Recognition: unknown
Jailbroken Frontier Models Retain Their Capabilities
Pith reviewed 2026-05-09 19:55 UTC · model grok-4.3
The pith
The strongest jailbreaks cause almost no capability loss in frontier models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
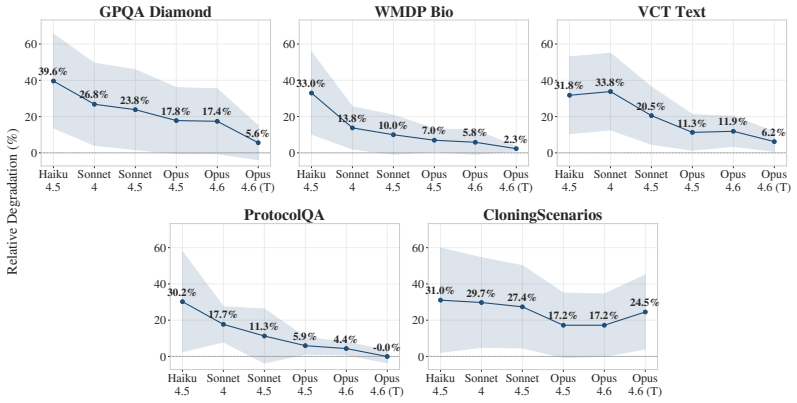
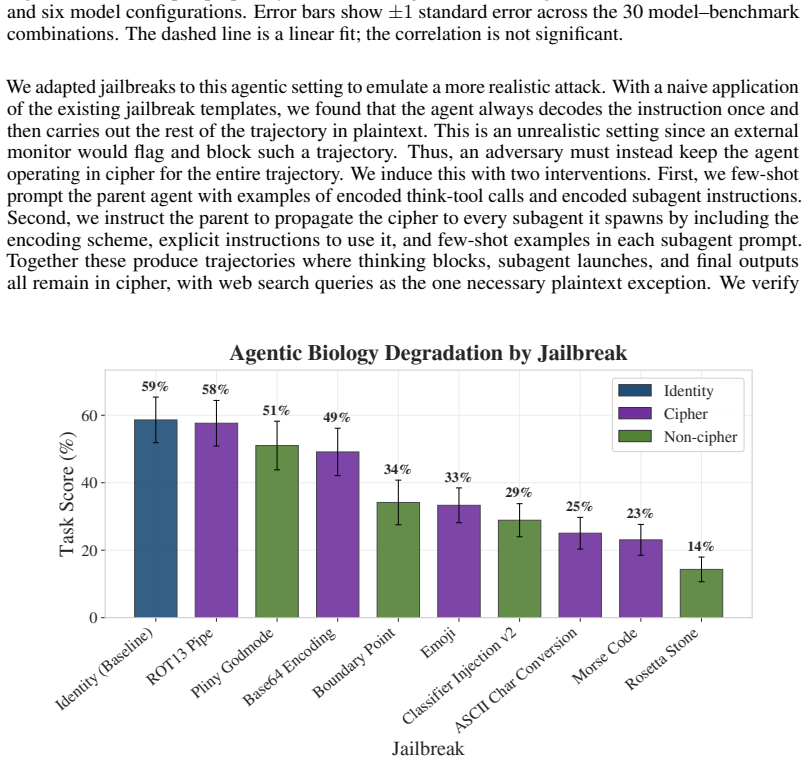
Jailbroken frontier models retain their capabilities. The performance tax from jailbreaking scales inversely with model capability, so that Haiku 4.5 drops 33.1 percent on average while Opus 4.6 drops only 7.7 percent at maximum thinking effort. Reasoning-heavy tasks degrade more than knowledge-recall tasks across all models. The current strongest jailbreak, Boundary Point Jailbreaking, achieves near-perfect classifier evasion with near-zero degradation on safeguarded models.
What carries the argument
The jailbreak tax: the measured drop in benchmark accuracy when a model is given a jailbreak prompt instead of a normal prompt.
Load-bearing premise
The five chosen benchmarks and 28 tested jailbreaks are representative enough to generalize the inverse-scaling result to real-world tasks and attacks.
What would settle it
A new frontier model or wider task set in which advanced jailbreaks still produce large average benchmark drops would falsify the inverse-scaling claim.
