Recognition: unknown
SENECA: Small-Sample Discrete Entropy Estimation via Self-Consistent Missing Mass
Pith reviewed 2026-05-09 18:52 UTC · model grok-4.3
The pith
SENECA estimates discrete entropy more accurately from small samples by using a self-consistent calculation of the missing probability mass.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
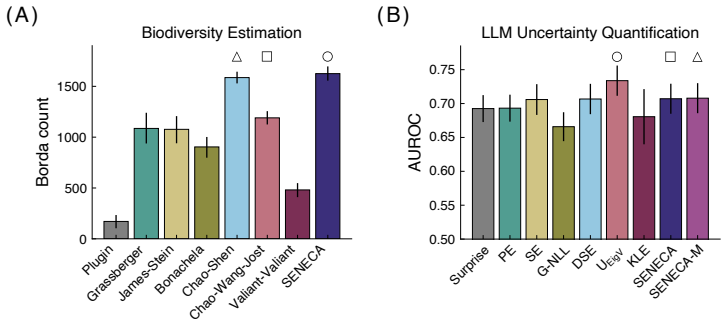
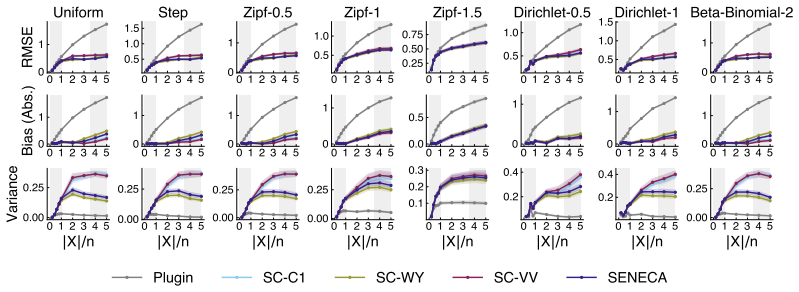
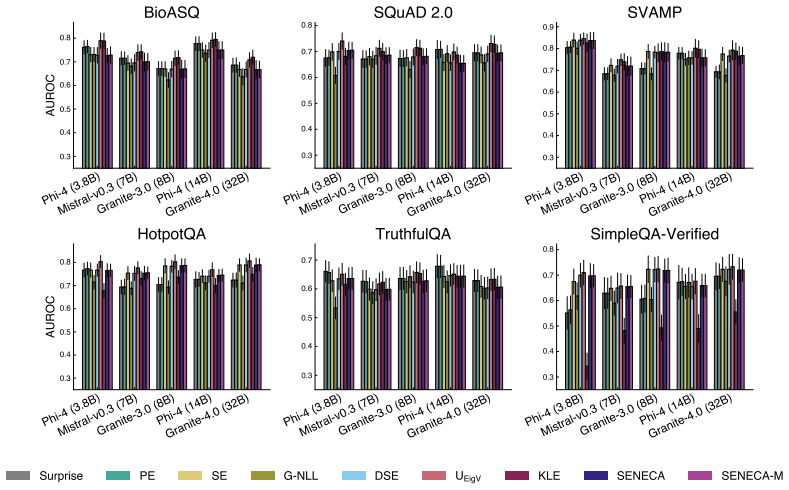
The paper establishes SENECA, an entropy estimator built around a novel self-consistent missing mass calculation. This calculation determines the aggregate probability of unobserved support elements such that the resulting entropy value remains internally consistent with the sample frequencies. Numerical experiments across multiple distributions and small sample sizes indicate superior performance relative to many state-of-the-art alternatives, while applications to biodiversity estimation and detection of incorrect large language model responses show the method remains competitive with domain-specific baselines.
What carries the argument
The self-consistent missing mass calculation, which solves for the total unobserved probability in a manner that stays consistent with the entropy estimate derived from the observed sample.
Load-bearing premise
The self-consistent missing mass calculation produces an unbiased or low-bias estimate of unobserved probability mass across the tested distributions and sample sizes.
What would settle it
A controlled experiment on a known discrete distribution with small sample size where the self-consistent missing mass value deviates markedly from the true unobserved mass and produces entropy estimates worse than standard baselines.
