Recognition: unknown
Adaptive Norm-Based Regularization for Neural Networks
Pith reviewed 2026-05-09 20:20 UTC · model grok-4.3
The pith
Neural network penalties that incorporate input feature covariances outperform standard norm-based regularization on correlated or high-dimensional data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that embedding the sample covariance of the input features into an ℓ2 penalty term, and pairing it with an ℓ1 term, yields network weights that are both sparse and structurally informed, thereby reducing generalization error relative to standard norm penalties in settings where inputs exhibit dependence or high dimensionality.
What carries the argument
Covariance-augmented ℓ2 penalty (ridge-type weight decay that scales with the input covariance matrix) and its combination with an ℓ1 sparsity term.
If this is right
- Predictive performance improves on unseen data when input features are correlated.
- Model complexity is controlled more effectively than with standard weight-decay or lasso penalties.
- The approach yields gains in both regression and classification tasks involving high-dimensional inputs.
- Real-world utility is demonstrated on energy-load forecasting and gene-expression classification.
Where Pith is reading between the lines
- The same covariance adjustment could be tested inside other network architectures such as convolutional or graph networks.
- If covariance estimation proves stable, the method might reduce the need for heavy hyperparameter search over penalty coefficients.
- Similar structural penalties could be derived for recurrent or attention-based models that process sequential or relational data.
Load-bearing premise
The covariance matrix of the input features can be reliably estimated from the training data and incorporated into the penalty without introducing optimization instability or bias that would negate the reported gains.
What would settle it
A controlled experiment or dataset in which the sample covariance estimate is noisy or ill-conditioned, such that the proposed methods produce equal or higher out-of-sample error than ordinary ℓ2 or ℓ1 penalties.
Figures


read the original abstract
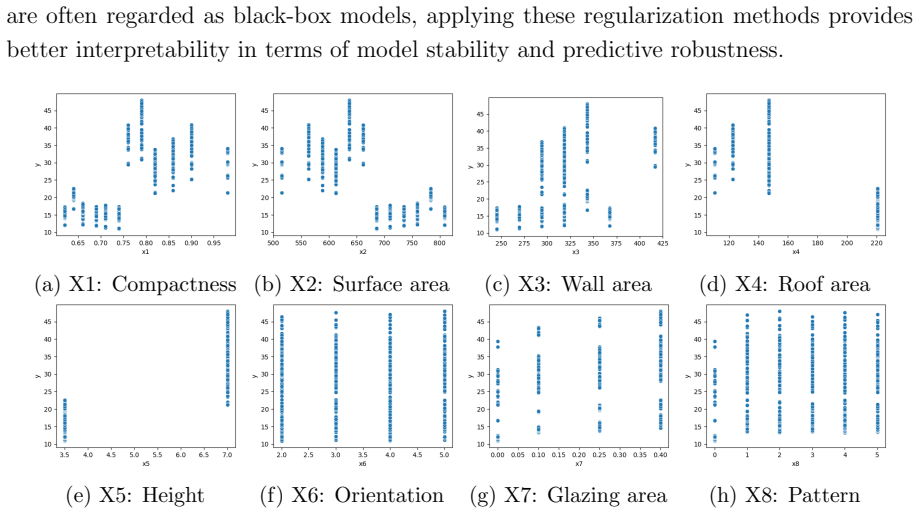
In this paper, we study norm-based regularization methods for neural networks. We compare existing penalization approaches and introduce two regularization strategies that extend classical ridge- and lasso-type penalties to neural network models. The first strategy modifies weight decay by incorporating the covariance structure of the input features into a ridge-type $\ell_2$ penalty, allowing regularization to account for feature dependence. The second combines an $\ell_1$ sparsity penalty with covariance-aware $\ell_2$ regularization, producing neural network weights that are both sparse and structurally informed. Monte Carlo simulations are used to evaluate these methods under different data-generating settings, followed by two real-data applications on building cooling-load prediction and leukemia cell-type classification from high-dimensional gene expression data. Across simulated and real-data examples, the proposed regularizers improve predictive performance on unseen data and provide more effective complexity control than standard norm-based penalties, particularly when features are correlated or high-dimensional.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes two covariance-aware extensions to standard norm-based regularization for neural networks: an ℓ2 penalty that incorporates the input feature covariance matrix into weight decay, and a hybrid ℓ1-ℓ2 penalty combining sparsity with the covariance structure. These are tested via Monte Carlo simulations across data-generating settings and applied to two real datasets (building cooling-load prediction and high-dimensional leukemia gene-expression classification), with the central claim that the proposed regularizers yield better out-of-sample predictive performance and complexity control than classical penalties, especially under feature correlation or high dimensionality.
