Recognition: unknown
Learning from Compressed CT: Feature Attention Style Transfer and Structured Factorized Projections for Resource-Efficient Medical Image Analysis
Pith reviewed 2026-05-09 20:02 UTC · model grok-4.3
The pith
A distillation framework lets AI detect abnormalities in JPEG-compressed chest CT scans with accuracy close to full-resolution models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors claim that their FAST method preserves activation patterns and structural relationships from high-fidelity CT data when training on compressed volumes, and that SFP provides a parameter-efficient projection alternative, allowing the overall CT-Lite model to reach AUROC scores within 5-7% of uncompressed baselines on the CT-RATE, NIDCH, and Rad-ChestCT datasets while using far fewer parameters.
What carries the argument
Feature Attention Style Transfer (FAST), a distillation approach that applies Gram-matrix-based attention style preservation together with dual-attention feature alignment to recover information from degraded compressed CT inputs.
If this is right
- CT-Lite achieves AUROC within 5-7% of the uncompressed baseline on three public CT datasets.
- It reduces projection-head parameters by almost half through structured factorization.
- The pipeline supports efficient electronic transfer of compressed volumes for AI diagnosis.
- Performance holds across multiple datasets despite JPEG compression artifacts.
Where Pith is reading between the lines
- Similar techniques might apply to other volumetric medical imaging like MRI to handle compression.
- Edge-device deployment becomes more feasible with the reduced parameter count.
- Testing on streaming compressed data in clinical workflows could validate real-world utility.
- Extensions could explore other compression standards beyond JPEG for broader compatibility.
Load-bearing premise
Gram-matrix attention style preservation and dual-attention feature alignment can recover diagnostic information lost during JPEG compression of CT volumes without creating misleading artifacts that affect abnormality detection.
What would settle it
Observing that CT-Lite misses a significant number of abnormalities or generates more false positives than the uncompressed baseline when evaluated on a large set of real-world JPEG-compressed clinical chest CT scans.
Figures






read the original abstract
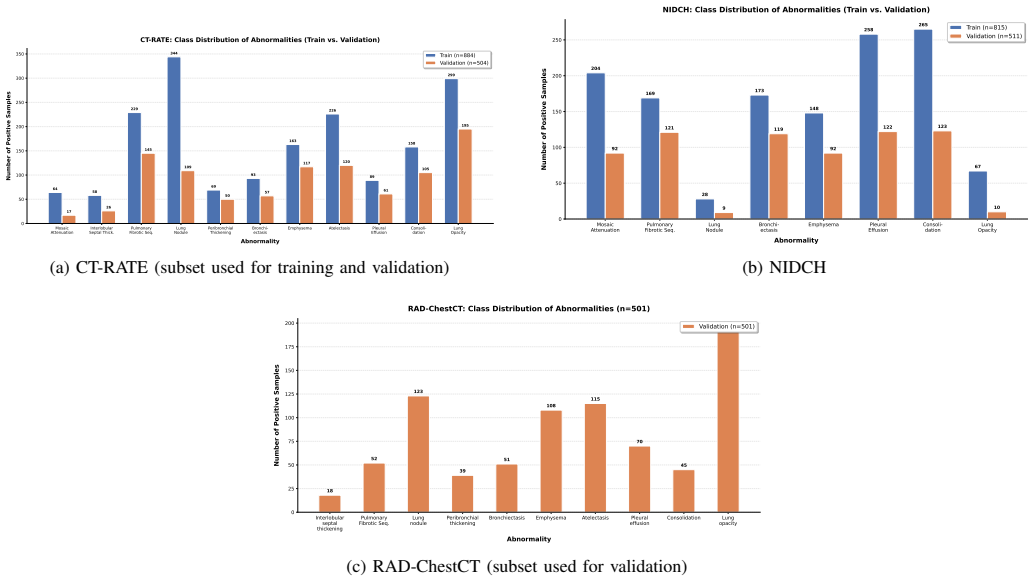
The deployment of artificial intelligence in medical imaging is hindered by high computational complexity and resource-intensive processing of volumetric data. Although chest computed tomography (CT) volumes offer richer diagnostic information than projection radiography, their use in AI-based diagnosis remains limited due to the computational burden of processing uncompressed volumetric images (typically stored in NIfTI or DICOM format). Addressing the growing need for low-resource deployment and efficient electronic data transfer, we investigate the utilization of JPEG-compressed chest CT volumes for thoracic abnormality detection. We propose Feature Attention Style Transfer (FAST), a novel distillation framework that transfers both activation patterns and structural relationships from high-fidelity CT representations to a spatiotemporal visual encoder operating on compressed inputs. By combining Gram-matrix-based attention style preservation with dual-attention feature alignment, FAST enables robust feature extraction from degraded volumes. Furthermore, we introduce Structured Factorized Projection (SFP), leveraging Block Tensor Train decomposition as a parameter-efficient alternative to dense projection layers, reducing projection-head parameters by almost half. Our contrastive learning pipeline, CT-Lite, integrates these components with a SigLIP-based multimodal alignment objective. Experiments on CT-RATE, NIDCH, and Rad-ChestCT demonstrate that CT-Lite achieves AUROC within 5-7\% of the uncompressed-input baseline across all three datasets, despite operating on compressed inputs with significantly fewer parameters, paving the way for AI-based clinical evaluation under resource constraints.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents CT-Lite, a resource-efficient framework for thoracic abnormality detection from JPEG-compressed chest CT volumes. It introduces Feature Attention Style Transfer (FAST), which uses Gram-matrix attention style preservation combined with dual-attention feature alignment to distill activation patterns and structural relationships from uncompressed to compressed inputs. Structured Factorized Projection (SFP) applies Block Tensor Train decomposition to reduce projection-head parameters by nearly half. These components are integrated into a SigLIP-based contrastive learning pipeline. Experiments on CT-RATE, NIDCH, and Rad-ChestCT report AUROC within 5-7% of the uncompressed-input baseline despite operating on compressed data with substantially fewer parameters.
