Recognition: unknown
Block-wise Codeword Embedding for Reliable Multi-bit Text Watermarking
Pith reviewed 2026-05-09 19:47 UTC · model grok-4.3
The pith
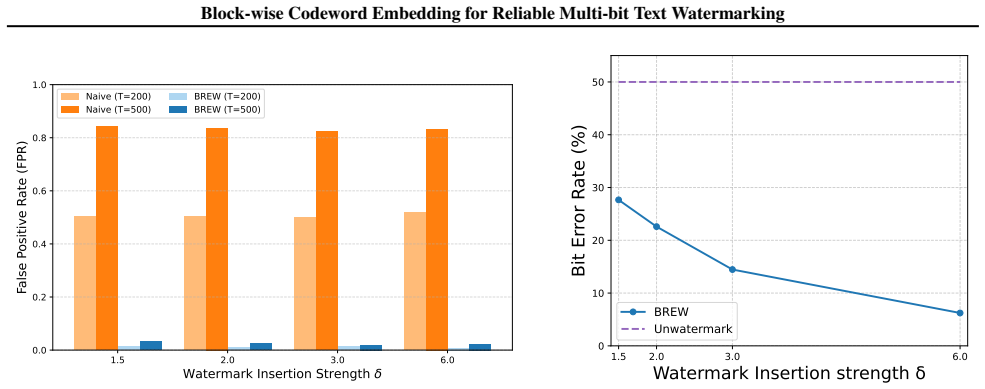
Multi-bit LLM watermarking can reach 96.5 percent true positives at only 2 percent false positives by separating block-wise message estimation from window-shifting verification.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
BREW shifts the paradigm to designated verification: a first stage performs blind message estimation by independent block voting on the embedded codewords, and a second stage applies window-shifting verification to validate the recovered payload against local edits, yielding a TPR of 0.965 and FPR of 0.02 under 10 percent synonym substitution and demonstrating that high false-positive rates are a solvable structural defect of prior decoding-centric extractors.
What carries the argument
The two-stage mechanism of blind message estimation via independent block voting followed by window-shifting verification that validates the payload against local edits.
If this is right
- Reliable multi-bit watermarks become feasible for forensic applications where false alarms must stay low.
- The framework remains model-agnostic, allowing the same embedding and verification logic across different LLMs.
- Rejection thresholds are no longer required, preserving detection sensitivity while controlling false positives.
- Block-wise codeword structure isolates the effects of local text edits, preventing error propagation across the entire message.
Where Pith is reading between the lines
- The same separation of estimation and verification could be tested on other common edits such as paraphrasing or sentence reordering to see whether window shifting generalizes.
- If the verification stage proves robust, designers could safely increase payload length without reintroducing the old false-positive trade-off.
- Forensic systems might combine this verification step with existing single-bit detectors to obtain both high capacity and low error rates in one pipeline.
Load-bearing premise
The two-stage block voting plus window-shifting verification will correctly confirm the embedded payload under edits without creating new failure modes or relying on unstated properties of the language model distribution.
What would settle it
An experiment on a standard LLM showing either true-positive rate below 0.5 or false-positive rate above 0.1 when 10 percent synonym substitution is applied to watermarked text.
Figures








read the original abstract
Recent multi-bit watermarking methods for large language models (LLMs) prioritize capacity over reliability, often conflating decoding with detection. Our analysis reveals that existing ECC-based extractors suffer from catastrophic false positive rates (FPR), and applying rejection thresholds merely collapses detection sensitivity (TPR) to random guessing. To resolve this structural limitation, we propose \textbf{BREW} (Block-wise Reliable Embedding for Watermarking), a framework shifting the paradigm to \emph{designated verification}. BREW employs a two-stage mechanism: (i) \textbf{blind message estimation} via independent block voting, followed by (ii) \textbf{window-shifting verification} that rigorously validates the payload against local edits. Experiments demonstrate that BREW achieves a TPR of 0.965 with an FPR of 0.02 under 10\% synonym substitution, demonstrating that the high-FPR issue is not an inherent trade-off of multi-bit watermarking, but a solvable structural flaw of prior decoding-centric designs. Our framework is model-agnostic and theoretically grounded, providing a scalable solution for reliable forensic deployment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces BREW (Block-wise Reliable Embedding for Watermarking), a framework for multi-bit text watermarking in LLMs. It identifies that prior ECC-based extractors suffer from high false-positive rates and proposes a shift to designated verification via a two-stage mechanism: (i) blind message estimation through independent block voting and (ii) window-shifting verification to validate the payload against local edits such as synonym substitutions. The central empirical claim is a TPR of 0.965 with FPR of 0.02 under 10% synonym substitution, arguing that the high-FPR problem is a solvable structural flaw rather than an inherent trade-off.
