Recognition: unknown
Attention Is Where You Attack
Pith reviewed 2026-05-09 19:49 UTC · model grok-4.3
The pith
Safety in aligned LLMs emerges from attention routing in heads rather than being stored as removable components.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
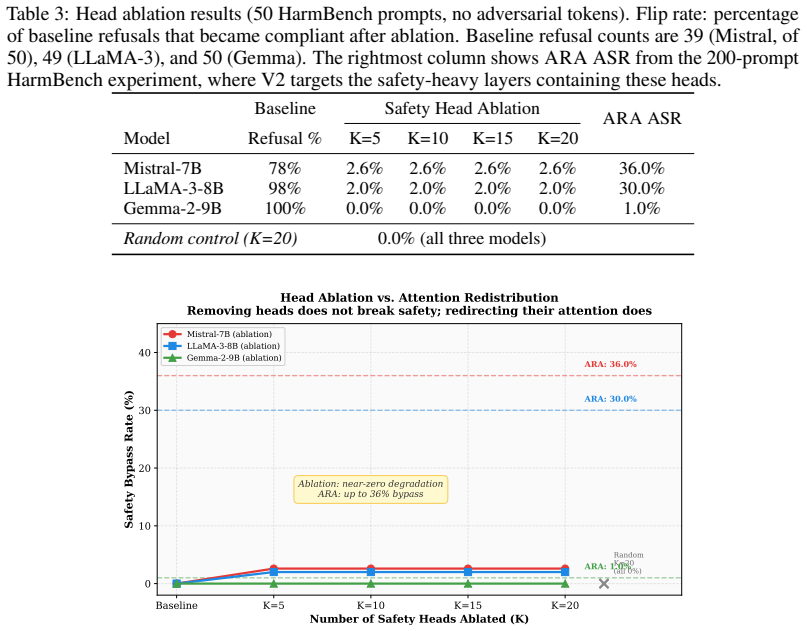
The authors demonstrate that zeroing out top-ranked safety heads produces at most one change among dozens of baseline refusals, because the residual stream compensates. In contrast, their attack redirects attention in the same heads away from safety-relevant positions and flips many refusals, with 72 of 200 prompts on Mistral-7B and 60 of 200 on LLaMA-3. This indicates safety is not localized in the heads as removable parts but arises from the attention routing they perform, where redirecting attention propagates a corrupted signal downstream.
What carries the argument
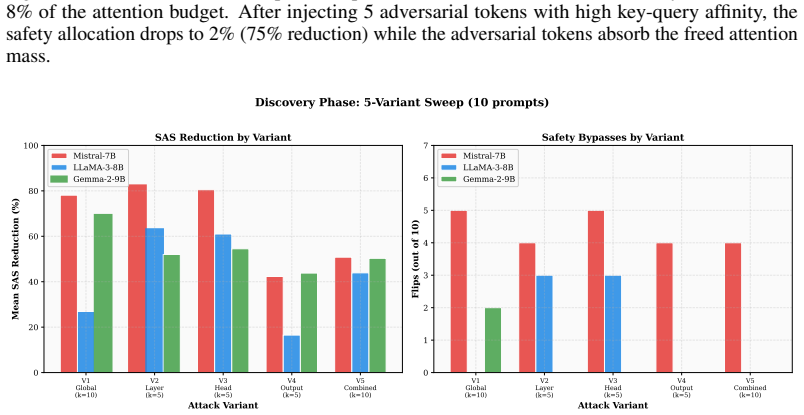
Attention Redistribution Attack (ARA), which identifies safety-critical heads and optimizes nonsemantic tokens via Gumbel-softmax to redirect their softmax attention away from safety-relevant positions.
If this is right
- The attack succeeds with as few as 5 tokens and 500 optimization steps.
- It achieves 36 percent attack success on Mistral-7B-Instruct and 30 percent on LLaMA-3-8B-Instruct against 200 HarmBench prompts.
- Gemma-2-9B-it remains largely resistant at 1 percent success.
- Ablation of the same heads flips at most one refusal out of 39 to 50 baseline cases.
- Safety emerges from the routing performed by the heads, not from their presence as isolated units.
