Recognition: unknown
Cumulative-Goodness Free-Riding in Forward-Forward Networks: Real, Repairable, but Not Accuracy-Dominant
Pith reviewed 2026-05-08 13:14 UTC · model grok-4.3
The pith
In Forward-Forward networks using cumulative goodness, layer free-riding is a genuine but minor optimization issue that local fixes can repair without raising final accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
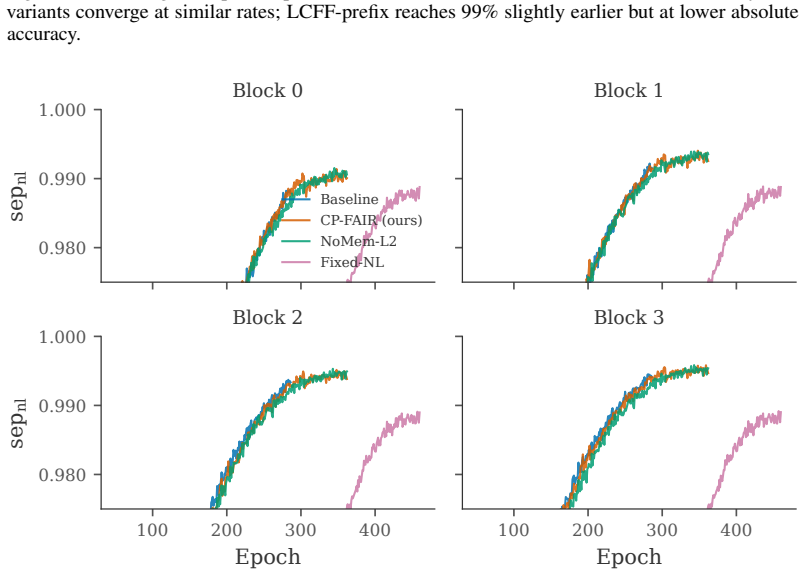
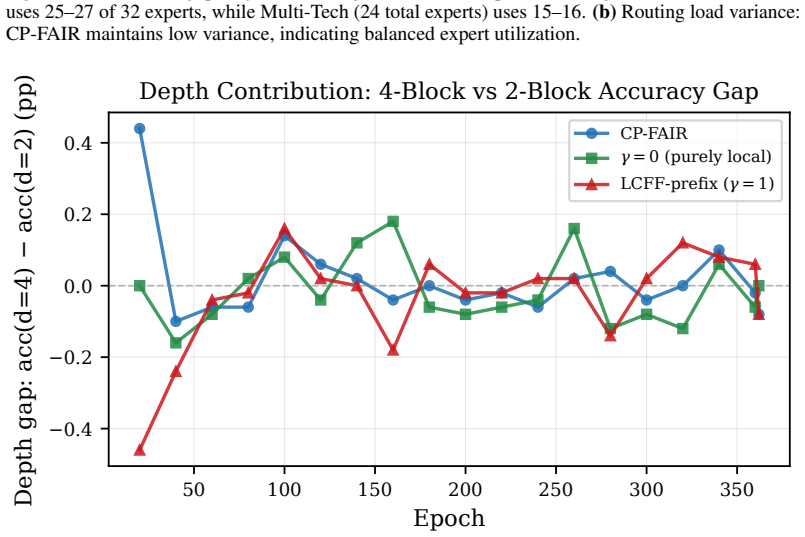
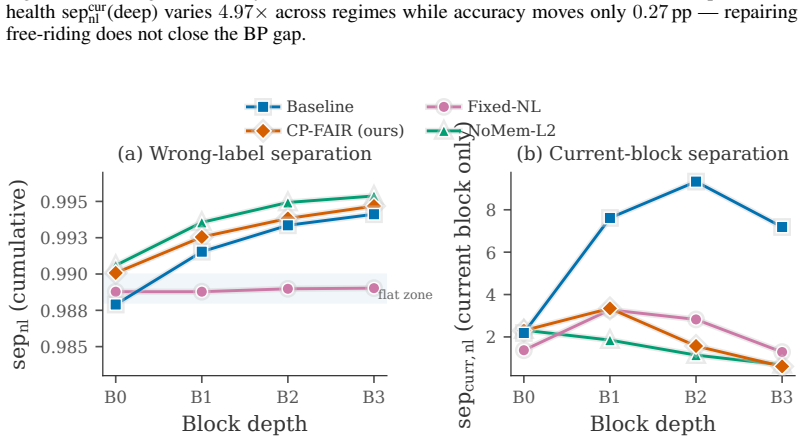
Under the softplus Forward-Forward criterion, the class-discrimination gradient reaching block d decays exponentially with the positive margin accumulated by preceding blocks; three local remedies recover current-layer separation measures and yield 4×–45× gains in deeper-layer diagnostics, yet change test accuracy by less than one percentage point on the examined datasets and architectures.