Significance. If the reported performance holds, the work has clear significance for enabling AI-based analysis of volumetric medical images under resource constraints, including limited storage, bandwidth, and compute. Strengths include validation across three public datasets and explicit parameter reduction via tensor decomposition. The approach directly addresses a practical barrier to deploying CT-based models in clinical settings where uncompressed NIfTI/DICOM handling is prohibitive.
major comments (2)
- [Abstract and Experiments] Abstract and Experiments section: the central claim that CT-Lite achieves AUROC 'within 5-7%' of the uncompressed baseline requires accompanying standard deviations, confidence intervals, or statistical significance tests across multiple runs or folds. Without these, it is unclear whether the observed gaps are reliable or could be explained by run-to-run variance, which is load-bearing for the claim of near-parity performance.
- [Method (FAST)] Method (FAST description): the dual-attention alignment is presented as recovering diagnostic information lost to JPEG compression, but the manuscript should include an explicit analysis or ablation showing that the transferred features do not introduce systematic artifacts that could inflate or deflate abnormality detection on the specific tasks (e.g., via qualitative feature visualization or error-case breakdown). This is load-bearing because the empirical results are the only test of whether the style-transfer mechanism preserves clinical utility.
minor comments (3)
- [Abstract] Abstract: the phrase 'reducing projection-head parameters by almost half' should be replaced with the exact reduction ratio and the absolute parameter counts for both the baseline and SFP heads.
- [Method (SFP)] Related Work or Method: ensure the Block Tensor Train decomposition is compared quantitatively to other low-rank or factorized projection alternatives (e.g., Tucker or CP decomposition) to justify the specific choice.
- [Experiments] Figure captions and tables: verify that all reported AUROC values are accompanied by the exact compression ratio (e.g., JPEG quality factor) used for each dataset.
Simulated Author's Rebuttal
We thank the referee for the positive assessment and constructive feedback. We address each major comment below and will revise the manuscript accordingly to strengthen the statistical rigor and validation of the FAST component.
read point-by-point responses
-
Referee: [Abstract and Experiments] Abstract and Experiments section: the central claim that CT-Lite achieves AUROC 'within 5-7%' of the uncompressed baseline requires accompanying standard deviations, confidence intervals, or statistical significance tests across multiple runs or folds. Without these, it is unclear whether the observed gaps are reliable or could be explained by run-to-run variance, which is load-bearing for the claim of near-parity performance.
Authors: We agree that variability measures are necessary to substantiate the near-parity claim. The reported results were obtained from single-run evaluations per dataset and configuration. In the revision, we will re-execute the primary experiments across at least three random seeds, reporting mean AUROC values with standard deviations (and optionally 95% confidence intervals) in both the abstract and the Experiments section. This will confirm that the 5-7% gaps are stable and not attributable to run-to-run variance. revision: yes
-
Referee: [Method (FAST)] Method (FAST description): the dual-attention alignment is presented as recovering diagnostic information lost to JPEG compression, but the manuscript should include an explicit analysis or ablation showing that the transferred features do not introduce systematic artifacts that could inflate or deflate abnormality detection on the specific tasks (e.g., via qualitative feature visualization or error-case breakdown). This is load-bearing because the empirical results are the only test of whether the style-transfer mechanism preserves clinical utility.
