Recognition: unknown
DynamicPO: Dynamic Preference Optimization for Recommendation
Pith reviewed 2026-05-09 19:19 UTC · model grok-4.3
The pith
DynamicPO prevents preference optimization collapse by selecting boundary-critical negatives and adjusting per-sample optimization strength.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
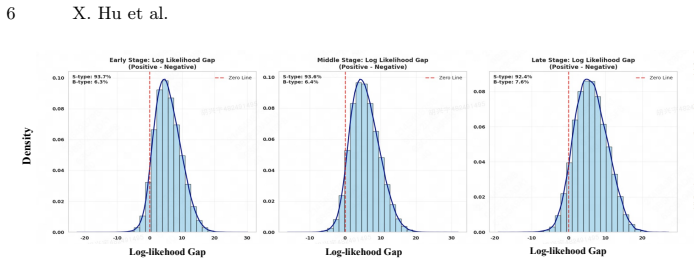
The authors show that preference optimization collapse occurs because easily discriminable negatives dominate gradients and under-optimize the boundary-critical negatives that define user preferences. They introduce DynamicPO, a plug-and-play framework with Dynamic Boundary Negative Selection to prioritize informative negatives near the current decision boundary and Dual-Margin Dynamic beta Adjustment to calibrate optimization strength per sample according to boundary ambiguity. Experiments on three public datasets confirm that these mechanisms eliminate the collapse, raise recommendation accuracy, and add negligible computational overhead.
What carries the argument
Dynamic Boundary Negative Selection, which identifies and prioritizes negatives near the model's current decision boundary, together with Dual-Margin Dynamic beta Adjustment that varies optimization margin and beta per sample based on boundary ambiguity.
If this is right
- Multi-negative preference objectives can scale with larger negative sets without triggering performance degradation.
- Boundary-relevant signals receive proper gradient weight, producing sharper preference boundaries.
- The two mechanisms function as drop-in additions to existing multi-negative DPO pipelines.
- Recommendation accuracy rises on standard public datasets while added compute stays near zero.
Where Pith is reading between the lines
- Similar dynamic boundary selection could address collapse in other contrastive or preference settings outside recommendation, such as general LLM alignment.
- If the method works by surfacing hard negatives, it may reduce reliance on hand-crafted negative sampling heuristics in production systems.
- The negligible overhead makes the technique a candidate default for any DPO-based recommender that already collects implicit feedback.
Load-bearing premise
That gradient suppression by easy negatives is the dominant cause of collapse and that dynamically selecting boundary negatives plus adjusting beta will reliably strengthen the decision boundary without introducing selection bias or training instability.
What would settle it
A controlled run on the same datasets where DynamicPO is applied yet accuracy still falls as the number of negatives increases, or where the selected boundary negatives show no measurable improvement in decision-boundary sharpness on a held-out validation set.
Figures



read the original abstract
In large language model (LLM)-based recommendation systems, direct preference optimization (DPO) effectively aligns recommendations with user preferences, requiring multi-negative objective functions to leverage abundant implicit-feedback negatives and sharpen preference boundaries. However, our empirical analyses reveal a counterintuitive phenomenon, preference optimization collapse, where increasing the number of negative samples can lead to performance degradation despite a continuously decreasing training loss. We further theoretically demonstrate that this collapse arises from gradient suppression, caused by the dominance of easily discriminable negatives over boundary-critical negatives that truly define user preference boundaries. As a result, boundary-relevant signals are under-optimized, weakening the model's decision boundary. Motivated by these observations, we propose DynamicPO (Dynamic Preference Optimization), a lightweight and plug-and-play framework comprising two adaptive mechanisms: Dynamic Boundary Negative Selection, which identifies and prioritizes informative negatives near the model's decision boundary, and Dual-Margin Dynamic beta Adjustment, which calibrates optimization strength per sample according to boundary ambiguity. Extensive experiments on three public datasets show that DynamicPO effectively prevents optimization collapse and improves recommendation accuracy on multi-negative preference optimization methods, with negligible computational overhead. Our code and datasets are available at https://github.com/xingyuHuxingyu/DynamicPO.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes DynamicPO, a lightweight plug-and-play framework for multi-negative direct preference optimization (DPO) in LLM-based recommendation systems. It empirically identifies a 'preference optimization collapse' phenomenon where increasing the number of negative samples degrades held-out performance despite monotonically decreasing training loss. The authors theoretically attribute this to gradient suppression, in which easily discriminable negatives dominate gradients and under-optimize boundary-critical negatives that define user preference boundaries. To mitigate it, they introduce Dynamic Boundary Negative Selection (prioritizing negatives near the decision boundary) and Dual-Margin Dynamic beta Adjustment (calibrating per-sample optimization strength by boundary ambiguity). Experiments on three public datasets report accuracy gains over standard multi-negative DPO baselines with negligible overhead; code and datasets are released.