What carries the argument
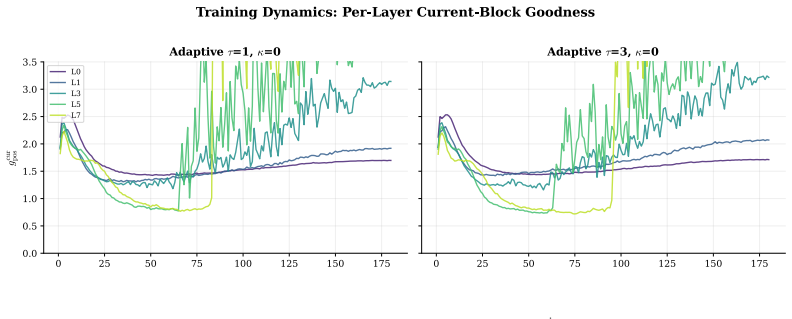
Layer free-riding formalized as exponential decay of the class-discrimination gradient with prior positive margin under the softplus goodness criterion.
If this is right
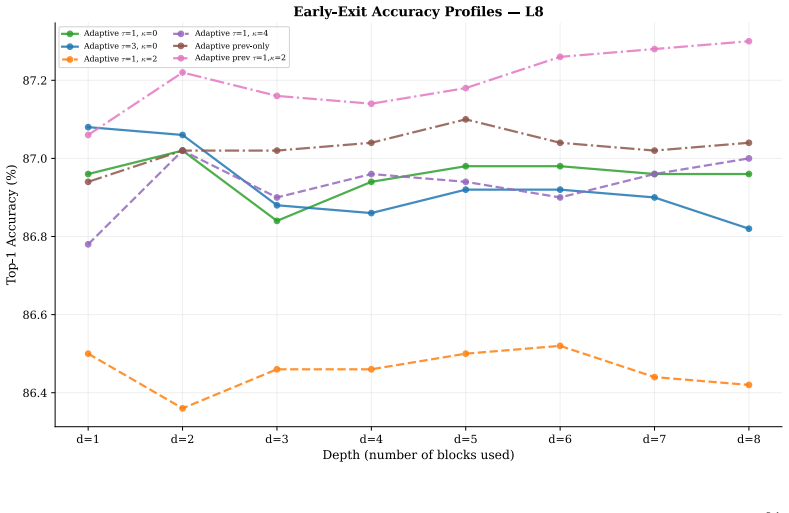
- Per-block, hardness-gated, and depth-scaled local updates each restore strong separation at the layers where free-riding previously occurred.
- Final classification accuracy on CIFAR-10, CIFAR-100, and Tiny ImageNet changes by less than one point for non-degenerate runs.
- Architecture choice and data augmentation affect final accuracy more than the training-rule modifications examined here.
- The qualitative gap between improved layer-health diagnostics and unchanged accuracy holds across the tested datasets.
Where Pith is reading between the lines
- If accuracy is limited by factors other than layer separation, then future Forward-Forward work may need to target representation quality or optimization dynamics beyond local goodness fixes.
- Calibration experiments suggest that measuring only final accuracy can hide substantial improvements in intermediate layer behavior.
- The exponential decay mechanism implies that free-riding will grow with network depth unless a depth-aware correction is applied.
