Recognition: unknown
Crab: A Semantics-Aware Checkpoint/Restore Runtime for Agent Sandboxes
Pith reviewed 2026-05-07 05:53 UTC · model grok-4.3
The pith
Crab uses an eBPF inspector to classify OS effects per agent turn and checkpoint only the recovery-relevant ones, reaching 100% correctness while cutting traffic by up to 87%.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Crab is a transparent host-side runtime that bridges the agent-OS semantic gap without changing agents or C/R backends. An eBPF-based inspector classifies every turn's OS-visible effects as recovery-relevant or irrelevant. A coordinator aligns checkpoints with turn boundaries and overlaps C/R work with LLM wait time. A host-scoped engine then schedules the resulting traffic across co-located sandboxes. On shell-intensive and code-repair workloads this yields 100% recovery correctness, up to 87% less checkpoint traffic, and execution time within 1.9% of the fault-free baseline.
What carries the argument
The eBPF-based inspector that classifies each turn's OS-visible effects as recovery-relevant or irrelevant, then drives selective checkpoint decisions at turn boundaries.
Load-bearing premise
The eBPF inspector can accurately and cheaply label every turn's OS effects as relevant or irrelevant for recovery without missing critical state or adding measurable overhead.
What would settle it
A workload in which an agent turn alters a file, process, or other OS state that the inspector labels irrelevant, yet that state proves necessary for correct restoration after a fault.
Figures















read the original abstract
Autonomous agents act through sandboxed containers and microVMs whose state spans filesystems, processes, and runtime artifacts. Checkpoint and restore (C/R) of this state is needed for fault tolerance, spot execution, RL rollout branching, and safe rollback-yet existing approaches fall into two extremes: application-level recovery preserves chat history but misses OS-side effects, while full per-turn checkpointing is correct but too expensive under dense co-location. The root cause is an agent-OS semantic gap: agent frameworks see tool calls but not their OS effects; the OS sees state changes but lacks turn-level context to judge recovery relevance. This gap hides massive sparsity: over 75% of agent turns produce no recovery-relevant state, so most checkpoints are unnecessary. Crab (Checkpoint-and-Restore for Agent SandBoxes) is a transparent host-side runtime that bridges this gap without modifying agents or C/R backends. An eBPF-based inspector classifies each turn's OS-visible effects to decide checkpoint granularity; a coordinator aligns checkpoints with turn boundaries and overlaps C/R with LLM wait time; and a host-scoped engine schedules checkpoint traffic across co-located sandboxes. On shell-intensive and code-repair workloads, Crab raises recovery correctness from 8% (chat-only) to 100%, cuts checkpoint traffic by up to 87%, and stays within 1.9% of fault-free execution time.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
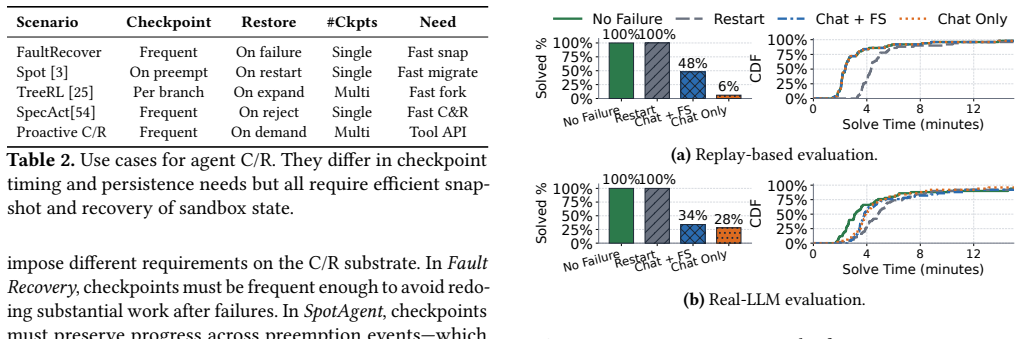
Summary. The paper introduces Crab, a transparent host-side runtime for semantics-aware checkpoint/restore in agent sandboxes. It bridges the agent-OS semantic gap via an eBPF-based inspector that classifies each turn's OS-visible effects (files, processes, artifacts) as recovery-relevant or irrelevant, a coordinator that aligns checkpoints with turn boundaries and overlaps C/R with LLM wait time, and a host-scoped engine for scheduling across co-located sandboxes. The central claim is that this exploits >75% sparsity in relevant turns to achieve 100% recovery correctness (vs. 8% for chat-only), up to 87% reduction in checkpoint traffic, and overhead within 1.9% of fault-free execution on shell-intensive and code-repair workloads, without modifying agents or C/R backends.
