Recognition: unknown
Learning to Act and Cooperate for Distributed Black-Box Consensus Optimization
Pith reviewed 2026-05-09 18:34 UTC · model grok-4.3
The pith
Large language models can extract sparse guidance from optimization trajectories to adapt both internal agent actions and external cooperation in distributed black-box consensus problems.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
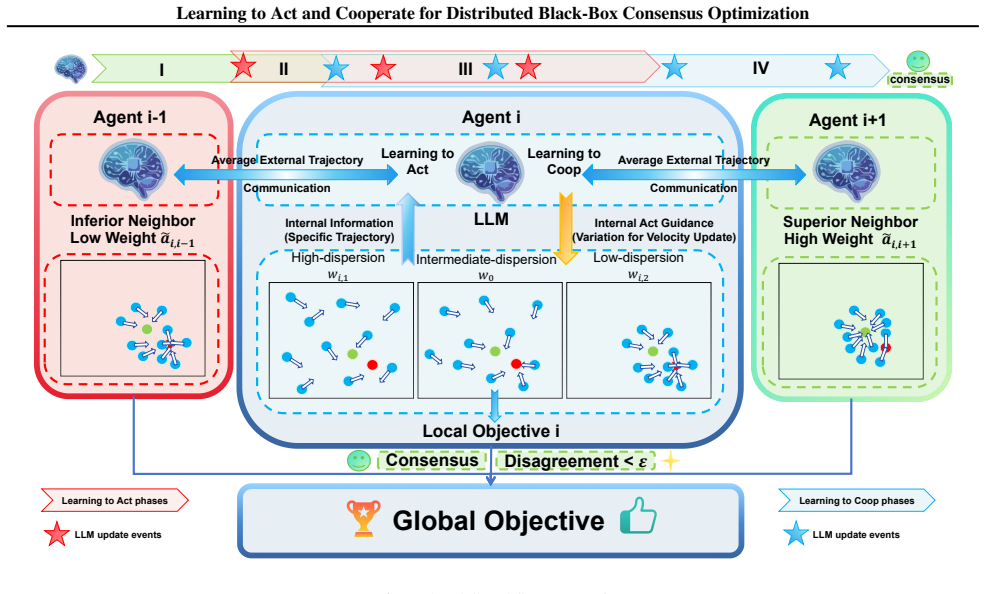
We redesign the agent-level swarm dynamics with an adaptive internal mechanism tailored to decentralized consensus settings, improving the balance between exploration, convergence, and local escape. Built on top of this adaptive execution layer, we propose Learning to Act and Cooperate (LAC-MAS), a trajectory-driven framework in which large language models provide sparse high-level guidance for shaping both agent-internal action behaviors and agent-external cooperation patterns from historical optimization trajectories. We further introduce a phased cognitive scheduling strategy to activate different forms of adaptation in a resource-aware manner.
What carries the argument
The LAC-MAS framework, in which large language models analyze historical trajectories to issue sparse high-level guidance that simultaneously shapes each agent's internal update rule and its external cooperation pattern with neighbors.
