Recognition: unknown
Beyond Decodability: Reconstructing Language Model Representations with an Encoding Probe
Pith reviewed 2026-05-09 19:29 UTC · model grok-4.3
The pith
An encoding probe reconstructs language model representations from interpretable features, revealing independent contributions from syntax and lexicon while speaker effects vary by training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
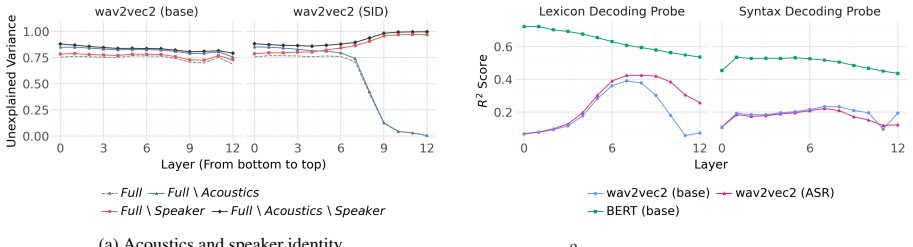
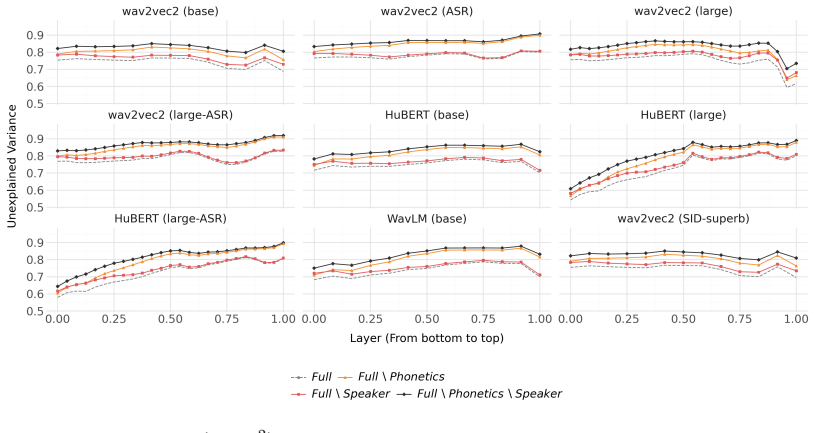
By reversing the direction of analysis, the encoding probe reconstructs model representations from interpretable feature sets. Evaluation on transformer models indicates that speaker-related effects vary strongly across different training objectives and datasets, while syntactic and lexical features contribute independently to reconstruction.
What carries the argument
The Encoding Probe, which takes interpretable features as input to reconstruct the model's internal representations and measures how well different feature groups explain the representation.
If this is right
- Speaker-related features influence representations differently based on training objectives and datasets.
- Syntactic and lexical features provide non-overlapping contributions to model representations.
- Contributions of various features can be compared directly without correlation bias.
- The probe works for both text and speech transformer models.
Where Pith is reading between the lines
- Researchers could use this to identify minimal feature sets needed for certain model capabilities.
- It might help explain performance differences between models trained on different data.
- The method could extend to analyzing other types of neural networks beyond language models.
Load-bearing premise
That the chosen feature sets are complete and free of unaccounted correlations, allowing differences in reconstruction to be attributed to the features themselves.
What would settle it
Observing no difference in reconstruction when using combined versus separate syntactic and lexical features, or consistent speaker effects across all models, would challenge the claims of independence and variation.
Figures







read the original abstract
Probing is widely used to study which features can be decoded from language model representations. However, the common decoding probe approach has two limitations that we aim to solve with our new encoding probe approach: contributions of different features to model representations cannot be directly compared, and feature correlations can affect probing results. We present an Encoding Probe that reverses this direction and reconstructs internal representations of models using interpretable features. We evaluate this method on text and speech transformer models, using feature sets spanning acoustics, phonetics, syntax, lexicon, and speaker identity. Our results suggest that speaker-related effects vary strongly across different training objectives and datasets, while syntactic and lexical features contribute independently to reconstruction. These results show that the Encoding Probe provides a complementary perspective on interpreting model representations beyond decodability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces an Encoding Probe that reverses the typical probing direction by reconstructing language model representations from sets of interpretable features (acoustics, phonetics, syntax, lexicon, speaker identity). It argues this addresses two limitations of decoding probes: inability to directly compare feature contributions and confounding by feature correlations. Evaluation on text and speech transformers yields the claims that speaker-related effects vary strongly across training objectives and datasets while syntactic and lexical features contribute independently to reconstruction.