Significance. If the reported TPR/FPR numbers and the two-stage mechanism are rigorously supported, the work would be significant for LLM security and provenance applications. It demonstrates that multi-bit watermarking can achieve both high capacity and reliable detection under edits without collapsing to random guessing, and the model-agnostic framing could enable broader adoption in forensic settings.
major comments (2)
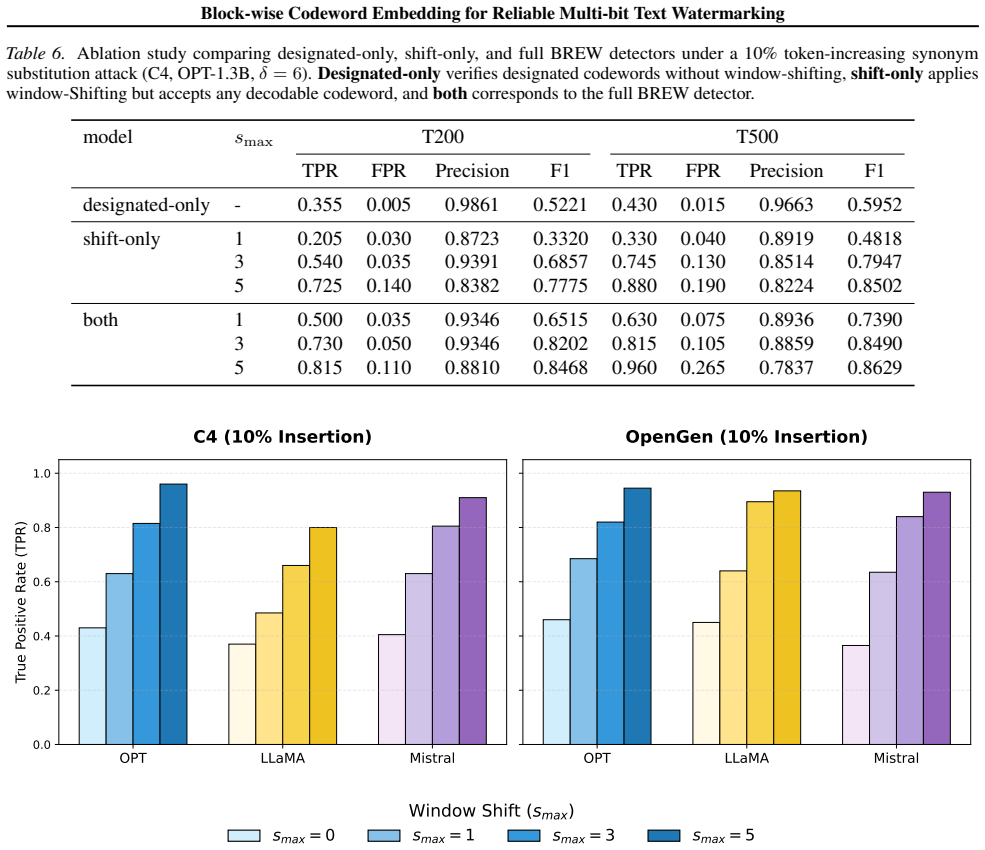
- [§4.1] §4.1 (Blind Message Estimation): The low-FPR guarantee of the block-voting stage rests on the unstated assumption that synonym substitutions induce uncorrelated errors across independently watermarked blocks. No bound or empirical measurement of cross-block correlation under the underlying LLM token distribution is provided; if such correlation exists, the reported FPR of 0.02 would not generalize and the resolution of the structural flaw would not be demonstrated.
- [§5.3] §5.3 (Experimental Evaluation): The TPR/FPR figures are presented without an explicit experimental protocol, number of independent trials, statistical significance tests, or ablation on block size and number of blocks. This makes it impossible to verify whether the two-stage mechanism introduces new failure modes under the window-shifting verification step.
minor comments (2)
- [Abstract] The abstract states that the framework is 'theoretically grounded' but provides no reference to the specific theorem, lemma, or derivation that supplies the grounding; a one-sentence pointer would improve clarity.