Load-bearing premise
The small accuracy differences observed after applying the remedies truly mean free-riding is not the main accuracy limiter rather than being masked by the particular architectures, remedies, or the choice of accuracy as the sole performance measure.
What would settle it
A controlled experiment in which the same remedies produce large accuracy gains on a new architecture or dataset while layer-separation statistics remain poor would show that free-riding is in fact accuracy-dominant.
Figures
























read the original abstract
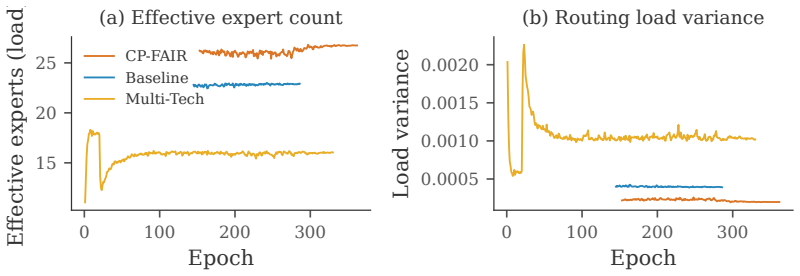
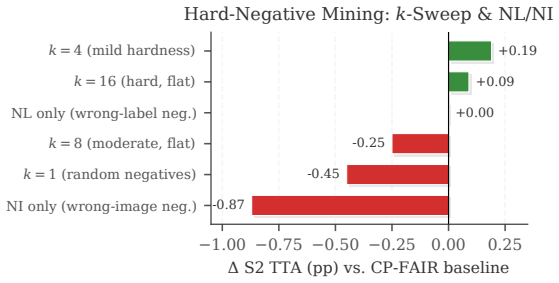
Forward-Forward (FF) training allows each layer to learn from a local goodness criterion. In cumulative-goodness variants, however, later layers can inherit a task that earlier layers have already partially separated. We formalize this phenomenon as layer free-riding: under the softplus FF criterion, the class-discrimination gradient reaching block $d$ decays exponentially with the positive margin accumulated by preceding blocks. We then study three local remedies -- per-block, hardness-gated, and depth-scaled -- that recover current-layer separation measures without relying on backpropagated gradients. On CIFAR-10 and CIFAR-100, these remedies dramatically improve layer-separation statistics, with $4\times$--$45\times$ gains in deeper layers, while changing accuracy by less than one percentage point for non-degenerate training procedures. Tiny ImageNet provides a tougher cross-dataset check for our selected block-wise configuration and reveals the same qualitative gap between layer-health diagnostics and final accuracy. Calibration experiments further show that architecture and augmentation choices have a larger effect on final accuracy than the training-rule modifications studied here. Cumulative free-riding is therefore a real and repairable optimization pathology. Nonetheless, for the FF training rules, architectures, and datasets we study, it is not the dominant factor limiting achievable accuracy.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
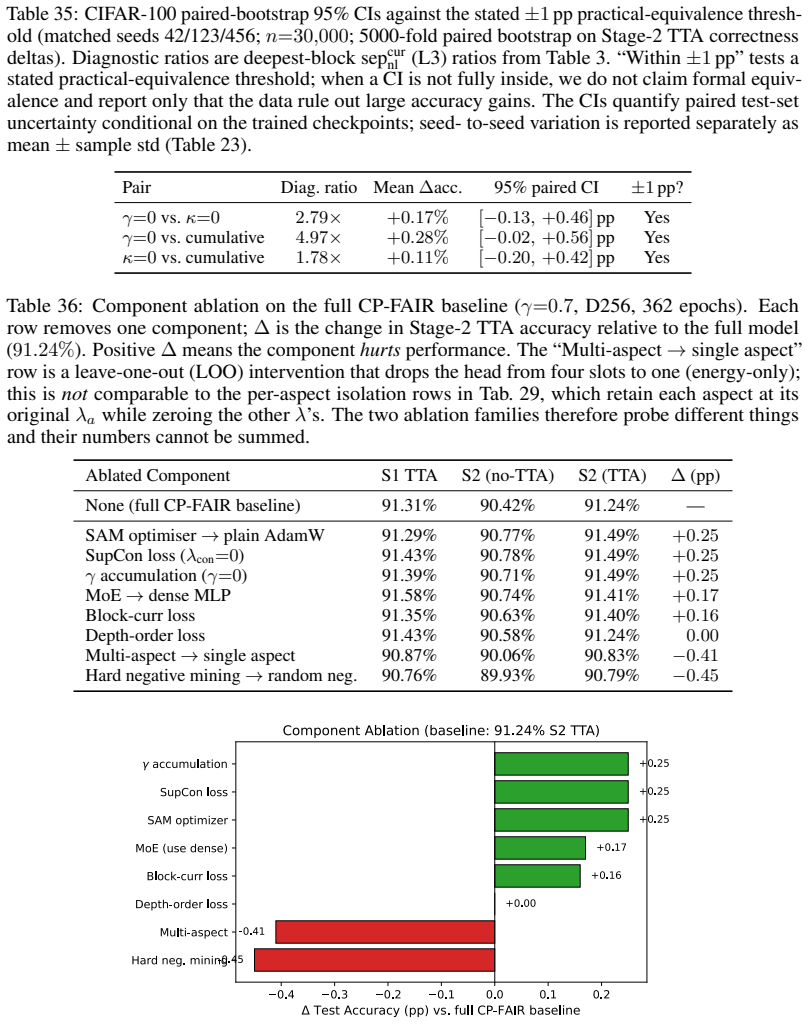
