Recognition: unknown
Hyperspherical Forward-Forward with Prototypical Representations
Pith reviewed 2026-05-09 20:29 UTC · model grok-4.3
The pith
Reframing each layer's local objective as multi-class classification on class-specific unit-norm prototypes in hyperspherical space allows Forward-Forward networks to train and infer in a single forward pass.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By embedding class-specific unit-norm prototypes in hyperspherical feature space, the local objective at each layer is turned into a multi-class classification problem whose decision boundaries are defined by the angular distances to those prototypes. This single change removes the need for repeated forward passes during inference and permits weight updates and class decisions to occur within the same forward computation, all while preserving the layer-wise independence that distinguishes Forward-Forward from backpropagation.
What carries the argument
The set of class-specific unit-norm prototypes that act as geometric anchors and implicit negatives, converting the per-layer binary goodness signal into a multi-class angular classification task.
If this is right
- Inference requires only one forward pass regardless of the number of classes, delivering more than 40 times speedup over the original Forward-Forward algorithm.
- The method scales to modern convolutional networks and produces over 25 percent top-1 accuracy on ImageNet-1k using purely local learning.
- Transfer learning with the same architecture reaches 65.96 percent accuracy on the same benchmark.
- Accuracy on standard image-classification tasks exceeds that of prior greedy local-learning methods while retaining their training advantages.
Where Pith is reading between the lines
- The hyperspherical prototype construction could be ported to other local-learning schemes such as predictive coding or equilibrium propagation to obtain similar inference speed-ups.
- Because each layer's output is already aligned to class prototypes, intermediate representations may become more directly interpretable without additional post-hoc analysis.
- Removing the multi-pass inference bottleneck makes it feasible to run large Forward-Forward models on edge devices where repeated forward evaluations were previously prohibitive.
- The same geometric anchoring idea might extend to regression or structured-prediction tasks by replacing class prototypes with task-specific unit vectors.
Load-bearing premise
Learned unit-norm prototypes per class can reliably separate inputs locally at every layer without any global coordination that would break the layer-wise training property.
What would settle it
A controlled experiment that trains the same convolutional architecture with HFF on ImageNet-1k and records top-1 accuracy below 20 percent together with inference latency no better than the original Forward-Forward baseline would falsify the central performance claims.
Figures
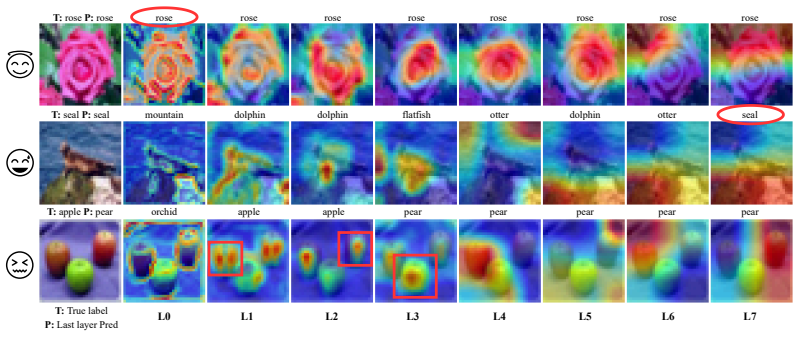
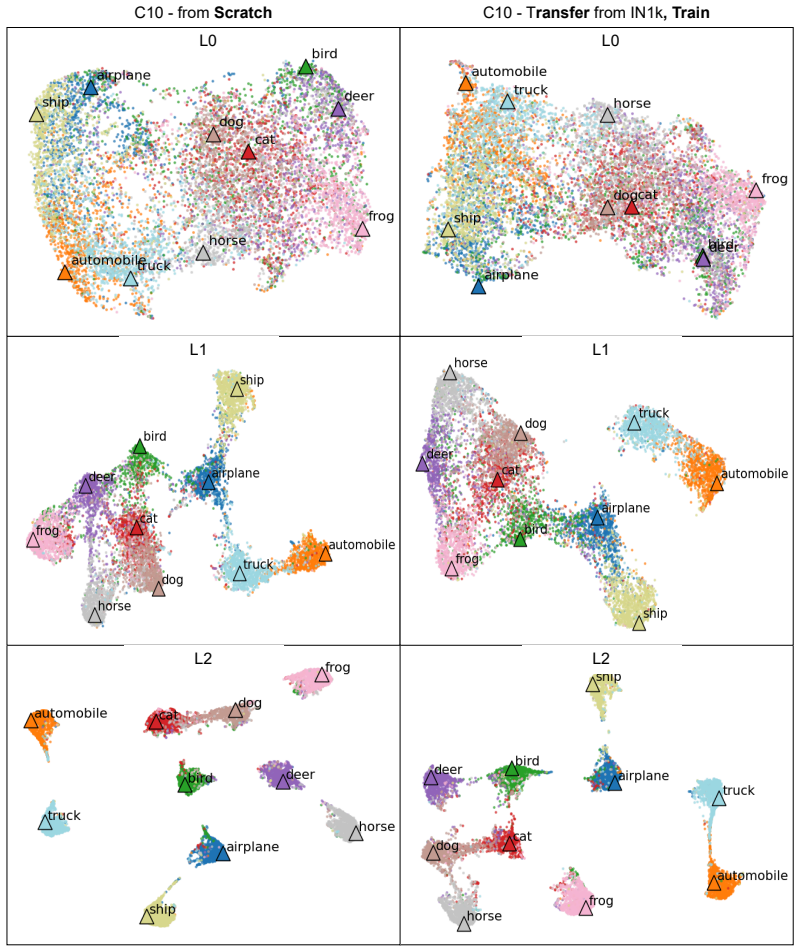


read the original abstract