Figures








read the original abstract
Discrete entropy estimation is a classic information theory problem, wherein the average information content of a discrete random variable is estimated from samples alone. Naive approaches, such as the plugin method, fail to account for the probability mass associated with members of the random variable's support that are unobserved in a given sample, known as the "missing mass." The resulting systemic underestimation is particularly problematic when data is time-consuming or costly to gather. We propose SENECA, an entropy estimation scheme based on a novel ``self-consistent'' missing mass calculation. Extensive numerical experiments indicate that our approach outperforms many state-of-the-art alternatives overall in the small-sample setting. We then apply SENECA to two practical use cases, namely biodiversity estimation and the detection of incorrect large language model responses, where our method is competitive with domain-specific approaches. Our work advances SENECA as an effective drop-in replacement for small-sample entropy estimation, with broad utility across several domains.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SENECA, a discrete entropy estimator that computes the missing probability mass via a novel self-consistent fixed-point equation rather than external smoothing or plug-in corrections. It claims that this yields lower bias and better overall accuracy than state-of-the-art alternatives in the small-sample regime, supported by numerical experiments across multiple distributions and sample sizes, and demonstrates competitive results when applied to biodiversity estimation and detection of incorrect LLM outputs.
Significance. If the self-consistent estimator can be shown to deliver reliably lower bias without hidden uniformity assumptions, the work would supply a practical, parameter-light tool for entropy estimation under data scarcity, with immediate relevance to information theory, ecology, and machine-learning reliability. The absence of free parameters and the direct use of a fixed-point relation are attractive features that distinguish it from many existing corrections.
major comments (2)
- [§4] §4 (Numerical Experiments): The central claim of outperformance is supported only by point estimates of error; no error bars, standard deviations across repeated trials, or formal statistical tests (paired t-test, Wilcoxon signed-rank, etc.) are reported. Without these, it is impossible to judge whether the reported gains over baselines are statistically reliable or could arise from sampling variability.
- [§3.2] §3.2 (Self-Consistent Missing Mass): The fixed-point equation that equates the entropy computed from observed frequencies plus missing mass m to an expression involving m itself is not accompanied by a bias analysis for non-uniform unobserved mass. If the equation implicitly treats the unseen symbols as equiprobable, the estimator will incur systematic error precisely on the heavy-tailed (Zipf, power-law) distributions that dominate the small-sample entropy literature; the experiments would then only demonstrate superiority inside the tested family.
minor comments (3)
- [Abstract] Abstract and §4: The range of alphabet sizes, exact sample sizes (n), and distribution families (including the exponents of any Zipf distributions) should be stated explicitly so readers can reproduce the experimental regime.
- [§5.1] §5.1 (Biodiversity): Clarify the precise mapping from the SENECA entropy estimate to the biodiversity index being reported; the current description leaves the downstream calculation implicit.
- [§3] Notation: The symbol m is used both for the missing-mass scalar and, in some places, for the number of missing symbols; a single consistent definition would remove ambiguity.
Simulated Author's Rebuttal
We thank the referee for their constructive and insightful comments on our manuscript. We address each major comment point by point below, indicating the revisions we have made to strengthen the presentation and analysis.
read point-by-point responses
-
Referee: [§4] §4 (Numerical Experiments): The central claim of outperformance is supported only by point estimates of error; no error bars, standard deviations across repeated trials, or formal statistical tests (paired t-test, Wilcoxon signed-rank, etc.) are reported. Without these, it is impossible to judge whether the reported gains over baselines are statistically reliable or could arise from sampling variability.
Authors: We agree that reporting only point estimates limits the ability to assess the reliability of the observed improvements. In the revised manuscript, we have expanded Section 4 to include results from 100 independent trials for each distribution and sample size. All figures now display mean error values with standard deviation error bars. We have also added a new table with the outcomes of paired t-tests and Wilcoxon signed-rank tests comparing SENECA against each baseline. These tests confirm that the performance advantages are statistically significant (p < 0.05) in the small-sample regime for the majority of settings. These additions directly address the concern and provide quantitative evidence that the gains are not attributable to sampling variability. revision: yes
-
Referee: [§3.2] §3.2 (Self-Consistent Missing Mass): The fixed-point equation that equates the entropy computed from observed frequencies plus missing mass m to an expression involving m itself is not accompanied by a bias analysis for non-uniform unobserved mass. If the equation implicitly treats the unseen symbols as equiprobable, the estimator will incur systematic error precisely on the heavy-tailed (Zipf, power-law) distributions that dominate the small-sample entropy literature; the experiments would then only demonstrate superiority inside the tested family.
