Recognition: unknown
DPU or GPU for Accelerating Neural Networks Inference -- Why not both? Split CNN Inference
Pith reviewed 2026-05-09 19:47 UTC · model grok-4.3
The pith
Splitting CNN layers between DPU and GPU with asynchronous pipelining reduces inference latency by up to 3.37 times compared to GPU-only runs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Partitioning CNN inference across the AI engines of a Versal VCK190 DPU for the first layers and an NVIDIA RTX 2080 GPU for the remaining layers, executed in an asynchronous pipeline, yields lower end-to-end latency than running the full network on either device alone. The approach further includes a trained graph neural network that selects the partition index for any given model, reaching 96.27 percent accuracy on the evaluated networks including LeNet-5, ResNet18/50/101/152, VGG16, and MobileNetv2.
What carries the argument
Split CNN Inference, the asynchronous pipeline that assigns initial layers to the DPU near the data source and remaining layers to the GPU while a graph neural network predicts the split point.
Load-bearing premise
The reported latency gains hold for the specific Versal VCK190 plus RTX 2080 hardware pair and the listed CNN models without requiring retraining of the partition predictor for new networks or input sizes.
What would settle it
Measuring higher end-to-end latency on the proposed split pipeline than on the faster of the two single-device baselines for ResNet50 or VGG16 on the same Versal VCK190 and RTX 2080 hardware.
Figures








read the original abstract
Video and image streaming on edge devices requires low latency. To address this, Neural Networks (NNs) are widely used, and prior work mainly focuses on accelerating them with single hardware units such as Graphics Processing Units (GPUs), Field Programmable Gate Arrays (FPGAs), and Deep Learning Processing Units (DPUs). However, further reductions in latency can be observed by combining these units. In this paper, partitioning CNN inference across DPU and GPU (Split CNN Inference) is proposed. The first partition runs on the AI engines (DPU) of a Versal VCK190, which consists of initial CNN layers processing the input images. The DPU processes the first partition near the source of the data. Pipelined asynchronously, a GPU runs the remaining layers. The GPU (NVIDIA RTX 2080) processes the second partition, albeit having reduced the data transfer between the data source (storage/camera) and the GPU. Furthermore, a Graph Neural Network (GNN)-based partition index prediction method is proposed to automate the partitioning of CNNs needed for the Split Inference. Well established models such as LeNet-5, ResNet18/50/101/152, VGG16, and MobileNetv2 are analyzed. Results demonstrate up to 2.48x latency improvement over DPU-only execution and up to 3.37x over GPU-only execution. The trained GNN model splits the layers between the appropriate devices with 96.27% accuracy.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes partitioning CNN inference across a DPU on the Versal VCK190 (initial layers on AI Engines) and an RTX 2080 GPU (remaining layers), executed asynchronously in a pipeline to reduce data movement. A Graph Neural Network is trained to predict the optimal layer index at which to split a given CNN. Experiments on LeNet-5, ResNet18/50/101/152, VGG16 and MobileNetv2 report up to 2.48× latency reduction versus DPU-only execution and 3.37× versus GPU-only execution, together with 96.27 % accuracy for the GNN predictor.
Significance. If the measured speedups are reproducible and the GNN predictor generalizes, the hybrid split approach could provide a practical route to lower-latency edge inference by exploiting complementary strengths of DPU and GPU. The automation component is a constructive contribution, but the current evidence is confined to one hardware pair and a narrow set of models, so the broader impact remains conditional on further validation.
major comments (3)
- [Abstract and Results] Abstract and Results sections: the headline latency claims (2.48× over DPU-only, 3.37× over GPU-only) rest on single-point end-to-end timing measurements without reported error bars, number of runs, warm-up protocol or ablation of PCIe transfer and synchronization overheads; these omissions are load-bearing for the central performance assertion.
- [GNN-based Partition Prediction] GNN partition predictor: the reported 96.27 % accuracy is given without description of the training corpus (which models and layer features were used), validation split, or accuracy on architectures not seen during training, undermining the claim that the method automates partitioning reliably.