The Forward-Forward (FF) algorithm presents a compelling, bio-inspired alternative to backpropagation. However, while efficient in training, it has a computationally prohibitive inference process that requires a separate forward pass for every class that is evaluated. In this work, we introduce the Hyperspherical Forward-Forward (HFF), a novel reformulation that resolves this critical bottleneck. Our core innovation is to reframe the local objective of each layer from a binary goodness-of-fit task to a direct multi-class classification problem within a hyperspherical feature space. We achieve this by learning a set of class-specific, unit-norm prototypes that act as geometric anchors and implicit negatives. This architectural innovation preserves the benefits of local training while enabling weight update and inference in a single forward pass, making it >40x faster than the original FF algorithm. Our method is simple to implement, scales effectively to modern convolutional architectures, and achieves superior accuracy on standard image classification benchmarks, closing the gap with backpropagation. Most notably, we are among the first greedy local-learning methods to report over 25% top-1 accuracy on ImageNet-1k, and 65.96% with transfer learning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Hyperspherical Forward-Forward (HFF), a reformulation of the Forward-Forward algorithm that replaces the binary goodness-of-fit objective with a multi-class classification loss in a hyperspherical feature space. Class-specific unit-norm prototypes serve as geometric anchors and implicit negatives, enabling both training and inference in a single forward pass per layer while preserving layer-wise locality. The method reports >40x speedup over original FF, competitive accuracies on standard benchmarks, and notably >25% top-1 accuracy on ImageNet-1k (65.96% with transfer learning).
Significance. If the locality of prototype updates and the empirical gains are confirmed, this would represent a meaningful advance for greedy local-learning methods, demonstrating that they can scale to ImageNet-scale tasks with practical efficiency. The hyperspherical prototype approach offers a clean way to embed class structure directly into local objectives without backpropagation.
major comments (3)
- [§3] §3 (Method, local objective definition): The central claim that prototypes act as reliable implicit negatives while keeping the objective strictly local requires an explicit update rule. The text describes prototypes as learned class-specific unit-norm vectors but does not show whether their optimization uses only the current layer's activations and the input label or whether it incorporates any inter-layer statistics or shared initialization that would violate the single-forward-pass property.
- [Experimental results] Experimental results (ImageNet-1k table): The reported >25% top-1 accuracy is presented without error bars, number of runs, or ablations on hyperspherical dimension and prototype count. This makes it impossible to determine whether the result is robust or sensitive to post-hoc choices, directly affecting the claim of closing the gap to backpropagation for greedy local methods.