Significance. If the eBPF classification is shown to be accurate (no false negatives on recoverable state) and low-overhead, Crab would address a practical gap in fault tolerance, spot execution, and RL branching for containerized agents by avoiding unnecessary full checkpoints while preserving correctness. The approach is novel in its turn-level semantic filtering and could scale to dense co-location scenarios; the empirical gains on the reported workloads, if reproducible with proper controls, would be a useful contribution to OS support for agent systems.
major comments (3)
- [§3.2] §3.2 (eBPF Inspector): The claim of 100% recovery correctness rests on the inspector never producing false negatives when classifying recovery-relevant state mutations. No validation against ground-truth state diffs (e.g., full filesystem/process diffs per turn) or false-negative rate analysis is described; without this, it is impossible to confirm that the 75% sparsity figure reflects measured rather than assumed irrelevance.
- [§5] §5 (Evaluation): Concrete performance numbers (100% correctness, 87% traffic reduction, 1.9% overhead, 75% sparsity) are reported for two workloads without error bars, precise workload definitions, baseline source code or configurations, or micro-benchmarks isolating inspector overhead. This makes it difficult to assess whether the data support the central claims or whether the eBPF component adds measurable cost.
- [§4] §4 (Coordinator and Relevance Definition): The notion of 'recovery-relevant' state is used to justify sparsity and checkpoint decisions but lacks a formal definition or enumeration of what constitutes recoverable artifacts (e.g., specific file types, process trees, or runtime state). This is load-bearing for both the correctness and traffic-reduction results.
minor comments (2)
- [Abstract] Abstract and §1: The 75% sparsity figure is stated as a fact but should be explicitly tied to a measurement section or figure so readers can trace its origin.
- [§5] Figures in §5: Ensure checkpoint traffic and correctness plots include legends, axis units, and comparison baselines (chat-only and full C/R) for immediate readability.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and detailed review. The comments identify areas where additional rigor will strengthen the manuscript, and we will revise accordingly. We respond to each major comment below.
read point-by-point responses
-
Referee: [§3.2] §3.2 (eBPF Inspector): The claim of 100% recovery correctness rests on the inspector never producing false negatives when classifying recovery-relevant state mutations. No validation against ground-truth state diffs (e.g., full filesystem/process diffs per turn) or false-negative rate analysis is described; without this, it is impossible to confirm that the 75% sparsity figure reflects measured rather than assumed irrelevance.
Authors: We acknowledge that the manuscript does not include an explicit empirical validation of the inspector against ground-truth state diffs. The design of the eBPF rules is intentionally conservative (any mutation that could affect subsequent turns is classified as relevant), but we agree this does not substitute for measured evidence. In the revised manuscript we will add a new subsection to §3.2 that reports a ground-truth comparison: for a representative sample of turns we collect full filesystem and process diffs (via snapshots and /proc enumeration) and measure the false-negative rate of the inspector. We will also report the per-workload sparsity as directly measured from these traces rather than as an aggregate claim. revision: yes
-
Referee: [§5] §5 (Evaluation): Concrete performance numbers (100% correctness, 87% traffic reduction, 1.9% overhead, 75% sparsity) are reported for two workloads without error bars, precise workload definitions, baseline source code or configurations, or micro-benchmarks isolating inspector overhead. This makes it difficult to assess whether the data support the central claims or whether the eBPF component adds measurable cost.
Authors: We agree that the evaluation section would be improved by greater statistical detail and reproducibility information. In the revised §5 we will (1) add error bars derived from at least five independent runs per configuration, (2) provide precise workload definitions together with the exact agent prompts, container images, and baseline checkpointing scripts (including repository links), and (3) insert micro-benchmark results that isolate the eBPF inspector overhead by comparing runs with the inspector enabled versus disabled while holding all other components constant. revision: yes
-
Referee: [§4] §4 (Coordinator and Relevance Definition): The notion of 'recovery-relevant' state is used to justify sparsity and checkpoint decisions but lacks a formal definition or enumeration of what constitutes recoverable artifacts (e.g., specific file types, process trees, or runtime state). This is load-bearing for both the correctness and traffic-reduction results.