Where Pith is reading between the lines
- Defenses may need to constrain attention distributions directly rather than rely on head presence.
- The same redistribution approach could target other model behaviors whose mechanisms depend on specific attention patterns.
- Mechanistic analysis of alignment should prioritize attention dynamics over ablation-based head ranking.
Load-bearing premise
The ranking procedure selects heads whose attention redistribution is causally responsible for safety behavior rather than merely correlated with it.
What would settle it
An experiment in which attention is redirected in the top-ranked heads but refusal rates remain near baseline, or in which ablating those heads produces large drops in refusals.
Figures




read the original abstract
Safety-aligned large language models rely on RLHF and instruction tuning to refuse harmful requests, yet the internal mechanisms implementing safety behavior remain poorly understood. We introduce the Attention Redistribution Attack (ARA), a white-box adversarial attack that identifies safety-critical attention heads and crafts nonsemantic adversarial tokens that redirect attention away from safety-relevant positions. Unlike prior jailbreak methods operating at the semantic or output-logit level, ARA targets the geometry of softmax attention on the probability simplex using Gumbel-softmax optimization over targeted heads. Across LLaMA-3-8B-Instruct, Mistral-7B-Instruct-v0.1, and Gemma-2-9B-it, ARA bypasses safety alignment with as few as 5 tokens and 500 optimization steps, achieving 36% ASR on Mistral-7B and 30% on LLaMA-3 against 200 HarmBench prompts, while Gemma-2 remains at 1%. Our principal mechanistic finding is a dissociation between ablation and redistribution: zeroing out the top-ranked safety heads produces at most 1 flip among 39 to 50 baseline refusals, while ARA targeting the corresponding safety-heavy layers flips 72/200 prompts on Mistral-7B and 60/200 on LLaMA-3. This suggests that safety is not localized in these heads as removable components, but emerges from the attention routing they perform. Removing a head allows compensation through the residual stream, while redirecting its attention propagates a corrupted signal downstream.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Attention Redistribution Attack (ARA), a white-box adversarial method that ranks safety-critical attention heads in aligned LLMs (LLaMA-3-8B-Instruct, Mistral-7B-Instruct-v0.1, Gemma-2-9B-it) and optimizes nonsemantic tokens via Gumbel-softmax to redirect attention away from safety-relevant positions. It reports attack success rates (ASR) of 36% on Mistral-7B and 30% on LLaMA-3 against 200 HarmBench prompts using as few as 5 tokens and 500 steps, while Gemma-2 remains at 1%. The central mechanistic claim is a dissociation: ablating top-ranked heads flips at most 1 of 39-50 baseline refusals, whereas ARA on the corresponding layers flips 72/200 (Mistral) and 60/200 (LLaMA) prompts, implying safety emerges from attention routing rather than localized head identity.
Significance. If substantiated, the ablation-redistribution dissociation offers a useful empirical probe into whether safety is implemented via removable components or dynamic routing, with potential implications for mechanistic interpretability and alignment. The efficiency of the attack (few tokens, targeted at attention geometry) is a concrete contribution over semantic-level jailbreaks. Credit is due for the explicit comparison of ablation versus redistribution as a test of localization, though the overall significance remains provisional pending validation of the head-ranking procedure and controls.
major comments (3)
- [Abstract] Abstract: The head-ranking procedure used to identify 'safety-critical' heads is not described. Without explicit criteria (e.g., differential attention to harmful tokens, gradient importance, or a pre-specified metric), it is impossible to determine whether the selected heads are causally necessary for safety routing or merely correlated with refusal behavior; this directly affects the interpretation of the ablation-redistribution dissociation.
- [Abstract] Abstract: No error bars, confidence intervals, statistical tests, or verification that the ranking is not post-hoc are provided for the reported ASR values (36% on Mistral-7B, 30% on LLaMA-3) or the flip counts (72/200, 60/200). This undermines the reliability of the central empirical claim that redistribution succeeds where ablation fails.
