Recognition: unknown
Structure Liberates: How Constrained Sensemaking Produces More Novel Research Output
Pith reviewed 2026-05-09 19:34 UTC · model grok-4.3
The pith
Constrained sensemaking trajectories from citations produce higher-quality and more novel research outputs than unconstrained inference from the same sources.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
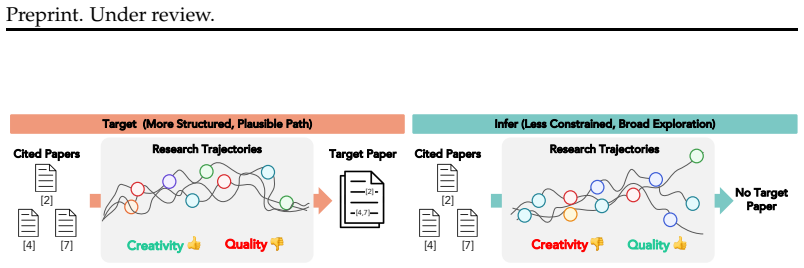
Target-trained models, which reconstruct the eight-stage ideation path from cited works to a known paper, achieve a 2.0% improvement in trajectory quality over Infer-trained models while also generating more novel and diverse outputs; when these trajectories condition downstream coding agents, the resulting research artifacts show higher executability and quality, indicating that structured reconstruction reduces cognitive load and enables greater downstream creativity.
What carries the argument
SCISENSE framework that breaks ideation into a fixed sequence of eight cognitive stages and uses it to generate Target trajectories (reconstructing paths to known papers) versus Infer trajectories (proposing novel directions) for training the SCISENSE-LM family of models.
If this is right
- Target conditioning produces ideation paths that are simultaneously more structured and more novel than free inference.
- Downstream coding agents produce higher-quality executable artifacts when guided by reconstruction-based trajectories.
- Structured early-stage sensemaking reduces the load on later creative steps in automated research pipelines.
- The same distinction between reconstruction and inference can be applied to other multi-step generation tasks beyond scientific writing.
Where Pith is reading between the lines
- The result suggests that human researchers might also benefit from tools that enforce structured reconstruction of prior work before generating new hypotheses.
- If the pattern holds, training regimes that emphasize faithful reconstruction of known successful paths could become a general principle for improving novelty in long-horizon LLM planning.
- The approach opens a way to study how different constraints at the ideation stage affect the diversity of research programs across entire fields.
Load-bearing premise
That trajectories reconstructed by LLMs from paper citations faithfully reflect real human research thinking and that the chosen automatic metrics for quality, novelty, and downstream executability measure the intended properties without task-specific bias.
What would settle it
A side-by-side rating by domain experts of Target versus Infer trajectories on perceived novelty and usefulness, or a controlled experiment measuring whether agents given Target trajectories actually complete more valid research tasks than those given Infer trajectories.
Figures











read the original abstract
Scientific discovery is an extended process of ideation--surveying prior work, forming hypotheses, and refining reasoning--yet existing approaches treat this phase as a brief preamble despite its central role in research. We introduce SCISENSE, a sensemaking-grounded framework that operationalizes ideation as a structured sequence of eight cognitive stages (Pirolli \& Card, 2005). We construct SCISENSE-Traj, a 100K-scale dataset of citation-conditioned research trajectories in two modes: Target, where an LLM reconstructs the ideation path leading to a known paper from its cited works, and Infer, where the LLM proposes novel directions from the same citations. We distill these into SCISENSE-LM, a family of sensemaking LLMs spanning 3B to 70B parameters. Contrary to the assumption that looser supervision promotes greater exploration, Target-trained models achieve a 2.0\% improvement in trajectory quality over Infer-trained models while also producing more novel and diverse outputs. This advantage propagates downstream: coding agents conditioned on Target trajectories produce research artifacts with higher executability and quality than those conditioned on Infer trajectories. This suggests that targeted ideation reduces cognitive burden on downstream agents, freeing them to explore more creatively. SCISENSE offers both a practical tool for augmenting LLM-driven research workflows and a principled testbed for studying how planning shapes scientific discovery.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the SCISENSE framework, which models scientific ideation as a structured sequence of eight cognitive stages drawn from Pirolli & Card (2005). It constructs the SCISENSE-Traj dataset of 100K citation-conditioned trajectories in two modes—Target (LLM reconstruction of the path to a known published paper) and Infer (LLM-proposed novel directions from the same citations)—and distills them into SCISENSE-LM models (3B–70B). The central empirical claim is that Target-trained models yield a 2.0% gain in trajectory quality, plus higher novelty and diversity, with this advantage propagating to downstream coding agents that produce more executable and higher-quality research artifacts when conditioned on Target trajectories.