Significance. If the covariance estimation proves stable and the reported gains are robust, the methods could provide a practical adaptive regularization tool for neural networks in structured or high-dimensional data. The Monte Carlo component offers controlled evidence, but the real-data claims—particularly the leukemia results—hinge on reliable covariance plug-in without introducing instability or bias, which is not yet demonstrated.
major comments (3)
- [§4.2 (real-data applications)] Leukemia classification experiment: direct plug-in of the sample covariance matrix into the ℓ2 penalty term is used for p ≫ n gene-expression data, but the sample covariance is singular and its eigenvalues are poorly estimated; this risks an ill-conditioned or feature-dependent effective regularization strength that could negate or artifactually produce the claimed performance gains. A stable estimator (e.g., shrinkage) should be substituted and results re-evaluated to confirm the adaptive-norm benefit is genuine rather than an artifact of invalid covariance estimation.
- [§4.1 (simulation study)] Monte Carlo simulation results: no quantitative details are given on the number of replications, standard errors or confidence intervals on performance metrics, exact hyperparameter tuning protocol (including how λ is selected), or statistical significance tests comparing the proposed penalties to baselines; without these, the claim of consistent improvement across settings cannot be verified and the evidence remains qualitative.
- [Table 3 (real-data results)] Table of real-data performance metrics: the reported improvements lack error bars, baseline method details (e.g., exact architectures and tuning for standard weight decay), and cross-validation procedures, making it impossible to assess whether the gains are statistically meaningful or reproducible.
minor comments (2)
- [Abstract] Abstract: the phrase 'structurally informed' is imprecise; clarify that the only structural information used is the input covariance matrix.
- [§3 (proposed methods)] Notation: the definition of the covariance-aware penalty should explicitly state whether the covariance estimate is computed once on the full training set or inside each optimization step, to avoid ambiguity in implementation.
Simulated Author's Rebuttal
We thank the referee for the careful and constructive review. The comments identify key areas where additional rigor is needed, particularly regarding covariance estimation in high dimensions and the completeness of experimental reporting. We respond to each major comment below and indicate planned revisions.
read point-by-point responses
-
Referee: [§4.2 (real-data applications)] Leukemia classification experiment: direct plug-in of the sample covariance matrix into the ℓ2 penalty term is used for p ≫ n gene-expression data, but the sample covariance is singular and its eigenvalues are poorly estimated; this risks an ill-conditioned or feature-dependent effective regularization strength that could negate or artifactually produce the claimed performance gains. A stable estimator (e.g., shrinkage) should be substituted and results re-evaluated to confirm the adaptive-norm benefit is genuine rather than an artifact of invalid covariance estimation.
Authors: We agree that direct use of the sample covariance matrix is problematic when p ≫ n, as it is singular and yields unstable eigenvalue estimates that can distort the effective regularization. This is a substantive limitation of the original implementation. In the revised manuscript we will replace the plug-in estimator with a shrinkage covariance estimator (Ledoit-Wolf) in the leukemia experiment, re-run the classification task, and report the updated results to demonstrate that the performance advantage of the covariance-aware penalty is not an artifact of ill-conditioned estimation. revision: yes
-
Referee: [§4.1 (simulation study)] Monte Carlo simulation results: no quantitative details are given on the number of replications, standard errors or confidence intervals on performance metrics, exact hyperparameter tuning protocol (including how λ is selected), or statistical significance tests comparing the proposed penalties to baselines; without these, the claim of consistent improvement across settings cannot be verified and the evidence remains qualitative.
Authors: The referee correctly notes that these quantitative elements were omitted. We will revise §4.1 to state the number of Monte Carlo replications performed, include standard errors and confidence intervals for all reported metrics, describe the exact hyperparameter tuning protocol (grid search over λ combined with cross-validation), and add formal statistical comparisons (e.g., paired tests) against the baseline penalties. These additions will convert the current qualitative presentation into verifiable quantitative evidence. revision: yes
-
Referee: [Table 3 (real-data results)] Table of real-data performance metrics: the reported improvements lack error bars, baseline method details (e.g., exact architectures and tuning for standard weight decay), and cross-validation procedures, making it impossible to assess whether the gains are statistically meaningful or reproducible.
