Recognition: unknown
EGREFINE: An Execution-Grounded Optimization Framework for Text-to-SQL Schema Refinement
Pith reviewed 2026-05-09 18:57 UTC · model grok-4.3
The pith
EGRefine recovers Text-to-SQL accuracy lost to ambiguous schema names by treating refinement as constrained optimization solved via greedy execution-verified renamings materialized as views.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
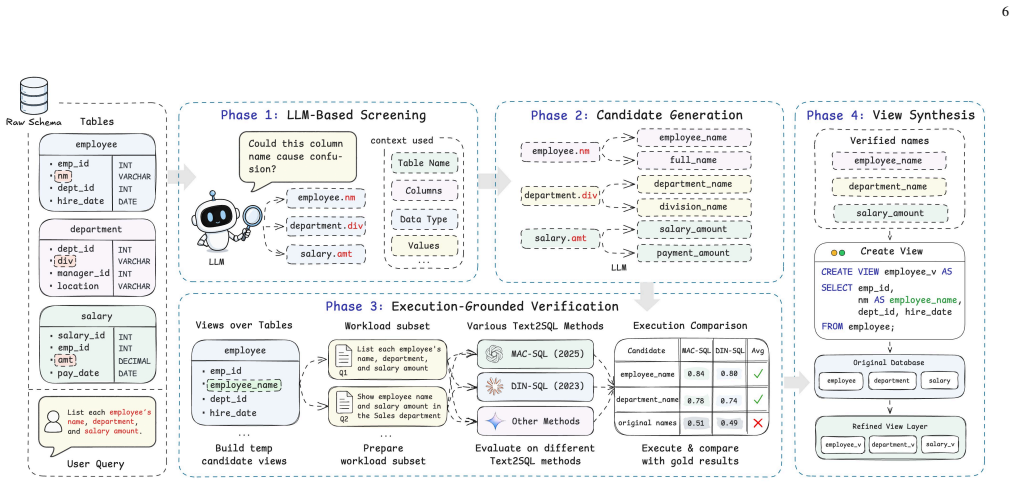
EGRefine solves the schema refinement problem by decomposing the constrained optimization into a column-wise greedy process, generating candidates, applying conservative verification through execution-grounded feedback to enforce column-local non-degradation, and materializing results as views to guarantee database-level query equivalence. This construction ensures safety at the column level while handling cross-column interactions empirically. The result is recovery of accuracy on naming-degraded schemas where the task fits current Text-to-SQL capabilities, correct abstention otherwise, and transfer of refined schemas across model families.
What carries the argument
The column-wise greedy decomposition of the constrained optimization problem for renaming, paired with conservative execution verification on sample queries to select only non-degrading candidates.
Load-bearing premise
That column-wise greedy selection of renamings, verified only on a finite set of queries, will not miss globally superior combinations or allow degradation on unseen queries.
What would settle it
An experiment that exhaustively searches renamings on a small schema and shows a non-greedy combination yields higher accuracy than the greedy output, or a test showing accuracy drop on queries held out from the verification set after applying the refined views.
Figures

read the original abstract
Text-to-SQL enables non-expert users to query databases in natural language, yet real-world schemas often suffer from ambiguous, abbreviated, or inconsistent naming conventions that degrade model accuracy. Existing approaches treat schemas as fixed and address errors downstream. In this paper, we frame schema refinement as a constrained optimization problem: find a renaming function that maximizes downstream Text-to-SQL execution accuracy while preserving query equivalence through database views. We analyze the computational hardness of this problem, which motivates a column-wise greedy decomposition, and instantiate it as EGRefine: a four-phase pipeline that screens ambiguous columns, generates context-aware candidate names, verifies them through execution-grounded feedback, and materializes the result as non-destructive SQL views. The pipeline carries two structural properties: column-local non-degradation, ensured by the conservative selection rule in the verification phase, and database-level query equivalence, ensured by the view-based materialization phase. Together they make the resulting refinement safe by construction at the column level, with cross-column and prompt-level interactions handled empirically rather than analytically. Across controlled schema-degradation, real-world, and enterprise benchmarks, EGRefine recovers accuracy lost to schema naming noise where applicable and correctly abstains where the underlying task exceeds current Text-to-SQL capabilities, with refined schemas transferring across model families to enable refine-once, serve-many-models deployment. Code and data are publicly available at https://github.com/ai-jiaqian/EGRefine.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper frames Text-to-SQL schema refinement as a constrained optimization problem of finding renamings that maximize execution accuracy while preserving equivalence via views. It provides a hardness analysis motivating a column-wise greedy decomposition, then instantiates EGRefine as a four-phase pipeline (screen ambiguous columns, generate context-aware candidates, verify via execution feedback, materialize as views). The pipeline is claimed to ensure column-local non-degradation by construction and database-level equivalence, with empirical results on controlled degradation, real-world, and enterprise benchmarks showing accuracy recovery where applicable, correct abstention otherwise, and transfer across model families.
