Recognition: unknown
MSACT: Multistage Spatial Alignment for Stable Low-Latency Fine Manipulation
Pith reviewed 2026-05-09 19:15 UTC · model grok-4.3
The pith
A multistage spatial attention module with self-supervised temporal alignment reduces drift in low-latency manipulation policies.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Built on an action-chunking transformer with a pretrained ResNet backbone, the multistage spatial attention module produces task-relevant 2D attention points as an additional input modality for action prediction. A temporal alignment loss forces the predicted attention sequence at each step to match visual features observed in later frames, suppressing drift in a fully self-supervised manner. This combination improves localization stability and task performance on simulated and real fine-manipulation benchmarks while preserving the low-latency inference property of the base policy.
What carries the argument
The multistage spatial attention module that jointly extracts 2D attention points and predicts their future sequences under a temporal alignment loss.
If this is right
- Task success rates rise on both simulated and physical bimanual fine-manipulation benchmarks.
- Attention drift decreases relative to the baseline action-chunking policy under visual disturbances.
- Inference latency remains unchanged from the base policy under the tested hardware conditions.
- The method works with the same limited demonstration sets used by prior action-chunking approaches.
Where Pith is reading between the lines
- The same alignment idea could be tested on single-arm or non-bimanual tasks to check whether the stability gain generalizes beyond two-handed setups.
- If the 2D attention points prove reliable, they might serve as a lightweight substitute for 3D keypoints in other vision-based controllers.
- Combining the module with occasional online fine-tuning could further reduce drift in long-horizon deployments.
Load-bearing premise
The self-supervised temporal alignment loss will suppress drift and improve the vision-to-action mapping under limited data without requiring keypoint annotations.
What would settle it
Running the same tasks with the temporal alignment loss disabled and observing no measurable increase in attention drift or drop in success rate compared to the full model.
Figures




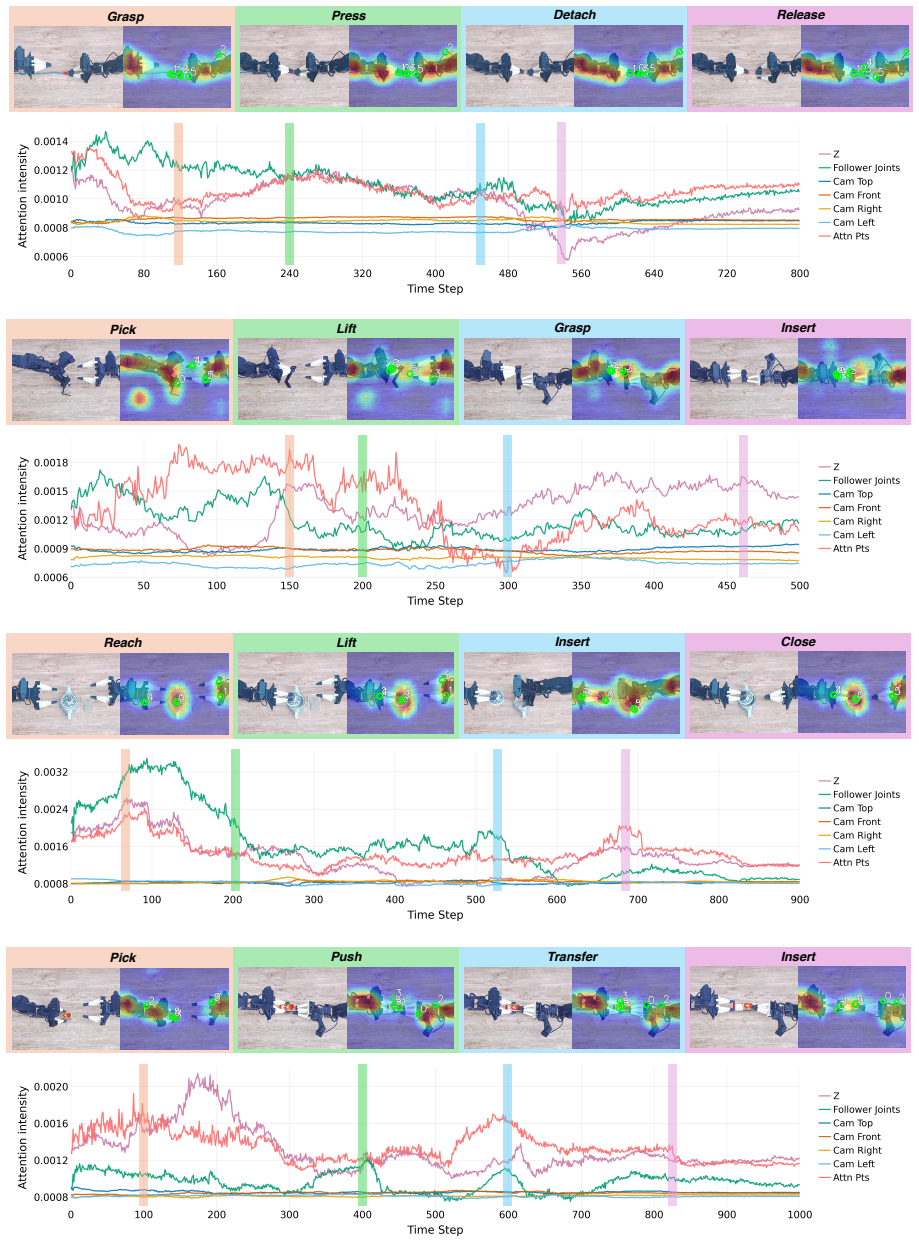
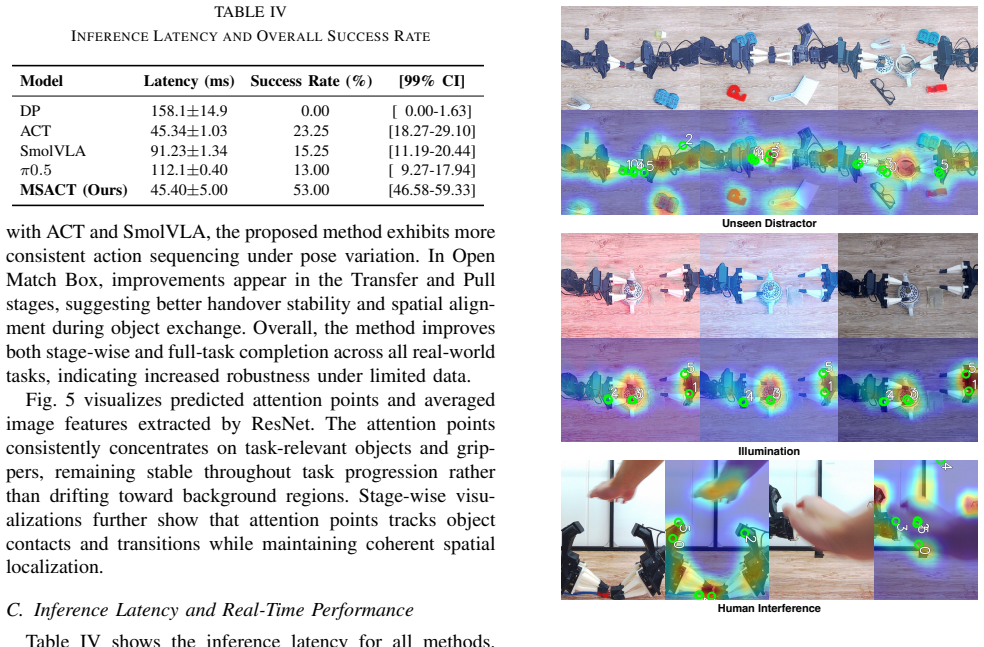