If this is right
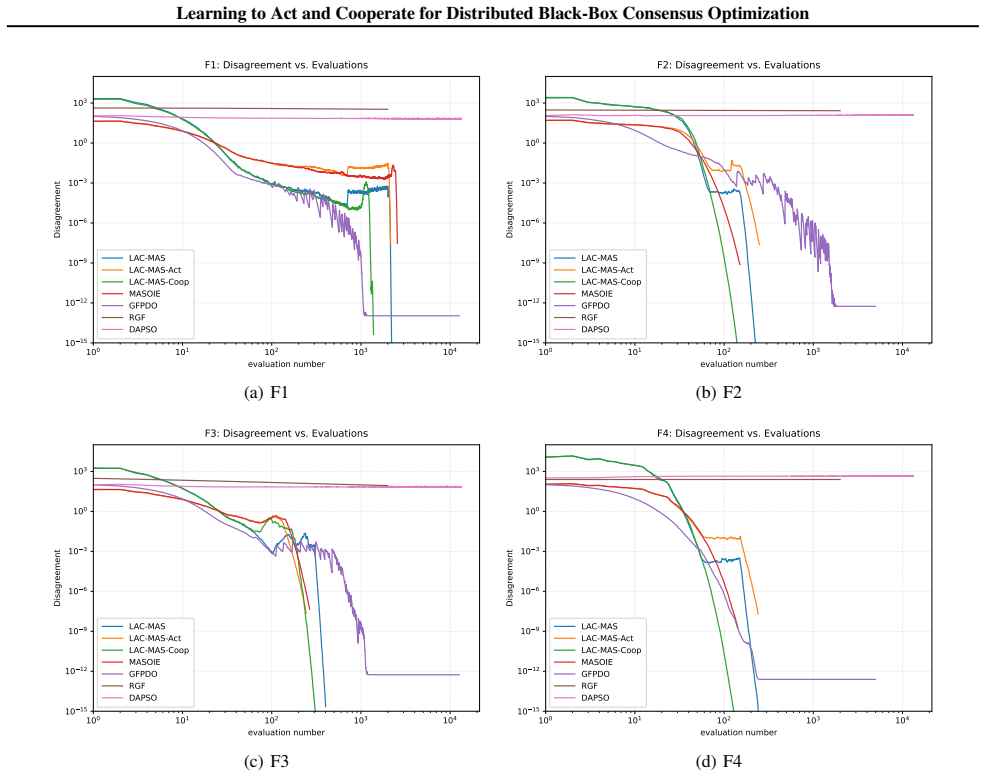
- Solution quality, convergence speed, and communication volume all improve over strong baselines on standard distributed black-box benchmarks.
- The same gains appear on real-world distributed tasks without requiring environment-specific tuning of cooperation rules.
- The method demonstrates a concrete path from manually engineered coordination protocols to trajectory-driven self-design of multi-agent optimization behavior.
- Phased scheduling keeps the added LLM queries infrequent enough that overall resource cost stays practical.
Where Pith is reading between the lines
- The same trajectory-to-guidance loop could be applied to other multi-agent coordination problems where explicit communication budgets matter, such as distributed robotics or sensor fusion.
- If the LLM component can be replaced by smaller distilled models without losing guidance quality, the method would become deployable on resource-constrained edge devices.
- The adaptive swarm layer may itself become a reusable primitive for other consensus-style algorithms that currently rely on static momentum or step-size schedules.
Load-bearing premise
Large language models can reliably extract useful sparse high-level guidance for agent-internal actions and external cooperation from historical trajectories in heterogeneous nonconvex environments while keeping computational and communication overhead manageable via phased scheduling.
What would settle it
An ablation study on the same benchmark suite in which the LLM guidance module is replaced by fixed handcrafted rules or random signals, yet the measured convergence speed, final solution quality, and total messages exchanged remain statistically indistinguishable from the full LAC-MAS runs.
Figures


read the original abstract
Distributed blackbox consensus optimization is a fundamental problem in multi-agent systems, where agents must improve a global objective using only local objective queries and limited neighbor communication. Existing methods largely rely on handcrafted update rules and static cooperation patterns, which often struggle to balance local adaptation, global coordination, and communication efficiency in heterogeneous nonconvex environments. In this paper, we take an initial step toward trajectory-driven self-design for distributed black-box consensus optimization. We first redesign the agent-level swarm dynamics with an adaptive internal mechanism tailored to decentralized consensus settings, improving the balance between exploration, convergence, and local escape. Built on top of this adaptive execution layer, we propose Learning to Act and Cooperate (LACMAS), a trajectorydriven framework in which large language models provide sparse highlevel guidance for shaping both agentinternal action behaviors and agentexternal cooperation patterns from historical optimization trajectories. We further introduce a phased cognitive scheduling strategy to activate different forms of adaptation in a resource-aware manner. Experiments on standard distributed black-box benchmarks and real-world distributed tasks show that LAC-MAS consistently improves solution quality, convergence efficiency, and communication efficiency over strong baselines, suggesting a practical route from handcrafted distributed coordination toward self-designing multi-agent optimization systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces LAC-MAS, a trajectory-driven framework for distributed black-box consensus optimization. It first redesigns agent-level swarm dynamics with an adaptive internal mechanism to better balance exploration, convergence, and local escape in decentralized settings. Built on this, large language models extract sparse high-level guidance from historical trajectories to shape both internal agent actions and external cooperation patterns, with a phased cognitive scheduling strategy to activate adaptations resource-efficiently. Experiments on standard distributed black-box benchmarks and real-world tasks are claimed to show consistent improvements in solution quality, convergence efficiency, and communication efficiency over strong baselines.
