Recognition: unknown
Exploring the Limits of End-to-End Feature-Affinity Propagation for Single-Point Supervised Infrared Small Target Detection
Pith reviewed 2026-05-09 19:18 UTC · model grok-4.3
The pith
End-to-end feature-affinity propagation from single points achieves competitive infrared small target detection with 38 percent fewer false alarms.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
In-batch point-anchored feature-affinity propagation, when regularized by EMA decoupling and contrastive separation, produces effective online point-to-mask supervision without external label-evolution loops, allowing the detector to reach competitive accuracy while establishing a new ultra-low false-alarm regime on SIRST3.
What carries the argument
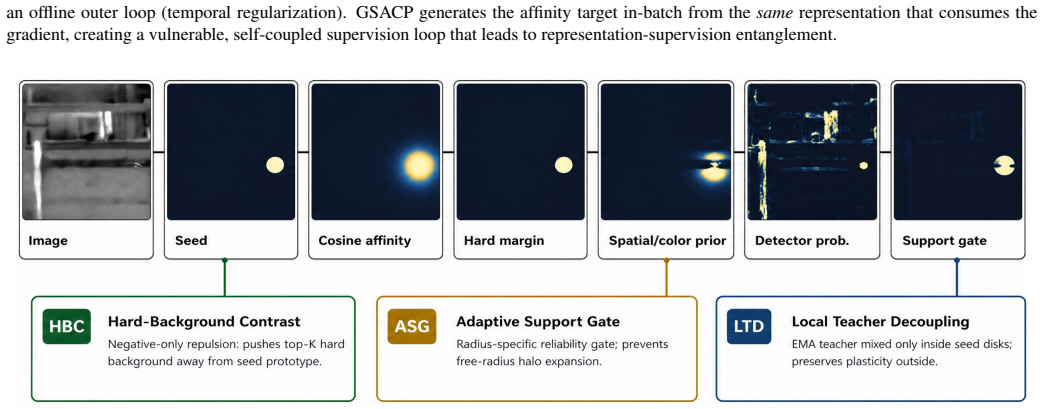
Point-anchored feature-affinity propagation, which generates online supervision targets from the model's current in-batch features using hard-margin affinity gated by local image priors.
If this is right
- Multi-stage active learning and physics-driven mask generation become unnecessary for achieving high precision under single-point supervision.
- The method supplies a compact alternative suited to deployment where false-alarm suppression is the dominant requirement.
- Systematic single-variable ablation isolates the separate contributions of EMA decoupling, contrastive separation, and support geometry to stable training.
- The performance boundaries of purely end-to-end affinity propagation are explicitly mapped against offline baselines.
Where Pith is reading between the lines
- If the drift mitigation proves general, the same online propagation pattern could reduce annotation costs in other single-point or sparse-label detection settings.
- The self-referential drift analysis points to a broader pattern that may arise in any end-to-end affinity or contrastive supervision scheme and would benefit from similar decoupling studies.
- Selective hybrid use of the online targets together with minimal offline refinement could further tighten boundaries without reintroducing full label-evolution pipelines.
Load-bearing premise
That regularized in-batch feature-affinity propagation will consistently improve the learned feature space rather than distort it to satisfy its own targets across the range of infrared scenes.
What would settle it
Reproducing the GSACP-Final training on SIRST3 and measuring no reduction or an increase in false-positive artifacts relative to PAL would show the claimed boundary-sharpening benefit does not hold.