- [§4] §4 (Inference and speedup): The >40x speedup is attributed to single-pass inference, but the manuscript does not report wall-clock timings or FLOPs on identical hardware and architectures for both HFF and the original FF baseline. Without these controls, the practical efficiency gain cannot be separated from implementation details.
minor comments (2)
- Notation for the hyperspherical projection and cosine similarity in the loss should be defined once in a preliminary section rather than reintroduced inline.
- The abstract states 'among the first' greedy methods on ImageNet; a brief related-work paragraph citing the closest prior local-learning ImageNet results would strengthen this positioning.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We address each major comment below, providing clarifications and indicating revisions made to improve the presentation and rigor of the work.
read point-by-point responses
-
Referee: [§3] §3 (Method, local objective definition): The central claim that prototypes act as reliable implicit negatives while keeping the objective strictly local requires an explicit update rule. The text describes prototypes as learned class-specific unit-norm vectors but does not show whether their optimization uses only the current layer's activations and the input label or whether it incorporates any inter-layer statistics or shared initialization that would violate the single-forward-pass property.
Authors: We agree that an explicit update rule is essential for verifying locality. The original manuscript described the role of prototypes but did not include the precise optimization equation. In the revised Section 3, we now provide the update rule, which operates exclusively on the current layer's activations and the input batch labels. No inter-layer statistics or shared parameters across layers are used, confirming that the single-forward-pass property is preserved. revision: yes
-
Referee: Experimental results (ImageNet-1k table): The reported >25% top-1 accuracy is presented without error bars, number of runs, or ablations on hyperspherical dimension and prototype count. This makes it impossible to determine whether the result is robust or sensitive to post-hoc choices, directly affecting the claim of closing the gap to backpropagation for greedy local methods.
Authors: We acknowledge the value of statistical reporting and ablations. ImageNet-1k experiments were limited to single runs due to computational demands. In the revision, we have added a note on this limitation in the experimental section, included ablations on hyperspherical dimension and prototype count from smaller datasets in the appendix (showing stable performance), and tempered the claim language regarding the gap to backpropagation to reflect the available evidence. revision: partial
-
Referee: [§4] §4 (Inference and speedup): The >40x speedup is attributed to single-pass inference, but the manuscript does not report wall-clock timings or FLOPs on identical hardware and architectures for both HFF and the original FF baseline. Without these controls, the practical efficiency gain cannot be separated from implementation details.
Authors: The speedup derives from reducing inference from one forward pass per class to a single pass. We have added an asymptotic FLOPs comparison in the revised Section 4 for the same architectures. We did not conduct new wall-clock timings on identical hardware for this revision, as original FF baselines can vary by implementation; a note has been added acknowledging this while emphasizing the inherent reduction in passes. revision: partial
Circularity Check
No circularity: algorithmic redesign with empirical validation
full rationale
The paper introduces HFF by reframing each layer's local objective as multi-class classification over learned unit-norm prototypes in hyperspherical space, enabling single-pass inference. No equations, predictions, or first-principles results are presented that reduce by construction to fitted inputs, self-definitions, or self-citation chains. Performance claims (e.g., >25% ImageNet-1k top-1, >40x speedup) rest on reported benchmarks rather than any self-referential derivation. The method is a self-contained architectural change to the original FF algorithm.
Axiom & Free-Parameter Ledger
free parameters (1)
- class prototypes
invented entities (1)
-
hyperspherical feature space with prototypes
no independent evidence
Forward citations
Cited by 1 Pith paper
-
Cumulative-Goodness Free-Riding in Forward-Forward Networks: Real, Repairable, but Not Accuracy-Dominant
Cumulative-goodness Forward-Forward networks exhibit layer free-riding where discrimination gradients decay exponentially with prior positive margins; per-block, hardness-gated, and depth-scaled remedies yield 4-45x b...