Significance. If the results hold, the work could meaningfully advance multi-agent systems research by providing a concrete route from handcrafted coordination rules toward LLM-assisted self-design in heterogeneous nonconvex environments. It explicitly builds on swarm dynamics and LLM capabilities while introducing phased scheduling for practicality, offering a falsifiable experimental path that could influence future distributed optimization methods if ablations confirm the LLM contribution.
major comments (2)
- [Abstract] Abstract: The central experimental claim that 'LAC-MAS consistently improves solution quality, convergence efficiency, and communication efficiency over strong baselines' lacks any reported details on the specific benchmarks, choice of baselines, number of independent runs, statistical tests, or error bars. This prevents verification that the data support the claim and is load-bearing for the paper's primary contribution.
- [Method] LAC-MAS framework description: The claim that LLM-derived guidance from trajectories produces gains beyond the redesigned adaptive execution layer and phased scheduling is not supported by ablations isolating the LLM component (e.g., replacing LLM outputs with heuristic or statistical trajectory summaries). Without such controls or error analysis on guidance quality, it remains possible that reported improvements derive primarily from the adaptive swarm dynamics rather than the trajectory-driven self-design element.
minor comments (1)
- [Abstract] The acronym is introduced as LACMAS in one sentence but rendered as LAC-MAS elsewhere; consistent hyphenation and capitalization would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which highlights important areas for strengthening the experimental presentation and validation of our contributions. We address each major comment below and will incorporate revisions to improve clarity and rigor without altering the core claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central experimental claim that 'LAC-MAS consistently improves solution quality, convergence efficiency, and communication efficiency over strong baselines' lacks any reported details on the specific benchmarks, choice of baselines, number of independent runs, statistical tests, or error bars. This prevents verification that the data support the claim and is load-bearing for the paper's primary contribution.
Authors: We agree that the abstract would benefit from additional context to make the claim verifiable at a glance. In the revised manuscript, we will update the abstract to briefly specify the benchmark categories (standard distributed black-box functions such as CEC suites and real-world tasks), the number of independent runs (e.g., 10–20), and the use of error bars with statistical comparisons where appropriate. The main experimental section already contains these details; the abstract revision will ensure the high-level claim is better supported without exceeding length constraints. revision: yes
-
Referee: [Method] LAC-MAS framework description: The claim that LLM-derived guidance from trajectories produces gains beyond the redesigned adaptive execution layer and phased scheduling is not supported by ablations isolating the LLM component (e.g., replacing LLM outputs with heuristic or statistical trajectory summaries). Without such controls or error analysis on guidance quality, it remains possible that reported improvements derive primarily from the adaptive swarm dynamics rather than the trajectory-driven self-design element.
Authors: This is a valid concern regarding the isolation of the LLM contribution. The current experiments compare LAC-MAS against strong non-LLM baselines and include the adaptive layer plus scheduling, but we did not include explicit ablations that replace LLM guidance with heuristic or statistical summaries. In the revision, we will add these controls (e.g., random/heuristic trajectory summaries and guidance-quality metrics) along with corresponding error analysis. This will directly test whether the trajectory-driven LLM element provides gains beyond the adaptive execution layer. revision: yes
Circularity Check
No circularity in the LAC-MAS framework derivation
full rationale
The paper's chain consists of redesigning adaptive swarm dynamics for decentralized consensus, layering LLM-based sparse guidance extracted from trajectories, and adding phased cognitive scheduling. These steps are introduced as constructive combinations of existing swarm and LLM ideas, with performance claims resting on external benchmark experiments rather than any equation, parameter fit, or self-citation that reduces the output to the input by construction. No load-bearing prediction or uniqueness claim collapses into a prior definition or fitted value.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