Authors: We appreciate the referee raising this important methodological point. The self-consistent fixed-point equation does not implicitly assume equiprobability of the unseen symbols. The missing mass m is solved for by enforcing consistency between the observed frequency-based entropy and the normalization constraint, without assigning individual probabilities to the unseen support; the contribution of the missing mass to the entropy is handled via a single aggregate term. To address the request for a bias analysis under non-uniform unobserved mass, we have added a new theoretical subsection in Section 3.2 deriving bounds on the bias that hold for arbitrary distributions over the unseen symbols, showing that the bias vanishes as the sample size grows. We have further expanded the experiments in Section 4 to include additional heavy-tailed cases (Zipf distributions with exponents from 0.5 to 2.0) and verified that SENECA retains its advantage. The original experiments already covered several power-law and Zipf-like distributions, but the new analysis and results provide stronger support for robustness beyond the tested family. revision: yes
Circularity Check
No circularity; self-consistent estimator is a derived fixed-point, not tautological
full rationale
The paper defines SENECA via a novel self-consistent missing mass calculation whose fixed-point equation is presented as an independent derivation from observed frequencies and entropy properties. Performance claims rest on numerical experiments across distributions rather than any reduction of the estimator to its inputs by construction. No self-citations, fitted parameters renamed as predictions, or ansatz smuggling appear in the derivation chain. The method is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Marah Abdin, Jyoti Aneja, Harkirat Behl, Sébastien Bubeck, Ronen Eldan, Suriya Gunasekar, Michael Harrison, Russell J Hewett, Mojan Javaheripi, Piero Kauffmann, et al. Phi-4 Technical Report.arXiv preprint arXiv:2412.08905, 2024
work page internal anchor Pith review arXiv 2024
-
[2]
Phi-4-Mini Technical Report: Compact yet Powerful Multimodal Language Models via Mixture-of-LoRAs
Abdelrahman Abouelenin, Atabak Ashfaq, Adam Atkinson, Hany Awadalla, Nguyen Bach, Jianmin Bao, Alon Benhaim, Martin Cai, Vishrav Chaudhary, Congcong Chen, et al. Phi-4-Mini Technical Report: Compact yet Powerful Multimodal Language Models via Mixture-of-LoRAs. arXiv preprint arXiv:2503.01743, 2025
work page internal anchor Pith review arXiv 2025
-
[3]
Rethinking Uncertainty Es- timation in LLMs: A Principled Single-Sequence Measure
Lukas Aichberger, Kajetan Schweighofer, and Sepp Hochreiter. Rethinking Uncertainty Es- timation in LLMs: A Principled Single-Sequence Measure. InThe Fourteenth International Conference on Learning Representations, 2026. URL https://openreview.net/forum? id=wdhruVcRx1
2026
-
[4]
Convergence properties of functional estimates for discrete distributions.Random Structures & Algorithms, 19(3-4):163–193, 2001
András Antos and Ioannis Kontoyiannis. Convergence properties of functional estimates for discrete distributions.Random Structures & Algorithms, 19(3-4):163–193, 2001
2001
-
[5]
Estimating the Entropy of Linguistic Distributions
Aryaman Arora, Clara Meister, and Ryan Cotterell. Estimating the Entropy of Linguistic Distributions. InProceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pages 175–195, 2022
2022
-
[6]
On a Statistical Estimate for the Entropy of a Sequence of Independent Random Variables.Theory of Probability & Its Applications, 4(3):333–336, 1959
Georgij P Basharin. On a Statistical Estimate for the Entropy of a Sequence of Independent Random Variables.Theory of Probability & Its Applications, 4(3):333–336, 1959
1959
-
[7]
Entropy estimates of small data sets.Journal of Physics A: Mathematical and Theoretical, 41(20):202001, 2008
Juan A Bonachela, Haye Hinrichsen, and Miguel A Munoz. Entropy estimates of small data sets.Journal of Physics A: Mathematical and Theoretical, 41(20):202001, 2008
2008
-
[8]
Accelerating Convergence
Richard L Burden and J Douglas Faires. Accelerating Convergence. InNumerical Analysis, page 89. Brooks/Cole, Cengage Learning, 9th edition, 2011. ISBN 978-0538733519
2011
-
[9]
infomeasure: a comprehensive Python package for information theory measures and estimators.Scientific Reports, 15(1): 29323, 2025