Significance. If the evaluation concerns can be resolved, the work would be significant for providing a large-scale, sensemaking-grounded testbed for studying how planning structure affects LLM-driven discovery, challenging the assumption that looser supervision necessarily increases exploration, and offering a practical augmentation for research-agent workflows. The 100K-scale dataset and multi-size model family constitute concrete resources that could support follow-on studies.
major comments (3)
- [§5] §5 (Evaluation): The reported 2.0% trajectory-quality improvement and claims of greater novelty/diversity are presented without details on the precise metrics, baselines, statistical tests, inter-annotator agreement for LLM judges, or explicit controls for the structural difference that Target trajectories are reconstructed from citation chains leading to published papers while Infer trajectories are not. This leaves open whether the advantage is substantive or an artifact of metric alignment with successful human outcomes.
- [§4.3] §4.3 (Novelty and diversity metrics): Any metric based on embedding similarity to real papers, citation fidelity, or coherence with published work will, by construction, favor Target trajectories because they are explicitly derived from paths that produced accepted papers. The manuscript must demonstrate that the observed gains reflect genuine exploratory divergence rather than reduced deviation from the training distribution of successful research.
- [§6] §6 (Downstream coding-agent experiments): The higher executability and quality of artifacts produced by agents conditioned on Target trajectories may simply reflect lower parsing burden from more coherent, citation-grounded inputs rather than evidence that constrained sensemaking frees agents for greater creativity. An ablation that holds input structure constant while varying only the degree of grounding would be needed to support the causal interpretation.
minor comments (2)
- [Introduction] The abstract and introduction cite Pirolli & Card (2005) for the eight-stage model but do not provide a table or explicit mapping showing how each stage is operationalized in the SCISENSE-Traj annotation protocol.
- [§5] Clarify whether the 2.0% figure is absolute or relative, and report confidence intervals or p-values for all headline comparisons.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We address each major comment below, indicating where we will revise the manuscript to strengthen the presentation and address potential concerns.
read point-by-point responses
-
Referee: [§5] §5 (Evaluation): The reported 2.0% trajectory-quality improvement and claims of greater novelty/diversity are presented without details on the precise metrics, baselines, statistical tests, inter-annotator agreement for LLM judges, or explicit controls for the structural difference that Target trajectories are reconstructed from citation chains leading to published papers while Infer trajectories are not. This leaves open whether the advantage is substantive or an artifact of metric alignment with successful human outcomes.
Authors: We agree that the current presentation of §5 lacks sufficient detail. In the revised manuscript we will add a dedicated evaluation subsection that precisely defines all metrics (including the LLM-judge rubric for trajectory quality, embedding-based novelty, and diversity), reports all baselines, includes statistical tests with p-values and confidence intervals, provides inter-annotator agreement for any human or LLM judgments, and explicitly controls for structural differences between Target and Infer trajectories. These additions will allow readers to assess whether the observed gains are substantive. revision: yes
-
Referee: [§4.3] §4.3 (Novelty and diversity metrics): Any metric based on embedding similarity to real papers, citation fidelity, or coherence with published work will, by construction, favor Target trajectories because they are explicitly derived from paths that produced accepted papers. The manuscript must demonstrate that the observed gains reflect genuine exploratory divergence rather than reduced deviation from the training distribution of successful research.