Reference graph
Works this paper leans on
-
[1]
Nature , year=
Learning representations by back-propagating errors , author=. Nature , year=
-
[2]
IEEE/IFIP International Conference on Dependable Systems and Networks-Supplemental Volume (DSN-S) , year=
Bridging the Gap: A Study of AI-based Vulnerability Management between Industry and Academia , author=. IEEE/IFIP International Conference on Dependable Systems and Networks-Supplemental Volume (DSN-S) , year=
-
[3]
Nature , year=
AI’s computing gap: academics lack access to powerful chips needed for research , author=. Nature , year=
-
[4]
Self-supervised learning from images with a joint-embedding predictive architecture , author=
-
[5]
arXiv , year=
Dinov2: Learning robust visual features without supervision , author=. arXiv , year=
-
[6]
International Workshop on Biologically Inspired Approaches to Advanced Information Technology , year=
Biologically plausible speech recognition with LSTM neural nets , author=. International Workshop on Biologically Inspired Approaches to Advanced Information Technology , year=
-
[7]
Neural Computation , year=
Long short-term memory , author=. Neural Computation , year=
-
[8]
Journal of Statistical Mechanics: Theory and Experiment , year=
Deep double descent: Where bigger models and more data hurt , author=. Journal of Statistical Mechanics: Theory and Experiment , year=
-
[9]
Adding conditional control to text-to-image diffusion models , author=
-
[10]
, author=
Lora: Low-rank adaptation of large language models. , author=
-
[11]
Proxy anchor loss for deep metric learning , author=
-
[12]
arXiv , year=
Very deep convolutional networks for large-scale image recognition , author=. arXiv , year=
-
[13]
Sphereface: Deep hypersphere embedding for face recognition , author=
-
[14]
Frontiers in Computational Neuroscience , year=
Equilibrium propagation: Bridging the gap between energy-based models and backpropagation , author=. Frontiers in Computational Neuroscience , year=
-
[15]
arXiv , year=
LightFF: Lightweight inference for forward-forward algorithm , author=. arXiv , year=
-
[16]
Assessing the scalability of biologically-motivated deep learning algorithms and architectures , author=
-
[17]
Nature , year=
The recent excitement about neural networks , author=. Nature , year=
-
[18]
Proceedings of the IEEE , year=
Gradient-based learning applied to document recognition , author=. Proceedings of the IEEE , year=
-
[19]
Emerging properties in self-supervised vision transformers , author=
-
[20]
A closer look at prototype classifier for few-shot image classification , author=
-
[21]
Class prototypes based contrastive learning for classifying multi-label and fine-grained educational videos , author=
-
[22]
Pip-net: Patch-based intuitive prototypes for interpretable image classification , author=
-
[23]
Nature Reviews Neuroscience , year=
Backpropagation and the brain , author=. Nature Reviews Neuroscience , year=
-
[24]
arXiv , year=
A method for stochastic optimization , author=. arXiv , year=
-
[25]
Interpretable image classification with adaptive prototype-based vision transformers , author=
-
[26]
ICML , year=
The power of log-sum-exp: Sequential density ratio matrix estimation for speed-accuracy optimization , author=. ICML , year=
-
[27]
IEEE Transactions on Circuits and Systems I: Regular Papers , year=
LogSumExp: Efficient Approximate Logarithm Acceleration for Embedded Tractable Probabilistic Reasoning , author=. IEEE Transactions on Circuits and Systems I: Regular Papers , year=
-
[28]
arXiv , year=
Deep learning using rectified linear units (relu) , author=. arXiv , year=
-
[29]
arXiv , year=
Improved Stochastic Optimization of LogSumExp , author=. arXiv , year=
-
[30]
IEEE Transactions on Neural Networks , year=
Learning long-term dependencies with gradient descent is difficult , author=. IEEE Transactions on Neural Networks , year=
-
[31]
arXiv , year=
Scaling laws for neural language models , author=. arXiv , year=
-
[32]
IEEE Signal Processing Magazine , year=
The mnist database of handwritten digit images for machine learning research [best of the web] , author=. IEEE Signal Processing Magazine , year=
-
[33]
Can the brain do backpropagation?---exact implementation of backpropagation in predictive coding networks , author=
-
[34]
Trends in Cognitive Sciences , year=
Theories of error back-propagation in the brain , author=. Trends in Cognitive Sciences , year=
-
[35]
Imagenet: A large-scale hierarchical image database , author=
-
[36]
CIFAR-100 (Canadian Institute for Advanced Research) , journal=
