Recognition: unknown
CRC-Screen: Certified DNA-Synthesis Hazard Screening Under Taxonomic Shift
Pith reviewed 2026-05-09 20:25 UTC · model grok-4.3
The pith
Fusing three public signals and calibrating the threshold with conformal methods certifies an expected false-negative rate bound for DNA-synthesis hazard screening that holds under taxonomic shifts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
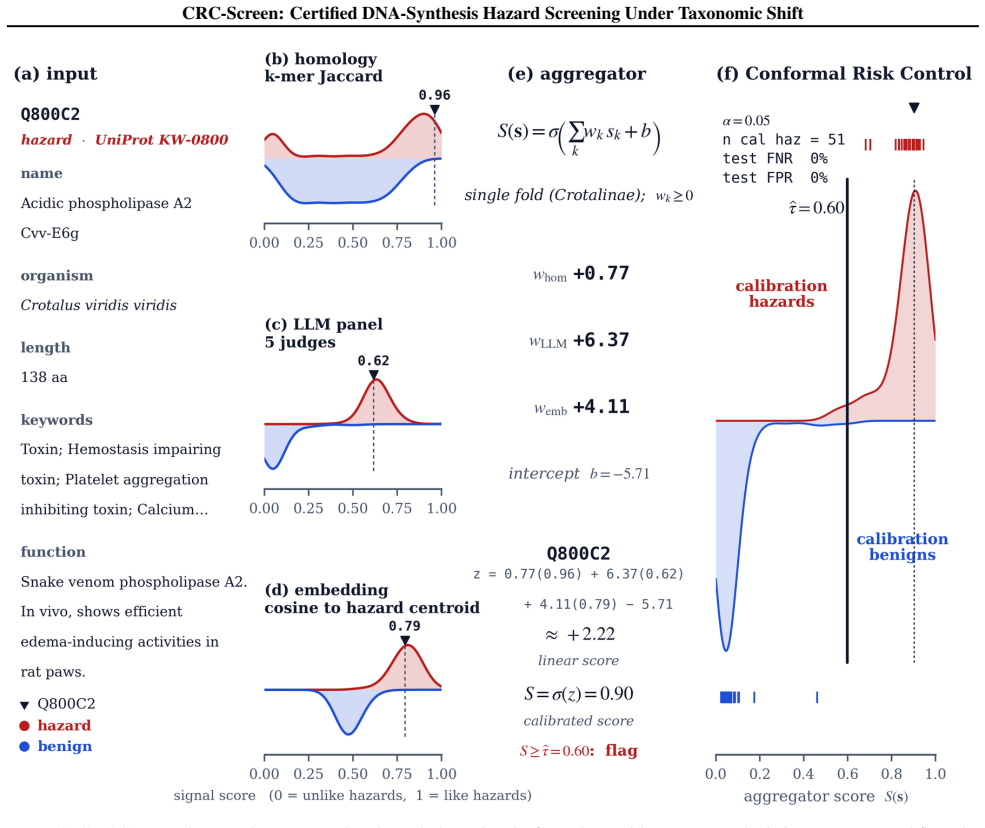
By combining k-mer Jaccard similarity to known toxins, the trimmed-mean score of a five-LLM judge panel, and cosine similarity to clustered embedding centroids inside a monotone logistic aggregator and then calibrating the resulting score with Conformal Risk Control on leave-one-taxonomic-family-out folds drawn from UniProt KW-0800 reviewed toxins, the screener certifies E[FNR] ≤ α while attaining 0 percent test miss rate on every fold and 0 percent test false-flag rate on nine of ten folds at α = 0.05.
What carries the argument
A monotone logistic aggregator of three annotation-derived signals whose threshold is set by Conformal Risk Control to enforce an upper bound on expected false-negative rate under distribution shift.
If this is right
- The size of the calibration set, not the design of the signals, is the binding constraint on how low a certifiable miss rate can be achieved.
- The full reviewed UniProt KW-0800 corpus already supplies enough data to reach procurement-grade α = 0.001.
- The same certified bound can be maintained on future orders whose hazards come from families outside the current calibration folds.
- The finite-sample slack of 1/(n_cal + 1) limits the smallest certifiable miss rate to 1.77 percent on the 200-hazard subsample used in the experiments.
Where Pith is reading between the lines
- Expanding the calibration set with additional reviewed toxins would directly tighten the certified risk bound without requiring new signal engineering.
