Recognition: 2 theorem links
· Lean TheoremGroup Cognition Learning: Making Everything Better Through Governed Two-Stage Agents Collaboration
Pith reviewed 2026-05-12 03:06 UTC · model grok-4.3
The pith
Group Cognition Learning uses two-stage agent collaboration to reduce modality dominance and spurious coupling in multimodal fusion.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Centralized multimodal learning compresses language, acoustic, and visual signals into a single fused representation but suffers from modality dominance where optimization ignores weaker yet informative modalities and from spurious modality coupling where models overfit to incidental cross-modal correlations. Group Cognition Learning addresses this with a two-stage protocol after modality-specific encoding: in Selective Interaction a Routing Agent proposes directed routes while an Auditing Agent assigns sample-wise gates to emphasize exchanges that yield positive marginal predictive gain; in Consensus Formation a Public-Factor Agent maintains an explicit shared factor and an AggregationAgent
What carries the argument
The two-stage governed collaboration protocol consisting of Selective Interaction (Routing Agent plus Auditing Agent) followed by Consensus Formation (Public-Factor Agent plus Aggregation Agent) that enforces gain-focused exchanges and contribution-aware weighting while preserving modality specializations.
If this is right
- Optimization no longer gravitates toward the path of least resistance and therefore incorporates information from weaker but still informative modalities.
- Models stop overfitting to incidental cross-modal correlations because only exchanges with positive marginal predictive gain are retained.
- Each modality representation is preserved as a distinct specialization channel rather than being fully compressed into one vector.
- State-of-the-art results are obtained on both regression and classification benchmarks across the three evaluated multimodal datasets.
- Analysis experiments confirm that the Routing, Auditing, Public-Factor, and Aggregation agents each contribute to the observed mitigation of dominance and coupling.
Where Pith is reading between the lines
- The same governed-agent pattern could be tested in non-multimodal settings where multiple feature groups risk one group dominating training.
- An explicit public factor that is maintained separately from modality channels offers a natural hook for inspecting what information the model treats as shared.
- The marginal-gain auditing step might be adapted as a general regularizer in any multi-component model to suppress low-value interactions.
- Scaling the four-agent design to datasets that contain more than three modalities would reveal whether additional specialized agents become necessary.
Load-bearing premise
The four specialized agents can be trained to reliably identify positive marginal predictive gain and contribution-aware weights without introducing new overfitting or requiring dataset-specific tuning that undermines generality.
What would settle it
If the full GCL system is compared on CMU-MOSI against a version where the Auditing Agent's gates are removed or fixed to allow all interactions, and the ablated version shows equal or higher performance, the necessity of selective gating for the claimed mitigation would be refuted.
Figures


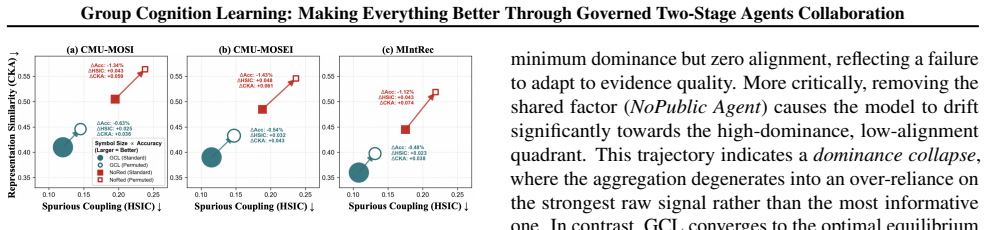

read the original abstract
Centralized multimodal learning commonly compresses language, acoustic, and visual signals into a single fused representation for prediction. While effective, this paradigm suffers from two limitations: modality dominance, where optimization gravitates towards the path of least resistance, ignoring weaker but informative modalities, and spurious modality coupling, where models overfit to incidental cross-modal correlations. To address these, we propose Group Cognition Learning (GCL), a governed collaboration paradigm that applies a two-stage protocol after modality-specific encoding. In Stage 1 (Selective Interaction), a Routing Agent proposes directed interaction routes, and an Auditing Agent assigns sample-wise gates to emphasize exchanges that yield positive marginal predictive gain while suppressing redundant coupling. In Stage 2 (Consensus Formation), a Public-Factor Agent maintains an explicit shared factor, and an Aggregation Agent produces the final prediction through contribution-aware weighting while keeping each modality representation as a specialization channel. Extensive experiments on CMU-MOSI, CMU-MOSEI, and MIntRec demonstrate that GCL mitigates dominance and coupling, establishing state-of-the-art results across both regression and classification benchmarks. Analysis experiments further demonstrate the effectiveness of the design.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Group Cognition Learning (GCL), a governed two-stage agent collaboration framework for multimodal learning. After modality-specific encoding, Stage 1 (Selective Interaction) uses a Routing Agent to propose interaction routes and an Auditing Agent to apply sample-wise gates emphasizing positive marginal predictive gain while suppressing redundant coupling. Stage 2 (Consensus Formation) employs a Public-Factor Agent to maintain a shared factor and an Aggregation Agent for final prediction via contribution-aware weighting, preserving modality specializations. The central claim is that this mitigates modality dominance and spurious coupling, yielding state-of-the-art regression and classification results on CMU-MOSI, CMU-MOSEI, and MIntRec, with supporting analysis experiments.