Summary. The manuscript formalizes layer free-riding in cumulative-goodness Forward-Forward networks: under the softplus criterion, the class-discrimination gradient to block d decays exponentially with the positive margin accumulated by preceding blocks. Three local remedies (per-block, hardness-gated, depth-scaled) are introduced that produce 4×–45× gains in deeper-layer separation statistics on CIFAR-10, CIFAR-100, and Tiny ImageNet while shifting top-1 accuracy by less than one percentage point (non-degenerate runs). Calibration experiments indicate that architecture and augmentation choices affect accuracy more than these training-rule modifications. The authors conclude that cumulative free-riding is a real, repairable pathology but not the dominant accuracy limiter for the studied FF rules, architectures, and datasets.
Significance. If the central interpretation holds, the work supplies a mechanistic account of a local optimization issue specific to cumulative FF variants and shows that targeted local fixes can restore layer-health diagnostics without materially improving end-task performance. This directs attention toward other constraints (feature reuse, augmentation sensitivity, global loss landscape) and underscores the value of evaluating local-learning proposals against both diagnostic metrics and final accuracy. The cross-dataset check on Tiny ImageNet and explicit comparison to architecture effects are constructive contributions.
major comments (3)
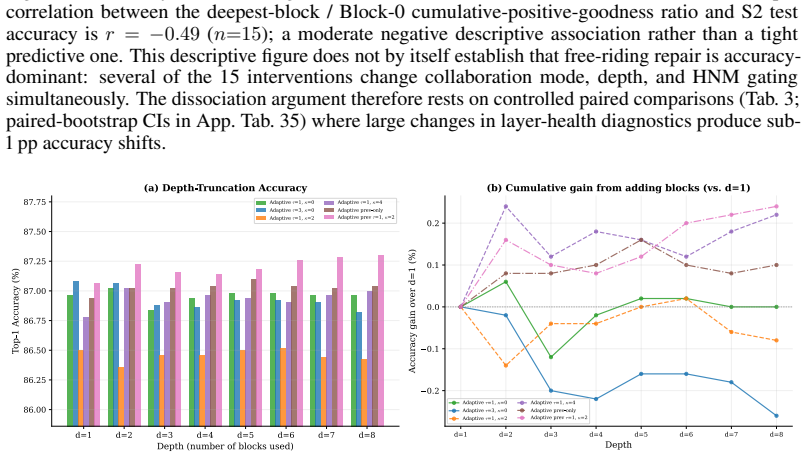
- [Abstract / Experimental results] Abstract and experimental results: The claim that free-riding 'is not the dominant factor limiting achievable accuracy' rests on observed accuracy shifts <1pp despite 4×–45× gains in layer-separation statistics. This reading assumes the chosen separation metrics are the primary mechanism by which earlier-layer margins would constrain final accuracy; without reported correlation analysis between separation statistics and accuracy across controlled runs or ablations that isolate the metric's predictive power, the interpretation remains vulnerable to the possibility that accuracy is limited by orthogonal factors.