Significance. If the empirical recovery and transfer results hold under the stated controls, the work offers a practical, model-agnostic way to mitigate naming-induced errors in Text-to-SQL without retraining or altering downstream systems. The public code and data release is a clear strength that supports reproducibility. The structural safety properties (local non-degradation and view equivalence) are attractive if they survive broader validation.
major comments (2)
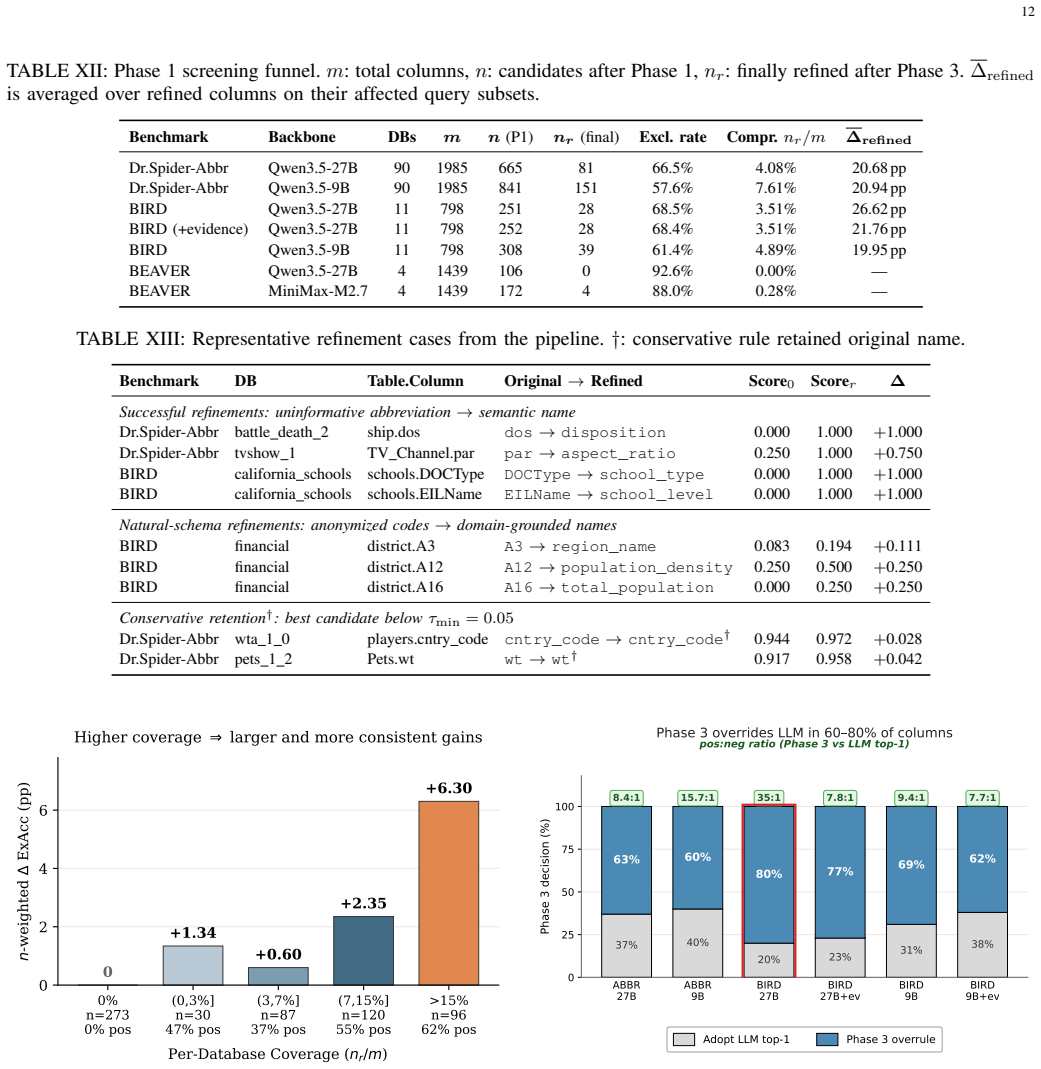
- [Abstract and §4] Abstract and §4 (pipeline description): the central claim of safe refinement rests on the conservative verification rule ensuring column-local non-degradation, yet the paper provides no formal argument or additional experiments showing that execution feedback on a finite query set suffices to prevent degradation on unseen queries or under prompt variations across model families.