Significance. If the claimed performance gains and mitigation effects are substantiated by detailed experiments, GCL could offer a structured alternative to standard fusion methods in multimodal settings by explicitly governing inter-modality interactions. The two-stage protocol with specialized agents addresses recognized issues of dominance and incidental correlations in a potentially generalizable way, which might extend to other fusion tasks. However, the lack of any implementation specifics or results in the provided manuscript prevents a full evaluation of its significance.
major comments (2)
- [Abstract] Abstract: The assertion that GCL 'establishes state-of-the-art results across both regression and classification benchmarks' on CMU-MOSI, CMU-MOSEI, and MIntRec is unsupported by any metrics, tables, baseline comparisons, ablation studies, or quantitative evidence, which is load-bearing for the headline performance claim.
- [Abstract] Abstract: The key mechanisms of 'positive marginal predictive gain' (used by the Auditing Agent) and 'contribution-aware weighting' (used by the Aggregation Agent) are invoked to mitigate dominance and coupling but receive no mathematical definitions, training procedures, loss terms, or optimization details, preventing verification of the central mitigation claim.
minor comments (1)
- [Abstract] Abstract: The repeated use of informal phrasing such as 'Making Everything Better' in the title and 'governed collaboration paradigm' could be replaced with more precise technical language to improve clarity for a journal audience.
Simulated Author's Rebuttal
Thank you for the referee's constructive comments. We recognize the limitations in the provided abstract regarding supporting evidence and details, and we will revise the manuscript to address these issues comprehensively.
read point-by-point responses
-
Referee: [Abstract] Abstract: The assertion that GCL 'establishes state-of-the-art results across both regression and classification benchmarks' on CMU-MOSI, CMU-MOSEI, and MIntRec is unsupported by any metrics, tables, baseline comparisons, ablation studies, or quantitative evidence, which is load-bearing for the headline performance claim.
Authors: We agree that the abstract claim of establishing state-of-the-art results must be supported by quantitative evidence. The revised manuscript will include detailed experimental results, tables showing performance metrics on the specified datasets for both regression and classification, baseline comparisons, and ablation studies to substantiate these claims. We will update the manuscript accordingly during the revision. revision: yes
-
Referee: [Abstract] Abstract: The key mechanisms of 'positive marginal predictive gain' (used by the Auditing Agent) and 'contribution-aware weighting' (used by the Aggregation Agent) are invoked to mitigate dominance and coupling but receive no mathematical definitions, training procedures, loss terms, or optimization details, preventing verification of the central mitigation claim.
Authors: The abstract describes the high-level ideas behind these mechanisms. In the revised manuscript, we will introduce precise mathematical definitions. Positive marginal predictive gain will be defined as the difference in the model's predictive loss or accuracy when the interaction is included versus excluded, used to gate the routes. The Auditing Agent will optimize a loss term that encourages positive gain. Contribution-aware weighting will be defined using a weighted aggregation where weights are derived from each modality's contribution to the final prediction, estimated through dedicated sub-networks or attention mechanisms. Full training procedures, loss functions, and optimization details will be provided in the methods section. revision: yes
Circularity Check
No circularity: abstract contains no equations or derivations
full rationale
The abstract describes a two-stage agent protocol in natural language without any equations, parameters, or mathematical steps. No self-definitional reductions, fitted inputs renamed as predictions, or self-citation chains appear. Claims of mitigating dominance and coupling rest on unspecified experiments rather than a closed derivation that reduces to its inputs by construction. This is the expected non-finding when only a high-level method sketch is available.