IEEE Transactions on Evolutionary Computation , volume=
Multi-Agent Swarm Optimization With Adaptive Internal and External Learning for Complex Consensus-Based Distributed Optimization , author=. IEEE Transactions on Evolutionary Computation , volume=. 2025 , publisher=
2025
-
[2]
IEEE/CAA Journal of Automatica Sinica , year=
Multi-agent swarm optimization with contribution-based cooperation for distributed multi-target localization and data association , author=. IEEE/CAA Journal of Automatica Sinica , year=
-
[3]
2024 International Conference on Cloud and Network Computing (ICCNC) , pages=
Joint Optimization of Multi-UAV Topology Control, Offloading and Path Planning in Air-Space Edge Computing Network , author=. 2024 International Conference on Cloud and Network Computing (ICCNC) , pages=. 2024 , organization=
2024
-
[4]
Proceedings of the 41st International Conference on Machine Learning (ICML) , year =
Incentivize without bonus: Efficient multi-agent reinforcement learning with structured uncertainty , author =. Proceedings of the 41st International Conference on Machine Learning (ICML) , year =
-
[5]
Proceedings of the IEEE , volume =
Consensus and Cooperation in Networked Multi-Agent Systems , author =. Proceedings of the IEEE , volume =. 2007 , doi =
2007
-
[6]
Proceedings of the 40th International Conference on Machine Learning , series =
Is Consensus Acceleration Possible in Decentralized Optimization over Slowly Time-Varying Networks? , author =. Proceedings of the 40th International Conference on Machine Learning , series =. 2023 , publisher =
2023
-
[7]
Handbook of Reinforcement Learning and Control , series =
Multi-Agent Reinforcement Learning: A Selective Overview of Theories and Algorithms , author =. Handbook of Reinforcement Learning and Control , series =. 2021 , doi =
2021
-
[8]
Proceedings of the 40th International Conference on Machine Learning , series =
RACE: Improve Multi-Agent Reinforcement Learning with Representation Asymmetry and Collaborative Embedding , author =. Proceedings of the 40th International Conference on Machine Learning , series =. 2023 , publisher =
2023
-
[9]
Advances in Neural Information Processing Systems , year =
Boosting Sample Efficiency and Generalization in Multi-Agent Reinforcement Learning with Equivariant Graph Neural Networks , author =. Advances in Neural Information Processing Systems , year =
-
[10]
The Surprising Effectiveness of
Yu, Chao and Velu, Akash and Vinitsky, Eugene and Gao, Jiaxuan and Wang, Yu and Bayen, Alexandre and Wu, Yi , booktitle =. The Surprising Effectiveness of
-
[11]
Proceedings of the Thirty-Eighth Conference on Uncertainty in Artificial Intelligence , series =
Reinforcement learning in many-agent settings under partial observability , author =. Proceedings of the Thirty-Eighth Conference on Uncertainty in Artificial Intelligence , series =. 2022 , publisher =
2022
-
[12]
IEEE Transactions on Evolutionary Computation , year =
Multi-Agent Evolution Strategy With Cooperative and Cumulative Step Adaptation for Black-Box Distributed Optimization , author =. IEEE Transactions on Evolutionary Computation , year =
-
[13]
IEEE/CAA Journal of Automatica Sinica , volume=
The confluence of evolutionary computation and multi-agent systems: A survey , author=. IEEE/CAA Journal of Automatica Sinica , volume=. 2025 , publisher=
2025
-
[14]
In The Twelfth International Conference on Learning Representations , year =
Large Language Models as Optimizers , author =. In The Twelfth International Conference on Learning Representations , year =
-
[15]
In The Twelfth International Conference on Learning Representations , year =
Large Language Models to Enhance Bayesian Optimization , author =. In The Twelfth International Conference on Learning Representations , year =
-
[16]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Teach Better or Show Smarter? On Instructions and Exemplars in Automatic Prompt Optimization , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[17]
Information Sciences , volume=
A general framework for population-based distributed optimization over networks , author=. Information Sciences , volume=. 2017 , publisher=
2017
-
[18]
IEEE Transactions on Neural Networks and Learning Systems , volume=
Randomized gradient-free method for multiagent optimization over time-varying networks , author=. IEEE Transactions on Neural Networks and Learning Systems , volume=. 2014 , publisher=