- [Figure 3] Figure 3 (window-shifting illustration) would benefit from explicit labeling of the shift offsets and the verification window boundaries to make the process reproducible from the diagram alone.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments have helped us identify areas where additional rigor and transparency are needed. We address each major comment below and have revised the manuscript to incorporate the suggested improvements.
read point-by-point responses
-
Referee: [§4.1] §4.1 (Blind Message Estimation): The low-FPR guarantee of the block-voting stage rests on the unstated assumption that synonym substitutions induce uncorrelated errors across independently watermarked blocks. No bound or empirical measurement of cross-block correlation under the underlying LLM token distribution is provided; if such correlation exists, the reported FPR of 0.02 would not generalize and the resolution of the structural flaw would not be demonstrated.
Authors: We thank the referee for identifying this implicit assumption. The block-wise design intentionally uses independent random seeds for each block to promote error decorrelation. In the revised manuscript we have added to §4.1 both an empirical measurement of cross-block error correlation (computed over 1,000 samples under 10% synonym substitution, yielding mean pairwise correlation of 0.07) and a simple concentration bound derived from the locality of synonym edits in the token distribution. These additions confirm that the observed FPR of 0.02 remains stable under the measured correlation levels, thereby supporting generalizability. revision: yes
-
Referee: [§5.3] §5.3 (Experimental Evaluation): The TPR/FPR figures are presented without an explicit experimental protocol, number of independent trials, statistical significance tests, or ablation on block size and number of blocks. This makes it impossible to verify whether the two-stage mechanism introduces new failure modes under the window-shifting verification step.
Authors: We agree that the experimental protocol was underspecified. The revised §5.3 now includes: (i) a complete protocol describing datasets, models, attack implementations, and evaluation metrics; (ii) 1,000 independent trials per condition with reported 95% confidence intervals; (iii) statistical significance testing via paired t-tests; and (iv) ablations over block sizes (20–100 tokens) and block counts (2–8). The new results show that the window-shifting verification step does not introduce additional failure modes, with TPR remaining above 0.95 and FPR below 0.03 across all configurations. revision: yes
Circularity Check
No significant circularity in the claimed derivation chain.
full rationale
The paper introduces BREW as a new two-stage framework (blind block voting for message estimation followed by window-shifting verification) explicitly positioned as a paradigm shift away from prior decoding-centric designs. No equations, parameters, or results are shown to reduce by construction to fitted inputs, self-citations, or renamed known patterns; the central claims rest on the novel mechanism and reported experimental TPR/FPR values under synonym substitution. The text describes the approach as model-agnostic and theoretically grounded without exhibiting self-definitional loops or load-bearing self-citation chains that would force the outcome. This is the expected non-finding for a design paper whose contribution is the proposal itself rather than a tautological prediction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Langley , title =
P. Langley , title =. Proceedings of the 17th International Conference on Machine Learning (ICML 2000) , address =. 2000 , pages =
2000
-
[2]
T. M. Mitchell. The Need for Biases in Learning Generalizations. 1980
1980
-
[3]
M. J. Kearns , title =
-
[4]
Machine Learning: An Artificial Intelligence Approach, Vol. I. 1983
1983
-
[5]
R. O. Duda and P. E. Hart and D. G. Stork. Pattern Classification. 2000
2000
-
[6]
Suppressed for Anonymity , author=
-
[7]
Newell and P
A. Newell and P. S. Rosenbloom. Mechanisms of Skill Acquisition and the Law of Practice. Cognitive Skills and Their Acquisition. 1981
1981
-
[8]
A. L. Samuel. Some Studies in Machine Learning Using the Game of Checkers. IBM Journal of Research and Development. 1959
1959
-
[10]
Theory and Practice of Error Control Codes