Figures




read the original abstract
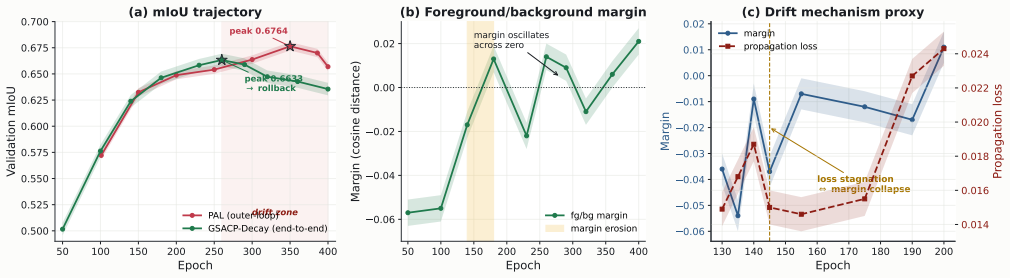
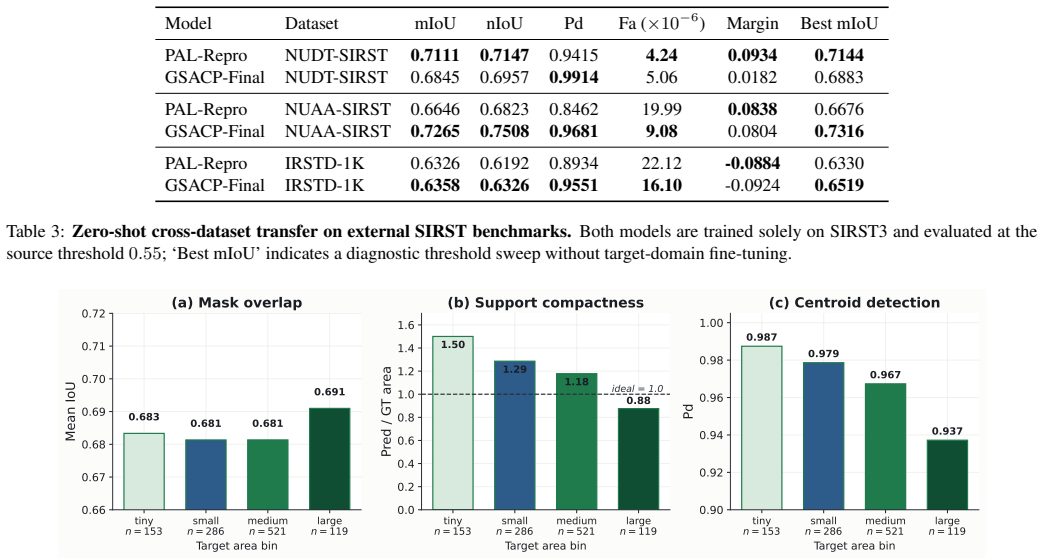
Single-point supervised infrared small target detection (IRSTD) drastically reduces dense annotation costs. Current state-of-the-art (SOTA) methods achieve high precision by recovering mask supervision through explicit, offline pseudo-label construction, such as multi-stage active learning and physics-driven mask generation. In this paper, we study a minimalist alternative: generating point-to-mask supervision online through in-batch, point-anchored feature-affinity propagation. We instantiate this paradigm as GSACP, an end-to-end testbed that directly supervises the detector using hard-margin feature affinity gated by local image priors, entirely eliminating external label-evolution loops. This compact design, however, exposes an optimization bottleneck. Because the affinity target is generated from the same feature representation being optimized, training forms a self-referential loop. We theoretically formalize this as \emph{Self-Referential Propagation Drift}, a representation-supervision entanglement that can sharpen true boundaries or distort the feature space to satisfy its own targets. To systematically isolate these failure modes, we apply a protocolized single-variable ablation procedure spanning local EMA teacher decoupling, hard-background contrastive separation, and adaptive support geometry. On the SIRST3 dataset, GSACP-Final establishes a new ultra-low false-alarm operating regime, achieving a highly competitive $0.6674$ mIoU while demonstrating a $38\% relative reduction in false-positive artifacts ($\mathrm{Fa}$) compared with PAL. By systematically deconstructing the end-to-end paradigm, we map its performance boundaries and show that in-batch feature propagation provides a compact alternative for deployment scenarios where false-alarm suppression is paramount.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes GSACP, an end-to-end testbed for single-point supervised infrared small target detection that generates online point-to-mask supervision via in-batch point-anchored feature-affinity propagation gated by local image priors. It explicitly formalizes the resulting Self-Referential Propagation Drift, applies a protocolized ablation over EMA teacher decoupling, hard-background contrastive separation, and adaptive support geometry to isolate failure modes, and reports on SIRST3 a competitive 0.6674 mIoU together with a 38% relative Fa reduction versus the PAL baseline.