2014
-
[19]
2015 International Symposium on Signals, Circuits and Systems (ISSCS) , pages=
A distributed particle swarm optimization algorithm for block motion estimation using the strategies of diffusion adaptation , author=. 2015 International Symposium on Signals, Circuits and Systems (ISSCS) , pages=. 2015 , organization=
2015
-
[20]
SIAM Journal on Optimization , volume=
EXTRA: An exact first-order algorithm for decentralized consensus optimization , author=. SIAM Journal on Optimization , volume=. 2015 , doi=
2015
-
[21]
Foundations and Trends
Distributed optimization and statistical learning via the alternating direction method of multipliers , author=. Foundations and Trends. 2011 , publisher=
2011
-
[22]
LLaMoCo: Instruction Tuning of Large Language Models for Optimization Code Generation , year=
Ma, Zeyuan and Gong, Yue-Jiao and Guo, Hongshu and Chen, Jiacheng and Ma, Yining and Cao, Zhiguang and Zhang, Jun , journal=. LLaMoCo: Instruction Tuning of Large Language Models for Optimization Code Generation , year=
-
[23]
Zhang, Xian-Rong and Gong, Yue-Jiao and Zhong, Yuan-Ting and Huang, Ting and Zhang, Jun , year=. Large language model as meta-surrogate for offline data-driven many-task optimization: A proof-of-principle study , volume=. doi:10.1016/j.ins.2025.122762 , journal=
-
[24]
Proceedings of the 41st International Conference on Machine Learning , pages =
Zhuge, Mingchen and Wang, Wenyi and Kirsch, Louis and Faccio, Francesco and Khizbullin, Dmitrii and Schmidhuber, J\". Proceedings of the 41st International Conference on Machine Learning , pages =. 2024 , volume =
2024
-
[25]
Conference on Language Modeling , year=
AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation , author=. Conference on Language Modeling , year=
-
[26]
The Thirteenth International Conference on Learning Representations , year=
Scaling Large Language Model-based Multi-Agent Collaboration , author=. The Thirteenth International Conference on Learning Representations , year=
-
[27]
2025 , eprint=
MAS-GPT: Training LLMs to Build LLM-based Multi-Agent Systems , author=. 2025 , eprint=
2025
-
[28]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
Automatic Prompt Optimization with ``Gradient Descent'' and Beam Search , author=. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=. 2023 , doi=
2023
-
[29]
Proceedings of the 40th International Conference on Machine Learning , pages =
Single Point-Based Distributed Zeroth-Order Optimization with a Non-Convex Stochastic Objective Function , author =. Proceedings of the 40th International Conference on Machine Learning , pages =. 2023 , volume =
2023
-
[30]
Proceedings of the 41st International Conference on Machine Learning , pages =
An Online Optimization Perspective on First-Order and Zero-Order Decentralized Nonsmooth Nonconvex Stochastic Optimization , author =. Proceedings of the 41st International Conference on Machine Learning , pages =. 2024 , volume =
2024
-
[31]
2023 , volume =
Nabli, Adel and Oyallon, Edouard , booktitle =. 2023 , volume =
2023
-
[32]
Proceedings of the 38th International Conference on Machine Learning , pages =
Optimal Complexity in Decentralized Training , author =. Proceedings of the 38th International Conference on Machine Learning , pages =. 2021 , volume =
2021
-
[33]
Proceedings of The 26th International Conference on Artificial Intelligence and Statistics , pages =
Refined Convergence and Topology Learning for Decentralized SGD with Heterogeneous Data , author =. Proceedings of The 26th International Conference on Artificial Intelligence and Statistics , pages =. 2023 , volume =
2023
-
[34]
International Conference on Learning Representations , year=
Decentralized Deep Learning with Arbitrary Communication Compression , author=. International Conference on Learning Representations , year=
-
[35]
, journal=
Nedić, Angelia and Olshevsky, Alex and Rabbat, Michael G. , journal=. Network Topology and Communication-Computation Tradeoffs in Decentralized Optimization , year=
-
[36]
Advances in Neural Information Processing Systems , volume=
Can Decentralized Algorithms Outperform Centralized Algorithms? A Case Study for Decentralized Parallel Stochastic Gradient Descent , author=. Advances in Neural Information Processing Systems , volume=
-
[37]
Distributed Subgradient Methods for Multi-Agent Optimization , year=
Nedic, Angelia and Ozdaglar, Asuman , journal=. Distributed Subgradient Methods for Multi-Agent Optimization , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.