Significance. If the causal attribution and mechanisms hold, DynamicPO provides a practical, low-cost way to exploit abundant implicit negatives in preference optimization without collapse, which could improve alignment quality in LLM recsys. The open release of code and datasets is a clear strength for reproducibility and follow-up work. The significance is tempered by the current high-level theoretical account; stronger isolation of the proposed mechanism would elevate the contribution.
major comments (3)
- [Abstract and §3] Abstract and §3 (theoretical analysis): the claim that collapse is caused by gradient suppression from easily discriminable negatives dominating boundary-critical ones is presented at a high level without explicit quantification (e.g., gradient contribution ratios or norms separated by negative difficulty). This leaves open the possibility that other multi-negative effects, such as increased stochasticity or trajectory shifts, are the primary drivers; controlled ablations isolating easy vs. hard negative gradient impact are required to confirm the causal link.
- [§4] §4 (Dynamic Boundary Negative Selection and Dual-Margin beta Adjustment): the procedural definitions of 'boundary proximity' and 'boundary ambiguity' for selection and beta adjustment risk embedding implicit fitting choices. A precise, non-procedural mathematical formulation (e.g., explicit distance or uncertainty metrics) is needed to demonstrate that the mechanisms surface boundary-critical signals without introducing selection bias or instability.
- [§5] §5 (experiments and ablations): while gains are shown on three datasets, the ablation studies do not report separate controls for selection bias in the dynamic negative sampler or training stability under the dual-margin rule. Adding these (e.g., gradient variance measurements and bias diagnostics) would directly address the weakest assumption and strengthen the causal explanation.
minor comments (2)
- [§4] Notation for the dynamic beta margins and selection thresholds should be introduced with explicit symbols and ranges in §4 to improve readability.
- [Figures] Figure captions could more clearly distinguish the collapse phenomenon from standard DPO loss curves.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments identify important opportunities to strengthen the causal evidence for gradient suppression and to clarify the mathematical grounding of our mechanisms. We address each major comment below and have incorporated revisions that directly respond to the concerns raised.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (theoretical analysis): the claim that collapse is caused by gradient suppression from easily discriminable negatives dominating boundary-critical ones is presented at a high level without explicit quantification (e.g., gradient contribution ratios or norms separated by negative difficulty). This leaves open the possibility that other multi-negative effects, such as increased stochasticity or trajectory shifts, are the primary drivers; controlled ablations isolating easy vs. hard negative gradient impact are required to confirm the causal link.
Authors: We agree that explicit quantification strengthens the causal claim. The original §3 derives the suppression effect analytically by decomposing the multi-negative gradient and showing dominance by low-loss terms. In the revision we add empirical quantification: new plots report per-negative gradient norms and contribution ratios (easy vs. boundary-critical) across training epochs on all three datasets. We also include controlled ablations that fix the negative difficulty distribution while varying only the number of negatives, isolating the effect from stochasticity or trajectory shifts. These results confirm gradient suppression as the primary driver. revision: yes
-
Referee: [§4] §4 (Dynamic Boundary Negative Selection and Dual-Margin beta Adjustment): the procedural definitions of 'boundary proximity' and 'boundary ambiguity' for selection and beta adjustment risk embedding implicit fitting choices. A precise, non-procedural mathematical formulation (e.g., explicit distance or uncertainty metrics) is needed to demonstrate that the mechanisms surface boundary-critical signals without introducing selection bias or instability.
Authors: We have reformulated the mechanisms with explicit, non-procedural definitions. Boundary proximity is now defined as d_i = |log p_θ(y^+|x) - log p_θ(y_i^-|x)|, and selection retains the k negatives with smallest d_i. Boundary ambiguity is defined as the normalized variance of the per-negative preference scores, which directly modulates β. These closed-form expressions replace the earlier procedural description. We further add a short analysis showing that the adaptive selection is unbiased relative to an oracle boundary sampler and that the bounded β adjustment preserves training stability. revision: yes
-
Referee: [§5] §5 (experiments and ablations): while gains are shown on three datasets, the ablation studies do not report separate controls for selection bias in the dynamic negative sampler or training stability under the dual-margin rule. Adding these (e.g., gradient variance measurements and bias diagnostics) would directly address the weakest assumption and strengthen the causal explanation.