read the original abstract
Real-world fine manipulation, particularly in bimanual manipulation, typically requires low-latency control and stable visual localization, while collecting large-scale data is costly and limited demonstrations may lead to localization drift. Existing approaches make different trade-offs: action-chunking policies such as ACT enable low-latency execution and data efficiency but rely on dense visual features without explicit spatial consistency, generative methods such as Diffusion Policy improve expressiveness but can incur iterative sampling latency, vision-language-action and voxel-based methods enhance generalization and geometric grounding but require higher computational cost and system complexity. We introduce a multistage spatial attention module that extracts stable 2D attention points and jointly predicts future attention sequences with a temporal alignment loss. Built upon ACT with a pretrained ResNet visual prior, a multistage attention module extracts task-relevant 2D attention points as a local spatial modality for action prediction. To maintain consistent object tracking, we introduce a self-supervised objective that aligns predicted attention sequences with visual features from future frames, suppressing drift without keypoint annotations and improving stability of the vision-to-action mapping under limited data. Experiments on simulated and real-world fine manipulation tasks, conducted on the ALOHA bimanual platform, evaluate task success, attention drift, inference latency, and robustness to visual disturbances. Results indicate improvements in localization stability and task performance while maintaining low-latency inference under the tested conditions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes MSACT, an extension of the ACT imitation-learning policy for bimanual fine manipulation. It augments the pretrained ResNet backbone with a multistage spatial attention module that extracts stable 2D attention points as an additional spatial modality for action prediction, and introduces a self-supervised temporal alignment loss that aligns predicted attention sequences with visual features from future frames. The loss is applied only during training to suppress localization drift without keypoint annotations or added inference cost. Experiments on simulated and real ALOHA bimanual tasks evaluate task success, attention drift, latency, and robustness to visual disturbances, reporting gains in stability and performance while preserving ACT-level latency.