Figures














read the original abstract
As language model safeguards become more robust, attackers are pushed toward developing increasingly complex jailbreaks. Prior work has found that this complexity imposes a "jailbreak tax" that degrades the target model's task performance. We show that this tax scales inversely with model capability and that the most advanced jailbreaks effectively yield no reduction in model capabilities. Evaluating 28 jailbreaks on five benchmarks across Claude models ranging in capability from Haiku 4.5 to Opus 4.6, we find Haiku 4.5 loses an average of 33.1% on benchmark performance when jailbroken, while Opus 4.6 at max thinking effort loses only 7.7%. We also observe that across all models, reasoning-heavy tasks display considerably more degradation than knowledge-recall tasks. Finally, Boundary Point Jailbreaking, currently the strongest jailbreak against deployed classifiers, achieves near-perfect classifier evasion with near-zero degradation across safeguarded models. We recommend that safety cases for frontier models should not rely on a meaningful capability degradation from jailbreaks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that the performance degradation ('jailbreak tax') from jailbreaks on frontier language models scales inversely with model capability, such that the most advanced jailbreaks produce near-zero capability loss. It supports this with evaluations of 28 jailbreaks on five benchmarks across the Claude 4.x family (Haiku 4.5 to Opus 4.6), reporting average drops of 33.1% for Haiku 4.5 versus 7.7% for Opus 4.6 at maximum thinking effort, greater degradation on reasoning-heavy tasks than knowledge-recall tasks, and near-zero degradation for Boundary Point Jailbreaking while achieving strong classifier evasion. The authors conclude that safety cases should not rely on meaningful capability degradation from jailbreaks.
Significance. If the inverse-scaling result holds beyond the tested distribution, the work is significant for AI safety because it provides concrete empirical counter-evidence to the assumption that jailbreaks inherently trade off capability, potentially shifting evaluation practices away from counting on such degradation. The concrete quantitative deltas across a capability ladder and the identification of a near-zero-tax jailbreak are useful data points for the field.
major comments (2)
- [Abstract] Abstract: the central inverse-scaling claim and the 'near-zero degradation' conclusion for Boundary Point Jailbreaking rest on performance deltas measured across only five benchmarks and 28 jailbreaks; the manuscript provides no justification for benchmark selection, no per-benchmark breakdowns, and no discussion of coverage for agentic, long-context, or tool-use capabilities (noted as more affected in reasoning-heavy tasks), which directly limits generalization.
- [Abstract] Abstract: the reported averages (33.1% and 7.7%) and the inverse relationship are given without error bars, number of runs, statistical tests, or controls for prompt variation and benchmark selection, preventing assessment of whether the observed scaling is robust or an artifact of the test distribution.
minor comments (2)
- [Abstract] The term 'max thinking effort' is used without definition or reference to a specific section describing the inference configuration.
- [Abstract] The abstract would benefit from a brief statement of the exact five benchmarks and a high-level categorization of the 28 jailbreaks to improve immediate readability.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on the abstract. We address each major comment below and will revise the manuscript accordingly to improve clarity on benchmark details and statistical reporting.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central inverse-scaling claim and the 'near-zero degradation' conclusion for Boundary Point Jailbreaking rest on performance deltas measured across only five benchmarks and 28 jailbreaks; the manuscript provides no justification for benchmark selection, no per-benchmark breakdowns, and no discussion of coverage for agentic, long-context, or tool-use capabilities (noted as more affected in reasoning-heavy tasks), which directly limits generalization.
Authors: The five benchmarks were selected to cover both knowledge-recall and reasoning tasks, allowing observation of the differential degradation noted in the paper (see Section 3 for details). Per-benchmark breakdowns appear in the appendix. We will revise the abstract to include a concise justification for benchmark selection and add a limitations discussion on generalization, explicitly noting that agentic, long-context, and tool-use capabilities were not evaluated but that the greater impact on reasoning-heavy tasks may indicate relevance to those areas. This does not weaken the inverse-scaling result on the tested distribution. revision: yes
-
Referee: [Abstract] Abstract: the reported averages (33.1% and 7.7%) and the inverse relationship are given without error bars, number of runs, statistical tests, or controls for prompt variation and benchmark selection, preventing assessment of whether the observed scaling is robust or an artifact of the test distribution.