Authors: We accept that a formal definition is required. In the revised manuscript we will expand the opening of §4 to state: recovery-relevant state is any OS-visible artifact whose mutation persists past the current turn boundary and whose absence would prevent correct restoration to that boundary. We will then enumerate the four categories used by the inspector: (i) non-temporary file-system modifications, (ii) process creations that leave open resources or children, (iii) network sockets and external file descriptors, and (iv) selected runtime artifacts (environment variables, shared-memory segments, and open file handles). This definition directly drives both the sparsity measurement and the coordinator's checkpoint decisions. revision: yes
Circularity Check
No circularity: empirical system results rest on direct measurements, not self-referential derivations
full rationale
The paper describes an implemented runtime (eBPF inspector, coordinator, host-scoped engine) and reports measured outcomes on workloads: recovery correctness rising from 8% to 100%, checkpoint traffic cut by up to 87%, and overhead bounded at 1.9%. These quantities are obtained by running the described components and observing end-to-end behavior; they are not obtained by fitting parameters to a subset of the same data and then re-deriving the same quantities, nor by any equation that takes the target metric as an input. No self-definitional relations, fitted-input predictions, or load-bearing self-citations that collapse the central argument appear in the abstract or the described approach. The 75% sparsity observation is presented as an empirical finding that motivates the design rather than an assumption smuggled into the evaluation. The eBPF classification accuracy is a correctness assumption whose verification is external to any derivation chain.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption eBPF provides complete, low-overhead visibility into OS state changes caused by agent turns without requiring agent or sandbox modifications
- domain assumption Agent turns can be reliably aligned with OS-visible effects at the host level
Reference graph
Works this paper leans on
-
[1]
Amazon Web Services. 2026. Amazon EC2 C6id Instances.https: //aws.amazon.com/ec2/instance-types/c6i/. Accessed 2026-03-26
2026
-
[2]
Amazon Web Services. 2026. Improving startup performance with AWS Lambda SnapStart.https://docs.aws.amazon.com/lambda/latest/ dg/snapstart.html. Accessed 2026-03-26
2026
-
[3]
Amazon Web Services. 2026. Spot Instance interruption notices (Ama- zon EC2 User Guide).https://docs.aws.amazon.com/AWSEC2/lates t/UserGuide/spot-instance-termination-notices.htmlDocuments that interruption notices are issued two minutes before interruption. Accessed: 2026-03-16
2026
-
[4]
Jason Ansel, Kapil Arya, and Gene Cooperman. 2009. DMTCP: Trans- parent Checkpointing for Cluster Computations and the Desktop. InProceedings of the IEEE International Parallel and Distributed Pro- cessing Symposium (IPDPS). IEEE, Rome, Italy, 12 pages.https: //people.csail.mit.edu/jansel/papers/2009ipdps-dmtcp.pdf
2009
-
[5]
Anthropic. 2025. Multi-Agent Research System.https://www.anthro pic.com/engineering/multi-agent-research-system. 2026-04-01
2025
-
[6]
Anthropic. 2026. Checkpointing (Claude Code Docs).https://code.cla ude.com/docs/en/checkpointingAccessed: 2026-03-16
2026
-
[7]
Anthropic. 2026. Claude 4.6.https://www.anthropic.com/claude. Accessed 2026-03-26
2026
-
[8]
Anthropic. 2026. Claude Code Overview (Claude Code Docs).https: //code.claude.com/docs/en/overviewAccessed: 2026-03-16
2026
-
[9]