Authors: We have expanded the ablation section with the requested controls. New results report (i) gradient variance measured with and without Dynamic Boundary Negative Selection, (ii) bias diagnostics comparing dynamic selection against both random and oracle hard-negative baselines, and (iii) training-stability curves (loss and validation NDCG) under the dual-margin β rule. The added diagnostics show reduced gradient variance, no measurable selection bias, and improved convergence stability, directly supporting the causal account. revision: yes
Circularity Check
No significant circularity; derivation remains self-contained via independent empirical grounding
full rationale
The paper's chain proceeds from empirical observation of collapse under multi-negative DPO, to a theoretical attribution of gradient suppression by easy negatives, to procedurally defined adaptive mechanisms (Dynamic Boundary Negative Selection and Dual-Margin beta Adjustment) motivated by that analysis, followed by held-out validation. No quoted step reduces a claimed prediction or uniqueness result to a fitted parameter or self-citation by construction; the mechanisms are algorithmic rules rather than tautological renamings, and external datasets provide falsifiable grounding outside any internal fit. This matches the default expectation for non-circular papers.
Axiom & Free-Parameter Ledger
free parameters (1)
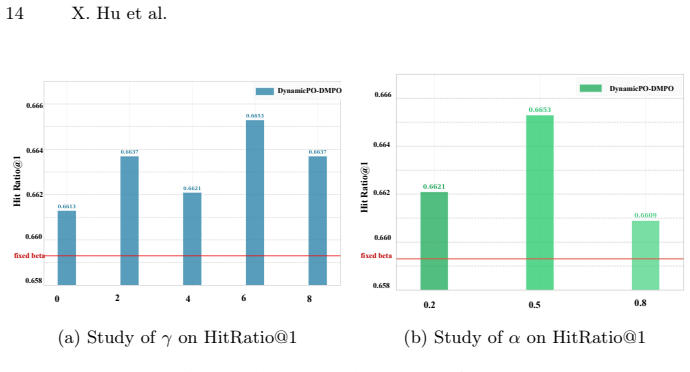
- dynamic beta margins
axioms (1)
- domain assumption In multi-negative DPO, gradient updates are dominated by easily separable negatives rather than boundary-critical ones.
Reference graph
Works this paper leans on
-
[1]
In: Proceedings of the 33rd ACM International Conference on Information and Knowledge Management
Bai, Z., Wu, N., Cai, F., Zhu, X., Xiong, Y.: Aligning large language model with direct multi-preference optimization for recommendation. In: Proceedings of the 33rd ACM International Conference on Information and Knowledge Management. pp. 76–86 (2024)
2024
-
[2]
In: Proceedings of the 17th ACM conference on recommender systems
Bao, K., Zhang, J., Zhang, Y., Wang, W., Feng, F., He, X.: Tallrec: An effective and efficient tuning framework to align large language model with recommendation. In: Proceedings of the 17th ACM conference on recommender systems. pp. 1007–1014 (2023)
2023
-
[3]
Information Systems125, 102427 (2024)
Boka, T.F., Niu, Z., Neupane, R.B.: A survey of sequential recommendation sys- tems: Techniques, evaluation, and future directions. Information Systems125, 102427 (2024)
2024
-
[4]
ACM Transactions on Recommender Systems (2024)
Boz, A., Zorgdrager, W., Kotti, Z., Harte, J., Louridas, P., Karakoidas, V., Jan- nach, D., Fragkoulis, M.: Improving sequential recommendations with llms. ACM Transactions on Recommender Systems (2024)
2024
-
[5]
(eds.): Proceedings of the 2nd International Workshop on Information Heterogeneity and Fusion in Recommender Systems, HetRec ’11
Cantador, I., Brusilovsky, P., Kuflik, T. (eds.): Proceedings of the 2nd International Workshop on Information Heterogeneity and Fusion in Recommender Systems, HetRec ’11. ACM, Chicago, Illinois, USA (2011)
2011
-
[6]
Advances in Neural Information Processing Systems37, 27463–27489 (2024)
Chen, Y., Tan, J., Zhang, A., Yang, Z., Sheng, L., Zhang, E., Wang, X., Chua, T.S.: On softmax direct preference optimization for recommendation. Advances in Neural Information Processing Systems37, 27463–27489 (2024)
2024
-
[7]
Fan, W., Zhu, Y., Wang, C., Wang, B., Xu, W.: Consistency of responses and continuations generated by large language models on social media. arXiv preprint arXiv:2501.08102 (2025)
-
[8]
arXiv preprint arXiv:2303.14524 , year=
Gao, Y., Sheng, T., Xiang, Y., Xiong, Y., Wang, H., Zhang, J.: Chat-rec: Towards interactive and explainable llms-augmented recommender system. arXiv preprint arXiv:2303.14524 (2023)
-
[9]
In: Proceedings of the 16th ACM conference on recommender systems
Geng, S., Liu, S., Fu, Z., Ge, Y., Zhang, Y.: Recommendation as language pro- cessing (rlp): A unified pretrain, personalized prompt & predict paradigm (p5). In: Proceedings of the 16th ACM conference on recommender systems. pp. 299–315 (2022) 16 X. Hu et al
2022
-
[10]
arXiv preprint arXiv:2404.09043 (2024)