Axiom & Free-Parameter Ledger
invented entities (4)
-
Routing Agent
no independent evidence
-
Auditing Agent
no independent evidence
-
Public-Factor Agent
no independent evidence
-
Aggregation Agent
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearStage 1 (Selective Interaction) uses Routing Agent to propose directed routes and Auditing Agent to assign sample-wise gates based on positive marginal predictive gain while suppressing redundant coupling via Lred (InfoNCE) and Lgain.
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanabsolute_floor_iff_bare_distinguishability unclearStage 2 maintains explicit public factor c via Public-Factor Agent and contribution-aware weighting πm via Aggregation Agent to prevent feature collapse.
Reference graph
Works this paper leans on
-
[1]
FirstName LastName , title =
-
[2]
Chunlei Meng and Jiacheng Yang and Wei Lin and Linqiang Hu and Bowen Liu and Zhuo Zou and LiDa Xu and Zhongxue Gan and Chun Ouyang , volume =. Multi-grained teacher–student joint representation learning for surface defect classification , journal =
-
[3]
2015 ieee information theory workshop (itw) , pages=
Deep learning and the information bottleneck principle , author=. 2015 ieee information theory workshop (itw) , pages=
work page 2015
-
[4]
Proceedings of the 28th ACM international conference on multimedia , pages=
Misa: Modality-invariant and-specific representations for multimodal sentiment analysis , author=. Proceedings of the 28th ACM international conference on multimedia , pages=
-
[5]
arXiv preprint arXiv:2401.11818 , year=
Mind: improving multimodal sentiment analysis via multimodal information disentanglement , author=. arXiv preprint arXiv:2401.11818 , year=
-
[6]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Joint multimodal transformer for emotion recognition in the wild , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[7]
Fine-grained disentangled representation learning for multimodal emotion recognition , author=. ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=. 2024 , organization=
work page 2024
-
[8]
Proceedings of the 30th ACM international conference on multimedia , pages=
Disentangled representation learning for multimodal emotion recognition , author=. Proceedings of the 30th ACM international conference on multimedia , pages=
-
[9]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Decoupled multimodal distilling for emotion recognition , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[10]
Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics , pages=
Confede: Contrastive feature decomposition for multimodal sentiment analysis , author=. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics , pages=
-
[11]
Proceedings of the AAAI conference on artificial intelligence , pages=
Scd-net: Spatiotemporal clues disentanglement network for self-supervised skeleton-based action recognition , author=. Proceedings of the AAAI conference on artificial intelligence , pages=
-
[12]
Computer Vision -- ECCV 2024 , pages=
Towards multimodal sentiment analysis debiasing via bias purification , author=. Computer Vision -- ECCV 2024 , pages=. 2024 , organization=
work page 2024
-
[13]
Proceedings of the 38th International Conference on Neural Information Processing Systems , volume=
Classifier-guided gradient modulation for enhanced multimodal learning , author=. Proceedings of the 38th International Conference on Neural Information Processing Systems , volume=
-
[14]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
D2r: Dual-branch dynamic routing network for multimodal sentiment detection , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
work page 2024
-
[15]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Multimodal prompting with missing modalities for visual recognition , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[16]
An Empirical Evaluation of Generic Convolutional and Recurrent Networks for Sequence Modeling
An empirical evaluation of generic convolutional and recurrent networks for sequence modeling , author=. arXiv preprint arXiv:1803.01271 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
IEEE Intelligent Systems , pages=
Multimodal sentiment intensity analysis in videos: Facial gestures and verbal messages , author=. IEEE Intelligent Systems , pages=
-
[18]
Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics , pages=
Multimodal language analysis in the wild: Cmu-mosei dataset and interpretable dynamic fusion graph , author=. Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics , pages=
-
[19]
2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages=
EMOE: Modality-Specific Enhanced Dynamic Emotion Experts , author=. 2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages=
work page 2025
-
[20]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