Authors: We acknowledge the value of direct evidence that FAST preserves clinical utility without introducing task-specific artifacts. The current manuscript supports this indirectly through end-to-end AUROC gains over compressed baselines. In the revision, we will add a dedicated ablation subsection that (i) visualizes feature distributions (t-SNE) and attention maps with/without the dual-attention module, (ii) performs an error-case breakdown on misclassified samples across the three datasets, and (iii) reports the effect of removing Gram-matrix style preservation. These additions will explicitly demonstrate absence of systematic biases. revision: yes
Circularity Check
No significant circularity; empirical results stand independently
full rationale
The paper proposes FAST (Gram-matrix attention style transfer plus dual-attention alignment) and SFP (Block Tensor Train decomposition) as architectural components, then validates them via AUROC measurements on three public datasets (CT-RATE, NIDCH, Rad-ChestCT) against an uncompressed baseline. No equation or definition in the described pipeline reduces the reported performance metric to a fitted constant, self-referential quantity, or prior self-citation chain. The central claim follows from standard contrastive training and parameter reduction applied to external data; the derivation chain is self-contained and externally falsifiable.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
The shortage of radiographers: A global crisis in healthcare,
K. Konstantinidis, “The shortage of radiographers: A global crisis in healthcare,”Journal of medical imaging and radiation sciences, vol. 55, no. 4, p. 101333, 2024
2024
-
[2]
The growing problem of radiologist shortages: Perspec- tives from iran,
S. A. Mirak, “The growing problem of radiologist shortages: Perspec- tives from iran,”Korean Journal of Radiology, 2025
2025
-
[3]
The growing problem of radiologist shortages: Australia and new zealand’s perspective,
S. Jeganathan, “The growing problem of radiologist shortages: Australia and new zealand’s perspective,”Korean Journal of Radiology, vol. 24, no. 11, p. 1043, 2023
2023
-
[4]
The role of ai in mitigating the impact of radiologist shortages: a systematised review,
N. Achour, T. Zapata, Y . Saleh, B. Pierscionek, N. Azzopardi-Muscat, D. Novillo-Ortiz, C. Morgan, and M. Chaouali, “The role of ai in mitigating the impact of radiologist shortages: a systematised review,” Health and Technology, vol. 15, no. 3, pp. 489–501, 2025
2025
-
[5]
Ai solutions to the radiology workforce shortage,
A. B. Jing, N. Garg, J. Zhang, and J. J. Brown, “Ai solutions to the radiology workforce shortage,”npj Health Systems, vol. 2, no. 1, p. 20, 2025
2025
-
[6]
The promise of ai in advancing global radiology,
P. J. Slanetz, “The promise of ai in advancing global radiology,” p. e230895, 2023
2023
-
[7]
Generalist foundation models from a multimodal dataset for 3d computed tomography,
I. E. Hamamci, S. Er, C. Wang, F. Almas, A. G. Simsek, S. N. Esirgun, I. Dogan, O. F. Durugol, B. Hou, S. Shitet al., “Generalist foundation models from a multimodal dataset for 3d computed tomography,”Nature Biomedical Engineering, pp. 1–19, 2026
2026
-
[8]
Comprehensive language-image pre-training for 3d medical image understanding,
T. Wald, I. E. Hamamci, Y . Gao, S. Bond-Taylor, H. Sharma, M. Ilse, C. Lo, O. Melnichenko, A. Schwaighofer, N. C. F. Codella, M. T. Wetscherek, K. H. Maier-Hein, P. Korfiatis, V . Salvatelli, J. Alvarez-Valle, and P ´erez-Garc´ıa, “Comprehensive language-image pre-training for 3d medical image understanding,” 2026. [Online]. Available: https://arxiv.org/...