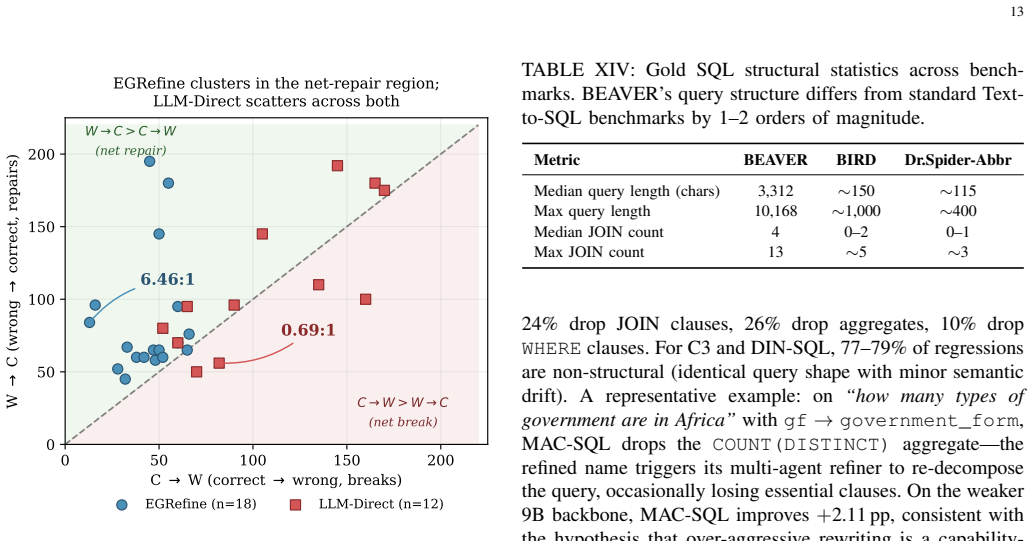
- [Abstract and hardness analysis section] Abstract and hardness analysis section: the column-wise greedy decomposition is motivated by computational hardness, but no approximation guarantee, exhaustive-search baseline on small instances, or comparison to joint optimization is reported; this leaves open whether locally optimal per-column choices sacrifice globally superior renamings that could further improve accuracy.
minor comments (2)
- [Abstract] The abstract states that cross-column and prompt-level interactions are handled empirically; a dedicated limitations or future-work paragraph would help readers assess the scope of this empirical handling.
- [Experimental section] Table or figure captions for the benchmark results should explicitly list the exact query sets, number of queries per benchmark, and the models used for verification to allow direct replication.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below with point-by-point responses and indicate where revisions will be made to improve clarity and rigor.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (pipeline description): the central claim of safe refinement rests on the conservative verification rule ensuring column-local non-degradation, yet the paper provides no formal argument or additional experiments showing that execution feedback on a finite query set suffices to prevent degradation on unseen queries or under prompt variations across model families.