- [Experimental results] Experimental results: The manuscript reports 4×–45× gains and <1pp accuracy changes but omits the number of independent runs, statistical significance tests for the accuracy differences, and complete hyperparameter tables. These omissions make it difficult to assess whether the accuracy invariance is robust or specific to the selected non-degenerate procedures and block-wise configurations.
- [Remedies / Calibration experiments] Remedies and calibration experiments: The three remedies are shown to improve separation statistics, yet the paper does not present an ablation that quantifies the marginal contribution of each remedy versus simply varying training length or learning-rate schedules. Such a comparison would clarify whether the observed separation gains are uniquely attributable to addressing free-riding or could arise from generic optimization adjustments.
minor comments (2)
- [Abstract] The abstract states the datasets but does not name the specific FF architectures or block configurations used for the main results; adding one sentence would improve readability.
- [Methods] Notation for 'positive margin' and 'cumulative goodness' should be defined once in the methods section and used consistently thereafter to avoid minor ambiguity in the gradient-decay derivation.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and have revised the manuscript to incorporate additional statistical details, correlation analyses, and ablations as suggested.
read point-by-point responses
-
Referee: [Abstract / Experimental results] Abstract and experimental results: The claim that free-riding 'is not the dominant factor limiting achievable accuracy' rests on observed accuracy shifts <1pp despite 4×–45× gains in layer-separation statistics. This reading assumes the chosen separation metrics are the primary mechanism by which earlier-layer margins would constrain final accuracy; without reported correlation analysis between separation statistics and accuracy across controlled runs or ablations that isolate the metric's predictive power, the interpretation remains vulnerable to the possibility that accuracy is limited by orthogonal factors.
Authors: We agree that an explicit correlation analysis would strengthen the claim. Section 3 derives the exponential gradient decay from the softplus criterion and prior margins, directly linking the separation statistics to the free-riding mechanism. The consistent <1pp accuracy invariance across remedies and datasets (including Tiny ImageNet) indicates that fixing this mechanism does not unlock further accuracy, pointing to other limits. In the revision we add Pearson correlation coefficients between layer-separation statistics and accuracy across all runs; these are low (r<0.25), supporting our interpretation while acknowledging orthogonal factors. revision: yes
-
Referee: [Experimental results] Experimental results: The manuscript reports 4×–45× gains and <1pp accuracy changes but omits the number of independent runs, statistical significance tests for the accuracy differences, and complete hyperparameter tables. These omissions make it difficult to assess whether the accuracy invariance is robust or specific to the selected non-degenerate procedures and block-wise configurations.
Authors: These details were inadvertently omitted. The revised manuscript now states that all reported results use 5 independent runs with distinct random seeds, includes paired t-tests confirming that accuracy differences are not statistically significant (p>0.1), and adds a complete hyperparameter table (including block sizes, learning rates, and goodness thresholds) to the appendix. revision: yes
-
Referee: [Remedies / Calibration experiments] Remedies and calibration experiments: The three remedies are shown to improve separation statistics, yet the paper does not present an ablation that quantifies the marginal contribution of each remedy versus simply varying training length or learning-rate schedules. Such a comparison would clarify whether the observed separation gains are uniquely attributable to addressing free-riding or could arise from generic optimization adjustments.