Lixiang Ao, George Porter, and Geoffrey M Voelker. 2022. Faasnap: Faas made fast using snapshot-based vms. InProceedings of the Seventeenth European Conference on Computer Systems. ACM, Rennes, France, 730– 746
2022
-
[10]
Leonardo Bautista-Gomez, Seiji Tsuboi, Dimitri Komatitsch, Franck Cappello, Naoya Maruyama, and Satoshi Matsuoka. 2011. FTI: High performance fault tolerance interface for hybrid systems. InProceed- ings of 2011 international conference for high performance computing, networking, storage and analysis. ACM, Seattle, WA, USA, 1–32
2011
-
[11]
James Cadden, Thomas Unger, Yara Awad, Han Dong, Orran Krieger, and Jonathan Appavoo. 2020. SEUSS: Skip Redundant Paths to Make Serverless Fast. InEuropean Conference on Computer Systems (EuroSys). ACM, New York, NY, USA, 1 – 15. doi:10.1145/3342195.3392698
-
[12]
Yang Chen. 2015. Checkpoint and restore of micro-service in docker containers. In2015 3rd International Conference on Mechatronics and Industrial Informatics (ICMII 2015). Atlantis Press, Zhuhai, China, 915– 918
2015
-
[13]
CRIU Project. 2025. CRIU: Checkpoint/Restore In Userspace (Main Page).https://criu.org/Main_PageDescribes freezing containers/apps and checkpointing state to disk. Accessed: 2026-03-16
2025
-
[14]
Xinhao Deng, Yixiang Zhang, Jiaqing Wu, Jiaqi Bai, Sibo Yi, Zhuoheng Zou, Yue Xiao, Rennai Qiu, Jianan Ma, Jialuo Chen, Xiaohu Du, Xiao- fang Yang, Shiwen Cui, Changhua Meng, Weiqiang Wang, Jiaxing Song, Ke Xu, and Qi Li. 2026. Taming OpenClaw: Security Analysis and Mit- igation of Autonomous LLM Agent Threats. arXiv:2603.11619 [cs.CR] https://arxiv.org/a...
-
[15]
Dong Du, Tianyi Yu, Yubin Xia, Binyu Zang, Guanglu Yan, Chenggang Qin, Qixuan Wu, and Haibo Chen. 2020. Catalyzer: Sub-millisecond Startup for Serverless Computing with Initialization-less Booting. In International Conference on Architectural Support for Programming Lan- guages and Operating Systems (ASPLOS). ACM, Lausanne, Switzerland, 467–481. doi:10.11...
-
[16]
E2B. 2026. E2B Documentation.https://e2b.dev/docsDescribes isolated sandboxes for agents to execute code, process data, and run tools. Accessed: 2026-03-16
2026
-
[17]
E2B. 2026. Sandbox Snapshots.https://e2b.dev/docs/sandbox/snaps hots. Accessed 2026-03-17
2026
-
[18]
Assaf Eisenman, Kiran Kumar Matam, Steven Ingram, Dheevatsa Mudigere, Raghuraman Krishnamoorthi, Krishnakumar Nair, Misha Smelyanskiy, and Murali Annavaram. 2022. Check-N-Run: A Check- pointing System for Training Deep Learning Recommendation Models. In19th USENIX Symposium on Networked Systems Design and Imple- mentation (NSDI). USENIX Association, Rento...
2022
-
[19]
Firecracker. 2026. Firecracker Snapshotting.https://github.com/firec racker-microvm/firecracker/blob/main/docs/snapshotting/snapshot- support.md. Accessed 2026-03-17
2026
-
[20]
Wei Gao, Yuheng Zhao, Tianyuan Wu, Shaopan Xiong, Weixun Wang, Dakai An, Lunxi Cao, Dilxat Muhtar, Zichen Liu, Haizhou Zhao, Ju Huang, Siran Yang, Yongbin Li, Wenbo Su, Jiamang Wang, Lin Qu, Bo Zheng, and Wei Wang. 2025. RollArt: Scaling Agentic RL Training via Disaggregated Infrastructure. arXiv:2512.22560 [cs.DC]https: //arxiv.org/abs/2512.22560
-
[21]
Paul H Hargrove and Jason C Duell. 2006. Berkeley lab check- point/restart (blcr) for linux clusters.Journal of Physics: Conference Series46, 1 (2006), 494–499
2006
-
[22]
Jialiang Huang, Mingxing Zhang, Teng Ma, Zheng Liu, Sixing Lin, Kang Chen, Jinlei Jiang, Xia Liao, Yingdi Shan, Ning Zhang, Mengting Lu, Tao Ma, Haifeng Gong, and Yongwei Wu. 2024. TrEnv: Trans- parently Share Serverless Execution Environments Across Different Functions and Nodes. InACM SIGOPS Symposium on Operating Sys- tems Principles (SOSP). ACM, Hilto...