Authors: We agree that the manuscript does not provide a formal proof that execution feedback on a finite query set guarantees non-degradation for arbitrary unseen queries or all prompt variations. The conservative verification rule ensures column-local non-degradation by construction only for the queries used in verification, while generalization across columns, models, and prompts is handled empirically as stated in the abstract. Our benchmarks include transfer results across model families and real-world/enterprise sets, but we acknowledge this falls short of exhaustive validation. We will revise §4 to explicitly bound the safety claim to the verification set, add a limitations discussion, and include new experiments on held-out queries and prompt variations. revision: yes
-
Referee: [Abstract and hardness analysis section] Abstract and hardness analysis section: the column-wise greedy decomposition is motivated by computational hardness, but no approximation guarantee, exhaustive-search baseline on small instances, or comparison to joint optimization is reported; this leaves open whether locally optimal per-column choices sacrifice globally superior renamings that could further improve accuracy.
Authors: The hardness analysis establishes NP-hardness of the joint problem, which motivates the scalable column-wise greedy decomposition. We acknowledge that no approximation ratio, exhaustive baseline on small instances, or joint-optimization comparison is provided, leaving open the possibility of superior global solutions. Joint optimization is impractical for realistic schema sizes due to combinatorial explosion. We will revise the hardness section to include exhaustive-search results on small synthetic instances (3-5 columns) quantifying the greedy-to-optimal gap and add discussion of the decomposition's trade-offs. revision: yes
Circularity Check
No significant circularity; derivation relies on external execution feedback and view materialization.
full rationale
The paper frames schema refinement as a constrained optimization problem whose objective is downstream Text-to-SQL execution accuracy measured on actual runs, which is external to the renaming function. Hardness analysis motivates the column-wise greedy decomposition without defining the objective in terms of itself. The verification phase applies a conservative selection rule using execution feedback on a finite query set, and materialization ensures equivalence via non-destructive views; these properties are enforced by construction through the described rules rather than by fitting or self-referential definition. No load-bearing self-citations, imported uniqueness theorems, or ansatzes appear in the derivation chain, and the approach remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Creating database views that alias renamed columns to originals preserves query equivalence.
- ad hoc to paper Column-wise greedy decomposition is a viable approximation to the global constrained optimization problem.
Reference graph
Works this paper leans on
-
[1]
A survey on deep learning approaches for text-to-SQL,
G. Katsogiannis-Meimarakis and G. Koutrika, “A survey on deep learning approaches for text-to-SQL,”The VLDB Journal, vol. 32, no. 4, pp. 905–936, 2023
2023
-
[2]
Natural language to SQL: State of the art and open problems,
Y . Luo, G. Li, J. Fan, C. Chai, and N. Tang, “Natural language to SQL: State of the art and open problems,”Proceedings of the VLDB Endowment, vol. 18, no. 12, pp. 5466–5471, 2025. 15
2025
-
[3]
DIN-SQL: Decomposed in-context learning of text-to-SQL with self-correction,
M. Pourreza and D. Rafiei, “DIN-SQL: Decomposed in-context learning of text-to-SQL with self-correction,” inNeurIPS, pp. 36339–36348, 2023
2023
-
[4]