Significance. If the reported gains hold, the work provides a lightweight, annotation-free mechanism for improving visual consistency in low-latency imitation policies, addressing a practical bottleneck in data-limited real-world manipulation. Credit is due for the training-only loss, reuse of the frozen ResNet backbone, and ablations that isolate the alignment term's contribution; these elements make the method immediately usable on existing ACT pipelines without hardware changes.
minor comments (2)
- [Abstract] Abstract: the claim of 'improvements in localization stability and task performance' is stated without any numerical values, success rates, or drift metrics; adding the key quantitative results (with error bars or trial counts) would make the summary self-contained.
- [Abstract] The multistage attention module is described as extracting 'task-relevant 2D attention points,' but the precise number of stages, how attention is pooled across stages, and the exact form of the temporal alignment loss (e.g., which future-frame horizon and loss function) are not summarized in the abstract; a short equation or diagram reference would aid readability.
Simulated Author's Rebuttal
We thank the referee for the positive summary of our work and the recommendation for minor revision. We appreciate the recognition of the practical advantages of the training-only alignment loss, the frozen ResNet backbone, and the ablations isolating the alignment term.
Circularity Check
No significant circularity; new modules and loss introduced independently
full rationale
The paper presents MSACT as an extension of the ACT baseline by adding a multistage spatial attention module and a self-supervised temporal alignment loss. These are defined as novel architectural components and training objectives rather than derived from or equivalent to any fitted parameters or prior results within the paper's own equations. The temporal alignment loss aligns predicted attention sequences to future-frame features at training time only, with no reduction to input data by construction. Experiments and ablations are reported as external validation on ALOHA benchmarks. No self-citation is load-bearing for the central claims, and the derivation chain does not collapse to renaming or fitting. This is a standard case of an honest incremental contribution with independent content.