Carlson Moses Büth, Kishor Acharya, and Massimiliano Zanin. infomeasure: a comprehensive Python package for information theory measures and estimators.Scientific Reports, 15(1): 29323, 2025
2025
-
[10]
Nonparametric Estimation of the Number of Classes in a Population.Scandinavian Journal of Statistics, pages 265–270, 1984
Anne Chao. Nonparametric Estimation of the Number of Classes in a Population.Scandinavian Journal of Statistics, pages 265–270, 1984
1984
-
[11]
Species estimation and applications
Anne Chao. Species estimation and applications. In Samuel Kotz, Campbell B Read, Brani Vidakovic, and Norman L. Johnson, editors,Encyclopedia of Statistical Sciences, volume 12, pages 7907–7916. Wiley, New York, 2 edition, 2005
2005
-
[12]
Diversity measures.Encyclopedia of Theoretical Ecology, pages 203–207, 2012
Anne Chao and Lou Jost. Diversity measures.Encyclopedia of Theoretical Ecology, pages 203–207, 2012
2012
-
[13]
Nonparametric estimation of Shannon’s index of diversity when there are unseen species in sample.Environmental and Ecological Statistics, 10:429–443, 2003
Anne Chao and Tsung-Jen Shen. Nonparametric estimation of Shannon’s index of diversity when there are unseen species in sample.Environmental and Ecological Statistics, 10:429–443, 2003
2003
-
[14]
Entropy and the species accumulation curve: a novel entropy estimator via discovery rates of new species.Methods in Ecology and Evolution, 4(11): 1091–1100, 2013
Anne Chao, Yun Tao Wang, and Lou Jost. Entropy and the species accumulation curve: a novel entropy estimator via discovery rates of new species.Methods in Ecology and Evolution, 4(11): 1091–1100, 2013
2013
-
[15]
I Chien and Olgica Milenkovic. Regularized Weighted Chebyshev Approximations for Support Estimation.arXiv preprint arXiv:1901.07506, 2019
-
[16]
Comparing the Areas under Two or More Correlated Receiver Operating Characteristic Curves: A Nonparametric Approach.Biometrics, pages 837–845, 1988
Elizabeth R DeLong, David M DeLong, and Daniel L Clarke-Pearson. Comparing the Areas under Two or More Correlated Receiver Operating Characteristic Curves: A Nonparametric Approach.Biometrics, pages 837–845, 1988
1988
-
[17]
Nonparametric richness estimators Chao1 and ACE must not be used with amplicon sequence variant data.The ISME Journal, 18 (1):wrae106, 2024
Yongcui Deng, Alexander K Umbach, and Josh D Neufeld. Nonparametric richness estimators Chao1 and ACE must not be used with amplicon sequence variant data.The ISME Journal, 18 (1):wrae106, 2024. 11
2024
-
[18]
Meta-analysis in clinical trials.Controlled Clinical Trials, 7(3):177–188, 1986
Rebecca DerSimonian and Nan Laird. Meta-analysis in clinical trials.Controlled Clinical Trials, 7(3):177–188, 1986
1986
-
[19]
Beiter Bootstrap Confidence Intervals.Journal of the American statistical Association, 82(397):171–185, 1987
Bradley Efron. Beiter Bootstrap Confidence Intervals.Journal of the American statistical Association, 82(397):171–185, 1987
1987
-
[20]
A comprehensive review and evaluation of species richness estimation.Briefings in Bioinformatics, 26(2):bbaf158, 2025
Johanna Elena Schmitz and Sven Rahmann. A comprehensive review and evaluation of species richness estimation.Briefings in Bioinformatics, 26(2):bbaf158, 2025
2025
-
[21]
Estimating the uncertainty in estimates of root mean square error of prediction: application to determining the size of an adequate test set in multivariate calibration
Nicolaas (Klaas) M Faber. Estimating the uncertainty in estimates of root mean square error of prediction: application to determining the size of an adequate test set in multivariate calibration. Chemometrics and Intelligent Laboratory Systems, 49(1):79–89, 1999
1999
-
[22]
doi: 10.1038/ s41586-024-07421-0
Sebastian Farquhar, Joel Kossen, Lukas Kuhn, and Yarin Gal. Detecting hallucinations in large language models using semantic entropy.Nature, 630:625–630, 2024. doi: 10.1038/ s41586-024-07421-0. URLhttps://doi.org/10.1038/s41586-024-07421-0
-
[23]
The Population Frequencies of Species and the Estimation of Population Parameters.Biometrika, 40(3-4):237–264, 1953
Irving J Good. The Population Frequencies of Species and the Estimation of Population Parameters.Biometrika, 40(3-4):237–264, 1953
1953
-
[24]
Granite 3.0 Language Models, October 2024
IBM Granite Team. Granite 3.0 Language Models, October 2024. URL https://github. com/ibm-granite/granite-3.0-language-models/