- DNA-synthesis providers could adopt the calibrated rule to reduce both missed hazards and unnecessary blocks on safe orders from novel organisms.
- The same three-signal plus conformal-calibration pattern may apply to other sequence-based screening tasks that face distributional shifts.
Load-bearing premise
The three chosen signals remain sufficiently informative when the hazardous sequence comes from a taxonomic family that was never seen during calibration.
What would settle it
A new family of toxins in which every one of the three signals produces scores that overlap completely with the distribution of benign sequences would cause the calibrated threshold to miss hazards at a rate exceeding the certified bound.
Figures


read the original abstract
DNA-synthesis providers screen incoming orders by searching the requested sequence against curated hazard lists. We show that this baseline collapses to a 100% false-flag rate when the hazardous sequence comes from a taxonomic family absent from the reference set: under Conformal Risk Control's certified miss-rate constraint, a low-discrimination signal forces the threshold below the entire test-benign mass. We compose three signals derived from a synthesis order's public annotation: $k$-mer Jaccard similarity to known toxins, the trimmed-mean score of a five-LLM judge panel, and cosine similarity to clustered embedding centroids. Fused under a monotone logistic aggregator and calibrated by Conformal Risk Control, the resulting screener certifies $\mathbb{E}[\mathrm{FNR}] \le \alpha$. Across ten leave-one-taxonomic-family-out folds at $\alpha=0.05$ on UniProt KW-0800 reviewed toxins, the calibrated screener achieves 0% test miss rate on every fold and 0% test false-flag rate on nine of ten folds. The bound's finite-sample slack $1/(n_{\mathrm{cal}}+1)$ caps the certifiable miss rate at 1.77% on our 200-hazard subsample; reaching procurement-grade $\alpha=10^{-3}$ requires an $18\times$ larger calibration set, which the full reviewed UniProt KW-0800 corpus is large enough to deliver. The binding constraint on certifiable DNA-synthesis screening is calibration data, not algorithms. Code: https://github.com/najmulhasan-code/crc-screen
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents CRC-Screen, a hazard screener for DNA synthesis orders that fuses three signals (k-mer Jaccard similarity to known toxins, trimmed-mean score from a five-LLM judge panel, and cosine similarity to embedding centroids) via a monotone logistic aggregator. It applies Conformal Risk Control (CRC) to certify E[FNR] ≤ α under taxonomic shift, reporting 0% test miss rate on all ten leave-one-taxonomic-family-out folds and 0% false-flag rate on nine of ten folds at α=0.05 using a 200-hazard UniProt KW-0800 subsample. The work emphasizes that calibration-set size, not algorithmic sophistication, is the binding constraint for procurement-grade α.
Significance. If the CRC certification extends beyond the support of the calibration families, the approach would supply a finite-sample, distribution-free bound on miss rate that directly mitigates the 100% false-flag collapse of list-based screening under taxonomic shift. The LOO design, open code, and explicit discussion of the 1/(n_cal+1) slack and required calibration size (18× larger for α=10^{-3}) are concrete strengths that make the empirical results reproducible and the calibration-data insight actionable.
major comments (2)
- [Abstract] Abstract and the CRC application section: the central claim that the screener 'certifies E[FNR] ≤ α' under taxonomic shift is load-bearing, yet CRC supplies this bound only under exchangeability between calibration and test points. The ten leave-one-family-out folds test shifts among families already present in the reviewed UniProt KW-0800 subsample; for a family entirely absent from the corpus the three signals can become arbitrarily weak (low Jaccard, uninformative LLM scores, off-centroid embeddings), rendering the logistic aggregator non-discriminative and allowing realized FNR to exceed the certified bound. The reported 0% miss rates are therefore empirical within-support results and do not extend the finite-sample guarantee to out-of-support taxonomic shifts.
- [Methods (CRC calibration subsection)] The construction of the calibration set and the precise definition of the risk function (FNR) used inside the CRC procedure are not fully specified in the abstract and must be verified in the methods; without them it is impossible to confirm that the monotone logistic aggregator preserves the monotonicity and boundedness properties required for the CRC guarantee to hold.
minor comments (2)
- [Abstract] The abstract states 'trimmed-mean score of a five-LLM judge panel' without naming the models or the trimming rule; these details are needed for reproducibility even if they appear later in the text.