Significance. If the headline metrics prove robust under statistical verification and identical splits, the work supplies a compact, single-stage alternative to multi-stage pseudo-labeling pipelines for IRSTD applications where false-alarm suppression is critical. The explicit drift formalization and ablation protocol constitute a reusable analytical lens for other end-to-end low-supervision regimes.
major comments (3)
- [Abstract] Abstract: the central claim of a 38% relative Fa reduction and 0.6674 mIoU versus PAL is presented without error bars, standard deviations across runs, or an explicit statement that the PAL baseline was re-evaluated on the identical train/test splits and data-augmentation protocol used for GSACP; this omission directly undermines the reliability of the reported operating point.
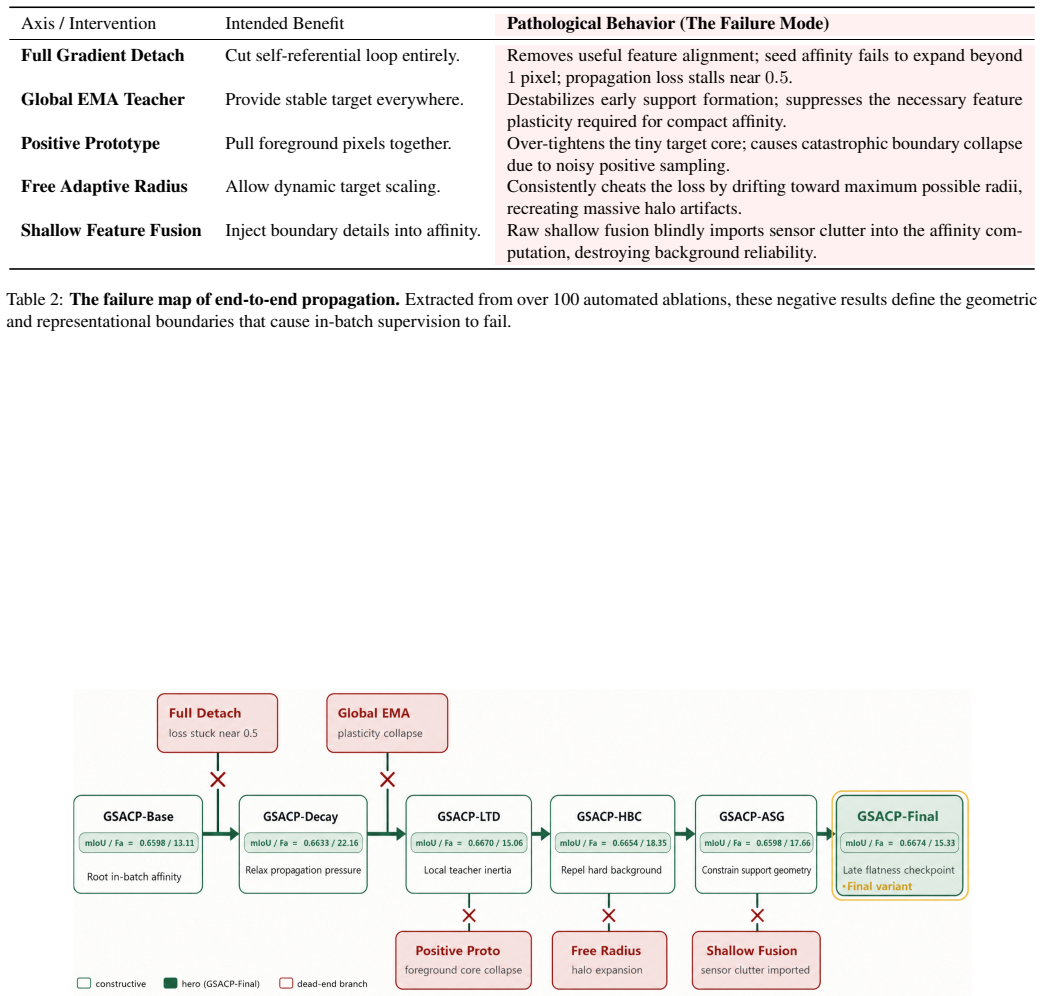
- [Ablation protocol] Ablation protocol (described in the main text): headline metrics are supplied only for the fully regularized GSACP-Final; the manuscript must report the corresponding mIoU and Fa values for each single-variable ablation (EMA-only, contrastive-only, geometry-only) to demonstrate that performance gains arise from drift neutralization rather than from the specific combination of regularizers.
