecun. How learning by reconstruction produces uninformative features for perception. InInternational Conference on Machine Learning, pages 2566–2585. PMLR, 2024
work page 2024
-
[31]
Benchmarking Neural Network Robustness to Common Corruptions and Perturbations
Dan Hendrycks and Thomas G. Dietterich. Benchmarking neural network robustness to common corrup- tions and perturbations.CoRR, abs/1903.12261, 2019. URLhttp://arxiv.org/abs/1903.12261. 11
work page internal anchor Pith review arXiv 1903
-
[32]
Chang Liu, Yinpeng Dong, Wenzhao Xiang, Xiao Yang, Hang Su, Jun Zhu, Yuefeng Chen, Yuan He, Hui Xue, and Shibao Zheng. A comprehensive study on robustness of image classification models: Benchmarking and rethinking, 2023. URLhttps://arxiv.org/abs/2302.14301
-
[33]
Tomas Mikolov, Wen-tau Yih, and Geoffrey Zweig. Linguistic regularities in continuous space word representations. In Lucy Vanderwende, Hal Daumé III, and Katrin Kirchhoff, editors,Proceedings of the 2013 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 746–751, Atlanta, Georgia, ...
work page 2013
-
[34]
and downsampled via any-pooling over H×W cells to the feature-map resolution. H and W here are the spatial dimensions of each feature map. MdnCS is computed only within the masked spatial regions to enable more accurate evaluation of localized changes. sh,w = ˆF1,h,w · ˆF2,h,w max(∥ ˆF1,h,w∥2∥ ˆF2,h,w∥2, ϵ) (1) Reconstruction: Perceptual and Structural Si...
work page 2011
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.