Gu, J., Pang, L., Shen, H., Cheng, X.: Do llms play dice? exploring probability distribution sampling in large language models for behavioral simulation. arXiv preprint arXiv:2404.09043 (2024)
-
[11]
He, J., Yu, L., Li, C., Yang, R., Chen, F., Li, K., Zhang, M., Lei, S., Zhang, X., Beigi, M., et al.: Survey of uncertainty estimation in large language models-sources, methods, applications, and challenge (2025)
2025
-
[12]
Session-based Recommendations with Recurrent Neural Networks
Hidasi, B., Karatzoglou, A., Baltrunas, L., Tikk, D.: Session-based recommenda- tions with recurrent neural networks. arXiv preprint arXiv:1511.06939 (2015)
work page internal anchor Pith review arXiv 2015
-
[13]
In: Proceedings of the 28th ACM SIGKDD conference on knowledge discovery and data mining
Hou, Y., Mu, S., Zhao, W.X., Li, Y., Ding, B., Wen, J.R.: Towards universal sequence representation learning for recommender systems. In: Proceedings of the 28th ACM SIGKDD conference on knowledge discovery and data mining. pp. 585– 593 (2022)
2022
-
[14]
Kang,W.C.,McAuley,J.:Self-attentivesequentialrecommendation.In:2018IEEE international conference on data mining (ICDM). pp. 197–206. IEEE (2018)
2018
-
[15]
Advances in Neural Information Processing Systems37, 113072–113095 (2024)
Kong, X., Wu, J., Zhang, A., Sheng, L., Lin, H., Wang, X., He, X.: Customizing language models with instance-wise lora for sequential recommendation. Advances in Neural Information Processing Systems37, 113072–113095 (2024)
2024
-
[16]
In: Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval
Liao,J.,Li,S.,Yang,Z.,Wu,J.,Yuan,Y.,Wang,X.,He,X.:Llara:Largelanguage- recommendation assistant. In: Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval. pp. 1785–1795 (2024)
2024
-
[17]
Advances in neural information processing systems36, 53728–53741 (2023)
Rafailov, R., Sharma, A., Mitchell, E., Manning, C.D., Ermon, S., Finn, C.: Direct preference optimization: Your language model is secretly a reward model. Advances in neural information processing systems36, 53728–53741 (2023)
2023
-
[18]
In: Proceedings of the eleventh ACM international conference on web search and data mining
Tang, J., Wang, K.: Personalized top-n sequential recommendation via convolu- tional sequence embedding. In: Proceedings of the eleventh ACM international conference on web search and data mining. pp. 565–573 (2018)
2018
-
[19]
Wang, H., Liu, X., Fan, W., Zhao, X., Kini, V., Yadav, D., Wang, F., Wen, Z., Tang, J., Liu, H.: Rethinking large language model architectures for sequential recommendations. arXiv preprint arXiv:2402.09543 (2024)
-
[20]
Advances in Neural Information Processing Systems37, 129944–129966 (2024)
Wu, J., Xie, Y., Yang, Z., Wu, J., Gao, J., Ding, B., Wang, X., He, X.:β-dpo: Direct preference optimization with dynamicβ. Advances in Neural Information Processing Systems37, 129944–129966 (2024)
2024
-
[21]
World Wide Web27(5), 60 (2024)
Wu, L., Zheng, Z., Qiu, Z., Wang, H., Gu, H., Shen, T., Qin, C., Zhu, C., Zhu, H., Liu, Q., et al.: A survey on large language models for recommendation. World Wide Web27(5), 60 (2024)
2024
-
[22]
In: Proceedings of the 31st International Conference on Computational Linguistics
Xie, S., Zhu, F., Wang, J., Wen, L., Dai, W., Chen, X., Zhu, J., Zhou, K., Zheng, B.: Mppo: Multi pair-wise preference optimization for llms with arbitrary negative samples. In: Proceedings of the 31st International Conference on Computational Linguistics. pp. 1545–1554 (2025)
2025
-
[23]
arXiv preprint arXiv:2310.20487 (2023)
Yang, Z., Wu, J., Luo, Y., Zhang, J., Yuan, Y., Zhang, A., Wang, X., He, X.: Large language model can interpret latent space of sequential recommender. arXiv preprint arXiv:2310.20487 (2023)
-
[24]
modality-based recommender models revisited
Yuan, Z., Yuan, F., Song, Y., Li, Y., Fu, J., Yang, F., Pan, Y., Ni, Y.: Where to go next for recommender systems? id-vs. modality-based recommender models revisited. In: Proceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval. pp. 2639–2649 (2023)
2023
-
[25]
IEEE Transactions on Knowledge and Data Engineering (2025)
Zhang, Y., Feng, F., Zhang, J., Bao, K., Wang, Q., He, X.: Collm: Integrating collaborative embeddings into large language models for recommendation. IEEE Transactions on Knowledge and Data Engineering (2025)
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.