Recognition: unknown
AgentFloor: How Far Up the tool use Ladder Can Small Open-Weight Models Go?
Pith reviewed 2026-05-09 20:03 UTC · model grok-4.3
The pith
Small and mid-sized open-weight models already handle most routine tool-use tasks in agent workflows and match GPT-5 on a new benchmark while running cheaper and faster.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
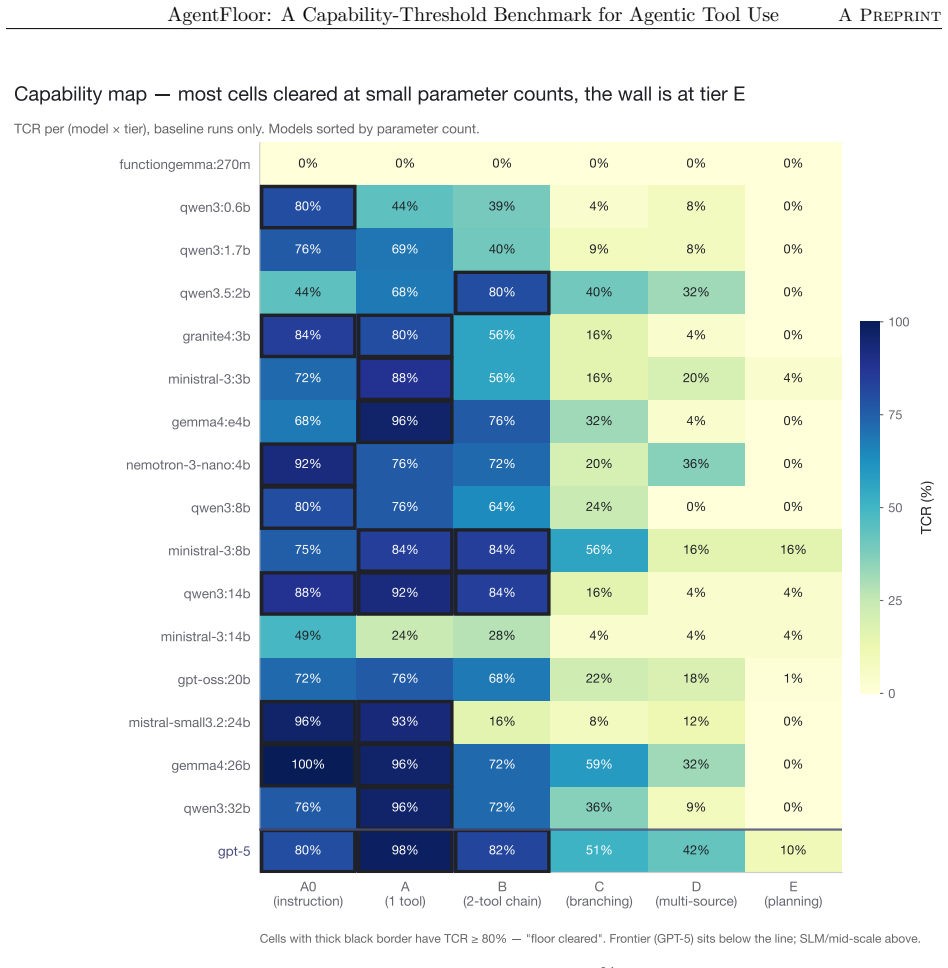
Production agentic systems make many model calls per user request, and most of those calls are short, structured, and routine. This raises a practical routing question that existing evaluations do not directly answer: which parts of an agent workflow truly require large frontier intelligence, and which can be handled by smaller models? We introduce AgentFloor, a deterministic 30-task benchmark organized as a six-tier capability ladder, spanning instruction following, tool use, multi-step coordination, and long-horizon planning under persistent constraints. We evaluate 16 open-weight models, from 0.27B to 32B parameters, alongside GPT-5 across 16,542 scored runs. Our results reveal a clear边界:
What carries the argument
AgentFloor, a deterministic 30-task benchmark structured as a six-tier capability ladder that measures progressive agent skills from instruction following to long-horizon planning.
If this is right
- Agent pipelines can route the majority of short-horizon structured calls to smaller open-weight models to lower cost and latency.
- Frontier models are needed primarily for the narrower set of long-horizon planning tasks that require sustained constraint tracking.