Authors: We acknowledge that the current Table 3 lacks the supporting information required for reproducibility and statistical assessment. In the revision we will add error bars (standard deviations across folds or replications), supply precise specifications of all baseline architectures and their tuning procedures, and document the cross-validation protocol used for both training and evaluation. These changes will allow readers to judge the reliability and reproducibility of the reported gains. revision: yes
Circularity Check
No circularity: regularization definitions and empirical tests are independent of evaluation data
full rationale
The paper defines two new penalties by directly incorporating the sample covariance of input features into classical ℓ2 (and combined ℓ1-ℓ2) norms; these definitions are fixed once the training covariance is computed and do not reference test-set performance or any fitted outcome. Monte Carlo simulations and real-data hold-out evaluations are performed on data partitions never used to construct the penalties. No equations, uniqueness theorems, or self-citations are invoked that would make the reported predictive gains equivalent to the inputs by construction. The central claims remain empirical comparisons rather than tautological renamings or self-referential derivations.
Axiom & Free-Parameter Ledger
free parameters (1)
- regularization strength lambda
axioms (1)
- domain assumption Input features possess a covariance structure that can be estimated from finite training samples and used to modify the penalty without destabilizing gradient-based optimization.
Reference graph
Works this paper leans on
-
[1]
Brooks, Steve and Gelman, Andrew and Jones, Galin and Meng, Xiao-Li , year =
-
[2]
Computational statistics & data analysis , volume =
Efficient methods for estimating constrained parameters with applications to regularized (lasso) logistic regression , author =. Computational statistics & data analysis , volume =. 2008 , publisher =
2008
-
[3]
Technometrics , volume=
Ridge regression: Biased estimation for nonorthogonal problems , author=. Technometrics , volume=. 1970 , publisher=
1970
-
[4]
2016 , publisher=
Deep Learning , author=. 2016 , publisher=
2016
-
[5]
Journal of the Royal Statistical Society: Series B , volume=
Regression shrinkage and selection via the lasso , author=. Journal of the Royal Statistical Society: Series B , volume=
-
[6]
Journal of the Royal Statistical Society: Series B , volume=
Regularization and variable selection via the elastic net , author=. Journal of the Royal Statistical Society: Series B , volume=
-
[7]
International Conference on Learning Representations (ICLR) , year=
Understanding deep learning requires rethinking generalization , author=. International Conference on Learning Representations (ICLR) , year=
-
[8]
2023 , publisher=
Dive into deep learning , author=. 2023 , publisher=
2023
-
[9]
Decoupled Weight Decay Regularization
Decoupled weight decay regularization , author=. arXiv preprint arXiv:1711.05101 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
2022 , publisher=
Machine learning: a first course for engineers and scientists , author=. 2022 , publisher=
2022
-
[11]
arXiv preprint arXiv:2407.18384 , year=
Mathematical theory of deep learning , author=. arXiv preprint arXiv:2407.18384 , year=
-
[12]
Statistical Methods in Medical Research , volume=
LASSO-type instrumental variable selection methods with an application to Mendelian randomization , author=. Statistical Methods in Medical Research , volume=. 2025 , publisher=
2025
-
[13]
Proceedings of the AAAI conference on artificial intelligence , volume=
Ead: elastic-net attacks to deep neural networks via adversarial examples , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[14]
Neurocomputing , volume=
A novel variable selection algorithm for multi-layer perceptron with elastic net , author=. Neurocomputing , volume=. 2019 , publisher=
2019
-
[15]
Proceedings of Neuro-N
Stochastic gradient learning in neural networks , author=. Proceedings of Neuro-N. 1991 , publisher=
1991
-
[16]
Neural networks: tricks of the trade: second edition , pages=
Stochastic gradient descent tricks , author=. Neural networks: tricks of the trade: second edition , pages=. 2012 , publisher=
2012
-
[17]
2009 , publisher=
The elements of statistical learning , author=. 2009 , publisher=
2009
-
[18]
Neural Computing and Applications , volume=
Dynamically pre-trained deep recurrent neural networks using environmental monitoring data for predicting PM 2.5 , author=. Neural Computing and Applications , volume=. 2016 , publisher=
2016
-
[19]
IEEE Access , volume=
Adaptive weight decay for deep neural networks , author=. IEEE Access , volume=. 2019 , publisher=
2019
-
[20]
L2 regularization versus batch and weight normalization