Text- to-sql empowered by large language models: A benchmark evaluation,
D. Gao, H. Wang, Y . Li,et al., “Text-to-SQL empowered by large language models: A benchmark evaluation,”arXiv preprint arXiv:2308.15363, 2023
-
[5]
MAC-SQL: A multi-agent collabo- rative framework for text-to-SQL,
B. Wang, C. Ren, J. Yang,et al., “MAC-SQL: A multi-agent collabo- rative framework for text-to-SQL,” inCOLING, pp. 540–557, 2025
2025
-
[6]
Chess: Contextual harnessing for efficient sql synthesis,
S. Talaei, M. Pourreza, Y .-C. Chang, A. Mirhoseini, and A. Saberi, “CHESS: Contextual harnessing for efficient SQL synthesis,”arXiv preprint arXiv:2405.16755, 2024
-
[7]
Spider: A large-scale human-labeled dataset for complex and cross-domain semantic parsing and text-to-SQL task,
T. Yu, R. Zhang, K. Yang, M. Yasunaga,et al., “Spider: A large-scale human-labeled dataset for complex and cross-domain semantic parsing and text-to-SQL task,” inEMNLP, pp. 3911–3921, 2018
2018
-
[8]
Evaluating the data model robustness of text-to-SQL systems based on real user queries,
J. F ¨urst, C. Kosten, F. Nooralahzadeh,et al., “Evaluating the data model robustness of text-to-SQL systems based on real user queries,”arXiv preprint arXiv:2402.08349, 2024
-
[9]
Fundamental challenges in evaluating text2SQL solutions and detecting their limitations,
C. Renggli, I. F. Ilyas, and T. Rekatsinas, “Fundamental challenges in evaluating text2SQL solutions and detecting their limitations,”arXiv preprint arXiv:2501.18197, 2025
-
[10]
RAT-SQL: Relation-aware schema encoding and linking for text-to-SQL parsers,
B. Wang, R. Shin, X. Liu, O. Polozov, and M. Richardson, “RAT-SQL: Relation-aware schema encoding and linking for text-to-SQL parsers,” inACL, pp. 7567–7578, 2020
2020
-
[11]
Dr.Spider: A diagnostic eval- uation benchmark towards text-to-SQL robustness,
S. Chang, J. Wang, M. Dong,et al., “Dr.Spider: A diagnostic eval- uation benchmark towards text-to-SQL robustness,”arXiv preprint arXiv:2301.08881, 2023
-
[12]
Can LLM already serve as a database interface? a big bench for large-scale database grounded text-to-SQLs,
J. Li, B. Hui, G. Qu,et al., “Can LLM already serve as a database interface? a big bench for large-scale database grounded text-to-SQLs,” inAdvances in Neural Information Processing Systems (NeurIPS), vol. 36, 2023
2023
-
[13]
PICARD: Parsing in- crementally for constrained auto-regressive decoding from language models,
T. Scholak, N. Schucher, and D. Bahdanau, “PICARD: Parsing in- crementally for constrained auto-regressive decoding from language models,” inEMNLP, pp. 9895–9901, 2021
2021
-
[14]
Text-to-SQL error correction with language models of code,
Z. Chen, S. Chen, M. White, R. Mooney,et al., “Text-to-SQL error correction with language models of code,” inACL (Short Papers), pp. 1359–1372, 2023
2023
-
[15]
SHARE: An SLM-based hierarchical action correction assistant for text-to-SQL,
G. Qu, J. Li, B. Qin,et al., “SHARE: An SLM-based hierarchical action correction assistant for text-to-SQL,” inACL, pp. 11268–11292, 2025
2025
-
[16]
Enhancing text-to-SQL parsing through question rewrit- ing and execution-guided refinement,
W. Maoet al., “Enhancing text-to-SQL parsing through question rewrit- ing and execution-guided refinement,” inFindings of ACL, pp. 2009– 2024, 2024
2009
-
[17]
CoSQL: A conversational text-to- SQL challenge towards cross-domain natural language interfaces to databases,
T. Yu, R. Zhang, H. Er,et al., “CoSQL: A conversational text-to- SQL challenge towards cross-domain natural language interfaces to databases,” inEMNLP-IJCNLP, pp. 1962–1979, 2019
1962
-
[18]
Speak to your parser: Interactive text-to-SQL with natural language feedback,
A. Elgohary, S. Hosseini, and A. H. Awadallah, “Speak to your parser: Interactive text-to-SQL with natural language feedback,” inACL, pp. 2065–2077, 2020