-
[9]
Large-scale and fine-grained vision-language pre-training for enhanced CT image understanding,
Z. Shui, J. Zhang, W. Cao, S. Wang, R. Guo, L. Lu, L. Yang, X. Ye, T. Liang, Q. Zhang, and L. Zhang, “Large-scale and fine-grained vision-language pre-training for enhanced CT image understanding,” in International Conference on Learning Representations (ICLR), 2025
2025
-
[10]
Determining optimal medical image compression: psycho- metric and image distortion analysis,
A. C. Flint, “Determining optimal medical image compression: psycho- metric and image distortion analysis,”BMC medical imaging, vol. 12, no. 1, p. 24, 2012
2012
-
[11]
arXiv preprint arXiv:2501.09001 (2025)
S. Pai, I. Hadzic, D. Bontempi, K. Bressem, B. H. Kann, A. Fedorov, R. H. Mak, and H. J. Aerts, “Vision foundation models for computed tomography,”arXiv preprint arXiv:2501.09001, 2025
-
[12]
V oco: A simple-yet-effective volume contrastive learning framework for 3d medical image analysis,
L. Wu, J. Zhuang, and H. Chen, “V oco: A simple-yet-effective volume contrastive learning framework for 3d medical image analysis,” inPro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2024, pp. 22 873–22 882
2024
-
[13]
Distilling the Knowledge in a Neural Network
G. Hinton, O. Vinyals, and J. Dean, “Distilling the knowledge in a neural network,” inNIPS Deep Learning and Representation Learning Workshop, 2015. [Online]. Available: http://arxiv.org/abs/1503.02531
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[14]
Direct distillation between different domains,
J. Tang, S. Chen, G. Niu, H. Zhu, J. T. Zhou, C. Gong, and M. Sugiyama, “Direct distillation between different domains,” inEuropean Conference on Computer Vision. Springer, 2024, pp. 154–172
2024
-
[15]
Vitkd: Feature- based knowledge distillation for vision transformers,
Z. Yang, Z. Li, A. Zeng, Z. Li, C. Yuan, and Y . Li, “Vitkd: Feature- based knowledge distillation for vision transformers,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 1379–1388
2024
-
[16]
Compute better spent: replacing dense layers with structured matri- ces,
S. Qiu, A. Potapczynski, M. Finzi, M. Goldblum, and A. G. Wilson, “Compute better spent: replacing dense layers with structured matri- ces,” inProceedings of the 41st International Conference on Machine Learning, 2024, pp. 41 698–41 716
2024
-
[17]
Sigmoid loss for language image pre-training,
X. Zhai, B. Mustafa, A. Kolesnikov, and L. Beyer, “Sigmoid loss for language image pre-training,” inProceedings of the IEEE/CVF international conference on computer vision, 2023, pp. 11 975–11 986
2023
-
[18]
Chestx-ray8: Hospital-scale chest x-ray database and benchmarks on weakly-supervised classification and localization of common thorax diseases,
X. Wang, Y . Peng, L. Lu, Z. Lu, M. Bagheri, and R. M. Summers, “Chestx-ray8: Hospital-scale chest x-ray database and benchmarks on weakly-supervised classification and localization of common thorax diseases,”CVPR, 2017
2017
-
[19]
Chexpert: A large chest radiograph dataset with uncertainty labels and expert comparison,
J. Irvin, P. Rajpurkar, M. Ko, Y . Yu, S. Ciurea-Ilcus, C. Chute, H. Mark- lund, B. Haghgoo, R. Ball, K. Shpanskayaet al., “Chexpert: A large chest radiograph dataset with uncertainty labels and expert comparison,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 33, no. 01, 2019, pp. 590–597
2019
-
[20]
Mimic-cxr, a de- identified publicly available database of chest radiographs with free-text reports,
A. E. Johnson, T. J. Pollard, S. J. Berkowitz, N. R. Greenbaum, M. P. Lungren, C.-y. Deng, R. G. Mark, and S. Horng, “Mimic-cxr, a de- identified publicly available database of chest radiographs with free-text reports,”Scientific Data, vol. 6, no. 1, p. 317, 2019
2019
-
[21]
Padchest: A large chest x-ray image dataset with multi-label annotated reports,
A. Bustos, A. Pertusa, J.-M. Salinas, and M. de la Iglesia-Vay ´a, “Padchest: A large chest x-ray image dataset with multi-label annotated reports,”Medical Image Analysis, 2020
2020
-
[22]
Vindr-cxr: An open dataset of chest x-rays with radiologist annotations,
H. Nguyenet al., “Vindr-cxr: An open dataset of chest x-rays with radiologist annotations,”Scientific Data, 2022
2022
-
[23]