Axiom & Free-Parameter Ledger
invented entities (1)
-
multistage spatial attention module
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Learning fine-grained bimanual manipulation with low-cost hardware,
T. Z. Zhao, V . Kumar, S. Levine, and C. Finn, “Learning fine-grained bimanual manipulation with low-cost hardware,” inProceedings of Robotics: Science and Systems (RSS), 2023
2023
-
[2]
Diffusion policy: Visuomotor policy learning via action diffusion,
C. Chi, S. Feng, Y . Du, Z. Xu, E. Cousineau, B. Burchfiel, and S. Song, “Diffusion policy: Visuomotor policy learning via action diffusion,” in Proceedings of Robotics: Science and Systems (RSS), 2023
2023
-
[3]
OpenVLA: An Open-Source Vision-Language-Action Model
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. Foster, G. Lam, P. Sanketiet al., “Open- vla: An open-source vision-language-action model,”arXiv preprint arXiv:2406.09246, 2024
work page internal anchor Pith review arXiv 2024
-
[4]
SmolVLA: A Vision-Language-Action Model for Affordable and Efficient Robotics
M. Shukor, D. Aubakirova, F. Capuano, P. Kooijmans, S. Palma, A. Zouitine, M. Aractingi, C. Pascal, M. Russi, A. Marafiotiet al., “Smolvla: A vision-language-action model for affordable and efficient robotics,”arXiv preprint arXiv:2506.01844, 2025
work page internal anchor Pith review arXiv 2025
-
[5]
$\pi_{0.5}$: a Vision-Language-Action Model with Open-World Generalization
P. Intelligence, K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusaiet al., “π0.5: a vision-language-action model with open-world generalization,”arXiv preprint arXiv:2504.16054, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Perceiver-actor: A multi- task transformer for robotic manipulation,
M. Shridhar, L. Manuelli, and D. Fox, “Perceiver-actor: A multi- task transformer for robotic manipulation,” inConference on Robot Learning. PMLR, 2023, pp. 785–799
2023
-
[7]
Deep residual learning for image recognition,
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 770–778
2016
-
[8]
Deep spatial autoencoders for visuomotor learning,
C. Finn, X. Y . Tan, Y . Duan, T. Darrell, S. Levine, and P. Abbeel, “Deep spatial autoencoders for visuomotor learning,” in2016 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2016, pp. 512–519
2016
-
[9]
End-to-end training of deep visuomotor policies,
S. Levine, C. Finn, T. Darrell, and P. Abbeel, “End-to-end training of deep visuomotor policies,”Journal of Machine Learning Research, vol. 17, no. 39, pp. 1–40, 2016
2016
-
[10]
Learning synergies between pushing and grasping with self- supervised deep reinforcement learning,
A. Zeng, S. Song, S. Welker, J. Lee, A. Rodriguez, and T. Funkhouser, “Learning synergies between pushing and grasping with self- supervised deep reinforcement learning,” in2018 IEEE/RSJ Interna- tional Conference on Intelligent Robots and Systems (IROS). IEEE, 2018, pp. 4238–4245
2018
-
[11]
Transporter networks: Rearranging the visual world for robotic manipulation,
A. Zeng, P. Florence, J. Tompson, S. Welker, J. Chien, M. Attarian, T. Armstrong, I. Krasin, D. Duong, V . Sindhwaniet al., “Transporter networks: Rearranging the visual world for robotic manipulation,” in Conference on Robot Learning. PMLR, 2021, pp. 726–747
2021
-
[12]
Spatial attention point network for deep-learning-based robust autonomous robot motion generation,
H. Ichiwara, H. Ito, K. Yamamoto, H. Mori, and T. Ogata, “Spatial attention point network for deep-learning-based robust autonomous robot motion generation,”arXiv preprint arXiv:2103.01598, 2021
-
[13]
Deep active visual atten- tion for real-time robot motion generation: Emergence of tool-body assimilation and adaptive tool-use,