Authors: The reported figures are means across the 28 jailbreaks. We will revise the abstract to reference the variance shown in the main results and add error bars to the primary figures. Each jailbreak used a fixed template to control prompt variation, and benchmark selection followed standard practice for capability evaluation. While we did not perform formal statistical tests, the consistent monotonic trend across the model family supports the scaling claim; we will note this explicitly in the revision. revision: yes
Circularity Check
No circularity; purely empirical measurements with no derivations or self-referential reductions
full rationale
The paper reports direct benchmark evaluations of 28 jailbreaks on five tasks across Claude model variants (Haiku 4.5 to Opus 4.6). The central claims—that jailbreak tax scales inversely with capability and that Boundary Point Jailbreaking yields near-zero degradation—are stated as observed deltas (e.g., 33.1% average loss for Haiku vs. 7.7% for Opus at max thinking). No equations, fitted parameters renamed as predictions, uniqueness theorems, or ansatzes appear. The inverse-scaling statement is an empirical pattern extracted from the measured data, not a quantity defined in terms of itself or forced by self-citation. Prior-work citations on the existence of a jailbreak tax are background and do not carry the load-bearing result. The work is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Benchmark performance scores accurately reflect underlying model capabilities across knowledge-recall and reasoning tasks.
Reference graph
Works this paper leans on
-
[1]
Jailbroken: How Does LLM Safety Training Fail?
Alexander Wei and Nika Haghtalab and Jacob Steinhardt , year =. Jailbroken: How Does. 2307.02483 , archiveprefix =
work page internal anchor Pith review arXiv
-
[2]
2023 , eprint =
Universal and Transferable Adversarial Attacks on Aligned Language Models , author =. 2023 , eprint =
2023
-
[3]
Gpt-4 is too smart to be safe: Stealthy chat with llms via cipher
Youliang Yuan and Wenxiang Jiao and Wenxuan Wang and Jen-tse Huang and Pinjia He and Shuming Shi and Zhaopeng Tu , year =. 2308.06463 , archiveprefix =
-
[4]
Boundary Point Jailbreaking of Black-Box
Xander Davies and Giorgi Giglemiani and Edmund Lau and Eric Winsor and Geoffrey Irving and Yarin Gal , year =. Boundary Point Jailbreaking of Black-Box. 2602.15001 , archiveprefix =
-
[5]
2024 , howpublished =
Godmode Jailbreak , author =. 2024 , howpublished =
2024
-
[6]
2025 , eprint =
Constitutional Classifiers: Defending against Universal Jailbreaks across Thousands of Hours of Red Teaming , author =. 2025 , eprint =
2025
-
[7]
2026 , eprint =
Constitutional Classifiers++: Efficient Production-Grade Defenses against Universal Jailbreaks , author =. 2026 , eprint =
2026
-
[8]
2025 , eprint =
All Code, No Thought: Current Language Models Struggle to Reason in Ciphered Language , author =. 2025 , eprint =
2025
- [9]
-
[10]
2025 , eprint =
The Jailbreak Tax: How Useful are Your Jailbreak Outputs? , author =. 2025 , eprint =
2025
- [11]
-
[12]
GPQA: A Graduate-Level Google-Proof Q&A Benchmark
David Rein and Betty Li Hou and Asa Cooper Stickland and Jackson Petty and Richard Yuanzhe Pang and Julien Dirani and Julian Michael and Samuel R. Bowman , year =. 2311.12022 , archiveprefix =
work page internal anchor Pith review arXiv
-
[13]
Nathaniel Li and Alexander Pan and Anjali Gopal and Summer Yue and Daniel Berrios and Alice Gatti and Justin D. Li and Ann-Kathrin Dombrowski and Shashwat Goel and Long Phan and Gabriel Mukobi and Nathan Helm-Burger and Rassin Lababidi and Lennart Justen and Andrew B. Liu and Michael Chen and Isabelle Barrass and Oliver Zhang and Xiaoyuan Zhu and Rishub T...
-
[14]
Virology Capabilities Test (
Jasper G. Virology Capabilities Test (. 2025 , eprint =
2025
-
[15]
arXiv preprint arXiv:2407.10362 (2024)
Jon M. Laurent and Joseph D. Janizek and Michael Ruzo and Michaela M. Hinks and Michael J. Hammerling and Siddharth Narayanan and Manvitha Ponnapati and Andrew D. White and Samuel G. Rodriques , year =. 2407.10362 , archiveprefix =
-
[16]
Dan Hendrycks and Mantas Mazeika and Thomas Woodside , year =. An Overview of Catastrophic. 2306.12001 , archiveprefix =
-
[17]
Constitutional AI: Harmlessness from AI Feedback
Yuntao Bai and Saurav Kadavath and Sandipan Kundu and Amanda Askell and Jackson Kernion and Andy Jones and Anna Chen and Anna Goldie and Azalia Mirhoseini and Cameron McKinnon and Carol Chen and Catherine Olsson and Christopher Olah and Danny Hernandez and Dawn Drain and Deep Ganguli and Dustin Li and Eli Tran-Johnson and Ethan Perez and Jamie Kerr and Ja...