2024
-
[25]
Finite sample corrections to entropy and dimension estimates.Physics Letters A, 128(6-7):369–373, 1988
Peter Grassberger. Finite sample corrections to entropy and dimension estimates.Physics Letters A, 128(6-7):369–373, 1988
1988
-
[26]
Entropy Estimates from Insufficient Samplings.arXiv preprint physics/0307138, 2003
Peter Grassberger. Entropy Estimates from Insufficient Samplings.arXiv preprint physics/0307138, 2003
-
[27]
A Note on the Entropy of Words in Printed English.Information and Control, 7(3):304–306, 1964
Mario C Grignetti. A Note on the Entropy of Words in Printed English.Information and Control, 7(3):304–306, 1964
1964
-
[28]
Simpleqa verified: A reliable factuality benchmark to measure parametric knowledge, 2026
Lukas Haas, Gal Yona, Giovanni D’Antonio, Sasha Goldshtein, and Dipanjan Das. SimpleQA Verified: A Reliable Factuality Benchmark to Measure Parametric Knowledge.arXiv preprint arXiv:2509.07968, 2025
-
[29]
Complementing Self-Consistency with Cross-Model Disagreement for Uncertainty Quantifica- tion
Kimia Hamidieh, Veronika Thost, Walter Gerych, Mikhail Yurochkin, and Marzyeh Ghassemi. Complementing Self-Consistency with Cross-Model Disagreement for Uncertainty Quantifica- tion. InThe Fourteenth International Conference on Learning Representations, 2026. URL https://openreview.net/forum?id=lOoRJo8xWy
2026
-
[30]
Optimal Prediction of the Number of Unseen Species with Multiplicity
Yi Hao and Ping Li. Optimal Prediction of the Number of Unseen Species with Multiplicity. Advances in Neural Information Processing Systems, 33:8553–8564, 2020
2020
-
[31]
University of Wisconsin-Madison, Mathematics Research Center, 1975
Bernard Harris.The Statistical Estimation of Entropy in the Non-Parametric Case. University of Wisconsin-Madison, Mathematics Research Center, 1975
1975
-
[32]
On tests of the overall treatment effect in meta-analysis with normally distributed responses.Statistics in Medicine, 20(12):1771–1782, 2001
Joachim Hartung and Guido Knapp. On tests of the overall treatment effect in meta-analysis with normally distributed responses.Statistics in Medicine, 20(12):1771–1782, 2001
2001
-
[33]
Model Selection and the Bias-Variance Tradeoff
Trevor Hastie, Robert Tibshirani, and Jerome Friedman. Model Selection and the Bias-Variance Tradeoff. InThe Elements of Statistical Learning: Data Mining, Inference, and Prediction, pages 37–38. Springer, 2009. ISBN 978-0387848570
2009
-
[34]
Entropy Inference and the James-Stein Estimator, with Application to Nonlinear Gene Association Networks.Journal of Machine Learning Research, 10(7), 2009
Jean Hausser and Korbinian Strimmer. Entropy Inference and the James-Stein Estimator, with Application to Nonlinear Gene Association Networks.Journal of Machine Learning Research, 10(7), 2009
2009
-
[35]
DeBERTaV3: Improving DeBERTa using ELECTRA-Style Pre-Training with Gradient-Disentangled Embedding Sharing
Pengcheng He, Jianfeng Gao, and Weizhu Chen. DeBERTaV3: Improving DeBERTa using ELECTRA-Style Pre-Training with Gradient-Disentangled Embedding Sharing. InThe Eleventh International Conference on Learning Representations, 2021
2021
-
[36]
A Generalization of Sampling Without Replace- ment from a Finite Universe.Journal of the American Statistical Association, 47(260):663–685, 1952
Daniel G Horvitz and Donovan J Thompson. A Generalization of Sampling Without Replace- ment from a Finite Universe.Journal of the American Statistical Association, 47(260):663–685, 1952. 12
1952
-
[37]
Granite 4.0 language models
IBM Research. Granite 4.0 language models. https://github.com/ibm-granite/ granite-4.0-language-models, 2025
2025
-
[38]
Joanna IntHout, John Ioannidis, and George F Borm. The Hartung-Knapp-Sidik-Jonkman method for random effects meta-analysis is straightforward and considerably outperforms the standard DerSimonian-Laird method.BMC Medical Research Methodology, 14(1):25, 2014
2014
-
[39]
Luchini, Reet Patel, Antoine Bosselut, Lonneke Van Der Plas, and Roger E
Mete Ismayilzada, Antonio Laverghetta Jr., Simone A. Luchini, Reet Patel, Antoine Bosselut, Lonneke Van Der Plas, and Roger E. Beaty. Creative Preference Optimization. In Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng, editors,Findings of the Association for Computational Linguistics: EMNLP 2025, pages 9580–9609, Suzhou, Ch...