- Some model failures on the ladder respond to targeted interventions rather than requiring universal increases in scale.
- Practical agent designs should incorporate explicit routing rules that match task horizon to model size.
Where Pith is reading between the lines
- Hybrid routing systems could become common, automatically assigning routine steps to small models and planning steps to large ones across many domains.
- Extending the ladder to include stochastic or real-world variable tasks would reveal whether the current tier boundaries remain stable.
- Similar tiered benchmarks could map capability cutoffs for other agent skills such as code execution or multimodal coordination.
Load-bearing premise
That success on these 30 fixed, deterministic tasks accurately reflects the difficulty distribution and generalization needed for variable tasks in deployed agent systems.
What would settle it
Deploying the same models inside live production agent pipelines with real user requests and measuring whether the tiered performance gaps and GPT-5 parity hold under open-ended conditions.
Figures







read the original abstract
Production agentic systems make many model calls per user request, and most of those calls are short, structured, and routine. This raises a practical routing question that existing evaluations do not directly answer: which parts of an agent workflow truly require large frontier intelligence, and which can be handled by smaller models? We introduce AgentFloor, a deterministic 30-task benchmark organized as a six-tier capability ladder, spanning instruction following, tool use, multi-step coordination, and long-horizon planning under persistent constraints. We evaluate 16 open-weight models, from 0.27B to 32B parameters, alongside GPT-5 across 16,542 scored runs. Our results reveal a clear boundary of model necessity. Small and mid-sized open-weight models are already sufficient for much of the short-horizon, structured tool use work that dominates real agent pipelines, and in aggregate, the strongest open-weight model matches GPT-5 on our benchmark while being substantially cheaper and faster to run. The gap appears most clearly on long-horizon planning tasks that require sustained coordination and reliable constraint tracking over many steps, where frontier models still hold an advantage, though neither side reaches strong reliability. We also find that this boundary is not explained by scale alone: some failures respond to targeted interventions, but the effects are model-specific rather than universal. These findings suggest a practical design principle for agentic systems: use smaller open-weight models for the broad base of routine actions, and reserve large frontier models for the narrower class of tasks that truly demand deeper planning and control. We release the benchmark, harness, sweep configurations, and full run corpus.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces AgentFloor, a deterministic 30-task benchmark organized as a six-tier capability ladder spanning instruction following, tool use, multi-step coordination, and long-horizon planning. It reports results from evaluating 16 open-weight models (0.27B–32B parameters) plus GPT-5 across 16,542 scored runs, claiming a clear performance boundary: small and mid-sized open-weight models suffice for most short-horizon structured tool use, the strongest open-weight model matches GPT-5 in aggregate (while being cheaper/faster), and gaps are concentrated in long-horizon tasks requiring sustained constraint tracking. The work releases the benchmark, harness, sweep configurations, and full run corpus.
Significance. If the benchmark's task distribution and tier boundaries accurately capture the short-horizon routine work that dominates production agent pipelines, the results have clear practical value for cost-aware routing in agentic systems. The scale of the evaluation (16k+ runs) and the public release of the full corpus and harness are strengths that support reproducibility and follow-on work.
major comments (3)
- [Benchmark description section (tasks and tiers)] Benchmark description section (tasks and tiers): the 30 tasks are described as hand-designed and deterministic with no reported coverage metrics, sampling from production logs, or external validation of the six-tier boundaries against real agent traces. This is load-bearing for the central claim that small models are 'already sufficient for much of the short-horizon, structured tool use work that dominates real agent pipelines,' as the observed sufficiency and routing principle rest on the untested assumption that the benchmark reflects the relevant difficulty distribution and failure modes.
- [Results section (performance boundary and interventions)] Results section (performance boundary and interventions): while aggregate scores and a 'clear boundary' are reported, the manuscript provides no statistical tests, confidence intervals, or variance measures across the 16,542 runs to support the separation between short- and long-horizon regimes or the model-specific nature of intervention effects. This weakens the strength of the design-principle recommendation.