Machine-learning-based multiple abnormality pre- diction with large-scale chest computed tomography volumes,
R. L. Draelos, D. Dov, M. A. Mazurowski, J. Y . Lo, R. Henao, G. D. Rubin, and L. Carin, “Machine-learning-based multiple abnormality pre- diction with large-scale chest computed tomography volumes,”Medical image analysis, vol. 67, p. 101857, 2021
2021
-
[24]
Deep residual learning for image recognition,
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 770–778
2016
-
[25]
Densely connected convolutional networks,
G. Huang, Z. Liu, L. Van Der Maaten, and K. Q. Weinberger, “Densely connected convolutional networks,” inProceedings of the IEEE confer- ence on computer vision and pattern recognition, 2017, pp. 4700–4708
2017
-
[26]
arXiv preprint arXiv:1711.05225 , year=
P. Rajpurkar, J. Irvin, K. Zhu, B. Yang, H. Mehta, T. Duan, D. Ding, A. Bagul, C. Langlotz, K. Shpanskaya, M. P. Lungren, and A. Y . Ng, “CheXNet: Radiologist-level pneumonia detection on chest x-rays with deep learning,”arXiv preprint arXiv:1711.05225, 2017
-
[27]
Comparison of deep learning approaches for multi-label chest x-ray classification,
I. M. Baltruschat, H. Nickisch, M. Grass, T. Knopp, and A. Saalbach, “Comparison of deep learning approaches for multi-label chest x-ray classification,”Scientific reports, vol. 9, no. 1, p. 6381, 2019
2019
-
[28]
An image is worth 16x16 words: Transformers for image recognition at scale,
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, J. Uszkoreit, and N. Houlsby, “An image is worth 16x16 words: Transformers for image recognition at scale,” inInternational Conference on Learning Representations, 2021. [Online]. Available: https://openreview.net/forum?id=YicbFdNTTy
2021
-
[29]
Training data-efficient image transformers & distillation through attention,
H. Touvron, M. Cord, M. Douze, F. Massa, A. Sablayrolles, and H. J ´egou, “Training data-efficient image transformers & distillation through attention,” inInternational conference on machine learning. PMLR, 2021, pp. 10 347–10 357
2021
-
[30]
Deit iii: Revenge of the vit,
H. Touvron, M. Cord, and H. J ´egou, “Deit iii: Revenge of the vit,” in European conference on computer vision. Springer, 2022, pp. 516–533
2022
-
[31]
Multi-task vision transformer using low- level chest x-ray feature corpus for COVID-19 diagnosis and severity quantification,
S. Park, G. Kim, Y . Oh, J. B. Seo, S. M. Lee, J. H. Kim, S. Moon, J.-K. Lim, C. M. Park, and J. C. Ye, “Multi-task vision transformer using low- level chest x-ray feature corpus for COVID-19 diagnosis and severity quantification,”Medical Image Analysis, vol. 75, p. 102299, 2022
2022
-
[32]
xViT- COS: Explainable vision transformer based COVID-19 screening using radiography,
A. K. Mondal, A. Bhattacharjee, P. Singla, and A. P. Prathosh, “xViT- COS: Explainable vision transformer based COVID-19 screening using radiography,”IEEE Journal of Translational Engineering in Health and Medicine, vol. 10, pp. 1–10, 2022
2022
-
[33]
Masked au- toencoders are scalable vision learners,
K. He, X. Chen, S. Xie, Y . Li, P. Doll ´ar, and R. Girshick, “Masked au- toencoders are scalable vision learners,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 16 000–16 009
2022
-
[34]
Delving into masked autoen- coders for multi-label thorax disease classification,
J. Xiao, Y . Bai, A. Yuille, and Z. Zhou, “Delving into masked autoen- coders for multi-label thorax disease classification,” inProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), 2023, pp. 3588–3600
2023
-
[35]
Self pre- training with masked autoencoders for medical image classification and segmentation,
L. Zhou, H. Liu, J. Bae, J. He, D. Samaras, and P. Prasanna, “Self pre- training with masked autoencoders for medical image classification and segmentation,” inIEEE International Symposium on Biomedical Imaging (ISBI), 2023, pp. 1–6
2023
-
[36]
Momentum contrast for unsupervised visual representation learning,
K. He, H. Fan, Y . Wu, S. Xie, and R. Girshick, “Momentum contrast for unsupervised visual representation learning,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 9729–9738
2020
-
[37]
A simple framework for contrastive learning of visual representations,
