Recognition: unknown
Budget-Aware Routing for Long Clinical Text
Pith reviewed 2026-05-09 19:54 UTC · model grok-4.3
The pith
A submodular RCD objective selects clinical text units to balance relevance, coverage, and diversity under token budgets.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
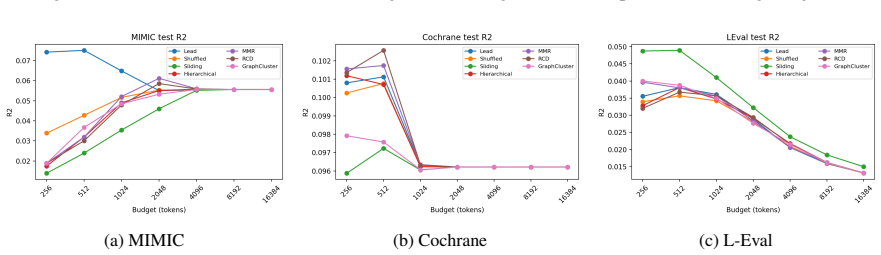
We cast budgeted context selection as a knapsack-constrained subset selection problem with two design choices: unitization that segments the document and selection that picks which units to keep. We propose RCD, a monotone submodular objective that balances relevance, coverage, and diversity. Experiments on MIMIC discharge notes, Cochrane abstracts, and L-Eval show that optimal strategies depend on the evaluation setting. Positional heuristics perform best at low budgets in extractive tasks, while diversity-aware methods such as MMR improve LLM generation. Selector choice matters more than unitization, with cluster-based grouping reducing performance and other schemes behaving similarly.
What carries the argument
RCD, a monotone submodular objective that scores subsets by combining relevance, coverage, and diversity terms to solve the knapsack-constrained selection of document units.
If this is right
- Positional heuristics outperform other methods at low token budgets when the task is extractive summarization.
- Diversity-aware selectors such as MMR improve results when the downstream step is LLM generation rather than extraction.
- Cluster-based unitization lowers performance while sentence, section, and window unitizations perform similarly.
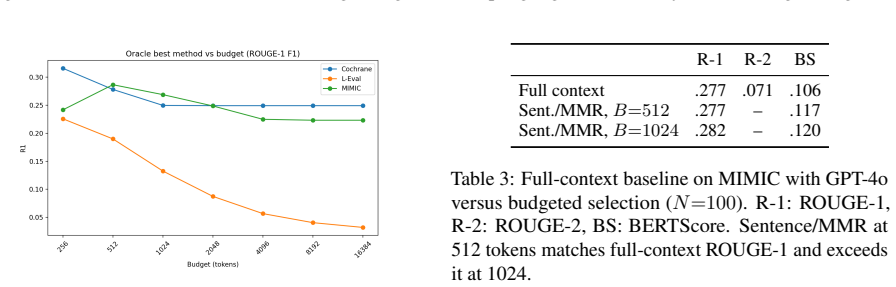
- ROUGE scores saturate for LLM-generated summaries, whereas BERTScore distinguishes quality differences more clearly.
- The choice of selector has a larger effect on final quality than the choice of how to segment the original document.
Where Pith is reading between the lines
- The same budgeted routing approach could be tested on long legal or scientific documents where token costs also constrain LLM use.
- Because selector choice dominates, future efforts might focus on learning adaptive selectors rather than refining segmentation rules.
- In clinical deployment one could measure whether RCD-selected contexts reduce factual errors or omissions relative to simple truncation.
- The observed saturation of ROUGE suggests developing task-specific clinical utility metrics to evaluate such routing methods.
Load-bearing premise
That the RCD objective can be defined and optimized so the chosen subsets produce meaningfully better downstream LLM performance on clinical tasks than simpler baselines.
What would settle it
If the same experiments found that RCD selection produced no consistent gains in ROUGE, BERTScore, or LLM output quality over positional or random baselines at multiple budget levels, the utility of the objective would be falsified.
Figures



read the original abstract
A key challenge for large language models is token cost per query and overall deployment cost. Clinical inputs are long, heterogeneous, and often redundant, while downstream tasks are short and high stakes. We study budgeted context selection, where a subset of document units is chosen under a strict token budget so an off-the-shelf generator can meet fixed cost and latency constraints. We cast this as a knapsack-constrained subset selection problem with two design choices, unitization that defines document segmentation and selection that determines which units are kept. We propose \textbf{RCD}, a monotone submodular objective that balances relevance, coverage, and diversity. We compare sentence, section, window, and cluster-based unitization, and introduce a routing heuristic that adapts to the budget regime. Experiments on MIMIC discharge notes, Cochrane abstracts, and L-Eval show that optimal strategies depend on the evaluation setting. Positional heuristics perform best at low budgets in extractive tasks, while diversity-aware methods such as MMR improve LLM generation. Selector choice matters more than unitization, with cluster-based grouping reducing performance and other schemes behaving similarly. ROUGE saturates for LLM summaries, while BERTScore better reflects quality differences. We release our code at https://github.com/stone-technologies/ACL_budget_paper.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes RCD, a monotone submodular objective combining relevance, coverage, and diversity terms for budgeted subset selection from long clinical documents. It frames the problem as a knapsack-constrained selection with design choices in unitization (sentence, section, window, cluster) and selection (including positional heuristics, MMR, and a proposed routing heuristic that adapts to budget). Experiments on MIMIC discharge notes, Cochrane abstracts, and L-Eval compare these across extractive and generative tasks, concluding that selector choice dominates unitization, positional methods win at low budgets for extractive settings, diversity-aware selectors help LLM generation, cluster unitization underperforms, and BERTScore differentiates quality better than saturating ROUGE. Code is released.