2025
-
[40]
URL https://aclanthology.org/2025
doi: 10.18653/v1/2025.findings-emnlp.509. URL https://aclanthology.org/2025. findings-emnlp.509/
-
[41]
Sweep Samples of Tropical Foliage Insects: Description of Study Sites, With Data on Species Abundances and Size Distributions.Ecology, 54(3):659–686, 1973
Daniel H Janzen. Sweep Samples of Tropical Foliage Insects: Description of Study Sites, With Data on Species Abundances and Size Distributions.Ecology, 54(3):659–686, 1973
1973
-
[42]
Sweep Samples of Tropical Foliage Insects: Effects of Seasons, Vegetation Types, Elevation, Time of Day, and Insularity.Ecology, 54(3):687–708, 1973
Daniel H Janzen. Sweep Samples of Tropical Foliage Insects: Effects of Seasons, Vegetation Types, Elevation, Time of Day, and Insularity.Ecology, 54(3):687–708, 1973
1973
-
[43]
On the bias of the Turing-Good estimate of probabilities.IEEE Transactions on Signal Processing, 42(2):496–498, 2002
Biing-Hwang Juang and SH Lo. On the bias of the Turing-Good estimate of probabilities.IEEE Transactions on Signal Processing, 42(2):496–498, 2002
2002
-
[44]
Language Models (Mostly) Know What They Know
Saurav Kadavath, Tom Conerly, Amanda Askell, Tom Henighan, Dawn Drain, Ethan Perez, Nicholas Schiefer, Zac Hatfield-Dodds, Nova DasSarma, Eli Tran-Johnson, et al. Language Models (Mostly) Know What They Know.arXiv preprint arXiv:2207.05221, 2022
work page internal anchor Pith review arXiv 2022
-
[45]
BioASQ-QA: A manually curated corpus for Biomedical Question Answering.Scientific Data, 10(1):170, 2023
Anastasia Krithara, Anastasios Nentidis, Konstantinos Bougiatiotis, and Georgios Paliouras. BioASQ-QA: A manually curated corpus for Biomedical Question Answering.Scientific Data, 10(1):170, 2023
2023
-
[46]
Semantic Uncertainty: Linguistic Invariances for Uncertainty Estimation in Natural Language Generation
Lorenz Kuhn, Yarin Gal, and Sebastian Farquhar. Semantic Uncertainty: Linguistic Invariances for Uncertainty Estimation in Natural Language Generation. InThe Eleventh International Conference on Learning Representations, 2023
2023
-
[47]
Gonzalez, Hao Zhang, and Ion Stoica
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. Efficient Memory Management for Large Language Model Serving with PagedAttention. InProceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles, 2023
2023
-
[48]
Ilaria Pia La Torre, David A Kelly, Hector D Menendez, and David Clark. To BEE or Not to BEE: Estimating more than Entropy with Biased Entropy Estimators.arXiv preprint arXiv:2501.11395, 2025
-
[49]
How Much Is Unseen Depends Chiefly on Information About the Seen
Seongmin Lee and Marcel Böhme. How Much Is Unseen Depends Chiefly on Information About the Seen. InProceedings of the 13th International Conference on Learning Representations, May 2025
2025
-
[50]
Linlin Li, Ivan Titov, and Caroline Sporleder. Improved Estimation of Entropy for Evaluation of Word Sense Induction.Computational Linguistics, 40(3):671–685, September 2014. doi: 10.1162/COLI_a_00196. URLhttps://aclanthology.org/J14-3007/
-
[51]
On the sub-Gaussianity of the missing mass.Statistics & Probability Letters, 206:109991, 2024
Yanpeng Li and Boping Tian. On the sub-Gaussianity of the missing mass.Statistics & Probability Letters, 206:109991, 2024
2024
-
[52]
Bradley Efron and Robert J Tibshirani.An introduction to the bootstrap, volume
Stephanie Lin, Jacob Hilton, and Owain Evans. TruthfulQA: Measuring How Models Mimic Human Falsehoods. In Smaranda Muresan, Preslav Nakov, and Aline Villavicencio, edi- tors,Proceedings of the 60th Annual Meeting of the Association for Computational Lin- guistics (Volume 1: Long Papers), pages 3214–3252, Dublin, Ireland, May 2022. Associ- ation for Comput...