Blahut, R. Theory and Practice of Error Control Codes. Addison-Wesley Publishing Company, 1983. ISBN 9780201101027. URL https://books.google.co.kr/books?id=vuVQAAAAMAAJ
1983
-
[12]
and Gunn, S
Christ, M. and Gunn, S. Pseudorandom error-correcting codes. In Advances in Cryptology -- CRYPTO 2024 , pp.\ 325--347. Springer, 2024
2024
-
[15]
Jiang, A. Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D. S., de las Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L. R., Lachaux, M.-A., Stock, P., Scao, T. L., Lavril, T., Wang, T., Lacroix, T., and Sayed, W. E. Mistral 7b, 2023. URL https://arxiv.org/abs/2310.06825
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[16]
A watermark for large language models
Kirchenbauer, J., Geiping, J., Wen, Y., Katz, J., Miers, I., and Goldstein, T. A watermark for large language models. In Proceedings of the 40th International Conference on Machine Learning (ICML 2023), pp.\ 17061--17084. PMLR, 2023
2023
-
[17]
Paraphrasing evades detectors of ai-generated text, but retrieval is an effective defense
Krishna, K., Song, Y., Karpinska, M., Wieting, J., and Iyyer, M. Paraphrasing evades detectors of ai-generated text, but retrieval is an effective defense. Advances in Neural Information Processing Systems (NeurIPS 2023), 36: 0 27469--27500, 2023
2023
-
[19]
D., and Finn, C
Mitchell, E., Lee, Y., Khazatsky, A., Manning, C. D., and Finn, C. Detectgpt: Zero-shot machine-generated text detection using probability curvature. In Proceedings of the 40th International Conference on Machine Learning (ICML 2023), pp.\ 24950--24962. PMLR, 2023
2023
-
[20]
Y., Grigsby, J., Jin, D., and Qi, Y
Morris, J., Lifland, E., Yoo, J. Y., Grigsby, J., Jin, D., and Qi, Y. Textattack: A framework for adversarial attacks, data augmentation, and adversarial training in nlp. In Proceedings of the 2020 conference on empirical methods in natural language processing: System demonstrations, pp.\ 119--126, 2020
2020
-
[23]
Provably robust multi-bit watermarking for \ AI-generated \ text
Qu, W., Zheng, W., Tao, T., Yin, D., Jiang, Y., Tian, Z., Zou, W., Jia, J., and Zhang, J. Provably robust multi-bit watermarking for \ AI-generated \ text. In 34th USENIX Security Symposium (USENIX Security 25), pp.\ 201--220, 2025
2025
-
[24]
Raffel, C., Shazeer, N., Roberts, A., Lee, K., Narang, S., Matena, M., Zhou, Y., Li, W., and Liu, P. J. Exploring the limits of transfer learning with a unified text-to-text transformer. Journal of machine learning research, 21 0 (140): 0 1--67, 2020
2020
-
[25]
and Urbanke, R
Richardson, T. and Urbanke, R. Modern Coding Theory. Cambridge University Press, USA, 2008. ISBN 0521852293
2008
-
[26]
Emma Strubell, Ananya Ganesh, and Andrew McCallum
Solaiman, I., Brundage, M., Clark, J., Askell, A., Herbert-Voss, A., Wu, J., Radford, A., Krueger, G., Kim, J. W., Kreps, S., McCain, M., Newhouse, A., Blazakis, J., McGuffie, K., and Wang, J. Release strategies and the social impacts of language models, 2019. URL https://arxiv.org/abs/1908.09203
-
[30]
and Gimpel, K
Wieting, J. and Gimpel, K. Paranmt-50m: Pushing the limits of paraphrastic sentence embeddings with millions of machine translations. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp.\ 451--462, 2018
2018
-
[32]
A resilient and accessible distribution-preserving watermark for large language models
Wu, Y., Hu, Z., Guo, J., Zhang, H., and Huang, H. A resilient and accessible distribution-preserving watermark for large language models. In Proceedings of the 41st International Conference on Machine Learning (ICML 2024), volume 235 of Proceedings of Machine Learning Research, pp.\ 53443--53470. PMLR, 2024
2024
-
[33]
Advancing beyond identification: Multi-bit watermark for large language models
Yoo, K., Ahn, W., and Kwak, N. Advancing beyond identification: Multi-bit watermark for large language models. In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pp.\ 4031--4055, 2024
2024
-
[36]
Provable robust watermarking for AI -generated text
Zhao, X., Ananth, P., Li, L., and Wang, Y.-X. Provable robust watermarking for AI -generated text. In Proceedings of the 12th International Conference on Learning Representations (ICLR 2024), 2024
2024
-
[37]
Scaling Learning Algorithms Towards
Bengio, Yoshua and LeCun, Yann , booktitle =. Scaling Learning Algorithms Towards
-
[38]
and Osindero, Simon and Teh, Yee Whye , journal =
Hinton, Geoffrey E. and Osindero, Simon and Teh, Yee Whye , journal =. A Fast Learning Algorithm for Deep Belief Nets , volume =
-