Significance. If the empirical findings hold, the work provides a principled, optimizable framework for cost-constrained context selection in clinical NLP, with practical guidance on strategy selection by budget and task type. Strengths include explicit verification that RCD is monotone and submodular, use of a standard greedy knapsack algorithm with cited approximation guarantees, and public code release supporting reproducibility.
major comments (2)
- [§4] §4 (experimental results): The claims that 'selector choice matters more than unitization' and that 'positional heuristics perform best at low budgets' are presented without error bars, standard deviations, or statistical significance tests across the reported ROUGE/BERTScore differences; this weakens the load-bearing conclusion that optimal strategies depend on the evaluation setting.
- [§3.2] §3.2 (RCD formulation): While the relevance, coverage, and diversity functions are stated to be monotone and submodular, the exact hyperparameter values (e.g., weights balancing the three terms or the diversity distance metric) and their sensitivity are not reported, leaving open whether the reported performance gains are robust or tied to specific tuning choices.
minor comments (3)
- [§1] The abstract and §1 refer to 'a routing heuristic that adapts to the budget regime' without a dedicated subsection or pseudocode; a brief algorithm box would clarify its relation to the greedy optimizer.
- Table captions and axis labels in the result figures do not consistently indicate the token budget values or the exact number of runs; this reduces clarity when comparing across datasets.
- [§2] A few citations to prior submodular summarization work (e.g., on MMR variants) appear only in passing; expanding the related-work paragraph would better situate the novelty of the combined RCD objective.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and outline the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [§4] §4 (experimental results): The claims that 'selector choice matters more than unitization' and that 'positional heuristics perform best at low budgets' are presented without error bars, standard deviations, or statistical significance tests across the reported ROUGE/BERTScore differences; this weakens the load-bearing conclusion that optimal strategies depend on the evaluation setting.
Authors: We agree that the absence of error bars and statistical tests limits the strength of these claims. In the revised version, we will rerun the key experiments with multiple random seeds (where applicable for stochastic components) and report standard deviations. We will also add pairwise statistical significance tests (e.g., paired t-tests with Bonferroni correction) between the top-performing selectors and unitization strategies at each budget level to support the conclusion that selector choice dominates unitization. revision: yes
-
Referee: [§3.2] §3.2 (RCD formulation): While the relevance, coverage, and diversity functions are stated to be monotone and submodular, the exact hyperparameter values (e.g., weights balancing the three terms or the diversity distance metric) and their sensitivity are not reported, leaving open whether the reported performance gains are robust or tied to specific tuning choices.
Authors: We appreciate this observation. The RCD objective uses equal weights of 1/3 for each term, with the diversity component computed via cosine distance on embeddings from a fixed sentence transformer model. We will add these exact values to §3.2 and include a sensitivity analysis (in the main text or appendix) showing performance variation under different weight combinations and alternative distance metrics. This will confirm that the reported gains are not overly sensitive to the chosen hyperparameters. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper defines the RCD objective explicitly in Section 3.2 as a sum of relevance, coverage, and diversity terms, verifies monotonicity and submodularity by direct check of the diminishing-returns property, and optimizes it via the standard greedy knapsack algorithm whose guarantee is cited from external literature. Experiments compare multiple unitization schemes and selectors on three independent external datasets (MIMIC, Cochrane, L-Eval) using ROUGE and BERTScore, with released code. No step reduces a claimed prediction or uniqueness result to a fitted parameter or self-citation by construction; the central claims rest on concrete definitions and empirical comparisons that are falsifiable outside the paper's own inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption RCD objective is monotone submodular
Reference graph
Works this paper leans on
-
[1]
American Hospital Association . 2025. Fast facts on U . S . hospitals. https://www.aha.org/statistics/fast-facts-us-hospitals. Accessed 2025-12-30
2025
-
[2]
Chen An, Shansan Gong, Kai Zhong, Ruiyi Lang, Shangyue Guo, Zhaoyi Li, Xin Yao, Jie Zhang, Yidong Zhao, Wei Liu, and Xipeng Qiu. 2024. https://aclanthology.org/2024.acl-long.776 L - E val: Instituting standardized evaluation for long context language models with real-world tasks . In Proceedings of the 62nd Annual Meeting of the Association for Computatio...
