Recognition: unknown
AEGIS: A Holistic Benchmark for Evaluating Forensic Analysis of AI-Generated Academic Images
Pith reviewed 2026-05-07 07:30 UTC · model grok-4.3
The pith
AEGIS benchmark reveals that even advanced models detect AI-generated academic images at only 48.80 percent overall accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
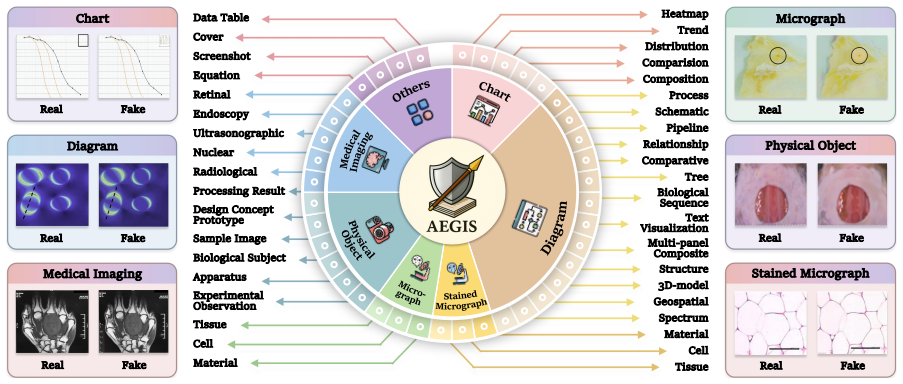
AEGIS is a holistic benchmark for forensic analysis of AI-generated academic images. It advances prior work through domain-specific complexity across seven academic categories and 39 subtypes, diverse forgery simulations of four prevalent academic strategies using 25 generative models, and multi-dimensional evaluation that jointly measures detection, reasoning, and localization. When applied to 25 leading multimodal large language models, nine expert models, and one unified model, the benchmark finds GPT-5.1 at 48.80 percent overall performance, expert models limited to 30.09 percent IoU localization accuracy, 11 generative models yielding average forensic accuracy below 50 percent, MLLMs at
What carries the argument
The AEGIS benchmark dataset and its three-axis evaluation protocol that measures binary authenticity detection, textual artifact reasoning, and pixel-level localization on domain-specific academic images.
Load-bearing premise
The 39 academic subtypes and four simulated forgery strategies drawn from 25 generative models sufficiently represent the real-world distribution and difficulty of AI-generated academic images.
What would settle it
A new forensic system that achieves greater than 85 percent accuracy across all detection, reasoning, and localization tasks on the full AEGIS test set while maintaining the same performance on held-out real academic images would falsify the claim of fundamental limitations.
Figures




















read the original abstract
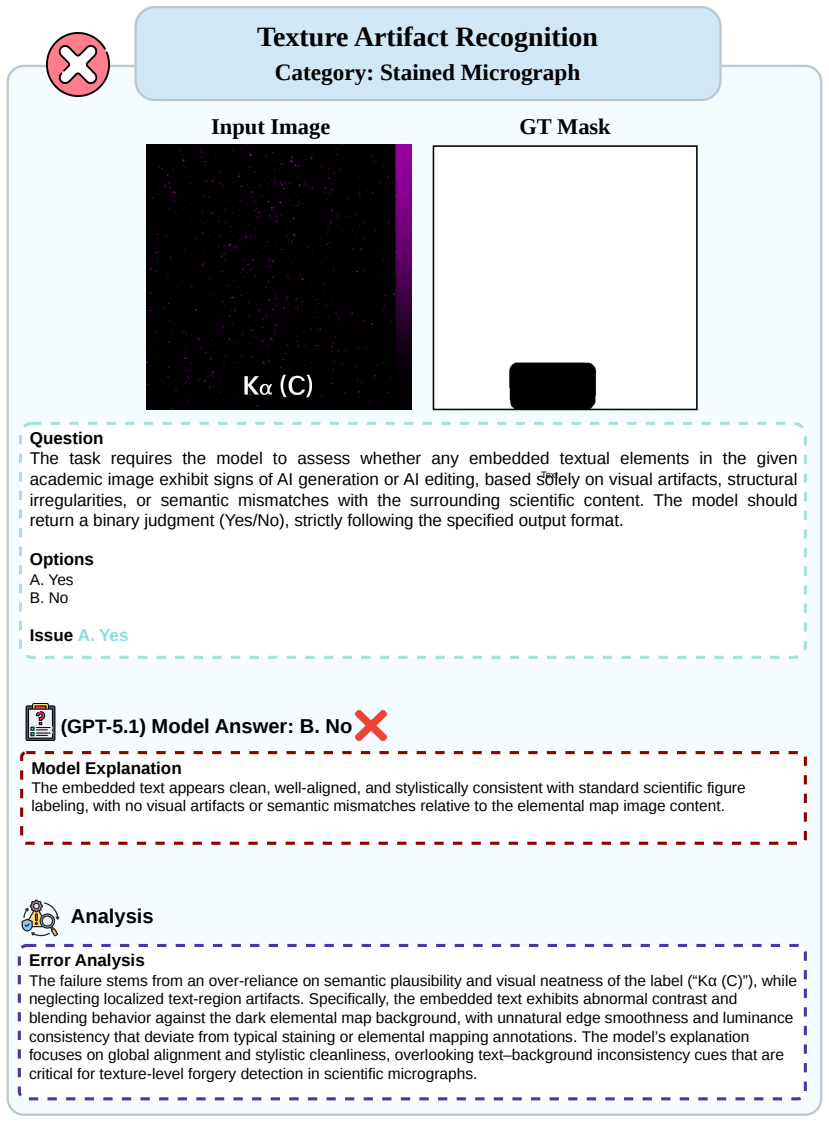