- [Results] Figure or table reporting per-fold false-flag rates should include the exact calibration-set size used in each LOO fold so readers can directly relate the observed slack to the theoretical 1/(n_cal+1) term.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. The comments highlight important nuances in the scope of the CRC guarantee and the need for explicit documentation of the calibration procedure. We address each point below and will incorporate clarifications in the revised manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract and the CRC application section: the central claim that the screener 'certifies E[FNR] ≤ α' under taxonomic shift is load-bearing, yet CRC supplies this bound only under exchangeability between calibration and test points. The ten leave-one-family-out folds test shifts among families already present in the reviewed UniProt KW-0800 subsample; for a family entirely absent from the corpus the three signals can become arbitrarily weak (low Jaccard, uninformative LLM scores, off-centroid embeddings), rendering the logistic aggregator non-discriminative and allowing realized FNR to exceed the certified bound. The reported 0% miss rates are therefore empirical within-support results and do not extend the finite-sample guarantee to out-of-support taxonomic shifts.
Authors: We agree that the finite-sample guarantee provided by Conformal Risk Control requires exchangeability between calibration and test points. The leave-one-family-out folds evaluate performance under taxonomic shifts among families that are represented in the overall UniProt KW-0800 subsample. For a taxonomic family entirely absent from this corpus, the three signals can indeed weaken substantially, and the certified bound on E[FNR] would not necessarily hold. We will revise the abstract, the CRC application section, and the discussion to explicitly delimit the claim to taxonomic shifts within the support of the calibration families, while noting the limitation for out-of-support families. This change preserves the paper's core contribution regarding calibration data as the binding constraint for within-support screening. revision: yes
-
Referee: [Methods (CRC calibration subsection)] The construction of the calibration set and the precise definition of the risk function (FNR) used inside the CRC procedure are not fully specified in the abstract and must be verified in the methods; without them it is impossible to confirm that the monotone logistic aggregator preserves the monotonicity and boundedness properties required for the CRC guarantee to hold.
Authors: The methods section constructs the calibration set for each fold as the 200-hazard subsample excluding the left-out family and defines the risk function as the indicator of false negative (hazard not flagged). The logistic aggregator is monotone non-decreasing in each of its three inputs by construction. To eliminate any ambiguity, we will expand the CRC calibration subsection with an explicit paragraph stating the calibration-set construction, the mathematical definition of the risk function, and a short verification that the aggregator satisfies the monotonicity and boundedness conditions required by the CRC framework. revision: yes
Circularity Check
No circularity: CRC certification and held-out empirical results are independent of inputs
full rationale
The paper composes three external signals (k-mer Jaccard, LLM panel scores, embedding cosine), fuses them via a monotone logistic aggregator, and applies standard Conformal Risk Control to produce a finite-sample bound on E[FNR]. The reported 0% miss/false-flag rates are direct observations on ten leave-one-taxonomic-family-out held-out folds, not predictions derived from the same data by construction. No self-definitional equations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the derivation chain; the CRC guarantee is invoked as an external theorem and the empirical folds are statistically separate from calibration. The derivation is therefore self-contained against the paper's own inputs.
Axiom & Free-Parameter Ledger
free parameters (1)
- logistic aggregator coefficients
axioms (1)