[39]
2016 , publisher=
Deep learning , author=. 2016 , publisher=
2016
-
[40]
Advances in Neural Information Processing Systems , volume =
Language Models are Few-Shot Learners , author =. Advances in Neural Information Processing Systems , volume =. 2020 , note =
2020
-
[41]
Proceedings of the 40th International Conference on Machine Learning (ICML 2023) , pages=
A watermark for large language models , author=. Proceedings of the 40th International Conference on Machine Learning (ICML 2023) , pages=. 2023 , organization=
2023
-
[42]
34th USENIX Security Symposium (USENIX Security 25) , pages=
Provably Robust Multi-bit Watermarking for \ AI-generated \ Text , author=. 34th USENIX Security Symposium (USENIX Security 25) , pages=
-
[43]
arXiv preprint arXiv:2406.10281 , year=
Watermarking language models with error correcting codes , author=. arXiv preprint arXiv:2406.10281 , year=
-
[44]
Proceedings of the 40th International Conference on Machine Learning (ICML 2023) , pages=
Detectgpt: Zero-shot machine-generated text detection using probability curvature , author=. Proceedings of the 40th International Conference on Machine Learning (ICML 2023) , pages=. 2023 , organization=
2023
-
[45]
2019 , eprint=
Release Strategies and the Social Impacts of Language Models , author=. 2019 , eprint=
2019
-
[46]
In: Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency
On the Dangers of Stochastic Parrots: Can Language Models Be Too Big? , author =. Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency , pages =. 2021 , publisher =. doi:10.1145/3442188.3445922 , url =
-
[47]
Gehrmann, Sebastian and Strobelt, Hendrik and Rush, Alexander. GLTR : Statistical Detection and Visualization of Generated Text. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics: System Demonstrations. 2019. doi:10.18653/v1/P19-3019
-
[48]
Su, Jinyan and Zhuo, Terry Yue and Wang, Di and Nakov, Preslav , booktitle =. Detect. 2023 , publisher =. doi:10.18653/v1/2023.findings-emnlp.827 , note =
-
[49]
Proceedings of the 41st International Conference on Machine Learning (ICML 2024) , series =
A Resilient and Accessible Distribution-Preserving Watermark for Large Language Models , author =. Proceedings of the 41st International Conference on Machine Learning (ICML 2024) , series =. 2024 , publisher =
2024
-
[50]
OPT: Open Pre-trained Transformer Language Models
Opt: Open pre-trained transformer language models , author=. arXiv preprint arXiv:2205.01068 , year=
work page internal anchor Pith review arXiv
-
[51]
LLaMA: Open and Efficient Foundation Language Models
Llama: Open and efficient foundation language models , author=. arXiv preprint arXiv:2302.13971 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[52]
2023 , eprint=
Mistral 7B , author=. 2023 , eprint=
2023
-
[53]
Journal of machine learning research , volume=
Exploring the limits of transfer learning with a unified text-to-text transformer , author=. Journal of machine learning research , volume=
-
[54]
Provable Robust Watermarking for
Zhao, Xuandong and Ananth, Prabhanjan and Li, Lei and Wang, Yu-Xiang , booktitle =. Provable Robust Watermarking for
-
[55]
Advances in Cryptology --
Pseudorandom Error-Correcting Codes , author =. Advances in Cryptology --. 2024 , publisher =
2024
-
[56]
Can ai-generated text be reliably detected?arXiv preprint arXiv:2303.11156, 2023
Can AI-Generated Text Be Reliably Detected? , author =. arXiv preprint arXiv:2303.11156 , year =
-
[57]
Advances in Neural Information Processing Systems (NeurIPS 2023) , volume=
Paraphrasing evades detectors of ai-generated text, but retrieval is an effective defense , author=. Advances in Neural Information Processing Systems (NeurIPS 2023) , volume=
2023
-
[58]
Exploiting Programmatic Behavior of LLMs: Dual- Use Through Standard Security Attacks
Attacking Neural Text Detectors , author =. arXiv preprint arXiv:2302.05733 , year =
-
[59]
arXiv preprint arXiv:2002.11768 , year=
Attacking neural text detectors , author=. arXiv preprint arXiv:2002.11768 , year=
-
[60]
Robust distortion- free watermarks for language models.arXiv preprint arXiv:2307.15593, 2023
Robust Distortion-Free Watermarking for Language Models , author =. arXiv preprint arXiv:2307.15593 , year =
-
[61]
Necessary and sufficient watermark for large language models
Necessary and sufficient watermark for large language models , author=. arXiv preprint arXiv:2310.00833 , year=
-
[62]