Significance. If the reconstruction results can be shown to be robust to feature correlations and omissions, the Encoding Probe would supply a useful quantitative complement to decodability-based interpretability methods, allowing direct assessment of how much variance in model activations is explained by specific linguistic properties. The approach is particularly relevant for comparing representations across training regimes in both NLP and speech models.
major comments (2)
- [Abstract] The central claim that syntactic and lexical features 'contribute independently' (Abstract) rests on the assumption that the chosen feature sets are mutually non-redundant and exhaustive. The manuscript provides no indication that multicollinearity was diagnosed, features were orthogonalized, or residual variance was examined for systematic structure after fitting, which is required to attribute reconstruction-error differences cleanly to the named categories rather than to unmeasured correlations.
- [Abstract] The abstract reports evaluation on text and speech models with multiple feature sets yet supplies no quantitative reconstruction metrics, error bars, confidence intervals, or controls for feature correlations. Without these, the strength of the reported variation in speaker effects and the independence of syntactic/lexical contributions cannot be assessed.
minor comments (2)
- [Abstract] The abstract does not name the specific models, datasets, or training objectives used in the evaluation, which would help readers contextualize the claimed variation across objectives.
- Consider including a table or figure that reports per-feature-set reconstruction performance (e.g., R² or MSE) across models to make the independent-contribution claim visually verifiable.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify how to strengthen the presentation of the Encoding Probe's claims. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] The central claim that syntactic and lexical features 'contribute independently' (Abstract) rests on the assumption that the chosen feature sets are mutually non-redundant and exhaustive. The manuscript provides no indication that multicollinearity was diagnosed, features were orthogonalized, or residual variance was examined for systematic structure after fitting, which is required to attribute reconstruction-error differences cleanly to the named categories rather than to unmeasured correlations.
Authors: We agree that explicit checks for multicollinearity and residual structure are necessary to support clean attribution of independent contributions. In the revised manuscript we will add a dedicated diagnostics subsection that reports variance inflation factors across all feature sets, incremental reconstruction performance when features are added sequentially, and an analysis of residuals after the full model fit to identify any remaining systematic variance. These additions will directly address the concern while preserving the core argument that the encoding direction reduces certain confounding issues relative to decoding probes. revision: yes
-
Referee: [Abstract] The abstract reports evaluation on text and speech models with multiple feature sets yet supplies no quantitative reconstruction metrics, error bars, confidence intervals, or controls for feature correlations. Without these, the strength of the reported variation in speaker effects and the independence of syntactic/lexical contributions cannot be assessed.