-
[53]
Generating with Confidence: Uncertainty Quantification for Black-box Large Language Models.Transactions on Machine Learning Research, 2024, 2024
Zhen Lin, Shubhendu Trivedi, and Jimeng Sun. Generating with Confidence: Uncertainty Quantification for Black-box Large Language Models.Transactions on Machine Learning Research, 2024, 2024. ISSN 2835-8856
2024
-
[54]
Enhancing Hallucination Detection through Noise Injection
Litian Liu, Reza Pourreza, Sunny Panchal, Apratim Bhattacharyya, Yubing Jian, Yao Qin, and Roland Memisevic. Enhancing Hallucination Detection through Noise Injection. In The Fourteenth International Conference on Learning Representations, 2026. URL https: //openreview.net/forum?id=WnM3sluiVn
2026
-
[55]
Learning theory and language modeling
David McAllester and Robert E Schapire. Learning theory and language modeling. InSeven- teenth International Joint Conference on Artificial Intelligence, 2001
2001
-
[56]
On the Convergence Rate of Good-Turing Estimators
David A McAllester and Robert E Schapire. On the Convergence Rate of Good-Turing Estimators. InConference on Learning Theory, pages 1–6, 2000
2000
-
[57]
Estimating Semantic Alphabet Size for LLM Uncertainty Quantification
Lucas Hurley McCabe, Rimon Melamed, Thomas Hartvigsen, and H Howie Huang. Estimating Semantic Alphabet Size for LLM Uncertainty Quantification. InThe Fourteenth International Conference on Learning Representations, 2026. URL https://openreview.net/forum? id=uYK6GPVg1O
2026
-
[58]
Beyond Semantic Entropy: Boosting LLM Uncertainty Quantification with Pairwise Semantic Similarity
Dang Nguyen, Ali Payani, and Baharan Mirzasoleiman. Beyond Semantic Entropy: Boosting LLM Uncertainty Quantification with Pairwise Semantic Similarity. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar, editors,Findings of the Associa- tion for Computational Linguistics: ACL 2025, pages 4530–4540, Vienna, Austria, July 2025. A...
2025
-
[59]
Kernel Language Entropy: Fine-grained Uncertainty Quantification for LLMs from Semantic Similarities
Alexander Nikitin, Jannik Kossen, Yarin Gal, and Pekka Marttinen. Kernel Language Entropy: Fine-grained Uncertainty Quantification for LLMs from Semantic Similarities. InAdvances in Neural Information Processing Systems, volume 37, pages 8901–8929, 2024
2024
-
[60]
Improved Information Gain Estimates for Decision Tree Induction
Sebastian Nowozin. Improved Information Gain Estimates for Decision Tree Induction. In Proceedings of the 29th International Coference on International Conference on Machine Learning, pages 571–578, 2012
2012
-
[61]
Competitive Distribution Estimation: Why is Good-Turing Good.Advances in Neural Information Processing Systems, 28, 2015
Alon Orlitsky and Ananda Theertha Suresh. Competitive Distribution Estimation: Why is Good-Turing Good.Advances in Neural Information Processing Systems, 28, 2015
2015
-
[62]
Optimal prediction of the number of unseen species.Proceedings of the National Academy of Sciences, 113(47):13283–13288, 2016
Alon Orlitsky, Ananda Theertha Suresh, and Yihong Wu. Optimal prediction of the number of unseen species.Proceedings of the National Academy of Sciences, 113(47):13283–13288, 2016
2016
-
[63]
Generalized Good-Turing Improves Missing Mass Estimation.Journal of the American Statistical Association, 118(543):1890–1899, 2023
Amichai Painsky. Generalized Good-Turing Improves Missing Mass Estimation.Journal of the American Statistical Association, 118(543):1890–1899, 2023
2023
-
[64]
Estimation of Entropy and Mutual Information.Neural Computation, 15(6): 1191–1253, 2003
Liam Paninski. Estimation of Entropy and Mutual Information.Neural Computation, 15(6): 1191–1253, 2003
2003
-
[65]
Efficient semantic uncertainty quantification in language mod- els via diversity-steered sampling
Ji Won Park and Kyunghyun Cho. Efficient semantic uncertainty quantification in language mod- els via diversity-steered sampling. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026. URLhttps://openreview.net/forum?id=IiEtQPGVyV
2026
-
[66]
Arkil Patel, Satwik Bhattamishra, and Navin Goyal. Are NLP Models really able to Solve Simple Math Word Problems? InProceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 2080–2094, Online, June 2021. Association for Computational Linguistics. doi: 10.18653/ v1/...