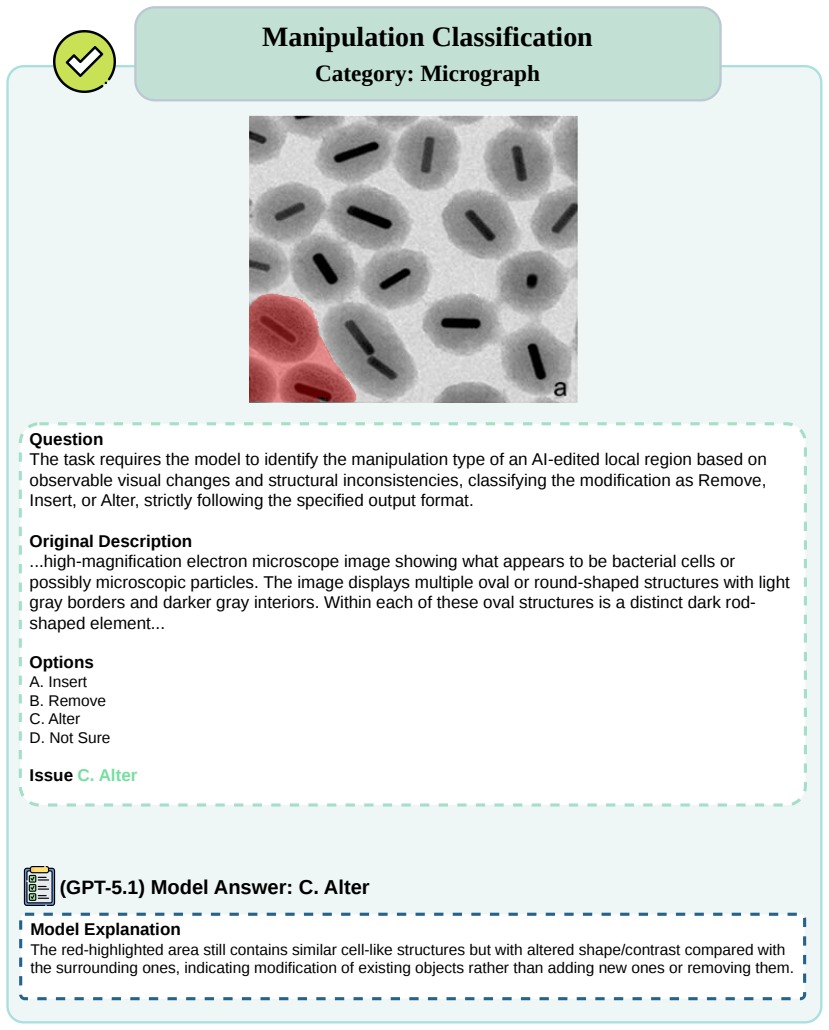
We introduce AEGIS, A holistic benchmark for Evaluating forensic analysis of AI-Generated academic ImageS. Compared to existing benchmarks, AEGIS features three key advances: (1) Domain-Specific Complexity: covering seven academic categories with 39 fine-grained subtypes, exposing intrinsic forensic difficulty, where even GPT-5.1 reaches 48.80% overall performance and expert models achieve only limited localization accuracy (IoU 30.09%); (2) Diverse Forgery Simulations: modeling four prevalent academic forgery strategies across 25 generative models, with 11 yielding average forensic accuracy below 50%, showing that forensics lag behind generative advances; and (3) Multi-Dimensional Forensic Evaluation: jointly assessing detection, reasoning, and localization, revealing complementary strengths between model families, with multimodal large language models (MLLMs) at 84.74% accuracy in textual artifact recognition and expert detectors peaking at 79.54% accuracy in binary authenticity detection. By evaluating 25 leading MLLMs, nine expert models, and one unified multimodal understanding and generation model, AEGIS serves as a diagnostic testbed exposing fundamental limitations in academic image forensics.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces AEGIS, a benchmark for forensic analysis of AI-generated academic images. It spans seven academic categories with 39 fine-grained subtypes, simulates four forgery strategies using 25 generative models, and evaluates 25 MLLMs plus nine expert detectors across detection, reasoning, and localization tasks. Key reported results include GPT-5.1 reaching only 48.80% overall performance, expert models at 30.09% IoU for localization, MLLMs at 84.74% on textual artifact recognition, and expert detectors at 79.54% on binary authenticity detection, positioning AEGIS as a diagnostic testbed for fundamental limitations in academic image forensics.