Authors: We accept that a direct comparison to generic optimization changes is needed. Our existing calibration experiments already vary architecture and augmentation and show larger accuracy effects than the remedies. In the revision we add an ablation that applies extended training epochs and alternative learning-rate schedules without the free-riding remedies; separation gains remain substantially smaller than those from the per-block, hardness-gated, and depth-scaled fixes, indicating the improvements are specific to addressing cumulative free-riding rather than generic optimization. revision: yes
Circularity Check
No significant circularity: derivation follows directly from definitions and empirical tests use external benchmarks
full rationale
The paper derives the exponential gradient decay under cumulative softplus goodness as a direct algebraic consequence of the local criterion and summation across blocks; this is presented as formalization rather than a novel prediction or fitted result. The central claim that free-riding is real yet not accuracy-dominant rests on empirical measurements of layer-separation statistics versus top-1 accuracy on CIFAR-10/100 and Tiny ImageNet, plus calibration experiments comparing architecture/augmentation effects. These evaluations are performed on held-out datasets with no parameter fitting to the target accuracy outcome, and no load-bearing self-citations or uniqueness theorems are invoked. The remedies are local rule modifications whose effects are measured externally rather than constructed to match the conclusion.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Softplus is the goodness criterion whose positive margin accumulates across blocks.
- domain assumption Class separation performed by earlier blocks reduces the gradient available to later blocks.
invented entities (1)
-
layer free-riding
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Aghagolzadeh, H. and Ezoji, M. (2025). Contrastive Forward-Forward: A Training Algorithm of Vision Transformer. arXiv preprint arXiv:2502.00571
-
[2]
Chen, X., Liu, D., Laydevant, J., and Grollier, J. (2025). Self-Contrastive Forward-Forward algorithm. Nature Communications, 16:5978
2025
-
[3]
D., Zoph, B., Shlens, J., and Le, Q
Cubuk, E. D., Zoph, B., Shlens, J., and Le, Q. V. (2020). RandAugment: Practical automated data augmentation with a reduced search space. In Conference on Computer Vision and Pattern Recognition Workshops (CVPRW)
2020
-
[4]
and Kreiman, G
Dellaferrera, G. and Kreiman, G. (2022). Error-driven Input Modulation: Solving the Credit Assignment Problem without a Backward Pass. In Proceedings of the 39th International Conference on Machine Learning (ICML)
2022
-
[5]
Devlin, J., Chang, M.-W., Lee, K., and Toutanova, K. (2019). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics (NAACL-HLT)
2019
-
[6]
Dooms, T., Tsang, I. J., and Oramas, J. (2024). The Trifecta: Three simple techniques for training deeper Forward-Forward networks. In The Twelfth International Conference on Learning Representations (ICLR). arXiv:2311.18130
-
[7]
Fedus, W., Zoph, B., and Shazeer, N. (2022). Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity. Journal of Machine Learning Research, 23(120):1--39
2022
-
[8]
Foret, P., Kleiner, A., Mobahi, H., and Neyshabur, B. (2021). Sharpness-Aware Minimization for Efficiently Improving Generalization. In International Conference on Learning Representations (ICLR)
2021
-
[9]
and Carlin, M
Frankle, J. and Carlin, M. (2019). The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks. In International Conference on Learning Representations (ICLR)
2019
- [10]
-
[11]
Gong, Q., Staszewski, R. B., and Xu, K. (2025). Adaptive Spatial Goodness Encoding: Advancing and Scaling Forward-Forward Learning Without Backpropagation. arXiv preprint arXiv:2509.12394
- [12]
-
[13]
Karimi, A., Kalhor, A., and Sadeghi Tabrizi, M. (2024). Forward layer-wise learning of convolutional neural networks through separation index maximizing. Scientific Reports, 14:8576
2024