L2 regularization versus batch and weight normalization , author=. arXiv preprint arXiv:1706.05350 , year=
-
[21]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Sparse convolutional neural networks , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[22]
2018 IEEE High Performance extreme Computing Conference (HPEC) , pages=
Sparse deep neural network exact solutions , author=. 2018 IEEE High Performance extreme Computing Conference (HPEC) , pages=. 2018 , organization=
2018
-
[23]
Neural Networks , volume=
Transformed l1 regularization for learning sparse deep neural networks , author=. Neural Networks , volume=. 2019 , publisher=
2019
-
[24]
2019 IEEE High Performance Extreme Computing Conference (HPEC) , pages=
Sparse deep neural network graph challenge , author=. 2019 IEEE High Performance Extreme Computing Conference (HPEC) , pages=. 2019 , organization=
2019
-
[25]
Accelerating sparse deep neural networks.arXiv preprint arXiv:2104.08378,
Accelerating sparse deep neural networks , author=. arXiv preprint arXiv:2104.08378 , year=
-
[26]
2021 IEEE International Conference on Information Communication and Software Engineering (ICICSE) , pages=
A bearing fault diagnosis method based on L1 regularization transfer learning and LSTM deep learning , author=. 2021 IEEE International Conference on Information Communication and Software Engineering (ICICSE) , pages=. 2021 , organization=
2021
-
[27]
Neural Networks , volume=
Low-rank discriminative regression learning for image classification , author=. Neural Networks , volume=. 2020 , publisher=
2020
-
[28]
Mechanical Systems and Signal Processing , volume=
Bearing fault diagnosis via generalized logarithm sparse regularization , author=. Mechanical Systems and Signal Processing , volume=. 2022 , publisher=
2022
-
[29]
Journal of Fourier analysis and applications , volume=
Enhancing sparsity by reweighted l1 minimization , author=. Journal of Fourier analysis and applications , volume=. 2008 , publisher=
2008
-
[30]
Pattern Recognition , volume=
Robust sparse coding for one-class classification based on correntropy and logarithmic penalty function , author=. Pattern Recognition , volume=. 2021 , publisher=
2021
-
[31]
2023 , publisher=
An introduction to statistical learning: With applications in python , author=. 2023 , publisher=
2023
-
[32]
Energy and buildings , volume=
Accurate quantitative estimation of energy performance of residential buildings using statistical machine learning tools , author=. Energy and buildings , volume=. 2012 , publisher=
2012
-
[33]
Energy , volume=
Prediction and optimization of heating and cooling loads in a residential building based on multi-layer perceptron neural network and different optimization algorithms , author=. Energy , volume=. 2022 , publisher=
2022
-
[34]
Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=
Tests for specification errors in classical linear least-squares regression analysis , author=. Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=. 1969 , publisher=
1969
-
[35]
Journal of Computational Biology , volume=
Cumida: An extensively curated microarray database for benchmarking and testing of machine learning approaches in cancer research , author=. Journal of Computational Biology , volume=. 2019 , publisher=
2019
-
[36]
The Annals of statistics , pages=
On the asymptotics of constrained M-estimation , author=. The Annals of statistics , pages=. 1994 , publisher=
1994
-
[37]
Annals of statistics , pages=
Asymptotics for lasso-type estimators , author=. Annals of statistics , pages=. 2000 , publisher=
2000
-
[38]
Journal of applied Statistics , volume=
A new class of efficient and debiased two-step shrinkage estimators: method and application , author=. Journal of applied Statistics , volume=. 2022 , publisher=
2022
-
[39]
ACM Computing Surveys (Csur) , volume=
Avoiding overfitting: A survey on regularization methods for convolutional neural networks , author=. ACM Computing Surveys (Csur) , volume=. 2022 , publisher=
2022
-
[40]
The journal of machine learning research , volume=
Dropout: a simple way to prevent neural networks from overfitting , author=. The journal of machine learning research , volume=. 2014 , publisher=
2014
-
[41]
International conference on machine learning , pages=
Batch normalization: Accelerating deep network training by reducing internal covariate shift , author=. International conference on machine learning , pages=. 2015 , organization=
2015
-
[42]
Artificial Intelligence Review , volume=
A systematic review on overfitting control in shallow and deep neural networks , author=. Artificial Intelligence Review , volume=. 2021 , publisher=
2021
-
[43]
Proceedings of the thirteenth international conference on artificial intelligence and statistics , pages=