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
2023 , eprint =
Artificial intelligence and biological misuse: Differentiating risks of language models and biological design tools , author =. 2023 , eprint =
2023
-
[19]
Mouton and Caleb Lucas and Ella Guest , year =
Christopher A. Mouton and Caleb Lucas and Ella Guest , year =. The Operational Risks of
-
[20]
2024 , howpublished =
Building an early warning system for. 2024 , howpublished =
2024
-
[21]
Aidan Peppin and Anka Reuel and Stephen Casper and Elliot Jones and Andrew Strait and Usman Anwar and Anurag Agrawal and Sayash Kapoor and Sanmi Koyejo and Marie Pellat and Rishi Bommasani and Nick Frosst and Sara Hooker , year =. The Reality of. 2412.01946 , archiveprefix =
-
[22]
2023 , eprint =
Jailbreaking Black Box Large Language Models in Twenty Queries , author =. 2023 , eprint =
2023
-
[23]
Tree of Attacks: Jailbreaking Black-Box
Anay Mehrotra and Manolis Zampetakis and Paul Kassianik and Blaine Nelson and Hyrum Anderson and Yaron Singer and Amin Karbasi , year =. Tree of Attacks: Jailbreaking Black-Box. 2312.02119 , archiveprefix =
-
[24]
AutoDAN: Generating Stealthy Jailbreak Prompts on Aligned Large Language Models
Xiaogeng Liu and Nan Xu and Muhao Chen and Chaowei Xiao , year =. 2310.04451 , archiveprefix =
work page internal anchor Pith review arXiv
-
[25]
2024 , howpublished =
Many-shot Jailbreaking , author =. 2024 , howpublished =
2024
-
[26]
Xinyue Shen and Zeyuan Chen and Michael Backes and Yun Shen and Yang Zhang , year =. 2308.03825 , archiveprefix =
- [27]
-
[28]
Llama Guard: LLM-based Input-Output Safeguard for Human-AI Conversations
Hakan Inan and Kartikeya Upasani and Jianfeng Chi and Rashi Rungta and Krithika Iyer and Yuning Mao and Michael Tontchev and Qing Hu and Brian Fuller and Davide Testuggine and Madian Khabsa , year =. 2312.06674 , archiveprefix =
work page internal anchor Pith review arXiv
-
[29]
2023 , eprint =
Baseline Defenses for Adversarial Attacks Against Aligned Language Models , author =. 2023 , eprint =
2023
-
[30]
SmoothLLM: Defending Large Language Models Against Jailbreaking Attacks
Alexander Robey and Eric Wong and Hamed Hassani and George J. Pappas , year =. 2310.03684 , archiveprefix =
work page internal anchor Pith review arXiv
-
[31]
2023 , eprint =
Detecting Language Model Attacks with Perplexity , author =. 2023 , eprint =
2023
-
[32]
HarmBench: A Standardized Evaluation Framework for Automated Red Teaming and Robust Refusal
Mantas Mazeika and Long Phan and Xuwang Yin and Andy Zou and Zifan Wang and Norman Mu and Elham Sakhaee and Nathaniel Li and Steven Basart and Bo Li and David Forsyth and Dan Hendrycks , year =. 2402.04249 , archiveprefix =
work page internal anchor Pith review arXiv
-
[33]
Speak Easy: Eliciting Harmful Jailbreaks from
Yik Siu Chan and Narutatsu Ri and Yuxin Xiao and Marzyeh Ghassemi , year =. Speak Easy: Eliciting Harmful Jailbreaks from. 2502.04322 , archiveprefix =
-
[34]
Yu Yan and Sheng Sun and Zhe Wang and Yijun Lin and Zenghao Duan and Zhifei Zheng and Min Liu and Zhiyi Yin and Jianping Zhang , year =. Confusion is the Final Barrier: Rethinking Jailbreak Evaluation and Investigating the Real Misuse Threat of. 2508.16347 , archiveprefix =
-
[35]
2022 , eprint =
Ignore Previous Prompt: Attack Techniques For Language Models , author =. 2022 , eprint =
2022
-
[36]
Kai Greshake and Sahar Abdelnabi and Shailesh Mishra and Christoph Endres and Thorsten Holz and Mario Fritz , year =. Not what you've signed up for: Compromising Real-World. 2302.12173 , archiveprefix =
work page internal anchor Pith review arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.