- [Discussion of long-horizon gaps] Discussion of long-horizon gaps: the paper notes that neither open-weight nor frontier models reach strong reliability on long-horizon planning yet does not quantify how the deterministic, fully observable task design may understate challenges from partial observability, ambiguous instructions, or cross-tier dependencies that occur in production workflows.
minor comments (2)
- [Abstract] Abstract: the list of evaluated models and exact parameter counts could be stated more explicitly to aid quick assessment of the scale comparison.
- [Figures] Figures: performance plots should include per-tier breakdowns with run-level variance or error bars to make the boundary claim visually verifiable.
Simulated Author's Rebuttal
Thank you for the constructive feedback on our paper. We address each of the major comments below and have revised the manuscript accordingly to strengthen the presentation of our results and acknowledge limitations.
read point-by-point responses
-
Referee: Benchmark description section (tasks and tiers): the 30 tasks are described as hand-designed and deterministic with no reported coverage metrics, sampling from production logs, or external validation of the six-tier boundaries against real agent traces. This is load-bearing for the central claim that small models are 'already sufficient for much of the short-horizon, structured tool use work that dominates real agent pipelines,' as the observed sufficiency and routing principle rest on the untested assumption that the benchmark reflects the relevant difficulty distribution and failure modes.
Authors: We agree that our benchmark is hand-designed and does not include direct sampling from production logs or quantitative coverage metrics. This represents a genuine limitation in validating how well the tier boundaries align with real-world agent workflows. In the revised manuscript, we have added a dedicated subsection in the Benchmark Description that details the design principles for each tier, drawing from common patterns in agent literature, and expanded the Limitations section to explicitly discuss the synthetic nature of the tasks and the need for future empirical validation against production traces. We maintain that the controlled, deterministic design allows for precise isolation of capabilities, which is valuable for the routing insights, but we now more clearly caveat the generalizability of our sufficiency claims. revision: yes
-
Referee: Results section (performance boundary and interventions): while aggregate scores and a 'clear boundary' are reported, the manuscript provides no statistical tests, confidence intervals, or variance measures across the 16,542 runs to support the separation between short- and long-horizon regimes or the model-specific nature of intervention effects. This weakens the strength of the design-principle recommendation.
Authors: We acknowledge that the original manuscript lacked formal statistical analysis to support the observed performance boundaries. We have revised the Results section to include standard deviation across runs for key metrics, confidence intervals where appropriate, and statistical significance tests (e.g., t-tests) comparing short-horizon vs. long-horizon performance across model sizes. These additions confirm the separation between regimes and the model-specific intervention effects, thereby strengthening the basis for our design recommendations. revision: yes
-
Referee: Discussion of long-horizon gaps: the paper notes that neither open-weight nor frontier models reach strong reliability on long-horizon planning yet does not quantify how the deterministic, fully observable task design may understate challenges from partial observability, ambiguous instructions, or cross-tier dependencies that occur in production workflows.
Authors: The referee is correct that we did not quantify the potential understatement due to our deterministic and fully observable setup. In the revised Discussion, we have added a paragraph analyzing this, including examples of how partial observability could compound errors in long-horizon tasks and noting that our benchmark isolates planning under ideal conditions. We agree this is an important direction for future extensions of the benchmark and have updated the text to reflect this limitation more explicitly. revision: partial
Circularity Check
No circularity: empirical results from new benchmark
full rationale
The paper introduces AgentFloor as a new deterministic 30-task benchmark and reports direct empirical performance measurements from 16,542 scored runs across 16 open-weight models and GPT-5. Central claims about small-model sufficiency for short-horizon tasks and aggregate matching of the strongest open-weight model to GPT-5 follow from observed tiered scores, not from any equations, fitted parameters, self-definitions, or load-bearing self-citations. No derivation chain exists that reduces results to inputs by construction; the work is self-contained as a transparent benchmark evaluation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The 30 tasks in the six-tier ladder sufficiently capture the spectrum of capabilities needed in real agent workflows.