- [Evaluation Setup] Evaluation: no cross-device, cross-resolution or cross-architecture experiments are presented; the optimal cut point depends on relative layer throughput, activation sizes and interconnect bandwidth, all of which are hardware- and model-specific, so the reported factors and automation claim cannot be assumed to hold beyond the Versal VCK190 + RTX 2080 pair.
minor comments (2)
- Figure captions and text should explicitly state the input resolution and batch size used for all timing measurements.
- The manuscript would benefit from a concise table summarizing per-model split indices chosen by the GNN and the corresponding measured latencies.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major point below and have revised the manuscript to incorporate additional details, statistical reporting, and clarifications on scope and limitations.
read point-by-point responses
-
Referee: [Abstract and Results] Abstract and Results sections: the headline latency claims (2.48× over DPU-only, 3.37× over GPU-only) rest on single-point end-to-end timing measurements without reported error bars, number of runs, warm-up protocol or ablation of PCIe transfer and synchronization overheads; these omissions are load-bearing for the central performance assertion.
Authors: We agree that the performance results require statistical rigor and overhead analysis to be fully convincing. In the revised manuscript we will report results from 100 runs per configuration after a 10-inference warm-up, include mean latency with standard deviation and error bars in all figures and tables, and add an explicit ablation isolating PCIe transfer time and synchronization overhead from the end-to-end latency. These additions directly address the load-bearing omissions noted. revision: yes
-
Referee: [GNN-based Partition Prediction] GNN partition predictor: the reported 96.27 % accuracy is given without description of the training corpus (which models and layer features were used), validation split, or accuracy on architectures not seen during training, undermining the claim that the method automates partitioning reliably.
Authors: We acknowledge that the GNN section lacked necessary methodological detail. The revised version will expand this section to describe the training corpus (layer features including type, dimensions, FLOPs and activation sizes extracted from LeNet-5, all ResNet variants, VGG16 and MobileNetv2), the 80/20 train/validation split, training hyperparameters, and accuracy measured on held-out model architectures not present in the training set. This will substantiate the automation claim. revision: yes
-
Referee: [Evaluation Setup] Evaluation: no cross-device, cross-resolution or cross-architecture experiments are presented; the optimal cut point depends on relative layer throughput, activation sizes and interconnect bandwidth, all of which are hardware- and model-specific, so the reported factors and automation claim cannot be assumed to hold beyond the Versal VCK190 + RTX 2080 pair.
Authors: We agree that the optimal split point is hardware- and model-dependent and that broader validation would strengthen the work. The revision will add a dedicated Limitations subsection that explicitly states the results apply to the Versal VCK190 + RTX 2080 pair, discusses how layer throughput, activation sizes and interconnect bandwidth affect the cut point, and notes that the GNN predictor can be retrained for new platforms. We cannot perform additional cross-device or cross-architecture experiments in this revision due to hardware availability constraints. revision: partial
- Performing additional cross-device, cross-resolution and cross-architecture experiments on hardware platforms other than the Versal VCK190 + RTX 2080 pair