T. Chen, S. Kornblith, M. Norouzi, and G. Hinton, “A simple framework for contrastive learning of visual representations,” inInternational conference on machine learning. PmLR, 2020, pp. 1597–1607
2020
-
[38]
Emerging properties in self-supervised vision transformers,
M. Caron, H. Touvron, I. Misra, H. J ´egou, J. Mairal, P. Bojanowski, and A. Joulin, “Emerging properties in self-supervised vision transformers,” inProceedings of the IEEE/CVF international conference on computer vision, 2021, pp. 9650–9660
2021
-
[39]
MoCo pretraining improves representation and transferability of chest X-ray models,
H. Sowrirajan, J. Yang, A. Y . Ng, and P. Rajpurkar, “MoCo pretraining improves representation and transferability of chest X-ray models,” in Medical Imaging with Deep Learning (MIDL). PMLR, 2021, pp. 728– 744
2021
-
[40]
Big self-supervised models advance medical image classi- fication,
S. Azizi, B. Mustafa, F. Ryan, Z. Beaver, J. Freyberg, J. Deaton, A. Loh, A. Karthikesalingam, S. Kornblith, T. Chen, V . Natarajan, and M. Norouzi, “Big self-supervised models advance medical image classi- fication,” inProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2021, pp. 3478–3488
2021
-
[41]
Robust and data-efficient generalization of self-supervised machine learning for diagnostic imaging,
S. Azizi, L. Culp, J. Freyberg, B. Mustafa, S. Baur, S. Kornblith, T. Chen, N. Tomasev, J. Mitrovi ´c, P. Strachanet al., “Robust and data-efficient generalization of self-supervised machine learning for diagnostic imaging,”Nature Biomedical Engineering, vol. 7, no. 6, pp. 756–779, 2023
2023
-
[42]
Vivit: A video vision transformer,
A. Arnab, M. Dehghani, G. Heigold, C. Sun, M. Lu ˇci´c, and C. Schmid, “Vivit: A video vision transformer,” inProceedings of the IEEE/CVF international conference on computer vision, 2021, pp. 6836–6846
2021
-
[43]
Is space-time attention all you need for video understanding?
G. Bertasius, H. Wang, and L. Torresani, “Is space-time attention all you need for video understanding?” inIcml, vol. 2, no. 3, 2021, p. 4
2021
-
[44]
Multiscale vision transformers,
H. Fan, B. Xiong, K. Mangalam, Y . Li, Z. Yan, J. Malik, and C. Feichten- hofer, “Multiscale vision transformers,” inProceedings of the IEEE/CVF international conference on computer vision, 2021, pp. 6824–6835
2021
-
[45]
Learning transferable visual models from natural language supervision,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clarket al., “Learning transferable visual models from natural language supervision,” inInternational conference on machine learning. PmLR, 2021, pp. 8748–8763
2021
-
[46]
Con- trastive learning of medical visual representations from paired images and text,
Y . Zhang, H. Jiang, Y . Miura, C. D. Manning, and C. P. Langlotz, “Con- trastive learning of medical visual representations from paired images and text,” inMachine learning for healthcare conference. PMLR, 2022, pp. 2–25
2022
-
[47]
Gloria: A multimodal global-local representation learning framework for label- efficient medical image recognition,
S.-C. Huang, L. Shen, M. P. Lungren, and S. Yeung, “Gloria: A multimodal global-local representation learning framework for label- efficient medical image recognition,” inProceedings of the IEEE/CVF international conference on computer vision, 2021, pp. 3942–3951
2021
-
[49]
Medclip: Contrastive learning from unpaired medical images and text,
Z. Wang, Z. Wu, D. Agarwal, and J. Sun, “Medclip: Contrastive learning from unpaired medical images and text,” inProceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, 2022, pp. 3876–3887
2022
-
[50]
Expert-level detection of pathologies from unannotated chest x-ray images via self-supervised learning,
E. Tiu, E. Talius, P. Patel, C. P. Langlotz, A. Y . Ng, and P. Rajpurkar, “Expert-level detection of pathologies from unannotated chest x-ray images via self-supervised learning,”Nature biomedical engineering, vol. 6, no. 12, pp. 1399–1406, 2022
2022
-
[51]
Towards scalable language-image pre-training for 3D medical imag- ing,
C. Zhao, A. Kondepudi, Y . Lyu, A. Rao, A. Chowdury, and X. Hou, “Towards scalable language-image pre-training for 3D medical imag- ing,”arXiv preprint arXiv:2505.21862, 2025
-
[52]
Bootstrapping chest CT image understanding by distilling knowledge from X-ray expert models,