Significance. If the benchmark construction proves representative of real academic forgeries, AEGIS would offer a useful standardized resource for the community. The multi-dimensional evaluation protocol, broad coverage of model families, and explicit comparison of generative versus forensic capabilities could help guide future work on image integrity in scholarly publishing. The empirical scale (25+ models evaluated) is a practical strength for a benchmark paper.
major comments (3)
- [§3] §3 (Benchmark Construction): The central claim that low performances (e.g., GPT-5.1 at 48.80%, expert IoU 30.09%) expose 'fundamental limitations' and that 'forensics lag behind generative advances' rests on the assumption that the 39 subtypes and four simulated forgery strategies match the distribution of real AI-generated academic images. The manuscript constructs these via simulation with 25 generative models but reports no external validation (statistical comparison of artifacts, expert realism ratings, or direct comparison against disclosed real AI figures from arXiv or journals). This is load-bearing for the 'diagnostic testbed' assertion.
- [§4] §4 (Evaluation Protocol): Performance numbers are presented as point estimates (e.g., 48.80% overall, 84.74% textual artifact recognition) without reported confidence intervals, per-category variance, or statistical tests for differences between MLLM and expert families. Given the claim of 'complementary strengths' and the use of held-out test images, absence of these measures makes it difficult to judge whether observed gaps are robust or sensitive to image selection.
- [§2, §5] §2 and §5 (Related Work and Discussion): The selection of the 25 generative models and the four forgery strategies is described at a high level, but the paper does not detail inclusion criteria or whether the set covers recent techniques (e.g., latest diffusion or autoregressive models). This affects the strength of the conclusion that 11 models yield <50% forensic accuracy and that forensics are lagging.
minor comments (2)
- [Tables] Table captions and axis labels in result tables should explicitly define all abbreviations (e.g., IoU, MLLM) and report the exact number of images per subtype to allow reproducibility.
- [Figure 1] The pipeline figure would benefit from explicit call-outs for the four forgery strategies and the three evaluation dimensions (detection, reasoning, localization) to improve immediate readability.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed review, which has helped us identify areas to strengthen the manuscript. We address each major comment point by point below, with clear indications of planned revisions. Our responses focus on substance and aim to enhance the clarity and robustness of the benchmark without overstating its scope.
read point-by-point responses
-
Referee: [§3] §3 (Benchmark Construction): The central claim that low performances (e.g., GPT-5.1 at 48.80%, expert IoU 30.09%) expose 'fundamental limitations' and that 'forensics lag behind generative advances' rests on the assumption that the 39 subtypes and four simulated forgery strategies match the distribution of real AI-generated academic images. The manuscript constructs these via simulation with 25 generative models but reports no external validation (statistical comparison of artifacts, expert realism ratings, or direct comparison against disclosed real AI figures from arXiv or journals). This is load-bearing for the 'diagnostic testbed' assertion.