Authors: We recognize the risk of metric bias. Our current novelty metric computes semantic distance to the full corpus rather than solely to the target paper, and diversity is measured via pairwise distances among generated trajectories. Nevertheless, to directly address the concern we will add alternative metrics that do not reference published outcomes (e.g., intra-set entropy and blind expert novelty ratings) and will report an analysis showing that Infer trajectories frequently collapse toward conventional directions while Target trajectories maintain structured variation. We will also clarify the exact computation in §4.3. revision: partial
-
Referee: [§6] §6 (Downstream coding-agent experiments): The higher executability and quality of artifacts produced by agents conditioned on Target trajectories may simply reflect lower parsing burden from more coherent, citation-grounded inputs rather than evidence that constrained sensemaking frees agents for greater creativity. An ablation that holds input structure constant while varying only the degree of grounding would be needed to support the causal interpretation.
Authors: This is a valid potential confound. We will add an ablation in the revised §6 that generates structured but non-citation-grounded trajectories (using generic research-stage templates) and compares them against both Target and Infer conditions. This will isolate the contribution of grounding versus the eight-stage sensemaking structure and thereby strengthen the causal claim that constrained sensemaking reduces downstream cognitive load. revision: yes
Circularity Check
No significant circularity in empirical comparison of Target vs. Infer trajectories
full rationale
The paper constructs SCISENSE-Traj by having an LLM reconstruct actual citation-to-paper paths (Target) versus propose novel directions (Infer), then trains SCISENSE-LM models on each and reports downstream empirical differences in quality, novelty, diversity, and executability. No equations, definitions, or self-citations reduce the 2.0% quality gain or novelty claims to the inputs by construction. The eight-stage framework is cited externally to Pirolli & Card (2005) without load-bearing self-reference. Evaluation metrics are presented as independent, with no evidence that novelty/diversity scores are fitted parameters or tautologically defined from the Target reconstruction process itself. The derivation remains a standard supervised comparison rather than a self-referential loop.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The eight cognitive stages of sensemaking from Pirolli & Card (2005) provide an accurate operationalization of the ideation phase in scientific research.
invented entities (3)
-
SCISENSE framework
no independent evidence
-
SCISENSE-Traj dataset
no independent evidence
-
SCISENSE-LM models
no independent evidence
Reference graph
Works this paper leans on
-
[1]
URL https://arxiv.org/abs/2410.07095. Audrey Cheng, Shu Liu, Melissa Pan, Zhifei Li, Bowen Wang, Alex Krentsel, Tian Xia, Mert Cemri, Jongseok Park, Shuo Yang, Jeff Chen, Lakshya Agrawal, Aditya Desai, Jiarong Xing, Koushik Sen, Matei Zaharia, and Ion Stoica. Barbarians at the gate: How ai is upending systems research, 2025. URL https://arxiv.org/abs/2510...
-
[2]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
URL https://arxiv.org/abs/2503.14476. 14 Preprint. Under review. A Citation Neighborhood Pipeline Details We illustrate the full multi-stage pipeline: 1) extracting citation neighborhoods from S2ORC
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
cross- pollination
summarizing individual papers; 3) generating target and inferred research trajectories; 4) enforcing structured outputs via prompting constraints. A.1 YAML prompt template libraries We package our prompt text as YAML template libraries to keep the pipeline reproducible and easy to audit: prompt wording is versioned separately from orchestration code, and ...
-
[4]
6- The expected system / method architecture
A section titled``Hypothesized Breakthrough''(rendered as`## Hypothesized Breakthrough`) that summarizes: 5- The likely research objective and novelty inferred from the cited corpus. 6- The expected system / method architecture. 7- The anticipated evaluation setting and success criteria. 8Include inline references to the relevant cited papers using [[pape...
-
[5]
minimum viable research artifact
A section titled``High-Impact Research Program''(rendered as`## High-Impact Research Program`) with subsections for Idea Formulation, Modeling, 18 Preprint. Under review. Experimentation, Validation, and Analysis (render each as`###`headings). For each subsection: 10- Articulate specific actions, checkpoints, and decision gates that synthesize insights fr...
-
[6]
Environment setup: Are dependencies specified, and could the environment be reproduced from the provided files (e.g.,requirements.txt, Dockerfiles)?
-
[7]
Data preparation: Is the data-loading or preprocessing pipeline present, and does it reference accessible artifacts?
-
[8]
Experiment execution: Do the core experiment scripts run to completion (as ev- idenced by logs or saved outputs), and do they implement the methodology de- scribed in the plan?