W. Cao, J. Zhang, Y . Xia, T. C. Mok, Z. Li, X. Ye, L. Lu, J. Zheng, Y . Tang, and L. Zhang, “Bootstrapping chest CT image understanding by distilling knowledge from X-ray expert models,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024, pp. 11 333–11 343
2024
-
[53]
Boosting vision semantic density with anatomy normality modeling for medical vision-language pre- training,
W. Cao, J. Zhang, Z. Shui, S. Wang, Z. Chen, X. Li, L. Lu, X. Ye, T. Liang, Q. Zhang, and L. Zhang, “Boosting vision semantic density with anatomy normality modeling for medical vision-language pre- training,” inProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2025
2025
-
[54]
Multimodal large language models in medical imaging: Current state and future directions,
Y . Nam, D. Y . Kim, S. Kyung, J. Seo, J. M. Song, J. Kwon, J. Kim, W. Jo, H. Park, J. Sunget al., “Multimodal large language models in medical imaging: Current state and future directions,”Korean Journal of Radiology, vol. 26, no. 10, pp. 900–923, 2025
2025
-
[55]
Merlin: a computed tomography vision–language foundation model and dataset,
L. Blankemeier, A. Kumar, J. P. Cohen, J. Liu, L. Liu, D. Van Veen, S. J. S. Gardezi, H. Yu, M. Paschali, Z. Chen, J.-B. Delbrouck, E. Reis, R. Holland, C. Truyts, C. Bluethgen, Y . Wu, L. Lian, M. E. K. Jensen, S. Ostmeier, M. Varma, J. M. J. Valanarasu, Z. Fang, Z. Huo, Z. Nabulsi, D. Ardila, W.-H. Weng, E. A. Junior, N. Ahuja, J. Fries, N. H. Shah, G. ...
2026
-
[56]
A survey of vision-language pretraining for medical imaging,
N. Hayatet al., “A survey of vision-language pretraining for medical imaging,”Medical Image Analysis, 2022
2022
-
[57]
Multimodal alignment and fusion: A survey,
H. Tang and S. Li, “Multimodal alignment and fusion: A survey,”IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024
2024
-
[58]
Fitnets: Hints for thin deep nets,
A. Romero, N. Ballas, S. E. Kahou, A. Chassang, C. Gatta, and Y . Bengio, “Fitnets: Hints for thin deep nets,” in3rd International Conference on Learning Representations (ICLR), San Diego, CA, USA, 2015
2015
-
[59]
Paying more attention to attention: Improving the performance of convolutional neural networks via atten- tion transfer,
S. Zagoruyko and N. Komodakis, “Paying more attention to attention: Improving the performance of convolutional neural networks via atten- tion transfer,” inInternational Conference on Learning Representations, 2017
2017
-
[60]
Contrastive representation distilla- tion,
Y . Tian, D. Krishnan, and P. Isola, “Contrastive representation distilla- tion,” inInternational Conference on Learning Representations, 2020
2020
-
[61]
Relational knowledge distilla- tion,
W. Park, D. Kim, Y . Lu, and M. Cho, “Relational knowledge distilla- tion,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 3967–3976
2019
-
[62]
MiniViT: Compressing vision transformers with weight multiplexing,
J. Zhang, H. Peng, K. Wu, M. Liu, B. Xiao, J. Fu, and L. Yuan, “MiniViT: Compressing vision transformers with weight multiplexing,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022, pp. 12 145–12 154
2022
-
[63]
Scalekd: Strong vision transformers could be excellent teachers,
J. Fan, C. Li, X. Liu, and A. Yao, “Scalekd: Strong vision transformers could be excellent teachers,”Advances in Neural Information Processing Systems, vol. 37, pp. 63 290–63 315, 2024
2024
-
[64]
Restructuring the teacher and student in self-distillation,
Y . Zheng, C. Wang, C. Tao, S. Lin, J. Qian, and J. Wu, “Restructuring the teacher and student in self-distillation,”IEEE Transactions on Image Processing, vol. 33, pp. 5551–5563, 2024
2024
-
[65]
Heterogeneous knowledge distillation using information flow modeling,
N. Passalis, M. Tzelepi, and A. Tefas, “Heterogeneous knowledge distillation using information flow modeling,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020, pp. 2339–2348
2020
-
[66]
UniCompress: Enhancing multi-data medical image com- pression with knowledge distillation,
R. Yang, Y . Chen, Z. Zhang, X. Liu, Z. Li, K. He, Z. Xiong, J. Suo, and Q. Dai, “UniCompress: Enhancing multi-data medical image com- pression with knowledge distillation,”arXiv preprint arXiv:2405.16850, 2024
-
[67]
Spatio-temporal knowledge dis- tilled video vision transformer (STKD-VViT) for multimodal deepfake detection,