Circularity Check
No significant circularity; claims rest on direct empirical timings and standard GNN training
full rationale
The paper's core results (latency speedups and GNN accuracy) derive from end-to-end hardware measurements on the Versal VCK190 + RTX 2080 pair for the listed CNNs, with the GNN trained to predict partition indices and its 96.27% accuracy evaluated on that data. No equation or claim reduces a 'prediction' to a fitted input by construction, no self-citation chain supports a uniqueness theorem or ansatz, and the derivation chain is self-contained via experimental validation rather than tautological re-labeling of inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption CNN layers can be partitioned and executed independently on separate accelerators with only data-transfer overhead
Reference graph
Works this paper leans on
-
[1]
Yann LeCun, Léon Bottou, Yoshua Bengio, and Patrick Haffner. 2002. Gradient- based learning applied to document recognition.Proceedings of the IEEE, 86, 11, 2278–2324
2002
-
[2]
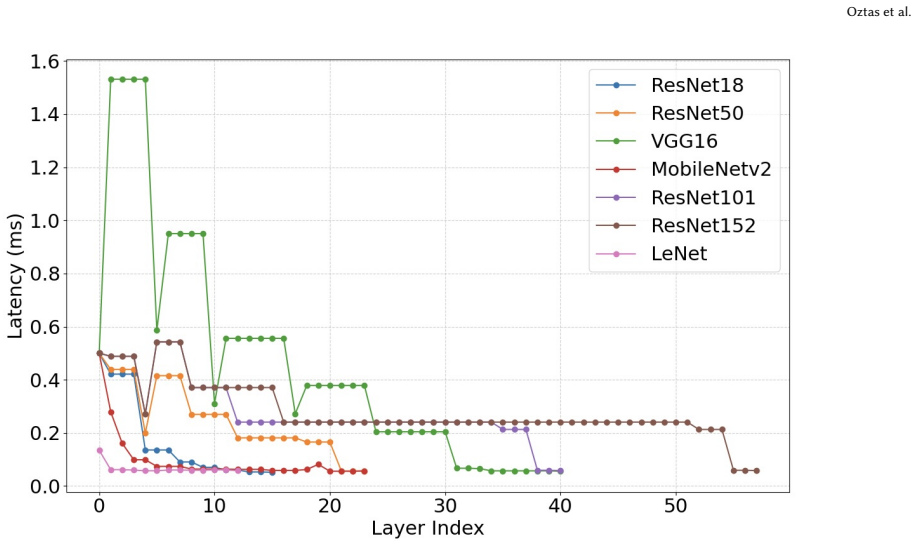
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. 2009. Imagenet: a large-scale hierarchical image database. In2009 IEEE conference on computer vision and pattern recognition. Ieee, 248–255. Oztas et al. Figure 9: Ground truth and predicted latency results for the VGG16 model. Table 2: GNN Evaluation Results Metric Name Latency Model ...
2009
-
[3]
Olga Russakovsky et al. 2015. Imagenet large scale visual recognition challenge. International journal of computer vision, 115, 3, 211–252
2015
-
[4]
Bipin Gaikwad and Abhijit Karmakar. 2021. Smart surveillance system for real-time multi-person multi-camera tracking at the edge.Journal of real-time image processing, 18, 6, 1993–2007
2021
-
[5]
Daniele Berardini, Lucia Migliorelli, Alessandro Galdelli, Emanuele Frontoni, Adriano Mancini, and Sara Moccia. 2024. A deep-learning framework running on edge devices for handgun and knife detection from indoor video-surveillance cameras.Multimedia Tools and Applications, 83, 7, 19109–19127
2024
-
[6]
Daniele Berardini, Adriano Mancini, Primo Zingaretti, and Sara Moccia. 2021. Edge artificial intelligence: a multi-camera video surveillance application. In International Design Engineering Technical Conferences and Computers and Infor- mation in Engineering Conference. Vol. 85437. American Society of Mechanical Engineers, V007T07A006
2021
-
[7]
Wenzhe Shi, Jose Caballero, Ferenc Huszár, Johannes Totz, Andrew P Aitken, Rob Bishop, Daniel Rueckert, and Zehan Wang. 2016. Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network. InProceedings of the IEEE conference on computer vision and pattern recognition, 1874–1883
2016
-
[8]
Norman P Jouppi et al. 2017. In-datacenter performance analysis of a tensor processing unit. InProceedings of the 44th annual international symposium on computer architecture, 1–12
2017
-
[9]
Google Cloud Blog. 2025. Introducing trillium, sixth-generation tpus. Blog post. Google. (Mar. 25, 2025). Retrieved Mar. 25, 2025 from https://cloud.google.com /blog/products/compute/introducing-trillium-6th-gen-tpus
2025
-
[10]
Gupta Alok. 2020. Architecture apocalypse dream architecture for deep learning inference and compute-versal ai core.Embedded World, 10
2020
-
[11]
Jude Haris, Perry Gibson, José Cano, Nicolas Bohm Agostini, and David Kaeli
-
[12]
Secda-tflite: a toolkit for efficient development of fpga-based dnn accel- erators for edge inference.Journal of Parallel and Distributed Computing, 173, 140–151
-
[13]