Authors: We accept that the current abstract lacks the quantitative anchors needed for readers to evaluate the reported effects. We will revise the abstract to include representative reconstruction metrics (e.g., mean R² values for syntactic-plus-lexical versus full feature sets) together with standard errors or confidence intervals, and we will note that correlation diagnostics and controls are now detailed in the main text. This change will make the strength of the speaker-effect variation and feature-independence claims directly assessable from the abstract. revision: yes
Circularity Check
No circularity: empirical reconstruction via standard regression on independent feature sets
full rationale
The paper defines an encoding probe as a regression that reconstructs model hidden states from a fixed set of external, human-interpretable features (acoustics, phonetics, syntax, lexicon, speaker). Reconstruction quality is measured by held-out error or correlation; differences across feature groups are reported directly from these fits. No equation equates a target quantity to a parameter fitted from the same quantity, no prediction is a renamed fit, and no load-bearing premise reduces to a self-citation chain. The central claims about independent contributions and speaker variation follow from comparing reconstruction metrics across disjoint feature subsets; these metrics are computed from the data and are not definitionally forced by the probe formulation itself. The approach is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Yossi Adi, Einat Kermany, Yonatan Belinkov, Ofer Lavi, and Yoav Goldberg. 2017. Fine-grained Analysis of Sentence Embeddings Using Auxiliary Prediction Tasks . In International Conference on Learning Representations
2017
-
[2]
Guillaume Alain and Yoshua Bengio. 2017. Understanding intermediate layers using linear classifier probes. International Conference on Learning Representations
2017
-
[3]
Alexei Baevski, Yuhao Zhou, Abdelrahman Mohamed, and Michael Auli. 2020. Wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations . In Advances in Neural Information Processing Systems , volume 33, pages 12449--12460. Curran Associates, Inc
2020
-
[4]
Yonatan Belinkov. 2022. https://doi.org/10.1162/coli_a_00422 Probing Classifiers : Promises , Shortcomings , and Advances . Computational Linguistics, 48(1):207--219
work page internal anchor Pith review doi:10.1162/coli_a_00422 2022
-
[5]
Martijn Bentum, Louis ten Bosch , and Tomas O. Lentz. 2025. https://doi.org/10.21437/Interspeech.2025-106 Word stress in self-supervised speech models: A cross-linguistic comparison . In Proc. Interspeech 2025 , pages 251--255
-
[6]
Piotr Bojanowski, Edouard Grave, Armand Joulin, and Tomas Mikolov. 2017. https://doi.org/10.1162/tacl_a_00051 Enriching Word Vectors with Subword Information . Transactions of the Association for Computational Linguistics, 5:135--146
-
[7]
Aemon Yat Fei Chiu, Kei Ching Fung, Roger Tsz Yeung Li, Jingyu Li, and Tan Lee. 2026. https://doi.org/10.48550/arXiv.2501.05310 A Large-Scale Probing Analysis of Speaker-Specific Attributes in Self-Supervised Speech Representations . Preprint, arXiv:2501.05310
-
[8]
Kwanghee Choi, Ankita Pasad, Tomohiko Nakamura, Satoru Fukayama, Karen Livescu, and Shinji Watanabe. 2024. https://doi.org/10.21437/Interspeech.2024-1157 Self- Supervised Speech Representations are More Phonetic than Semantic . In Proc. Interspeech 2024 , pages 4578--4582
-
[9]
Grzegorz Chrupa a and Afra Alishahi. 2019. https://doi.org/10.18653/v1/P19-1283 Correlating Neural and Symbolic Representations of Language . In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics , pages 2952--2962, Florence, Italy. Association for Computational Linguistics
-
[10]
Cameron Churchwell, Max Morrison, and Bryan Pardo. 2024. https://doi.org/10.1109/ICASSPW62465.2024.10669905 High- Fidelity Neural Phonetic Posteriorgrams . In 2024 IEEE International Conference on Acoustics , Speech , and Signal Processing Workshops ( ICASSPW ) , pages 823--827, Seoul, Korea, Republic of. IEEE
-
[11]
Alexis Conneau, German Kruszewski, Guillaume Lample, Lo \"i c Barrault, and Marco Baroni. 2018. https://doi.org/10.18653/v1/P18-1198 What you can cram into a single \ &!\#* vector: Probing sentence embeddings for linguistic properties . In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics ( Volume 1: Long Papers ) , p...
-
[12]
Kelleher, and Julie Carson-Berndsen
Patrick Cormac English, John D. Kelleher, and Julie Carson-Berndsen . 2022. https://doi.org/10.18653/v1/2022.sigmorphon-1.9 Domain- Informed Probing of wav2vec 2.0 Embeddings for Phonetic Features . In Proceedings of the 19th SIGMORPHON Workshop on Computational Research in Phonetics , Phonology , and Morphology , pages 83--91, Seattle, Washington. Associ...
-
[13]
Marianne de Heer Kloots , Hosein Mohebbi, Charlotte Pouw, Gaofei Shen, Willem Zuidema, and Martijn Bentum. 2025. https://doi.org/10.21437/Interspeech.2025-1526 What do self-supervised speech models know about Dutch ? Analyzing advantages of language-specific pre-training . In Proc. Interspeech 2025 , pages 256--260
-
[14]
Anton De La Fuente and Dan Jurafsky. 2024. https://doi.org/10.21437/Interspeech.2024-2341 A layer-wise analysis of Mandarin and English suprasegmentals in SSL speech models . In Interspeech 2024, pages 1290--1294. ISCA
-
[15]
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. https://doi.org/10.18653/v1/N19-1423 BERT : Pre-training of deep bidirectional transformers for language understanding . In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long an...