- domain assumption Exchangeability between calibration and test samples
Reference graph
Works this paper leans on
-
[1]
The Twelfth International Conference on Learning Representations (
Conformal Risk Control , author =. The Twelfth International Conference on Learning Representations (. 2024 , url =
2024
-
[2]
The Annals of Statistics , volume =
Conformal prediction beyond exchangeability , author =. The Annals of Statistics , volume =. 2023 , doi =
2023
-
[3]
2022 , isbn =
Algorithmic Learning in a Random World , author =. 2022 , isbn =
2022
-
[4]
Journal of Molecular Biology , volume =
Basic Local Alignment Search Tool , author =. Journal of Molecular Biology , volume =. 1990 , doi =
1990
-
[5]
Sensitive protein alignments at tree-of-life scale using
Buchfink, Benjamin and Reuter, Klaus and Drost, Hajk-Georg , journal =. Sensitive protein alignments at tree-of-life scale using. 2021 , doi =
2021
-
[6]
and Zhang, Hao and Gonzalez, Joseph E
Zheng, Lianmin and Chiang, Wei-Lin and Sheng, Ying and Zhuang, Siyuan and Wu, Zhanghao and Zhuang, Yonghao and Lin, Zi and Li, Zhuohan and Li, Dacheng and Xing, Eric P. and Zhang, Hao and Gonzalez, Joseph E. and Stoica, Ion , booktitle =. Judging. 2023 , url =
2023
-
[7]
2025 , doi =
Nucleic Acids Research , volume =. 2025 , doi =
2025
-
[8]
Scikit-learn: Machine Learning in
Pedregosa, Fabian and Varoquaux, Ga. Scikit-learn: Machine Learning in. Journal of Machine Learning Research , volume =. 2011 , url =
2011
-
[9]
Increased cyber-biosecurity for
Puzis, Rami and Farbiash, Dor and Brodt, Oleg and Elovici, Yuval and Greenbaum, Dov , journal =. Increased cyber-biosecurity for. 2020 , doi =
2020
-
[10]
Journal of the ACM , volume =
Bates, Stephen and Angelopoulos, Anastasios and Lei, Lihua and Malik, Jitendra and Jordan, Michael , title =. Journal of the ACM , volume =. 2021 , publisher =
2021
-
[11]
and Wasserman, Larry , title =
Lei, Jing and G'Sell, Max and Rinaldo, Alessandro and Tibshirani, Ryan J. and Wasserman, Larry , title =. Journal of the American Statistical Association , volume =. 2018 , doi =
2018
-
[12]
and Foygel Barber, Rina and Cand
Tibshirani, Ryan J. and Foygel Barber, Rina and Cand. Conformal Prediction Under Covariate Shift , booktitle =
-
[13]
Conformalized Quantile Regression , booktitle =
Romano, Yaniv and Patterson, Evan and Cand. Conformalized Quantile Regression , booktitle =
-
[14]
Journal of the American Statistical Association , volume =
Sadinle, Mauricio and Lei, Jing and Wasserman, Larry , title =. Journal of the American Statistical Association , volume =. 2019 , doi =
2019
-
[15]
, title =
Cauchois, Maxime and Gupta, Suyash and Duchi, John C. , title =. Journal of Machine Learning Research , volume =
-
[16]
and Bates, Stephen , title =
Angelopoulos, Anastasios N. and Bates, Stephen , title =. Foundations and Trends in Machine Learning , volume =. 2023 , doi =
2023
-
[17]
and Madden, Thomas L
Altschul, Stephen F. and Madden, Thomas L. and Sch. Gapped. Nucleic Acids Research , volume =. 1997 , doi =
1997
-
[18]
Nature Biotechnology , volume =
Steinegger, Martin and S. Nature Biotechnology , volume =. 2017 , doi =
2017
-
[19]
, title =
Edgar, Robert C. , title =. Bioinformatics , volume =. 2010 , doi =
2010
-
[20]
, title =
Eddy, Sean R. , title =. PLOS Computational Biology , volume =. 2011 , doi =
2011
-
[21]
and Sonnhammer, Erik L
Mistry, Jaina and Chuguransky, Sara and Williams, Lowri and Qureshi, Matloob and Salazar, Gustavo A. and Sonnhammer, Erik L. L. and Tosatto, Silvio C. E. and Paladin, Lisanna and Raj, Shriya and Richardson, Lorna J. and Finn, Robert D. and Bateman, Alex , title =. Nucleic Acids Research , volume =. 2021 , doi =
2021
-
[22]
and Wang, Yuqi and Huang, Hongzhan and McGarvey, Peter B
Suzek, Baris E. and Wang, Yuqi and Huang, Hongzhan and McGarvey, Peter B. and Wu, Cathy H. and. Bioinformatics , volume =. 2015 , doi =
2015
-
[23]
, title =
Camacho, Christiam and Coulouris, George and Avagyan, Vahram and Ma, Ning and Papadopoulos, Jason and Bealer, Kevin and Madden, Thomas L. , title =. BMC Bioinformatics , volume =. 2009 , doi =
2009
-
[24]
Lawrence and Ma, Jerry and Fergus, Rob , title =