-
[9]
Paper generation: Is a compiled or compilable paper produced, and does it contain sections covering motivation, method, results, and limitations? The executability score is the mean of the four rescaled dimension scores: EXEC= 1 4 4 ∑ i=1 ˆsi. B. Scientific Grounding.The grounding judge receives the plan, the cited papers, the repository, and the generate...
2024
-
[10]
∑ x,y∈B x<y cos(x,y). Similarity for model type k was computed by averaging over bundles Gk, and diversity was defined as D(k) emb =1− 1 |Gk| ∑ B∈Gk Simemb(B),D (overall) emb = 1 2 D(infer) emb +D (target) emb . Self-BLEU diversity.As a lexical complement to the embedding analysis, we computed self-BLEU over the same five-sample bundles. For each bundleB,...
2046
-
[11]
26 Preprint
∑ x,y∈B x<y SimBS(x,y). 26 Preprint. Under review. Diversity was then computed as D(k) BS =1− 1 |Gk| ∑ B∈Gk SimBS(B),D (overall) BS = 1 2 D(infer) BS +D (target) BS . Sentence Mover’s Similarity diversity.Texts were chunked identically and each chunk was embedded using a sentence embedding model. For a document pair (x, y), cosine distance between chunk e...
-
[12]
Diversity was computed analogously, D(k) SMS =1− 1 |Gk| ∑ B∈Gk SimSMS(B),D (overall) SMS = 1 2 D(infer) SMS +D (target) SMS
∑ x,y∈B x<y SimSMS(x,y). Diversity was computed analogously, D(k) SMS =1− 1 |Gk| ∑ B∈Gk SimSMS(B),D (overall) SMS = 1 2 D(infer) SMS +D (target) SMS . G LLM-as-Judge Table 8 shows the results of LLM-as-Judge by rubric metric across different model families. The LLM-as-Judge Prompt template is as follows: You must evaluate the proposal rigorously, fairly, ...
-
[13]
Consider whether it explicitly compares against prior 28 Preprint
Novelty & Differentiation.Evaluate whether the proposal introduces a genuinely new idea relative to [[R#]]. Consider whether it explicitly compares against prior 28 Preprint. Under review. work, whether novelty is conceptual, methodological, or contextual, whether it is non-obvious, and whether it clearly articulates what is new
-
[14]
Consider whether a clear gap is identified, whether success would advance the field, whether contributions are well-scoped, and whether beneficiaries are identified
Significance & Potential Contribution.Assess importance and potential impact if successful. Consider whether a clear gap is identified, whether success would advance the field, whether contributions are well-scoped, and whether beneficiaries are identified
-
[15]
Check that references are accurate, properly formatted, and complete
Grounding in Prior Work & Citation Integrity.Evaluate engagement with prior literature and correctness of citations. Check that references are accurate, properly formatted, and complete
-
[16]
Consider assumptions, logical consistency, distinction between speculation and fact, and acknowledgment of limits
Conceptual Soundness & Plausibility.Assess internal coherence and plausibility of the core idea. Consider assumptions, logical consistency, distinction between speculation and fact, and acknowledgment of limits
-
[17]
Consider clarity of hypotheses, experimental design, metrics, baselines, and whether claims are falsifiable
Methodological Rigor & Falsifiability.Evaluate whether the proposal can be rigorously tested. Consider clarity of hypotheses, experimental design, metrics, baselines, and whether claims are falsifiable
-
[18]
Consider resources, scope, risks, and planning
Feasibility & Scope Management.Assess whether the work is realistically executable. Consider resources, scope, risks, and planning
-
[19]
Sensemaking & Iterative Knowledge Development.Evaluate whether the proposal includes an iterative learning strategy, considers alternative hypotheses, and plans for handling contradictory evidence
-
[20]
Consider whether the proposal is well-structured, precise, and suffi- ciently detailed
Clarity, Structure, and Reproducibility.Assess clarity, organization, and repro- ducibility. Consider whether the proposal is well-structured, precise, and suffi- ciently detailed. INPUT PROMPT WITH REFERENCE PAPERS.{{input prompt}} GENERATED PROPOSAL.{{proposal}} START OF EV ALUATION. 29
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.