H. Hiruma, H. Ito, H. Mori, and T. Ogata, “Deep active visual atten- tion for real-time robot motion generation: Emergence of tool-body assimilation and adaptive tool-use,”IEEE Robotics and Automation Letters, vol. 7, no. 3, pp. 8550–8557, 2022
2022
-
[14]
3d space perception via disparity learning using stereo images and an attention mechanism: Real-time grasping motion generation for transparent objects,
X. Cai, H. Ito, H. Hiruma, and T. Ogata, “3d space perception via disparity learning using stereo images and an attention mechanism: Real-time grasping motion generation for transparent objects,”IEEE Robotics and Automation Letters, 2024
2024
-
[15]
V oxact-b: V oxel- based acting and stabilizing policy for bimanual manipulation,
I.-C. A. Liu, S. He, D. Seita, and G. S. Sukhatme, “V oxact-b: V oxel- based acting and stabilizing policy for bimanual manipulation,” in Conference on Robot Learning, 2024
2024
-
[16]
Polarnet: 3d point clouds for language-guided robotic manipulation,
S. Chen, R. Garcia, C. Schmid, and I. Laptev, “Polarnet: 3d point clouds for language-guided robotic manipulation,” inConference on Robotic Learning (CoRL), 2023
2023
-
[17]
3d diffusion policy: Generalizable visuomotor policy learning via simple 3d representations,
Y . Ze, G. Zhang, K. Zhang, C. Hu, M. Wang, and H. Xu, “3d diffusion policy: Generalizable visuomotor policy learning via simple 3d representations,” inProceedings of Robotics: Science and Systems (RSS), 2024
2024
-
[18]
RT-1: Robotics Transformer for Real-World Control at Scale
A. Brohan, N. Brown, J. Carbajal, Y . Chebotar, J. Dabis, C. Finn, K. Gopalakrishnan, K. Hausman, A. Herzog, J. Hsuet al., “Rt-1: Robotics transformer for real-world control at scale,”arXiv preprint arXiv:2212.06817, 2022
work page internal anchor Pith review arXiv 2022
-
[19]
Rt-2: Vision-language-action models transfer web knowledge to robotic control,
B. Zitkovich, T. Yu, S. Xu, P. Xu, T. Xiao, F. Xia, J. Wu, P. Wohlhart, S. Welker, A. Wahidet al., “Rt-2: Vision-language-action models transfer web knowledge to robotic control,” inConference on Robot Learning. PMLR, 2023, pp. 2165–2183
2023
-
[20]
Learning structured output represen- tation using deep conditional generative models,
K. Sohn, H. Lee, and X. Yan, “Learning structured output represen- tation using deep conditional generative models,”Advances in neural information processing systems, vol. 28, 2015
2015
-
[21]
Deep learning for detecting robotic grasps,
I. Lenz, H. Lee, and A. Saxena, “Deep learning for detecting robotic grasps,”The International Journal of Robotics Research, vol. 34, no. 4-5, pp. 705–724, 2015
2015
-
[22]
Contact- rich manipulation of a flexible object based on deep predictive learning using vision and tactility,
H. Ichiwara, H. Ito, K. Yamamoto, H. Mori, and T. Ogata, “Contact- rich manipulation of a flexible object based on deep predictive learning using vision and tactility,” in2022 international conference on robotics and automation (ICRA). IEEE, 2022, pp. 5375–5381
2022
-
[23]
Attention is all you need,
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,” Advances in neural information processing systems, vol. 30, 2017
2017
-
[24]
Feature pyramid networks for object detection,
T.-Y . Lin, P. Doll´ar, R. Girshick, K. He, B. Hariharan, and S. Belongie, “Feature pyramid networks for object detection,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 2117–2125
2017
-
[25]
Lerobot: State-of-the-art machine learning for real-world robotics in pytorch,
R. Cadene, S. Alibert, A. Soare, Q. Gallouedec, A. Zouitine, S. Palma, P. Kooijmans, M. Aractingi, M. Shukor, D. Aubakirova, M. Russi, F. Capuano, C. Pascal, J. Choghari, J. Moss, and T. Wolf, “Lerobot: State-of-the-art machine learning for real-world robotics in pytorch,” https://github.com/huggingface/lerobot, 2024
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.