2065
-
[19]
Interactive text-to-SQL generation via editable step-by-step explanations,
Y . Tian, Z. Zhang, Z. Ning,et al., “Interactive text-to-SQL generation via editable step-by-step explanations,” inEMNLP, pp. 16149–16166, 2023
2023
-
[20]
Benchmarking and improving text-to-SQL generation under ambiguity,
A. Bhaskar, T. Tomar, A. Sathe, and S. Sarawagi, “Benchmarking and improving text-to-SQL generation under ambiguity,” inEMNLP, pp. 7053–7074, 2023
2023
-
[21]
AMBROSIA: A benchmark for parsing ambiguous questions into database queries,
I. Saparina and M. Lapata, “AMBROSIA: A benchmark for parsing ambiguous questions into database queries,” inNeurIPS, pp. 90600– 90628, 2024
2024
-
[22]
PRACTIQ: A practical conversational text-to-SQL dataset with ambiguous and unanswerable queries,
S. Qiuet al., “PRACTIQ: A practical conversational text-to-SQL dataset with ambiguous and unanswerable queries,” inNAACL, 2025
2025
-
[23]
ODIN: A NL2SQL recommender to handle schema ambiguity,
K. Vaidya, A. Sankararaman, J. Ding, C. Lei, X. Qin, B. Narayanaswamy, and T. Kraska, “ODIN: A NL2SQL recommender to handle schema ambiguity,”arXiv preprint arXiv:2505.19302, 2025
-
[24]
CLEAR: A parser-independent disambiguation framework for NL2SQL,
M. Zhang, K. Ma, L. Xu, K. Zhang, Y . Peng, and R. Jin, “CLEAR: A parser-independent disambiguation framework for NL2SQL,” inICDE, pp. 1–14, 2025
2025
-
[25]
arXiv preprint arXiv:2207.10397 , year=
B. Chen, F. Zhang, A. Nguyen,et al., “CodeT: Code generation with generated tests,”arXiv preprint arXiv:2207.10397, 2023
-
[26]
Teaching Large Language Models to Self-Debug
X. Chen, M. Lin, N. Sch ¨arli, and D. Zhou, “Teaching large language models to self-debug,”arXiv preprint arXiv:2304.05128, 2024
work page internal anchor Pith review arXiv 2024
-
[27]
Reflexion: Language agents with verbal reinforcement learning,
N. Shinn, F. Cassano, A. Gopinath, K. Narasimhan, and S. Yao, “Reflexion: Language agents with verbal reinforcement learning,” in NeurIPS, 2023
2023
-
[28]
Cafarella, Çagatay Demiralp, and Michael Stonebraker
P. B. Chen, M. Cafarella, C ¸ . Demiralp, and M. Stonebraker, “Beaver: An enterprise benchmark for text-to-sql,”arXiv preprint arXiv:2409.02038, 2024
work page internal anchor Pith review arXiv 2024
-
[29]
Seq2SQL: Generating Structured Queries from Natural Language using Reinforcement Learning
V . Zhong, C. Xiong, and R. Socher, “Seq2SQL: Generating structured queries from natural language using reinforcement learning,”arXiv preprint arXiv:1709.00103, 2017
work page internal anchor Pith review arXiv 2017
-
[30]
Bridging textual and tabular data for cross-domain text-to-SQL semantic parsing,
X. V . Lin, R. Socher, and C. Xiong, “Bridging textual and tabular data for cross-domain text-to-SQL semantic parsing,” inFindings of EMNLP, pp. 4870–4888, 2020
2020
-
[31]
Resdsql: Decoupling schema linking and skeleton parsing for text-to-sql,
H. Li, B. Hui, G. Qu, J. Yang, B. Li, B. Li, B. Wang, B. Qin, R. Cao, and J. Li, “Resdsql: Decoupling schema linking and skeleton parsing for text-to-sql,” inProc. of AAAI, 2023
2023
-
[32]
CodeS: Towards building open- source language models for text-to-SQL,
H. Li, J. Zhang, H. Liu,et al., “CodeS: Towards building open- source language models for text-to-SQL,”Proceedings of the ACM on Management of Data, vol. 2, no. 3, pp. 1–28, 2024
2024
-
[33]
The death of schema linking? text-to-sql in the age of well-reasoned language models,
K. Maamari, F. Abubaker, D. Jaroslawicz, and A. Mhedhbi, “The death of schema linking? Text-to-SQL in the age of well-reasoned language models,”arXiv preprint arXiv:2408.07702, 2024
-
[34]
A survey of nl2sql with large language models: Where are we, and where are we going?
