Beyond Visual Fidelity: Benchmarking Super-Resolution Models for Large-Scale Remote Sensing Imagery via Downstream Task Integration
Pith reviewed 2026-05-09 20:21 UTC · model grok-4.3
The pith
Super-resolution models picked by PSNR or SSIM often deliver worse results on actual remote sensing tasks than lower-scoring alternatives.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
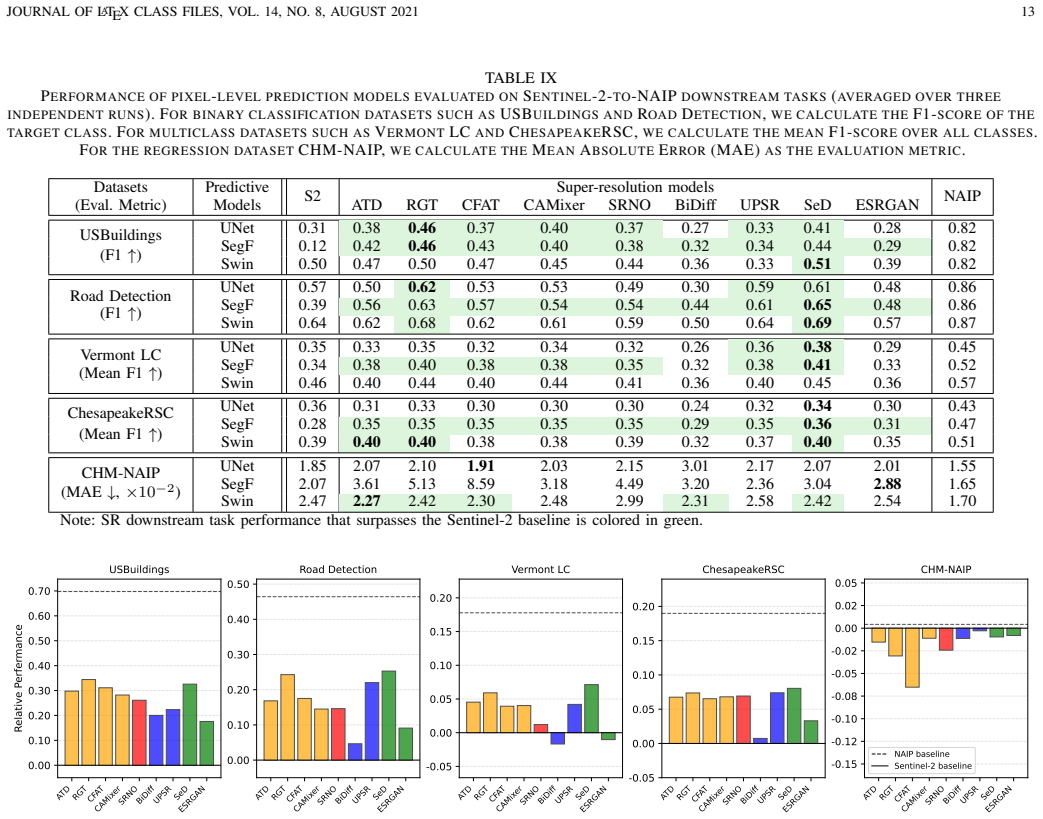
GeoSR-Bench supplies the first large-scale, task-integrated benchmark for super-resolution in remote sensing. It pairs low- and high-resolution imagery across diverse land covers and directly measures how nine different SR models affect performance on land cover segmentation, infrastructure mapping, and biophysical variable estimation. Results across GAN, transformer, neural operator, and diffusion architectures show that gains on traditional fidelity metrics do not reliably produce gains on these tasks and can even reduce task accuracy.
What carries the argument
GeoSR-Bench, a collection of spatially co-located, temporally aligned, and quality-controlled image pairs from 36,000 locations that links SR outputs to five downstream task models per scenario.
If this is right
- SR model rankings for remote sensing shift when evaluation uses task performance instead of fidelity metrics.
- Developers should optimize or fine-tune SR networks directly on task losses rather than generic reconstruction objectives.
- Diffusion and transformer SR models may outperform GANs on task utility even when trailing on PSNR or SSIM.
- New benchmarks must include downstream task integration to guide SR progress for Earth observation.
- Operational monitoring systems may achieve higher accuracy by selecting SR models according to task results rather than visual scores.
Where Pith is reading between the lines
- Incorporating auxiliary task losses during SR training could close the gap between visual fidelity and functional utility.
- The same evaluation mismatch likely exists in other domains such as medical or astronomical imaging where tasks matter more than pixel accuracy.
- Future SR research could test whether certain artifact types introduced by diffusion models systematically hurt change detection more than segmentation.
- Agencies running large-scale Earth observation pipelines might adopt task-integrated benchmarks to replace current fidelity-only leaderboards.
Load-bearing premise
The five chosen downstream tasks and the 36,000 image locations represent the practical value of super-resolved imagery in real Earth monitoring workflows.
What would settle it
A replication of the 270-setting experiments on a fresh geographic sample or with different task models that instead finds consistently strong positive correlations between PSNR/SSIM gains and downstream accuracy.