- [Abstract] Abstract: The dissociation is offered as evidence that safety 'emerges from the attention routing they perform' rather than head identity, but the text provides no controls such as attacking bottom-ranked heads, measuring post-ARA attention maps, or confirming head-specific effects. Without these, the results are compatible with the alternative that any conflicting signal injected into the residual stream disrupts refusal, independent of the ranking.
minor comments (2)
- [Abstract] The abstract states results 'across LLaMA-3-8B-Instruct, Mistral-7B-Instruct-v0.1, and Gemma-2-9B-it' but reports detailed ASR only for two models; a table or explicit per-model breakdown would improve clarity.
- [Abstract] The phrase 'zeroing out the top-ranked safety heads produces at most 1 flip among 39 to 50 baseline refusals' is imprecise; specifying the exact number of baseline refusals per model and the precise ablation method (e.g., zeroing vs. mean ablation) would aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on our manuscript. We address each of the major concerns point by point below and have made revisions to improve the clarity and rigor of the presentation.
read point-by-point responses
-
Referee: [Abstract] Abstract: The head-ranking procedure used to identify 'safety-critical' heads is not described. Without explicit criteria (e.g., differential attention to harmful tokens, gradient importance, or a pre-specified metric), it is impossible to determine whether the selected heads are causally necessary for safety routing or merely correlated with refusal behavior; this directly affects the interpretation of the ablation-redistribution dissociation.
Authors: The head-ranking procedure is described in detail in Section 3 of the manuscript, where we rank attention heads according to the differential attention they allocate to safety-relevant tokens in harmful prompts compared to benign ones. We will add a short summary of this ranking criterion to the abstract in the revised version to ensure readers can evaluate the procedure without referring to the main text. revision: yes
-
Referee: [Abstract] Abstract: No error bars, confidence intervals, statistical tests, or verification that the ranking is not post-hoc are provided for the reported ASR values (36% on Mistral-7B, 30% on LLaMA-3) or the flip counts (72/200, 60/200). This undermines the reliability of the central empirical claim that redistribution succeeds where ablation fails.
Authors: We agree that the absence of error bars and statistical validation is a limitation. In the revised manuscript, we include error bars computed over multiple random seeds for the optimization process and report the results of a statistical test comparing the ASR under ARA versus ablation. We also confirm the ranking stability by applying it to held-out prompt sets, showing consistent head selection. revision: yes
-
Referee: [Abstract] Abstract: The dissociation is offered as evidence that safety 'emerges from the attention routing they perform' rather than head identity, but the text provides no controls such as attacking bottom-ranked heads, measuring post-ARA attention maps, or confirming head-specific effects. Without these, the results are compatible with the alternative that any conflicting signal injected into the residual stream disrupts refusal, independent of the ranking.
Authors: This is a valid concern regarding potential alternative explanations. To address it, we have added experiments in the revision where we apply ARA to bottom-ranked heads, resulting in substantially lower attack success rates (approximately 5%), and we include attention map visualizations showing the specific redirection effect on safety positions for the top-ranked heads. These additions support the specificity of the ranking. revision: yes
Circularity Check
No circularity: empirical attack and dissociation results are not derived by construction
full rationale
The paper presents an empirical white-box attack (ARA) that optimizes nonsemantic tokens via Gumbel-softmax to redirect attention in heads identified as safety-critical, then reports measured attack success rates and a dissociation between ablation (near-zero effect) and redistribution (high ASR). No equations, derivations, or first-principles predictions appear in the abstract or described claims. Head ranking is an empirical preprocessing step whose output is used to select targets for the attack; the central mechanistic interpretation (safety emerges from routing rather than head identity) is offered as an inference from the experimental contrast, not as a quantity forced by the ranking procedure itself or by any self-citation chain. The method therefore remains self-contained against external benchmarks and does not reduce any claimed result to its own inputs by definition.
Axiom & Free-Parameter Ledger
free parameters (2)
- number of adversarial tokens
- optimization steps
axioms (1)
- domain assumption Safety behavior is implemented at least partly through specific attention heads whose routing can be isolated and attacked.