L. Xinyu, S. Shuyu, L. Boyan,et al., “A survey of text-to-SQL in the era of LLMs: Where are we, and where are we going?,”arXiv preprint arXiv:2408.05109, 2025
-
[35]
Next-generation database interfaces: A survey of LLM-based text-to-SQL,
Z. Hong, Z. Yuan, Q. Zhang,et al., “Next-generation database interfaces: A survey of LLM-based text-to-SQL,”arXiv preprint arXiv:2406.08426, 2025
-
[36]
Towards robustness of text-to-SQL models against synonym substitution,
Y . Gan, X. Chen, Q. Huang, M. Purver, J. R. Woodward, J. Xie, and P. Huang, “Towards robustness of text-to-SQL models against synonym substitution,” inACL, pp. 2505–2515, 2021
2021
-
[37]
Exploring underexplored limitations of cross-domain text-to-SQL generalization,
Y . Gan, X. Chen, and M. Purver, “Exploring underexplored limitations of cross-domain text-to-SQL generalization,” inEMNLP, pp. 8926–8931, 2021
2021
-
[38]
Interactive text-to-SQL via expected information gain for disambiguation,
L. Qiu, J. Li, C. Su, and L. Chen, “Interactive text-to-SQL via expected information gain for disambiguation,”arXiv preprint arXiv:2507.06467, 2025
-
[39]
Know what I don’t know: Han- dling ambiguous and unknown questions for text-to-SQL,
B. Wang, Y . Gao, Z. Li, and J.-G. Lou, “Know what I don’t know: Han- dling ambiguous and unknown questions for text-to-SQL,” inFindings of ACL, pp. 5701–5714, 2023
2023
-
[40]
Spider 2.0: Evaluating language models on real-world enterprise text-to-SQL workflows,
F. Leiet al., “Spider 2.0: Evaluating language models on real-world enterprise text-to-SQL workflows,” inICLR, 2025
2025
-
[41]
BenchPress: A human-in-the-loop annotation sys- tem for rapid text-to-SQL benchmark curation,
F. Wenz, O. Bouattour, D. Yang, J. Choi, C. Gregg, N. Tatbul, and C ¸ a˘gatay Demiralp, “BenchPress: A human-in-the-loop annotation sys- tem for rapid text-to-SQL benchmark curation,” inCIDR, 2026
2026
-
[42]
Reliable text-to-SQL with adaptive abstention,
K. Chen, Y . Chen, X. Yu, and N. Koudas, “Reliable text-to-SQL with adaptive abstention,”arXiv preprint arXiv:2501.10858, 2025
-
[43]
SNAILS: Schema naming assessments for improved LLM-based SQL inference,
K. Luoma and A. Kumar, “SNAILS: Schema naming assessments for improved LLM-based SQL inference,”Proceedings of the ACM on Management of Data, vol. 3, no. 1, pp. 1–25, 2025
2025
-
[44]
SQL-of-Thought: Multi-agentic text-to-SQL with guided error correction,
S. Chaturvedi, A. Chadha, and L. Bindschaedler, “SQL-of-Thought: Multi-agentic text-to-SQL with guided error correction,”arXiv preprint arXiv:2509.00581, 2025
-
[45]
Generalized coloring for tree-like graphs,
K. Jansen and P. Scheffler, “Generalized coloring for tree-like graphs,” Discrete Applied Mathematics, vol. 75, no. 2, pp. 135–155, 1997
1997
-
[46]
Garcia-Molina, J
H. Garcia-Molina, J. D. Ullman, and J. Widom,Database Systems: The Complete Book. Pearson Prentice Hall, 2nd ed., 2008
2008
-
[47]
Abiteboul, R
S. Abiteboul, R. Hull, and V . Vianu,Foundations of Databases. Addison- Wesley, 1995
1995
-
[48]
Self-consistency improves chain of thought reasoning in language models,
X. Wang, J. Wei, D. Schuurmans, Q. V . Le, E. H. Chi, S. Narang, A. Chowdhery, and D. Zhou, “Self-consistency improves chain of thought reasoning in language models,” inICLR, 2023
2023
-
[49]
C3: Zero -shot text-to-SQL with ChatGPT
X. Dong, C. Zhang, Y . Ge, Y . Mao, Y . Gao, J. Lin, and D. Lou, “C3: Zero-shot text-to-sql with chatgpt,”arXiv preprint arXiv:2307.07306, 2023
-
[50]
Chain-of-thought prompting elicits reasoning in large language models,
J. Wei, X. Wang, D. Schuurmans, M. Bosma, B. Ichter, F. Xia, E. H. Chi, Q. V . Le, and D. Zhou, “Chain-of-thought prompting elicits reasoning in large language models,” inNeurIPS, pp. 24824–24837, 2022
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.