2024
-
[3]
Yushi Bai and 1 others. 2023. https://arxiv.org/abs/2308.14508 Long B ench: A bilingual, multitask benchmark for long context understanding . arXiv preprint arXiv:2308.14508
work page internal anchor Pith review arXiv 2023
-
[4]
Jaime Carbonell and Jade Goldstein. 1998. https://doi.org/10.1145/290941.291025 The use of MMR , diversity-based reranking for reordering documents and producing summaries . In Proceedings of the 21st Annual International ACM SIGIR Conference on Research and Development in Information Retrieval , pages 335--336
-
[5]
Arman Cohan, Franck Dernoncourt, Dong Suk Kim, Trung Bui, Seokhwan Kim, Walter Chang, and Nazli Goharian. 2018. A discourse-aware attention model for abstractive summarization of long documents. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short...
2018
-
[6]
Cheng Hsieh and 1 others. 2024. https://arxiv.org/abs/2404.06654 RULER : Scaling benchmarks for long context language models . arXiv preprint arXiv:2404.06654
work page internal anchor Pith review arXiv 2024
- [7]
-
[8]
Qiao Jin, Bhuwan Dhingra, Zhengping Liu, William Cohen, and Xinghua Lu. 2019. Pubmedqa: A dataset for biomedical research question answering. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 2567--2577
2019
-
[9]
Alistair E W Johnson, Tom J Pollard, Lu Shen, Li-wei H Lehman, Mengling Feng, Mohammad Ghassemi, Benjamin Moody, Peter Szolovits, Leo Anthony Celi, and Roger G Mark. 2023. https://doi.org/10.1038/s41597-022-01899-x MIMIC - IV , a freely accessible electronic health record dataset . Scientific Data, 10(1):1--13
-
[10]
Greg Kamradt. 2023. Needle in a haystack evaluations for long context models. https://github.com/gkamradt/LLMTest_NeedleInAHaystack. Accessed 2025-12-30
2023
- [11]
-
[12]
Alex Kulesza and Ben Taskar. 2012. https://doi.org/10.1561/2200000044 Determinantal point processes for machine learning . Foundations and Trends in Machine Learning, 5(2--3):123--286
-
[13]
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Deniz Kucuk, Mike Lewis, Wen-tau Yih, and Sebastian Riedel. 2020. https://arxiv.org/abs/2005.11401 Retrieval-augmented generation for knowledge-intensive NLP tasks . Advances in Neural Information Processing Systems, 33:9459--9474
work page internal anchor Pith review arXiv 2020
-
[14]
Chin-Yew Lin. 2004. Rouge: A package for automatic evaluation of summaries. Text Summarization Branches Out
2004
- [15]
-
[16]
Yang Liu and Mirella Lapata. 2019. Text summarization with pretrained encoders. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 3730--3740
2019
-
[17]
George L Nemhauser, Laurence A Wolsey, and Marshall L Fisher. 1978. https://doi.org/10.1007/BF01588971 An analysis of approximations for maximizing submodular set functions . Mathematical Programming, 14(1):265--294
-
[18]
OpenAI . 2025. Openai API pricing. https://openai.com/api/pricing/. Accessed 2025-12-30
2025
-
[19]
S. Trent Rosenbloom, William W. Stead, Joshua C. Denny, Dario Giuse, Nancy M. Lorenzi, Steven H. Brown, and Kevin B. Johnson. 2010. https://doi.org/10.4338/ACI-2010-03-RA-0019 Generating clinical notes for electronic health record systems . Applied Clinical Informatics, 1(3):232--243
-
[20]
Liu, and Christopher D
Abigail See, Peter J. Liu, and Christopher D. Manning. 2017. https://aclanthology.org/P17-1099/ Get to the point: Summarization with pointer-generator networks . In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1073--1083
2017
-
[21]
Eva Sharma, Chen Li, and Lu Wang. 2019. Bigpatent: A large-scale dataset for abstractive and coherent summarization. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 2204--2213
2019
-
[22]
Maxim Sviridenko. 2004. A note on maximizing a submodular set function subject to a knapsack constraint. In Proceedings of the 13th Annual ACM - SIAM Symposium on Discrete Algorithms , pages 1020--1021
2004
-
[23]
Tianyi Zhang, Varsha Kishore, Felix Wu, Kilian Q Weinberger, and Yoav Artzi. 2020. Bertscore: Evaluating text generation with bert. In International Conference on Learning Representations
2020
-
[24]
Yutong Zhang and 1 others. 2024. Benchmarking large language models for medical evidence summarization. Nature Machine Intelligence, 6
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.