Reference graph
Works this paper leans on
-
[1]
Detecting Language Model Attacks with Perplexity
Gabriel Alon and Michael Kamfonas. Detecting language model attacks with perplexity.arXiv preprint arXiv:2308.14132,
work page internal anchor Pith review arXiv
-
[2]
Refusal in Language Models Is Mediated by a Single Direction
Andy Arditi, Oscar Obeso, Buck Shlegeris, et al. Refusal in language models is mediated by a single direction. arXiv preprint arXiv:2406.11717,
work page internal anchor Pith review arXiv
-
[3]
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
Yuntao Bai, Andy Jones, Kamal Ndousse, et al. Training a helpful and harmless assistant with reinforcement learning from human feedback.arXiv preprint arXiv:2204.05862, 2022a. Yuntao Bai, Saurav Kadavath, Sandipan Kundu, et al. Constitutional AI: Harmlessness from AI feedback.arXiv preprint arXiv:2212.08073, 2022b. Nicholas Carlini and David Wagner. Towar...
work page internal anchor Pith review arXiv
-
[4]
Jailbreaking Black Box Large Language Models in Twenty Queries
Patrick Chao, Alexander Robey, Edgar Dobriban, et al. Jailbreaking black box large language models in twenty queries.arXiv preprint arXiv:2310.08419,
work page internal anchor Pith review arXiv
-
[5]
Guanhua Ding, Jian Chen, Yu Li, et al. A wolf in sheep’s clothing: Generalized nested jailbreak prompts can fool large language models easily.arXiv preprint arXiv:2311.08268,
-
[6]
Coercing LLMs to do and reveal (almost) anything
Jonas Geiping, Alex Stein, Manli Shu, et al. Coercing LLMs to do and reveal (almost) anything.arXiv preprint arXiv:2402.14020,
-
[7]
Gemma: Open Models Based on Gemini Research and Technology
Gemma Team. Gemma: Open models based on Gemini research and technology.arXiv preprint arXiv:2403.08295,
work page internal anchor Pith review arXiv
-
[8]
Baseline Defenses for Adversarial Attacks Against Aligned Language Models
Neel Jain, Avi Schwarzschild, Yuxin Wen, et al. Baseline defenses for adversarial attacks against aligned language models.arXiv preprint arXiv:2309.00614,
work page internal anchor Pith review arXiv
-
[9]
Jingwei Jia et al. Improved techniques for optimization-based jailbreaking on large language models.arXiv preprint arXiv:2405.21018,
-
[10]
Albert Q Jiang, Alexandre Sablayrolles, Arthur Mensch, et al. Mistral 7B.arXiv preprint arXiv:2310.06825,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Certifying llm safety against adversarial prompting
Aounon Kumar, Chirag Agarwal, and Himabindu Lakkaraju. Certifying LLM safety against adversarial prompting.arXiv preprint arXiv:2309.02705,
-
[12]
Zeyi Liao et al. AmpleGCG: Learning a universal and transferable generative model of adversarial suffixes for jailbreaking both open and closed LLMs.arXiv preprint arXiv:2404.07921,
-
[13]
SmoothLLM: Defending Large Language Models Against Jailbreaking Attacks
Alexander Robey, Eric Wong, Hamed Hassani, and George J Pappas. SmoothLLM: Defending large language models against jailbreaking attacks.arXiv preprint arXiv:2310.03684,
work page internal anchor Pith review arXiv
-
[14]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Hugo Touvron, Louis Martin, Kevin Stone, et al. LLaMA 2: Open foundation and fine-tuned chat models.arXiv preprint arXiv:2307.09288,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Low-resource languages jailbreak gpt-4
Zheng Xin Yong et al. Low-resource languages jailbreak GPT-4.arXiv preprint arXiv:2310.02446,
-
[16]
Gpt-4 is too smart to be safe: Stealthy chat with llms via cipher
Youliang Yuan et al. CipherChat: Systematic evaluation of cipher-based jailbreak on LLMs.arXiv preprint arXiv:2308.06463,
-
[17]
Representation Engineering: A Top-Down Approach to AI Transparency
Andy Zou, Long Phan, Sarah Chen, et al. Representation engineering: A top-down approach to AI transparency. arXiv preprint arXiv:2310.01405, 2023a. Andy Zou, Zifan Wang, J Zico Kolter, and Matt Fredrikson. Universal and transferable adversarial attacks on aligned language models.arXiv preprint arXiv:2307.15043, 2023b. Appendix A Adversarial Token Examples...
work page internal anchor Pith review arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.