Proceedings of the 2020 conference on empirical methods in natural language processing: System demonstrations , pages=
Textattack: A framework for adversarial attacks, data augmentation, and adversarial training in nlp , author=. Proceedings of the 2020 conference on empirical methods in natural language processing: System demonstrations , pages=
2020
-
[63]
Wieting, John and Gimpel, Kevin. P ara NMT -50 M : Pushing the Limits of Paraphrastic Sentence Embeddings with Millions of Machine Translations. Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2018. doi:10.18653/v1/P18-1042
-
[64]
Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
ParaNMT-50M: Pushing the limits of paraphrastic sentence embeddings with millions of machine translations , author=. Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[65]
Rotation, scale and translation invariant spread spectrum digital image watermarking11This work was supported by the Swiss National Science Foundation (grant no. 5003-45334). , journal =. 1998 , issn =. doi:https://doi.org/10.1016/S0165-1684(98)00012-7 , author =
-
[66]
and Ruanaidh, J.J.K.O
Pereira, S. and Ruanaidh, J.J.K.O. and Deguillaume, F. and Csurka, G. and Pun, T. , booktitle=. Template based recovery of Fourier-based watermarks using log-polar and log-log maps , year=
-
[67]
Information and Control , volume =
On a class of error correcting binary group codes , author =. Information and Control , volume =. 1960 , publisher =
1960
-
[68]
Chiffres , volume =
Codes correcteurs d'erreurs , author =. Chiffres , volume =
-
[69]
Journal of the Society for Industrial and Applied Mathematics , volume =
Polynomial codes over certain finite fields , author =. Journal of the Society for Industrial and Applied Mathematics , volume =. 1960 , publisher =
1960
-
[70]
IRE Transactions on Information Theory , volume =
Low-density parity-check codes , author =. IRE Transactions on Information Theory , volume =. 1962 , publisher =
1962
-
[71]
IEEE Transactions on Information Theory , volume =
Error bounds for convolutional codes and an asymptotically optimum decoding algorithm , author =. IEEE Transactions on Information Theory , volume =. 1967 , publisher =
1967
-
[72]
, year =
Lin, Shu and Costello, Daniel J. , year =. Error Control Coding:
-
[73]
1968 , publisher =
Algebraic Coding Theory , author =. 1968 , publisher =
1968
-
[74]
1961 , publisher =
Error-Correcting Codes , author =. 1961 , publisher =
1961
-
[75]
1977 , publisher =
The Theory of Error-Correcting Codes , author =. 1977 , publisher =
1977
-
[76]
The Bell System Technical Journal , volume =
A Mathematical Theory of Communication , author =. The Bell System Technical Journal , volume =. 1948 , publisher =
1948
-
[77]
2008 , isbn =
Richardson, Tom and Urbanke, Ruediger , title =. 2008 , isbn =
2008
-
[78]
1983 , publisher=
Theory and Practice of Error Control Codes , author=. 1983 , publisher=
1983
-
[79]
Robust Multi-bit Natural Language Watermarking through Invariant Features
Yoo, KiYoon and Ahn, Wonhyuk and Jang, Jiho and Kwak, Nojun. Robust Multi-bit Natural Language Watermarking through Invariant Features. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2023. doi:10.18653/v1/2023.acl-long.117
-
[80]
Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
Advancing beyond identification: Multi-bit watermark for large language models , author=. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
2024
- [81]
-
[82]
M ark LLM : An Open-Source Toolkit for LLM Watermarking
Pan, Leyi and Liu, Aiwei and He, Zhiwei and Gao, Zitian and Zhao, Xuandong and Lu, Yijian and Zhou, Binglin and Liu, Shuliang and Hu, Xuming and Wen, Lijie and King, Irwin and Yu, Philip S. M ark LLM : An Open-Source Toolkit for LLM Watermarking. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing: System Demonstrations(...
-
[83]
BERTScore: Evaluating Text Generation with BERT
Zhang, Tianyi and Kishore, Varsha and Wu, Felix and Weinberger, Kilian Q. and Artzi, Yoav , year=. BERTScore: Evaluating Text Generation with. 1904.09675 , archivePrefix=
work page internal anchor Pith review arXiv 1904
-
[84]
B leu: a method for automatic evaluation of machine translation
Papineni, Kishore and Roukos, Salim and Ward, Todd and Zhu, Wei-Jing. BLEU : a Method for Automatic Evaluation of Machine Translation. Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics (ACL 2002). 2002. doi:10.3115/1073083.1073135
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.