2021
-
[67]
A Comparative Analysis of Discrete Entropy Estimators for Large-Alphabet Problems.Entropy, 26(5):369, 2024
Assaf Pinchas, Irad Ben-Gal, and Amichai Painsky. A Comparative Analysis of Discrete Entropy Estimators for Large-Alphabet Problems.Entropy, 26(5):369, 2024
2024
-
[68]
Minimax Risk for Missing Mass Estimation
Nikhilesh Rajaraman, Andrew Thangaraj, and Ananda Theertha Suresh. Minimax Risk for Missing Mass Estimation. In2017 IEEE International Symposium on Information Theory (ISIT), pages 3025–3029. IEEE, 2017. 14
2017
-
[69]
SQuAD : 100,000+ questions for machine comprehension of text
Pranav Rajpurkar, Jian Zhang, Konstantin Lopyrev, and Percy Liang. SQuAD: 100,000+ Questions for Machine Comprehension of Text. In Jian Su, Kevin Duh, and Xavier Carreras, editors,Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, pages 2383–2392, Austin, Texas, November 2016. Association for Computational Linguistics....
-
[70]
Small-Sample Estimation of the Mutational Support and Distribution of SARS-CoV-2.IEEE/ACM Transactions on Computational Biology and Bioinformatics, 20(1):668–682, 2022
Vishal Rana, Eli Chien, Jianhao Peng, and Olgica Milenkovic. Small-Sample Estimation of the Mutational Support and Distribution of SARS-CoV-2.IEEE/ACM Transactions on Computational Biology and Bioinformatics, 20(1):668–682, 2022
2022
-
[71]
A conceptual guide to measuring species diversity.Oikos, 130(3):321–338, 2021
Michael Roswell, Jonathan Dushoff, and Rachael Winfree. A conceptual guide to measuring species diversity.Oikos, 130(3):321–338, 2021
2021
-
[72]
A Mathematical Theory of Communication.The Bell System Technical Journal, 27(3):379–423, 1948
Claude Elwood Shannon. A Mathematical Theory of Communication.The Bell System Technical Journal, 27(3):379–423, 1948
1948
-
[73]
The Introduction of Entropy and Information Methods to Ecology by Ramon Margalef.Entropy, 21(8):794, 2019
William B Sherwin and Narcis Prat i Fornells. The Introduction of Entropy and Information Methods to Ecology by Ramon Margalef.Entropy, 21(8):794, 2019
2019
-
[74]
A simple confidence interval for meta-analysis.Statistics in Medicine, 21(21):3153–3159, 2002
Kurex Sidik and Jeffrey N Jonkman. A simple confidence interval for meta-analysis.Statistics in Medicine, 21(21):3153–3159, 2002
2002
-
[75]
On Sub-Gaussian Concentration of Missing Mass.Theory of Probability & Its Applications, 68(2):324–329, 2023
Maciej Skorski. On Sub-Gaussian Concentration of Missing Mass.Theory of Probability & Its Applications, 68(2):324–329, 2023
2023
-
[76]
Fast Implementation of DeLong’s Algorithm for Comparing the Areas Under Correlated Receiver Operating Characteristic Curves.IEEE Signal Processing Letters, 21(11):1389–1393, 2014
Xu Sun and Weichao Xu. Fast Implementation of DeLong’s Algorithm for Comparing the Areas Under Correlated Receiver Operating Characteristic Curves.IEEE Signal Processing Letters, 21(11):1389–1393, 2014
2014
-
[77]
Estimating the Unseen: Improved Estimators for Entropy and Other Properties.Journal of the ACM (JACM), 64(6):1–41, 2017
Gregory Valiant and Paul Valiant. Estimating the Unseen: Improved Estimators for Entropy and Other Properties.Journal of the ACM (JACM), 64(6):1–41, 2017
2017
-
[78]
Pauli Virtanen, Ralf Gommers, Travis E. Oliphant, Matt Haberland, Tyler Reddy, David Cournapeau, Evgeni Burovski, Pearu Peterson, Warren Weckesser, Jonathan Bright, Stéfan J. van der Walt, Matthew Brett, Joshua Wilson, K. Jarrod Millman, Nikolay Mayorov, Andrew R. J. Nelson, Eric Jones, Robert Kern, Eric Larson, C J Carey, ˙Ilhan Polat, Yu Feng, Eric W. M...
-
[79]
Coverage-adjusted entropy estimation.Statistics in Medicine, 26(21):4039–4060, 2007
Vincent Q Vu, Bin Yu, and Robert E Kass. Coverage-adjusted entropy estimation.Statistics in Medicine, 26(21):4039–4060, 2007
2007
-
[80]
Chebyshev polynomials, moment matching, and optimal estimation of the unseen.The Annals of Statistics, 47(2):857–883, 2019
Yihong Wu and Pengkun Yang. Chebyshev polynomials, moment matching, and optimal estimation of the unseen.The Annals of Statistics, 47(2):857–883, 2019
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.