Rives, Alexander and Meier, Joshua and Sercu, Tom and Goyal, Siddharth and Lin, Zeming and Liu, Jason and Guo, Demi and Ott, Myle and Zitnick, C. Lawrence and Ma, Jerry and Fergus, Rob , title =. Proceedings of the National Academy of Sciences , volume =. 2021 , doi =
2021
-
[25]
Science , volume =
Lin, Zeming and Akin, Halil and Rao, Roshan and Hie, Brian and Zhu, Zhongkai and Lu, Wenting and Smetanin, Nikita and Verkuil, Robert and Kabeli, Ori and Shmueli, Yaniv and dos Santos Costa, Allan and Fazel-Zarandi, Maryam and Sercu, Tom and Candido, Salvatore and Rives, Alexander , title =. Science , volume =. 2023 , doi =
2023
-
[26]
IEEE Transactions on Pattern Analysis and Machine Intelligence , volume =
Elnaggar, Ahmed and Heinzinger, Michael and Dallago, Christian and Rehawi, Ghalia and Wang, Yu and Jones, Llion and Gibbs, Tom and Feher, Tamas and Angerer, Christoph and Steinegger, Martin and Bhowmik, Debsindhu and Rost, Burkhard , title =. IEEE Transactions on Pattern Analysis and Machine Intelligence , volume =. 2022 , doi =
2022
-
[27]
and Subramanian, Subu and Mohr, Benjamin P
Madani, Ali and Krause, Ben and Greene, Eric R. and Subramanian, Subu and Mohr, Benjamin P. and Holton, James M. and Olmos, Jose Luis and Xiong, Caiming and Sun, Zachary Z. and Socher, Richard and Fraser, James S. and Naik, Nikhil , title =. Nature Biotechnology , volume =. 2023 , doi =
2023
-
[28]
Frontiers in Bioengineering and Biotechnology , volume =
Diggans, James and Leproust, Emily , title =. Frontiers in Bioengineering and Biotechnology , volume =. 2019 , doi =
2019
-
[29]
and Lucas, Caleb and Guest, Ella , title =
Mouton, Christopher A. and Lucas, Caleb and Guest, Ella , title =. 2024 , url =
2024
-
[30]
and Friedman, Robert M
Carter, Sarah R. and Friedman, Robert M. , title =. 2015 , url =
2015
-
[31]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP) , pages =
Liu, Yang and Iter, Dan and Xu, Yichong and Wang, Shuohang and Xu, Ruochen and Zhu, Chenguang , title =. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP) , pages =. 2023 , doi =
2023
-
[32]
, title =
Dubois, Yann and Li, Xuechen and Taori, Rohan and Zhang, Tianyi and Gulrajani, Ishaan and Ba, Jimmy and Guestrin, Carlos and Liang, Percy and Hashimoto, Tatsunori B. , title =. Advances in Neural Information Processing Systems 36 (NeurIPS 2023) , year =
2023
-
[33]
, title =
Guo, Chuan and Pleiss, Geoff and Sun, Yu and Weinberger, Kilian Q. , title =. Proceedings of the 34th International Conference on Machine Learning (ICML) , series =
-
[34]
Advances in Neural Information Processing Systems 30 (NIPS 2017) , year =
Geifman, Yonatan and El-Yaniv, Ran , title =. Advances in Neural Information Processing Systems 30 (NIPS 2017) , year =
2017
-
[35]
, title =
Platt, John C. , title =. Advances in Large Margin Classifiers , editor =
-
[36]
Reimers, Nils and Gurevych, Iryna , title =. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP) , pages =. 2019 , doi =
2019
-
[37]
Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP) , pages =
Karpukhin, Vladimir and Oguz, Barlas and Min, Sewon and Lewis, Patrick and Wu, Ledell and Edunov, Sergey and Chen, Danqi and Yih, Wen-tau , title =. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP) , pages =. 2020 , doi =
2020
-
[38]
Devlin, Jacob and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina , title =. Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers) , pages =. 2019 , doi =
2019
-
[39]
, title =
Dietterich, Thomas G. , title =. Multiple Classifier Systems , series =. 2000 , doi =
2000
-
[40]
Proceedings of the Twenty-First International Conference on Machine Learning (ICML) , year =
Caruana, Rich and Niculescu-Mizil, Alexandru and Crew, Geoff and Ksikes, Alex , title =. Proceedings of the Twenty-First International Conference on Machine Learning (ICML) , year =
-
[41]
, title =
Stone, M. , title =. Journal of the Royal Statistical Society: Series B (Methodological) , volume =. 1974 , doi =
1974
-
[42]
Toxicon , volume =
Jungo, Florence and Bairoch, Amos , title =. Toxicon , volume =. 2005 , doi =
2005
-
[43]
Nucleic Acids Research , volume =
Kaas, Quentin and Yu, Rilei and Jin, Ai-Hua and Dutertre, S. Nucleic Acids Research , volume =. 2012 , doi =
2012
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.