-
[23]
iFlow-cli. 2026. iFlow-cli.https://cli.iflow.cn/. Accessed 2026-03-26
2026
-
[24]
illumos Project. 2026. Working With ZFS Snapshots and Clones (ZFS Administration Guide).https://www.illumos.org/books/zfs-admi n/snapshots.htmlDefines ZFS snapshots as read-only, near-instant, copy-on-write point-in-time filesystem copies. Accessed: 2026-03-16
2026
- [25]
-
[26]
LangChain. 2026. Persistence (LangGraph Docs).https://docs.langcha in.com/oss/python/langgraph/persistenceDescribes checkpointing of graph state at every step, threads, and time-travel debugging. Accessed: 2026-03-16
2026
-
[27]
Linux Kernel Developers. 2026. Control Groups (cgroups) v2 (Linux Kernel Documentation).https://docs.kernel.org/admin-guide/cgroup- v2.htmlDescribes the unified cgroup hierarchy for resource control and process grouping. Accessed: 2026-03-16
2026
-
[28]
Linux Kernel Developers. 2026. eBPF Syscall (Linux Kernel Documen- tation).https://docs.kernel.org/userspace-api/ebpf/syscall.html Reference for loading/attaching eBPF programs (including tracing/c- group attachment points). Accessed: 2026-03-16
2026
-
[29]
Linux Kernel Developers. 2026. Soft-Dirty PTEs (Linux Kernel Doc- umentation).https://www.kernel.org/doc/html/v5.4/admin- guide/mm/soft-dirty.htmlDescribes soft-dirty tracking. Accessed: 2026-03-16
2026
-
[30]
LlamaIndex. 2026. Maintaining state (LlamaIndex Docs).https://deve lopers.llamaindex.ai/python/framework/understanding/agent/state/ Explains that AgentWorkflow is stateless by default and uses Context to maintain state across runs. Accessed: 2026-03-16
2026
-
[31]
Terminal-Bench: Benchmarking Agents on Hard, Realistic Tasks in Command Line Interfaces
Mike A. Merrill, Alexander G. Shaw, Nicholas Carlini, et al . 2026. Terminal-Bench: Benchmarking Agents on Hard, Realistic Tasks in Command Line Interfaces. arXiv:2601.11868 [cs.AI]
work page internal anchor Pith review arXiv 2026
-
[32]
Xupeng Miao, Chunan Shi, Jiangfei Duan, Xiaoli Xi, Dahua Lin, Bin Cui, and Zhihao Jia. 2024. SpotServe: Serving Generative Large Lan- guage Models on Preemptible Instances. InProceedings of the 29th ACM International Conference on Architectural Support for Program- ming Languages and Operating Systems, Volume 2(La Jolla, CA, USA) (ASPLOS ’24). Association...
-
[33]
Microsoft. 2026. Managing State (AutoGen Docs).https://microsof t.github.io/autogen/stable/user-guide/agentchat-user-guide/tuto 14 rial/state.htmlOfficial tutorial on saving/loading agent/team state. Accessed: 2026-03-16
2026
-
[34]
MiniMax. 2026. MiniMax M2.7.https://www.minimaxi.com/models/ text/m27. Accessed 2026-03-26
2026
-
[35]
Jayashree Mohan, Amar Phanishayee, and Vijay Chidambaram. 2021. CheckFreq: Frequent, Fine-Grained DNN Checkpointing. In19th USENIX Conference on File and Storage Technologies (FAST). USENIX Association, Virtual Event, 203–216.https://www.usenix.org/confere nce/fast21/presentation/mohan
2021
-
[36]
Adam Moody, Greg Bronevetsky, Kathryn Mohror, and Bronis R De Supinski. 2010. Design, modeling, and evaluation of a scalable multi-level checkpointing system. InSC’10: Proceedings of the 2010 ACM/IEEE International Conference for High Performance Computing, Networking, Storage and Analysis. IEEE, New Orleans, LA, USA, 1–11
2010
- [37]
-
[38]
Open Container Initiative. 2026. runc Checkpoint/Restore Documen- tation.https://github.com/opencontainers/runc/blob/main/docs/ch eckpoint-restore.mdDocuments runc checkpoint/restore integration with CRIU. Accessed: 2026-03-16
2026
-
[39]