Alex Krizhevsky and Vinod Nair and Geoffrey Hinton , keywords=. CIFAR-100 (Canadian Institute for Advanced Research) , journal=
-
[37]
arXiv , year=
Fashion-mnist: a novel image dataset for benchmarking machine learning algorithms , author=. arXiv , year=
-
[38]
Nature reviews neuroscience , year=
The free-energy principle: a unified brain theory? , author=. Nature reviews neuroscience , year=
-
[39]
Attention is all you need , author=
-
[40]
Scientific Reports , year=
Training convolutional neural networks with the Forward--Forward Algorithm , author=. Scientific Reports , year=
-
[41]
arXiv , year=
On Advancements of the Forward-Forward Algorithm , author=. arXiv , year=
-
[42]
Deep residual learning for image recognition , author=
-
[43]
arXiv , year=
Distance-forward learning: enhancing the forward-forward algorithm towards high-performance on-chip learning , author=. arXiv , year=
-
[44]
Imagenet classification with deep convolutional neural networks , author=
-
[45]
A method for stochastic optimization , author=
-
[46]
Decoupled weight decay regularization , author=
-
[47]
arXiv , year=
The forward-forward algorithm: Some preliminary investigations , author=. arXiv , year=
-
[48]
arXiv , year=
Symba: Symmetric backpropagation-free contrastive learning with forward-forward algorithm for optimizing convergence , author=. arXiv , year=
-
[49]
Symposium on VLSI 2024 , year=
FFCL: forward-forward net with cortical loops, training and inference on edge without Backpropogation , author=. Symposium on VLSI 2024 , year=
2024
-
[50]
Layer collaboration in the forward-forward algorithm , author=
-
[51]
arXiv , year=
Training convolutional neural networks with the forward-forward algorithm , author=. arXiv , year=
-
[52]
Convolutional channel-wise competitive learning for the forward-forward algorithm , author=
-
[53]
Neural Computation , year=
Predictive coding approximates backprop along arbitrary computation graphs , author=. Neural Computation , year=
-
[54]
Joint European Conference on Machine Learning and Knowledge Discovery in Databases , year=
Difference target propagation , author=. Joint European Conference on Machine Learning and Knowledge Discovery in Databases , year=
-
[55]
Nature Communications , year=
Random feedback weights support learning in deep neural networks , author=. Nature Communications , year=
-
[56]
How important is weight symmetry in backpropagation? , author=
-
[57]
Direct feedback alignment provides learning in deep neural networks , author=
-
[58]
Biologically-plausible learning algorithms can scale to large datasets , author=
-
[59]
Hebbian deep learning without feedback , author=
-
[60]
arXiv , year=
Scalable Forward-Forward Algorithm , author=. arXiv , year=
-
[61]
TMLR , year=
The trifecta: Three simple techniques for training deeper forward-forward networks , author=. TMLR , year=
-
[62]
arXiv , year=
NoProp: Training Neural Networks without Back-propagation or Forward-propagation , author=. arXiv , year=
-
[63]
ICML , year=
Dendritic Localized Learning: Toward Biologically Plausible Algorithm , author=. ICML , year=
-
[64]
Frontiers in Computational Neuroscience , year=
Toward an integration of deep learning and neuroscience , author=. Frontiers in Computational Neuroscience , year=
-
[65]
International Machine Vision and Image Processing Conference (MVIP) , year=
Marginal Contrastive Loss: A Step Forward for Forward-Forward , author=. International Machine Vision and Image Processing Conference (MVIP) , year=
-
[66]
Frontiers in Neuroscience , year=
Direct feedback alignment with sparse connections for local learning , author=. Frontiers in Neuroscience , year=
-
[67]
2005 , publisher=
The organization of behavior: A neuropsychological theory , author=. 2005 , publisher=
2005
-
[68]
Hyperspherical classification with dynamic label-to-prototype assignment , author=
-
[69]
Mono-Forward: Revisiting Forward-Forward through Objective-Locality Decomposition
Mono-forward: backpropagation-free algorithm for efficient neural network training harnessing local errors , author=. arXiv preprint arXiv:2501.09238 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[70]
International conference on machine learning , pages=
Training neural networks with local error signals , author=. International conference on machine learning , pages=. 2019 , organization=
2019
-
[71]
International conference on machine learning , pages=
Greedy layerwise learning can scale to imagenet , author=. International conference on machine learning , pages=. 2019 , organization=
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.