Ehsan Aghapour, Dolly Sapra, Andy Pimentel, and Anuj Pathania. 2022. Cpu- gpu layer-switched low latency cnn inference. In2022 25th Euromicro Confer- ence on Digital System Design (DSD). IEEE, 324–331
2022
-
[14]
Fabian Kreß, Tim Hotfilter, Julian Hoefer, Tanja Harbaum, Juergen Becker, et al
-
[15]
In2024 IEEE Computer Society Annual Symposium on VLSI (ISVLSI)
Automated deep neural network inference partitioning for distributed embedded systems. In2024 IEEE Computer Society Annual Symposium on VLSI (ISVLSI). IEEE, 39–44
-
[16]
Jiyoung An, Esmerald Aliaj, and Sang-Woo Jun. 2023. Precog: near-storage accelerator for heterogeneous cnn inference. In2023 IEEE 34th International Conference on Application-specific Systems, Architectures and Processors (ASAP). IEEE, 45–52
2023
-
[17]
Yongjoo Jang, Sejin Kim, Daehoon Kim, Sungjin Lee, and Jaeha Kung. 2021. Deep partitioned training from near-storage computing to dnn accelerators. IEEE Computer Architecture Letters, 20, 1, 70–73
2021
-
[18]
Hongsun Jang, Jaeyong Song, Jaewon Jung, Jaeyoung Park, Youngsok Kim, and Jinho Lee. 2024. Smart-infinity: fast large language model training using near-storage processing on a real system. In2024 IEEE International Symposium on High-Performance Computer Architecture (HPCA). IEEE, 345–360
2024
-
[19]
Ao Zhou, Jianlei Yang, Tong Qiao, Yingjie Qi, Zhi Yang, Weisheng Zhao, and Chunming Hu. 2024. Graph neural networks automated design and deployment on device-edge co-inference systems. InProceedings of the 61st ACM/IEEE Design Automation Conference, 1–6
2024
-
[20]
Walther Carballo-Hernández, Maxime Pelcat, and François Berry. 2023. Au- tomatic cnn model partitioning for gpu/fpga-based embedded heterogeneous accelerators using geometric programming.Journal of Signal Processing Sys- tems, 95, 10, 1203–1218
2023
- [21]
-
[22]
Nick Erickson, Jonas Mueller, Alexander Shirkov, Hang Zhang, Pedro Larroy, Mu Li, and Alexander Smola. 2020. Autogluon-tabular: robust and accurate automl for structured data.arXiv preprint arXiv:2003.06505
work page internal anchor Pith review arXiv 2020
-
[23]
Sepp Hochreiter and Jürgen Schmidhuber. 1997. Long short-term memory. Neural computation, 9, 8, 1735–1780
1997
-
[24]
AMD. [n. d.] Dpucvdx8g product guide (pg389). AMD. Retrieved Aug. 31, 2025 from https://docs.amd.com/r/en-US/pg389-dpucvdx8g
2025
-
[25]
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. 2016. Deep residual learning for image recognition. InProceedings of the IEEE conference on computer vision and pattern recognition, 770–778
2016
-
[26]
Karen Simonyan and Andrew Zisserman. 2014. Very deep convolutional net- works for large-scale image recognition.arXiv preprint arXiv:1409.1556. DPU or GPU for Accelerating Neural Networks Inference – Why not both? Split CNN Inference
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[27]
Mark Sandler, Andrew Howard, Menglong Zhu, Andrey Zhmoginov, and Liang- Chieh Chen. 2018. Mobilenetv2: inverted residuals and linear bottlenecks. In Proceedings of the IEEE conference on computer vision and pattern recognition, 4510–4520
2018
-
[28]
MLCommons. [n. d.] Mlperf inference: edge benchmark suite. MLCommons. Retrieved Aug. 31, 2025 from https://mlcommons.org/benchmarks/inference-e dge/
2025
-
[29]
PyTorch. [n. d.] Model zoo — pytorch/serve master documentation. PyTorch. Retrieved Mar. 31, 2025 from https://docs.pytorch.org/serve/model_zoo.html
2025
-
[30]
Keras Team. [n. d.] Keras documentation: keras applications. Keras. Retrieved Mar. 31, 2025 from https://keras.io/api/applications/
2025
-
[31]
Xilinx. [n. d.] Model zoo table — vitis ai 3.5 reference documentation. Xilinx. Retrieved Mar. 31, 2025 from https://xilinx.github.io/Vitis-AI/3.5/html/docs/re ference/-/ModelZoo_Github_web.htm
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.