DLF: Disentangled-language-focused multimodal sentiment analysis , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[21]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Enriching multimodal sentiment analysis through textual emotional descriptions of visual-audio content , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[22]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Semi-IIN: Semi-supervised Intra-inter modal Interaction Learning Network for Multimodal Sentiment Analysis , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[23]
Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics , pages=
Multimodal transformer for unaligned multimodal language sequences , author=. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics , pages=
-
[24]
Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing , pages =
Tensor Fusion Network for Multimodal Sentiment Analysis , author =. Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing , pages =
work page 2017
-
[25]
arXiv preprint arXiv:1806.00064 , year=
Efficient low-rank multimodal fusion with modality-specific factors , author=. arXiv preprint arXiv:1806.00064 , year=
-
[26]
Proceedings of the AAAI conference on artificial intelligence , pages=
Learning modality-specific representations with self-supervised multi-task learning for multimodal sentiment analysis , author=. Proceedings of the AAAI conference on artificial intelligence , pages=
-
[27]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Progressive modality reinforcement for human multimodal emotion recognition from unaligned multimodal sequences , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[28]
arXiv preprint arXiv:2310.05804 , year=
Learning language-guided adaptive hyper-modality representation for multimodal sentiment analysis , author=. arXiv preprint arXiv:2310.05804 , year=
-
[29]
Proceedings of the 19th ACM International Conference on Multimodal Interaction , pages =
Multimodal sentiment analysis with word-level fusion and reinforcement learning , author =. Proceedings of the 19th ACM International Conference on Multimodal Interaction , pages =
-
[30]
Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics , pages =
Integrating Multimodal Information in Large Pretrained Transformers , author =. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics , pages =
-
[31]
Proceedings of the 30th ACM International Conference on Multimedia , pages =
Zhang, Hanlei and Xu, Hua and Wang, Xin and Zhou, Qianrui and Zhao, Shaojie and Teng, Jiayan , title =. Proceedings of the 30th ACM International Conference on Multimedia , pages =
-
[32]
Kamrul Hasan and Sangwu Lee and AmirAli Bagher Zadeh and Chengfeng Mao and Louis
Wasifur Rahman and Md. Kamrul Hasan and Sangwu Lee and AmirAli Bagher Zadeh and Chengfeng Mao and Louis. Integrating Multimodal Information in Large Pretrained Transformers , booktitle =
-
[33]
arXiv preprint arXiv:2410.11428 , year=
CTA-Net: A CNN-Transformer Aggregation Network for Improving Multi-Scale Feature Extraction , author=. arXiv preprint arXiv:2410.11428 , year=
-
[34]
RTS-ViT: Real-Time Share Vision Transformer for Image Classification , year=
Meng, Chunlei and Lin, Wei and Liu, Bowen and Zhang, Hongda and Gan, Zhongxue and Ouyang, Chun , journal=. RTS-ViT: Real-Time Share Vision Transformer for Image Classification , year=
-
[35]
Multimodal Transformers are Hierarchical Modal-wise Heterogeneous Graphs , author =. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[36]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Contextual augmented global contrast for multimodal intent recognition , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[37]
Neural Machine Translation by Jointly Learning to Align and Translate
Neural machine translation by jointly learning to align and translate , author=. arXiv preprint arXiv:1409.0473 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[38]
A discriminative feature learning approach for deep face recognition , author=. Computer vision--ECCV 2016: 14th European conference, amsterdam, the netherlands, October 11--14, 2016, proceedings, part VII 14 , pages=
work page 2016
-
[39]
International conference on machine learning , pages=
A simple framework for contrastive learning of visual representations , author=. International conference on machine learning , pages=
-
[40]
Jian and Zhongxue Gan and Chun Ouyang , journal=
Chunlei Meng and Guanhong Huang and Rong Fu and Runmin. Jian and Zhongxue Gan and Chun Ouyang , journal=
-
[41]
Meng, Chunlei and Zhou, Ziyang and He, Lucas and Du, Xiaojing and Ouyang, Chun and Gan, Zhongxue , booktitle=. Temporal-Spatial Decouple Before Act: Disentangled Representation Learning for Multimodal Sentiment Analysis , pages=
-
[42]
Mitigating Shared-Private Branch Imbalance via Dual-Branch Rebalancing for Multimodal Sentiment Analysis , author=. arXiv preprint arXiv:2604.25179 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[43]
Chunlei Meng and Jiabin Luo and Zhenglin Yan and Zhenyu Yu and Rong Fu and Zhongxue Gan and Chun Ouyang , journal=
-
[44]
Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , year =
Wei, Shicai and Luo, Chunbo and Luo, Yang , title =. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , year =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.