-
[16]
The geneva minimalistic acoustic parameter set (GeMAPS) for voice research and affective computing,
Florian Eyben, Klaus R. Scherer, Bjorn W. Schuller, Johan Sundberg, Elisabeth Andre, Carlos Busso, Laurence Y. Devillers, Julien Epps, Petri Laukka, Shrikanth S. Narayanan, and Khiet P. Truong. 2016. https://doi.org/10.1109/TAFFC.2015.2457417 The Geneva Minimalistic Acoustic Parameter Set ( GeMAPS ) for Voice Research and Affective Computing . IEEE Transa...
-
[17]
Florian Eyben, Martin W \"o llmer, and Bj \"o rn Schuller. 2010. https://doi.org/10.1145/1873951.1874246 Opensmile: The munich versatile and fast open-source audio feature extractor . In Proceedings of the 18th ACM International Conference on Multimedia , pages 1459--1462, Firenze Italy. ACM
-
[18]
Michele Gubian, Ioana Krehan, Oli Liu, James Kirby, and Sharon Goldwater. 2025. https://doi.org/10.48550/arXiv.2506.10855 Analyzing the relationships between pretraining language, phonetic, tonal, and speaker information in self-supervised speech models . Preprint, arXiv:2506.10855
-
[19]
Hazen, Wade Shen, and Christopher White
Timothy J. Hazen, Wade Shen, and Christopher White. 2009. https://doi.org/10.1109/ASRU.2009.5372889 Query-by-example spoken term detection using phonetic posteriorgram templates . In 2009 IEEE Workshop on Automatic Speech Recognition & Understanding , pages 421--426
-
[20]
John Hewitt, Kawin Ethayarajh, Percy Liang, and Christopher Manning. 2021. https://doi.org/10.18653/v1/2021.emnlp-main.122 Conditional probing: Measuring usable information beyond a baseline . In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing , pages 1626--1639, Online and Punta Cana, Dominican Republic. Association...
-
[21]
John Hewitt and Percy Liang. 2019. https://doi.org/10.18653/v1/D19-1275 Designing and Interpreting Probes with Control Tasks . In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing ( EMNLP-IJCNLP ) , pages 2733--2743, Hong Kong, China. Association...
-
[22]
John Hewitt and Christopher D. Manning. 2019. https://doi.org/10.18653/v1/N19-1419 A Structural Probe for Finding Syntax in Word Representations . In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics : Human Language Technologies , Volume 1 ( Long and Short Papers ) , pages 4129--4138, Minnea...
-
[23]
Matthew Honnibal, Ines Montani, Sofie Van Landeghem, and Adriane Boyd. 2020. https://doi.org/10.5281/zenodo.1212303 spaCy : Industrial-strength natural language processing in python
-
[24]
Harold Hotelling. 1936. https://doi.org/10.2307/2333955 Relations Between Two Sets of Variates . Biometrika, 28(3/4):321--377
-
[25]
Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan Salakhutdinov, and Abdelrahman Mohamed. 2021. https://doi.org/10.1109/TASLP.2021.3122291 HuBERT : Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units . IEEE/ACM Transactions on Audio, Speech, and Language Processing, 29:3451--3460
-
[26]
Dieuwke Hupkes and Willem Zuidema. 2018. Visualisation and ' Diagnostic Classifiers ' Reveal how Recurrent and Recursive Neural Networks Process Hierarchical Structure ( Extended Abstract ). pages 5617--5621
2018
-
[27]
Anna A Ivanova, John Hewitt, and Noga Zaslavsky. 2021. Probing artificial neural networks: Insights from neuroscience. In ICLR 2021 Workshop ``How Can Findings about the Brain Improve AI Systems?''