Why does unsupervised pre-training help deep learning? , author=. Proceedings of the thirteenth international conference on artificial intelligence and statistics , pages=. 2010 , organization=
2010
-
[44]
The Journal of Machine Learning Research , volume=
On over-fitting in model selection and subsequent selection bias in performance evaluation , author=. The Journal of Machine Learning Research , volume=. 2010 , publisher=
2010
-
[45]
Advances in neural information processing systems , volume=
Overfitting in neural nets: Backpropagation, conjugate gradient, and early stopping , author=. Advances in neural information processing systems , volume=
-
[46]
Advances in neural information processing systems , volume=
A simple weight decay can improve generalization , author=. Advances in neural information processing systems , volume=
-
[47]
IEEE transactions on intelligent transportation systems , volume=
Convolutional neural network with adaptive regularization to classify driving styles on smartphones , author=. IEEE transactions on intelligent transportation systems , volume=. 2019 , publisher=
2019
-
[48]
Neural Networks , volume=
Theory of adaptive SVD regularization for deep neural networks , author=. Neural Networks , volume=. 2020 , publisher=
2020
-
[49]
, author=
Manifold regularized deep neural networks. , author=. INTERSPEECH , pages=
-
[50]
Neural Networks , volume=
Batch gradient method with smoothing L1/2 regularization for training of feedforward neural networks , author=. Neural Networks , volume=. 2014 , publisher=
2014
-
[51]
Neural networks , volume=
Structural learning with forgetting , author=. Neural networks , volume=. 1996 , publisher=
1996
-
[52]
International Conference on Neural Information Processing , pages=
Convergence of batch BP algorithm with penalty for FNN training , author=. International Conference on Neural Information Processing , pages=. 2006 , organization=
2006
-
[53]
Journal of Machine Learning Research , volume=
Lassonet: A neural network with feature sparsity , author=. Journal of Machine Learning Research , volume=
-
[54]
International Conference on Machine Learning , pages=
Combined group and exclusive sparsity for deep neural networks , author=. International Conference on Machine Learning , pages=. 2017 , organization=
2017
-
[55]
Advances in neural information processing systems , volume=
Learning the number of neurons in deep networks , author=. Advances in neural information processing systems , volume=
-
[56]
IEEE transactions on image processing , volume=
Click prediction for web image reranking using multimodal sparse coding , author=. IEEE transactions on image processing , volume=. 2014 , publisher=
2014
-
[57]
Information Sciences , volume=
High dimensional data regression using Lasso model and neural networks with random weights , author=. Information Sciences , volume=. 2016 , publisher=
2016
-
[58]
IEEE Transactions on Knowledge and Data Engineering , volume=
Feature selection for neural networks using group lasso regularization , author=. IEEE Transactions on Knowledge and Data Engineering , volume=. 2019 , publisher=
2019
-
[59]
IEEE transactions on neural networks and learning systems , volume=
Design and application of a variable selection method for multilayer perceptron neural network with LASSO , author=. IEEE transactions on neural networks and learning systems , volume=. 2016 , publisher=
2016
-
[60]
Journal of big data , volume=
A survey on image data augmentation for deep learning , author=. Journal of big data , volume=. 2019 , publisher=
2019
-
[61]
Journal of big Data , volume=
Text data augmentation for deep learning , author=. Journal of big Data , volume=. 2021 , publisher=
2021
-
[62]
International conference on machine learning , pages=
Overfitting in adversarially robust deep learning , author=. International conference on machine learning , pages=. 2020 , organization=
2020
-
[63]
Bioinformatics , volume=
Graph convolutional network-based feature selection for high-dimensional and low-sample size data , author=. Bioinformatics , volume=. 2023 , publisher=
2023
-
[64]
Biostatistics , volume=
A sparse additive model for treatment effect-modifier selection , author=. Biostatistics , volume=. 2022 , publisher=
2022
-
[65]
Annals of statistics , volume=
Variable selection in nonparametric additive models , author=. Annals of statistics , volume=
-
[66]
Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=
Sparse additive models , author=. Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=. 2009 , publisher=
2009
-
[67]
The Annals of Statistics , volume=
A new test for high-dimensional two-sample mean problems with consideration of correlation structure , author=. The Annals of Statistics , volume=. 2024 , publisher=
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.