Reference graph
Works this paper leans on
-
[1]
WebArena: A Realistic Web Environment for Building Autonomous Agents
Webarena: A realistic web environment for building autonomous agents , author=. arXiv preprint arXiv:2307.13854 , year=
work page internal anchor Pith review arXiv
-
[2]
ComplexFuncBench: Exploring multi-step and constrained function calling under long-context scenario , author=. arXiv preprint arXiv:2501.10132 , year=
-
[3]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
Critictool: Evaluating self-critique capabilities of large language models in tool-calling error scenarios , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[4]
arXiv preprint arXiv:2505.04799 , year=
Safeguard-by-development: A privacy-enhanced development paradigm for multi-agent collaboration systems , author=. arXiv preprint arXiv:2505.04799 , year=
-
[5]
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
arXiv preprint arXiv:2309.10691 , year=
Mint: Evaluating llms in ƒmulti-turn interaction with tools and language feedback , author=. arXiv preprint arXiv:2309.10691 , year=
-
[7]
Identifying the Risks of LM Agents with an LM-Emulated Sandbox
Identifying the risks of lm agents with an lm-emulated sandbox , author=. arXiv preprint arXiv:2309.15817 , year=
work page internal anchor Pith review arXiv
-
[8]
ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs
Toolllm: Facilitating large language models to master 16000+ real-world apis, 2023 , author=. URL https://arxiv. org/abs/2307.16789 , volume=
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[9]
Forty-second International Conference on Machine Learning , year=
The berkeley function calling leaderboard (bfcl): From tool use to agentic evaluation of large language models , author=. Forty-second International Conference on Machine Learning , year=
-
[10]
RouteLLM: Learning to Route LLMs with Preference Data
Routellm: Learning to route llms with preference data , author=. arXiv preprint arXiv:2406.18665 , year=
work page internal anchor Pith review arXiv
-
[11]
Proceedings of the 29th International Conference on Evaluation and Assessment in Software Engineering , pages=
Small models, big tasks: An exploratory empirical study on small language models for function calling , author=. Proceedings of the 29th International Conference on Evaluation and Assessment in Software Engineering , pages=
-
[12]
AutoMix: Automatically mixing language models
Automix: Automatically mixing language models , author=. arXiv preprint arXiv:2310.12963 , year=
-
[13]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing: Industry Track , pages=
Granite-function calling model: Introducing function calling abilities via multi-task learning of granular tasks , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing: Industry Track , pages=
2024
-
[14]
Phi-4 technical report , author=. arXiv preprint arXiv:2412.08905 , year=
work page internal anchor Pith review arXiv
-
[15]
SmolLM2: When Smol Goes Big -- Data-Centric Training of a Small Language Model
SmolLM2: When Smol Goes Big--Data-Centric Training of a Small Language Model , author=. arXiv preprint arXiv:2502.02737 , year=
work page internal anchor Pith review arXiv
-
[16]
Small language models are the future of agentic ai , author=. arXiv preprint arXiv:2506.02153 , year=
-
[17]
Hybrid LLM: Cost-efficient and quality-aware query routing
Hybrid llm: Cost-efficient and quality-aware query routing , author=. arXiv preprint arXiv:2404.14618 , year=
-
[18]
arXiv preprint arXiv:2504.11543 , year =
Real: Benchmarking autonomous agents on deterministic simulations of real websites , author=. arXiv preprint arXiv:2504.11543 , year=
-
[19]
The llama 3 herd of models , author=. arXiv preprint arXiv:2407.21783 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
arXiv preprint arXiv:2512.07497 , year=
How Do LLMs Fail In Agentic Scenarios? A Qualitative Analysis of Success and Failure Scenarios of Various LLMs in Agentic Simulations , author=. arXiv preprint arXiv:2512.07497 , year=
-
[21]
Findings of the Association for Computational Linguistics: ACL 2024 , pages=
Stabletoolbench: Towards stable large-scale benchmarking on tool learning of large language models , author=. Findings of the Association for Computational Linguistics: ACL 2024 , pages=
2024
-
[22]
SWE-bench: Can Language Models Resolve Real-World GitHub Issues?