Figures









read the original abstract
Super-resolution (SR) techniques have made major advances in reconstructing high-resolution images from low-resolution inputs. The increased resolution provides visual enhancement and utility for monitoring tasks. In particular, SR has been increasingly developed for satellite-based Earth observation, with applications in urban planning, agriculture, ecology, and disaster response. However, existing SR studies and benchmarks typically use fidelity metrics such as PSNR or SSIM, whereas the true utility of super-resolved images lies in supporting downstream tasks such as land cover classification, biomass estimation, and change detection. To bridge this gap, we introduce GeoSR-Bench, a downstream task-integrated SR benchmark dataset to evaluate SR models beyond fidelity metrics. GeoSR-Bench comprises spatially co-located, temporally aligned, and quality-controlled image pairs from about 36,000 locations across diverse land covers, spanning resolutions from 500m to 0.6m. To the best of our knowledge, GeoSR-Bench is the first SR benchmark that directly connects improved image resolution from SR models with downstream Earth monitoring tasks, including land cover segmentation, infrastructure mapping, and biophysical variable estimation. Using GeoSR-Bench, we benchmark GAN, transformer, neural operator, and diffusion-based SR models on perceptual quality and downstream task performance. We conduct experiments with 270 settings, covering 2 cross-platform SR tasks, 9 SR models, 3 downstream task models, and 5 downstream tasks for each SR task. The results show that improvements in traditional SR metrics often do not correlate with gains in task performance, and the correlations can be negative, indicating that these metrics provide limited guidance for selecting superior models for downstream tasks. This reveals the need to integrate downstream tasks into SR model development and evaluation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces GeoSR-Bench, a large-scale benchmark with ~36,000 quality-controlled, co-located image pairs spanning resolutions from 500m to 0.6m across diverse land covers. It evaluates 9 SR models (including GAN, transformer, neural operator, and diffusion-based) in 2 cross-platform scenarios through 270 experimental settings with 3 downstream task models and 5 tasks per scenario (land cover segmentation, infrastructure mapping, biophysical variable estimation). The primary result is that traditional SR fidelity metrics (PSNR, SSIM) exhibit weak or negative correlations with downstream task performance gains.
Significance. The scale of the benchmark and the direct integration of downstream tasks represent a valuable contribution to the field of remote sensing image processing. If the observed lack of positive correlation between fidelity metrics and task utility is robust, this could significantly influence SR model development by prioritizing task performance over visual metrics, leading to more practical models for applications in urban planning, agriculture, and disaster response. The empirical benchmarking approach with held-out tasks is a strength.
major comments (2)
- [§3] §3 (Dataset): The description of the 36,000 locations and quality control process lacks explicit details on selection criteria, data exclusion rules, and assessment of potential biases or representativeness across land cover types, which is critical to support the generalizability of the negative correlation findings.
- [§5] §5 (Experimental Results): The analysis of correlations between SR metrics and downstream task performance across the 270 settings does not include statistical significance tests, error bars, or confidence intervals; this weakens the central claim that correlations 'often do not correlate' or 'can be negative'.
minor comments (1)
- [Abstract] Abstract: A supplementary table breaking down the 270 settings by SR model, task, and platform would improve clarity of the experimental design.
Simulated Author's Rebuttal
We thank the referee for their thorough review and constructive comments on our manuscript. We appreciate the recognition of the benchmark's scale and the importance of integrating downstream tasks. Below, we provide point-by-point responses to the major comments.
read point-by-point responses
-
Referee: [§3] §3 (Dataset): The description of the 36,000 locations and quality control process lacks explicit details on selection criteria, data exclusion rules, and assessment of potential biases or representativeness across land cover types, which is critical to support the generalizability of the negative correlation findings.
Authors: We agree that more detailed information on the dataset curation process is necessary to bolster the generalizability of our results. In the revised version of the manuscript, we will expand the description in §3 to explicitly detail the selection criteria for the approximately 36,000 locations, the specific data exclusion rules applied during quality control, and an assessment of potential biases along with the representativeness across various land cover types. This addition will help substantiate the robustness of the observed correlations. revision: yes
-
Referee: [§5] §5 (Experimental Results): The analysis of correlations between SR metrics and downstream task performance across the 270 settings does not include statistical significance tests, error bars, or confidence intervals; this weakens the central claim that correlations 'often do not correlate' or 'can be negative'.
Authors: We concur that incorporating statistical rigor would strengthen the presentation of our findings. Accordingly, in the revised manuscript, we will augment the analysis in §5 by including statistical significance tests for the correlations, as well as error bars and confidence intervals where appropriate, across the 270 experimental settings. These additions will provide quantitative support for our conclusions regarding the weak or negative correlations between traditional SR fidelity metrics and downstream task performance. revision: yes
Circularity Check
No circularity: empirical benchmarking study with independent experimental results
full rationale
The paper introduces GeoSR-Bench as a new dataset and performs direct empirical comparisons of 9 SR models across 2 scenarios, 3 task models, and 5 downstream tasks using 36,000 image pairs. No derivations, equations, or fitted parameters are presented as predictions; results are computed from held-out evaluations. No self-citation chains or ansatzes underpin the central claim of weak/negative correlations between fidelity metrics and task performance. The study is self-contained against external benchmarks and does not reduce its findings to inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Spatially co-located, temporally aligned, and quality-controlled image pairs from diverse land covers form a fair basis for SR benchmarking.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.