2021
-
[28]
Nikolaus Kriegeskorte, Marieke Mur, and Peter A Bandettini. 2008. Representational similarity analysis-connecting the branches of systems neuroscience. Frontiers in systems neuroscience, page 4
2008
-
[29]
Yoonjeong Lee, Patricia Keating, and Jody Kreiman. 2019. https://doi.org/10.1121/1.5125134 Acoustic voice variation within and between speakers . The Journal of the Acoustical Society of America, 146(3):1568--1579
-
[30]
Oli Danyi Liu, Hao Tang, and Sharon Goldwater. 2023. https://doi.org/10.21437/Interspeech.2023-871 Self-supervised Predictive Coding Models Encode Speaker and Phonetic Information in Orthogonal Subspaces . In Proc. Interspeech 2023 , pages 2968--2972
-
[31]
Danni Ma, Neville Ryant, and Mark Liberman. 2021. https://doi.org/10.1109/ICASSP39728.2021.9414776 Probing Acoustic Representations for Phonetic Properties . In ICASSP 2021 - 2021 IEEE International Conference on Acoustics , Speech and Signal Processing ( ICASSP ) , pages 311--315
-
[32]
Rowan Hall Maudslay and Ryan Cotterell. 2021. https://doi.org/10.18653/v1/2021.naacl-main.11 Do Syntactic Probes Probe Syntax ? Experiments with Jabberwocky Probing . In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics : Human Language Technologies , pages 124--131, Online. Association for C...
-
[33]
Vassil Panayotov, Guoguo Chen, Daniel Povey, and Sanjeev Khudanpur. 2015. https://doi.org/10.1109/ICASSP.2015.7178964 Librispeech: An ASR corpus based on public domain audio books . In 2015 IEEE International Conference on Acoustics , Speech and Signal Processing ( ICASSP ) , pages 5206--5210
-
[34]
Ankita Pasad, Chung-Ming Chien, Shane Settle, and Karen Livescu. 2024. https://doi.org/10.1162/tacl_a_00656 What Do Self-Supervised Speech Models Know About Words ? Transactions of the Association for Computational Linguistics, 12:372--391
-
[35]
Ankita Pasad, Ju-Chieh Chou, and Karen Livescu. 2021. https://doi.org/10.1109/ASRU51503.2021.9688093 Layer- Wise Analysis of a Self-Supervised Speech Representation Model . In 2021 IEEE Automatic Speech Recognition and Understanding Workshop ( ASRU ) , pages 914--921, Cartagena, Colombia. IEEE
-
[36]
Pedregosa, G
F. Pedregosa, G. Varoquaux, A. Gramfort, V. Michel, B. Thirion, O. Grisel, M. Blondel, P. Prettenhofer, R. Weiss, V. Dubourg, J. Vanderplas, A. Passos, D. Cournapeau, M. Brucher, M. Perrot, and E. Duchesnay. 2011. Scikit-learn: Machine learning in Python . Journal of Machine Learning Research, 12:2825--2830
2011
-
[37]
Gaofei Shen, Afra Alishahi, Arianna Bisazza, and Grzegorz Chrupa a. 2023. https://doi.org/10.21437/Interspeech.2023-679 Wave to Syntax : Probing spoken language models for syntax . In INTERSPEECH 2023 , pages 1259--1263
-
[38]
Diego Simon, Emmanuel Chemla, Jean-Remi King, and Yair Lakretz
Pablo J. Diego Simon, Emmanuel Chemla, Jean-Remi King, and Yair Lakretz. 2025. Probing syntax in large language models: Successes and remaining challenges. In Second Conference on Language Modeling
2025
-
[39]
Ian Tenney, Dipanjan Das, and Ellie Pavlick. 2019. https://doi.org/10.18653/v1/P19-1452 BERT Rediscovers the Classical NLP Pipeline . In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics , pages 4593--4601, Florence, Italy. Association for Computational Linguistics
-
[40]
Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, Remi Louf, Morgan Funtowicz, Joe Davison, Sam Shleifer, Patrick von Platen , Clara Ma, Yacine Jernite, Julien Plu, Canwen Xu, Teven Le Scao, Sylvain Gugger, and 3 others. 2020. https://doi.org/10.18653/v1/2020.emnlp-demos.6 Transformers: St...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.