Swe-bench: Can language models resolve real-world github issues? , author=. arXiv preprint arXiv:2310.06770 , year=
work page internal anchor Pith review arXiv
-
[23]
arXiv preprint arXiv:2411.13547 , year=
Toolscan: A benchmark for characterizing errors in tool-use llms , author=. arXiv preprint arXiv:2411.13547 , year=
-
[24]
Proceedings of the 2023 conference on empirical methods in natural language processing , pages=
Api-bank: A comprehensive benchmark for tool-augmented llms , author=. Proceedings of the 2023 conference on empirical methods in natural language processing , pages=
2023
-
[25]
AgentBench: Evaluating LLMs as Agents
Agentbench: Evaluating llms as agents , author=. arXiv preprint arXiv:2308.03688 , year=
work page internal anchor Pith review arXiv
-
[26]
Small language models: Survey, measurements, and insights.arXiv preprint arXiv:2409.15790, 2024
Small language models: Survey, measurements, and insights , author=. arXiv preprint arXiv:2409.15790 , year=
-
[27]
2023 , eprint =
Gorilla: Large Language Model Connected with Massive APIs , author =. 2023 , eprint =
2023
-
[28]
2023 , eprint =
API-Bank: A Comprehensive Benchmark for Tool-Augmented LLMs , author =. 2023 , eprint =
2023
-
[29]
2023 , eprint =
Toolformer: Language Models Can Teach Themselves to Use Tools , author =. 2023 , eprint =
2023
-
[30]
2024 , howpublished =
Berkeley Function Calling Leaderboard (. 2024 , howpublished =
2024
-
[31]
2023 , eprint =
ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs , author =. 2023 , eprint =
2023
-
[32]
$\tau$-bench: A Benchmark for Tool-Agent-User Interaction in Real-World Domains
Yao, Shunyu and Shinn, Noah and Razavi, Pedram and Narasimhan, Karthik , year =. 2406.12045 , archivePrefix =
work page internal anchor Pith review arXiv
-
[33]
2024 , eprint =
NESTFUL: A Benchmark for Evaluating LLMs on Nested Sequences of API Calls , author =. 2024 , eprint =
2024
-
[34]
2025 , eprint =
ToolHop: A Query-Driven Benchmark for Evaluating Large Language Models in Multi-Hop Tool Use , author =. 2025 , eprint =
2025
-
[35]
2024 , eprint =
SpecTool: A Benchmark for Characterizing Errors in Tool-Use LLMs , author =. 2024 , eprint =
2024
-
[36]
2025 , eprint =
CRITICTOOL: Evaluating Self-Critique Capabilities of Large Language Models in Tool-Calling Error Scenarios , author =. 2025 , eprint =
2025
-
[37]
2023 , eprint =
ToolEmu: Emulating Large Language Model Agents for Safe and Effective Tool Learning , author =. 2023 , eprint =
2023
-
[38]
2024 , eprint =
AgentBoard: An Analytical Evaluation Board of Multi-turn LLM Agents , author =. 2024 , eprint =
2024
-
[39]
2024 , eprint =
OSWorld: Benchmarking Multimodal Agents for Open-Ended Tasks in Real Computer Environments , author =. 2024 , eprint =
2024
-
[40]
2024 , eprint =
AppWorld: A Controllable World of Apps and People for Benchmarking Interactive Coding Agents , author =. 2024 , eprint =
2024
-
[41]
2023 , eprint =
GAIA: a Benchmark for General AI Assistants , author =. 2023 , eprint =
2023
-
[42]
2021 , eprint =
ALFWorld: Aligning Text and Embodied Environments for Interactive Learning , author =. 2021 , eprint =
2021
-
[43]
2022 , eprint =
ScienceWorld: Is your Agent Smarter than a 5th Grader? , author =. 2022 , eprint =
2022
-
[44]
2020 , eprint =
Scaling Laws for Neural Language Models , author =. 2020 , eprint =
2020
-
[45]
2022 , eprint =
Training Compute-Optimal Large Language Models , author =. 2022 , eprint =
2022
-
[46]
2022 , eprint =
Emergent Abilities of Large Language Models , author =. 2022 , eprint =
2022
-
[47]
2023 , eprint =
Are Emergent Abilities of Large Language Models a Mirage? , author =. 2023 , eprint =
2023
-
[48]
2024 , eprint =
Small Language Models: Survey, Measurements, and Insights , author =. 2024 , eprint =
2024
-
[49]
2024 , eprint =
A Comprehensive Survey of Small Language Models in the Era of Large Language Models: Techniques, Enhancements, Applications, Collaboration with LLMs, and Trustworthiness , author =. 2024 , eprint =