OpenAI. 2026. Codex Overview (OpenAI Codex Docs).https://open ai.com/codex/Accessed: 2026-03-16
2026
-
[40]
OpenAI. 2026. Run Long-Horizon Tasks with Codex.https://develope rs.openai.com/blog/run-long-horizon-tasks-with-codex. 2026-04-01
2026
-
[41]
OpenClaw. 2026. Sandboxing (OpenClaw Docs).https://docs.ope nclaw.ai/gateway/sandboxingExplains that gateway stays on host; tool execution can run in Docker sandbox; sandboxing reduces blast radius but is not a perfect boundary. Accessed: 2026-03-16
2026
-
[42]
OpenHands. 2026. Docker Sandbox (OpenHands Docs).https://do cs.openhands.dev/openhands/usage/sandboxes/dockerStates that Docker sandbox runs the agent server inside a Docker container by default/recommended. Accessed: 2026-03-16
2026
-
[43]
Ohad Rodeh, Josef Bacik, and Chris Mason. 2013. BTRFS: The Linux B-Tree Filesystem.ACM Trans. Storage9, 3, Article 9 (Aug. 2013), 32 pages. doi:10.1145/2501620.2501623
-
[44]
Foteini Strati, Sara McAllister, Amar Phanishayee, Jakub Tarnawski, and Ana Klimovic. 2024. DéjàVu: KV-cache streaming for fast, fault- tolerant generative LLM serving. InProceedings of the 41st International Conference on Machine Learning(Vienna, Austria)(ICML’24). JMLR.org, Article 1902, 27 pages
2024
- [45]
-
[46]
Weixun Wang, XiaoXiao Xu, Wanhe An, Fangwen Dai, Wei Gao, Yancheng He, Ju Huang, Qiang Ji, Hanqi Jin, Xiaoyang Li, et al
-
[47]
Let It Flow: Agentic Crafting on Rock and Roll, Building the ROME Model within an Open Agentic Learning Ecosystem. arXiv:2512.24873 [cs.AI]https://arxiv.org/abs/2512.24873
-
[48]
OpenHands: An Open Platform for AI Software Developers as Generalist Agents
Xingyao Wang, Boxuan Li, Yufan Song, Frank F. Xu, Xiangru Tang, Mingchen Zhuge, Jiayi Pan, Yueqi Song, Bowen Li, Jaskirat Singh, Hoang H. Tran, Fuqiang Li, Ren Ma, Mingzhang Zheng, Bill Qian, Yan- jun Shao, Niklas Muennighoff, Yizhe Zhang, Binyuan Hui, Junyang Lin, Robert Brennan, Hao Peng, Heng Ji, and Graham Neubig. 2025. Open- Hands: An Open Platform f...
work page internal anchor Pith review arXiv 2025
-
[49]
Zhuang Wang, Zhen Jia, Shuai Zheng, Zhen Zhang, Xinwei Fu, T. S. Eu- gene Ng, and Yida Wang. 2023. Gemini: Fast Failure Recovery in Distributed Training with In-Memory Checkpoints. InACM SIGOPS Symposium on Operating Systems Principles (SOSP). ACM, Koblenz, Germany, 364–381. doi:10.1145/3600006.3613145
-
[50]
Fangnuo Wu, Mingkai Dong, Gequan Mo, and Haibo Chen. 2023. Treesls: A whole-system persistent microkernel with tree-structured state checkpoint on nvm. InProceedings of the 29th Symposium on Operating Systems Principles. ACM, Koblenz, Germany, 1–16
2023
-
[51]
Hanafy, Tarek Abdelzaher, David Irwin, Jesse Milzman, and Prashant Shenoy
Li Wu, Walid A. Hanafy, Tarek Abdelzaher, David Irwin, Jesse Milzman, and Prashant Shenoy. 2025. FailLite: Failure-Resilient Model Serving for Resource-Constrained Edge Environments. arXiv:2504.15856 [cs.DC]https://arxiv.org/abs/2504.15856
- [52]
- [53]
-
[54]
John Yang, Carlos E Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press. 2024. Swe-agent: Agent- computer interfaces enable automated software engineering.Advances in Neural Information Processing Systems37 (2024), 50528–50652
2024
-
[55]
Naimeng Ye, Arnav Ahuja, Georgios Liargkovas, Yunan Lu, Kostis Kaffes, and Tianyi Peng. 2026. Speculative Actions: A Lossless Framework for Faster Agentic Systems. arXiv:2510.04371 [cs.AI] https://arxiv.org/abs/2510.04371
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [56]
- [57]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.