Authors: We appreciate the referee's emphasis on this foundational assumption. The 39 subtypes and four forgery strategies were derived from a systematic review of documented academic image manipulation cases in the literature (e.g., figure duplication, data fabrication, and AI-assisted enhancement in scholarly publishing). While we acknowledge that exhaustive external validation against undisclosed real-world AI-generated figures is not feasible—due to the absence of large-scale, labeled public datasets of such forgeries—we will add a dedicated subsection in §3 detailing the derivation process, including specific citations to real-world examples and the rationale for each strategy. This will better substantiate the representativeness claim while preserving the diagnostic value demonstrated by the consistently low forensic performance across diverse models. We view this as a partial revision that clarifies rather than alters the core methodology. revision: partial
-
Referee: [§4] §4 (Evaluation Protocol): Performance numbers are presented as point estimates (e.g., 48.80% overall, 84.74% textual artifact recognition) without reported confidence intervals, per-category variance, or statistical tests for differences between MLLM and expert families. Given the claim of 'complementary strengths' and the use of held-out test images, absence of these measures makes it difficult to judge whether observed gaps are robust or sensitive to image selection.
Authors: We agree that the absence of statistical measures limits the interpretability of the reported gaps. In the revised version, we will augment §4 with 95% bootstrap confidence intervals for all aggregate and per-task metrics (computed over the held-out test set), per-category performance variance, and statistical significance tests (e.g., McNemar's test for binary detection comparisons and paired Wilcoxon tests for localization IoU between MLLM and expert families). These will be added to the main results tables and discussion of complementary strengths. This revision directly addresses the concern and strengthens the empirical claims. revision: yes
-
Referee: [§2, §5] §2 and §5 (Related Work and Discussion): The selection of the 25 generative models and the four forgery strategies is described at a high level, but the paper does not detail inclusion criteria or whether the set covers recent techniques (e.g., latest diffusion or autoregressive models). This affects the strength of the conclusion that 11 models yield <50% forensic accuracy and that forensics are lagging.
Authors: We will expand the relevant sections in §2 (Related Work) and §5 (Discussion) to explicitly state the inclusion criteria: models were chosen for architectural diversity (GAN, diffusion, and autoregressive families), recency (covering developments through early 2024), community adoption, and demonstrated capability in generating academic-style visuals. We will also add a paragraph acknowledging the rapid evolution of generative techniques and noting that while the set captures major paradigms, it cannot include every post-construction model. This clarification will reinforce the conclusion regarding the 11 models below 50% accuracy without overstating coverage. revision: yes
Circularity Check
No significant circularity in benchmark construction or evaluation
full rationale
This is an empirical benchmark paper with no mathematical derivations, fitted parameters, or equations. The central claims rest on direct performance measurements (e.g., GPT-5.1 at 48.80% overall accuracy, expert IoU at 30.09%) obtained by running models on a held-out test set constructed from 7 categories, 39 subtypes, and 4 simulated forgery strategies across 25 generators. These metrics are independent observations against the benchmark images rather than quantities defined in terms of the benchmark itself. No self-citation chain, ansatz smuggling, uniqueness theorem, or renaming of known results is load-bearing for the diagnostic-testbed claim. The representativeness of the chosen subtypes is an external validity assumption, not a circular reduction of the reported results to the inputs by construction. The derivation chain is therefore self-contained.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The chosen seven academic categories and 39 subtypes adequately represent the intrinsic forensic difficulty of real academic images.
- domain assumption The four simulated forgery strategies and 25 generative models produce fakes that match the distribution of actual academic image manipulations.
Reference graph
Works this paper leans on
-
[1]
On the detection of synthetic images generated by diffusion models. InICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1–5. IEEE. Google DeepMind. 2025a. Gemini 2.5 flash and pro are now generally available, and we’re introducing 2.5 flash-lite, our most cost-efficient and fastest 2.5 model yet. htt...
-
[2]
Llava-next: Improved reasoning, ocr, and world knowledge. https://llava-vl.github.io/ blog/2024-01-30-llava-next/ . Accessed: 2025- 04-05. Andreas Lugmayr, Martin Danelljan, Andres Romero, Fisher Yu, Radu Timofte, and Luc Van Gool. 2022. Repaint: Inpainting using denoising diffusion prob- abilistic models. InProceedings of the IEEE/CVF Conference on Compu...
work page internal anchor Pith review arXiv 2024
-
[3]
Lower FID scores indi- cate higher visual fidelity and closer alignment with real-image statistics
evaluates the distributional similarity be- tween generated images and real academic im- ages by computing the Fréchet distance between their feature embeddings extracted from a pre- trained Inception model. Lower FID scores indi- cate higher visual fidelity and closer alignment with real-image statistics. • CLIP Score.CLIP Score (Hessel et al., 2021) mea...
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.