S. Usmani, S. Kumar, and D. Sadhya, “Spatio-temporal knowledge dis- tilled video vision transformer (STKD-VViT) for multimodal deepfake detection,”Neurocomputing, vol. 620, p. 129256, 2025
2025
-
[68]
Image style transfer using convolutional neural networks,
L. A. Gatys, A. S. Ecker, and M. Bethge, “Image style transfer using convolutional neural networks,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016, pp. 2414– 2423
2016
-
[69]
Learning both weights and connections for efficient neural networks,
S. Han, J. Pool, J. Tran, and W. J. Dally, “Learning both weights and connections for efficient neural networks,” inAdvances in Neural Information Processing Systems (NeurIPS), 2015
2015
-
[70]
Deep compression: Compressing deep neural networks with pruning, trained quantization and Huffman cod- ing,
S. Han, H. Mao, and W. J. Dally, “Deep compression: Compressing deep neural networks with pruning, trained quantization and Huffman cod- ing,” inInternational Conference on Learning Representations (ICLR), 2016
2016
-
[71]
The lottery ticket hypothesis: Finding sparse, trainable neural networks,
J. Frankle and M. Carbin, “The lottery ticket hypothesis: Finding sparse, trainable neural networks,” inInternational Conference on Learning Representations (ICLR), 2019
2019
-
[72]
Quantization and training of neural networks for efficient integer-arithmetic-only inference,
B. Jacob, S. Kligys, B. Chen, M. Zhu, M. Tang, A. Howard, H. Adam, and D. Kalenichenko, “Quantization and training of neural networks for efficient integer-arithmetic-only inference,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2018, pp. 2704–2713
2018
-
[73]
GPTQ: Accurate post-training quantization for generative pre-trained transformers,
E. Frantar, S. Ashkboos, T. Hoefler, and D. Alistarh, “GPTQ: Accurate post-training quantization for generative pre-trained transformers,” in International Conference on Learning Representations (ICLR), 2023
2023
-
[74]
QLoRA: Efficient finetuning of quantized LLMs,
T. Dettmers, A. Pagnoni, A. Holtzman, and L. Zettlemoyer, “QLoRA: Efficient finetuning of quantized LLMs,” inAdvances in Neural Infor- mation Processing Systems (NeurIPS), 2023
2023
-
[75]
Low-rank matrix factorization for deep neural network training with high-dimensional output targets,
T. N. Sainath, B. Kingsbury, V . Sindhwani, E. Arisoy, and B. Ramab- hadran, “Low-rank matrix factorization for deep neural network training with high-dimensional output targets,” inIEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2013, pp. 6655– 6659
2013
-
[76]
Exploiting linear structure within convolutional networks for efficient evaluation,
E. L. Denton, W. Zaremba, J. Bruna, Y . LeCun, and R. Fergus, “Exploiting linear structure within convolutional networks for efficient evaluation,” inAdvances in Neural Information Processing Systems (NeurIPS), 2014
2014
-
[77]
LoRA: Low-rank adaptation of large language models,
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, and W. Chen, “LoRA: Low-rank adaptation of large language models,” inInternational Conference on Learning Representations (ICLR), 2022
2022
-
[78]
Knowledge distillation: A survey,
J. Gou, B. Yu, S. J. Maybank, and D. Tao, “Knowledge distillation: A survey,”International Journal of Computer Vision, 2021
2021
-
[79]
Structured transforms for small-footprint deep learning,
V . Sindhwani, T. N. Sainath, and S. Kumar, “Structured transforms for small-footprint deep learning,” inAdvances in Neural Information Processing Systems (NeurIPS), 2015
2015
-
[80]
KronA: Parameter efficient tuning with Kronecker adapter,
A. Edalati, M. Tahaei, I. Kobyzev, V . P. Nia, J. J. Clark, and M. Reza- gholizadeh, “KronA: Parameter efficient tuning with Kronecker adapter,” inNeurIPS Workshop on Transfer Learning for Natural Language Processing, 2022
2022
-
[81]
Compression of deep convolutional neural networks for fast and low power mobile applications,
Y .-D. Kim, E. Park, S. Yoo, T. Choi, L. Yang, and D. Shin, “Compression of deep convolutional neural networks for fast and low power mobile applications,” inInternational Conference on Learning Representations (ICLR), 2016
2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.