2024
-
[50]
2024 , eprint =
A Survey of Small Language Models , author =. 2024 , eprint =
2024
-
[51]
2023 , eprint =
Textbooks Are All You Need , author =. 2023 , eprint =
2023
-
[52]
2024 , eprint =
Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone , author =. 2024 , eprint =
2024
-
[53]
2024 , eprint =
Qwen2 Technical Report , author =. 2024 , eprint =
2024
-
[54]
2024 , eprint =
Gemma: Open Models Based on Gemini Research and Technology , author =. 2024 , eprint =
2024
-
[55]
2025 , eprint =
SmolLM2: When Smol Goes Big -- Data-Centric Training of a Small Language Model , author =. 2025 , eprint =
2025
-
[56]
2024 , eprint =
TinyLlama: An Open-Source Small Language Model , author =. 2024 , eprint =
2024
-
[57]
2024 , eprint =
OLMo: Accelerating the Science of Language Models , author =. 2024 , eprint =
2024
-
[58]
2023 , eprint =
Orca: Progressive Learning from Complex Explanation Traces of GPT-4 , author =. 2023 , eprint =
2023
-
[59]
2023 , eprint =
Distilling Step-by-Step! Outperforming Larger Language Models with Less Training Data and Smaller Model Sizes , author =. 2023 , eprint =
2023
-
[60]
2025 , eprint =
Small Models, Big Tasks: An Exploratory Empirical Study on Small Language Models for Function Calling , author =. 2025 , eprint =
2025
-
[61]
2025 , eprint =
Small Language Models are the Future of Agentic AI , author =. 2025 , eprint =
2025
-
[62]
2025 , eprint =
Small Language Models for Agentic Systems: A Survey of Architectures, Capabilities, and Deployment Trade-offs , author =. 2025 , eprint =
2025
-
[63]
2022 , eprint =
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models , author =. 2022 , eprint =
2022
-
[64]
2022 , eprint =
ReAct: Synergizing Reasoning and Acting in Language Models , author =. 2022 , eprint =
2022
-
[65]
2023 , eprint =
Plan-and-Solve Prompting: Improving Zero-Shot Chain-of-Thought Reasoning by Large Language Models , author =. 2023 , eprint =
2023
-
[66]
2023 , eprint =
Tree of Thoughts: Deliberate Problem Solving with Large Language Models , author =. 2023 , eprint =
2023
-
[67]
2022 , eprint =
Self-Consistency Improves Chain of Thought Reasoning in Language Models , author =. 2022 , eprint =
2022
-
[68]
2024 , eprint =
Quantifying Language Models' Sensitivity to Spurious Features in Prompt Design or: How I Learned to Start Worrying about Prompt Formatting , author =. 2024 , eprint =
2024
-
[69]
Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (ACL) , year =
Fantastically Ordered Prompts and Where to Find Them: Overcoming Few-Shot Prompt Order Sensitivity , author =. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (ACL) , year =
-
[70]
2024 , eprint =
Does Prompt Formatting Have Any Impact on LLM Performance? , author =. 2024 , eprint =
2024
-
[71]
2023 , eprint =
Reflexion: Language Agents with Verbal Reinforcement Learning , author =. 2023 , eprint =
2023
-
[72]
2023 , eprint =
Self-Refine: Iterative Refinement with Self-Feedback , author =. 2023 , eprint =
2023
-
[73]
2024 , eprint =
CRITIC: Large Language Models Can Self-Correct with Tool-Interactive Critiquing , author =. 2024 , eprint =
2024
-
[74]
2024 , eprint =
Large Language Models Cannot Self-Correct Reasoning Yet , author =. 2024 , eprint =
2024
-
[75]
2024 , eprint =
On the Self-Verification Limitations of Large Language Models on Reasoning and Planning Tasks , author =. 2024 , eprint =
2024
-
[76]
2025 , eprint =
Why Do Multi-Agent LLM Systems Fail? , author =. 2025 , eprint =
2025
-
[77]
2025 , note =
Taxonomy of Failure Modes in Agentic AI Systems , author =. 2025 , note =
2025
-
[78]
2023 , eprint =
FrugalGPT: How to Use Large Language Models While Reducing Cost and Improving Performance , author =. 2023 , eprint =
2023
-
[79]
2024 , eprint =
Hybrid LLM: Cost-Efficient and Quality-Aware Query Routing , author =. 2024 , eprint =
2024
-
[80]
2025 , eprint =
A Unified Approach to Routing and Cascading for LLMs , author =. 2025 , eprint =
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.