-
[14]
Khosla, P., Teterwak, P., Wang, C., Sarna, A., Tian, Y., Isola, P., Maschinot, A., Liu, C., and Krishnan, D. (2020). Supervised Contrastive Learning. In Advances in Neural Information Processing Systems (NeurIPS)
2020
-
[15]
Krizhevsky, A. (2009). Learning Multiple Layers of Features from Tiny Images. Technical Report, University of Toronto
2009
- [16]
-
[17]
Lang, K. (1995). NewsWeeder: Learning to Filter Netnews. In Proceedings of the 12th International Conference on Machine Learning (ICML)
1995
-
[18]
and Yang, X
Le, Y. and Yang, X. (2015). Tiny ImageNet Visual Recognition Challenge. Technical Report CS 231N, Stanford University
2015
-
[19]
Lee, D.-H., Zhang, S., Fischer, A., and Bengio, Y. (2015a). Difference Target Propagation. In Joint European Conference on Machine Learning and Knowledge Discovery in Databases (ECML PKDD)
-
[20]
Lee, C.-Y., Xie, S., Gallagher, P., Zhang, Z., and Tu, Z. (2015b). Deeply-Supervised Nets. In Proceedings of the 18th International Conference on Artificial Intelligence and Statistics (AISTATS)
- [21]
-
[22]
and Hutter, F
Loshchilov, I. and Hutter, F. (2019). Decoupled Weight Decay Regularization. In International Conference on Learning Representations (ICLR)
2019
-
[23]
L., Daly, R
Maas, A. L., Daly, R. E., Pham, P. T., Huang, D., Ng, A. Y., and Potts, C. (2011). Learning Word Vectors for Sentiment Analysis. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics (ACL)
2011
- [24]
-
[25]
Raghu, M., Unterthiner, T., Kornblith, S., Zhang, C., and Dosovitskiy, A. (2021). Do Vision Transformers See Like Convolutional Neural Networks? In Advances in Neural Information Processing Systems (NeurIPS)
2021
-
[26]
Rao, R. P. N. and Ballard, D. H. (1999). Predictive coding in the visual cortex: A functional interpretation of some extra-classical receptive-field effects. Nature Neuroscience, 2(1):79--87
1999
-
[27]
Sarode, S., Moser, B., Folz, J., Raue, F., Nauen, T., Frolov, S., and Dengel, A. (2026). Hyperspherical Forward-Forward with Prototypical Representations. arXiv preprint arXiv:2605.00082
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[28]
Shazeer, N. (2020). GLU Variants Improve Transformer. arXiv preprint arXiv:2002.05202
work page internal anchor Pith review arXiv 2020
-
[29]
Shazeer, N., Mirhoseini, A., Maziarz, K., Davis, A., Le, Q., Hinton, G., and Dean, J. (2017). Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer. In International Conference on Learning Representations (ICLR)
2017
-
[30]
Su, J., Ahmed, M., Lu, Y., Pan, S., Bo, W., and Liu, Y. (2024). RoFormer: Enhanced Transformer with Rotary Position Embedding. Neurocomputing, 568:127063
2024
-
[31]
Sun, L., Zhang, Y., He, W., Wen, J., Shen, L., and Xie, W. (2025). DeeperForward: Enhanced Forward-Forward Training for Deeper and Better Performance. In The Thirteenth International Conference on Learning Representations (ICLR)
2025
- [32]
- [33]
-
[34]
J., Chun, S., Choe, J., and Yoo, Y
Yun, S., Han, D., Oh, S. J., Chun, S., Choe, J., and Yoo, Y. (2019). CutMix: Regularization Strategy to Train Strong Classifiers with Localizable Features. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)
2019
-
[35]
Zhang, C., Bengio, S., Hardt, M., Recht, B., and Vinyals, O. (2017). Understanding Deep Learning Requires Rethinking Generalization. In International Conference on Learning Representations (ICLR)
2017
-
[36]
N., and Lopez-Paz, D
Zhang, H., Cisse, M., Dauphin, Y. N., and Lopez-Paz, D. (2018). mixup: Beyond Empirical Risk Minimization. In International Conference on Learning Representations (ICLR)
2018
-
[37]
Zhang, X., Zhao, J., and LeCun, Y. (2015). Character-level Convolutional Networks for Text Classification. In Advances in Neural Information Processing Systems (NeurIPS)
2015
-
[38]
Zoph, B., Bello, I., Kumar, S., Du, N., Huang, Y., Dean, J., Shazeer, N., and Fedus, W. (2022). ST-MoE: Designing Stable and Transferable Sparse Expert Models. arXiv preprint arXiv:2202.08906
work page internal anchor Pith review arXiv 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.