- [Theoretical formalization] Theoretical section on Self-Referential Propagation Drift: while the drift is correctly identified as representation-supervision entanglement, the paper does not quantify how much residual self-reference remains after EMA decoupling (e.g., via a drift metric or feature-space divergence plot), leaving open whether the reported gains on low-contrast SIRST3 scenes are stable or merely an artifact of the chosen regularization strength.
minor comments (2)
- [Abstract] Abstract: the acronym 'GSACP-Final' appears without a preceding definition or expansion; a one-sentence gloss would improve readability.
- [Method] Notation: the symbols for feature affinity and gated propagation should be introduced with a single equation reference early in the method section to avoid repeated inline definitions.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback, which has helped us identify areas where the manuscript can be strengthened. We address each major comment point by point below, indicating the revisions we will incorporate.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of a 38% relative Fa reduction and 0.6674 mIoU versus PAL is presented without error bars, standard deviations across runs, or an explicit statement that the PAL baseline was re-evaluated on the identical train/test splits and data-augmentation protocol used for GSACP; this omission directly undermines the reliability of the reported operating point.
Authors: We agree that an explicit statement on the evaluation protocol and error bars would improve reliability. The PAL baseline was re-evaluated on the identical SIRST3 train/test splits and data-augmentation protocol as GSACP; this is documented in Section 4.1 but was omitted from the abstract for brevity. Our experiments were performed as single runs owing to the high computational cost of end-to-end training. We will revise the abstract to include the explicit protocol statement and add a limitations note in the results section acknowledging the single-run setting. If additional compute becomes available, we will report standard deviations from multiple seeds in the camera-ready version. revision: partial
-
Referee: [Ablation protocol] Ablation protocol (described in the main text): headline metrics are supplied only for the fully regularized GSACP-Final; the manuscript must report the corresponding mIoU and Fa values for each single-variable ablation (EMA-only, contrastive-only, geometry-only) to demonstrate that performance gains arise from drift neutralization rather than from the specific combination of regularizers.
Authors: This observation is correct. The manuscript describes the single-variable ablation protocol but reports quantitative mIoU and Fa only for the final GSACP-Final configuration. To isolate the contribution of each regularizer to drift neutralization, we will add a dedicated ablation table in the revised manuscript that lists mIoU and Fa for EMA-only, contrastive-only, geometry-only, and all pairwise combinations. This will make the incremental gains transparent and directly address the concern. revision: yes
-
Referee: [Theoretical formalization] Theoretical section on Self-Referential Propagation Drift: while the drift is correctly identified as representation-supervision entanglement, the paper does not quantify how much residual self-reference remains after EMA decoupling (e.g., via a drift metric or feature-space divergence plot), leaving open whether the reported gains on low-contrast SIRST3 scenes are stable or merely an artifact of the chosen regularization strength.
Authors: We acknowledge the gap. While the formalization correctly identifies representation-supervision entanglement and the EMA teacher is introduced to mitigate it, no explicit residual-drift metric or divergence plot is provided. The ablation results offer indirect evidence of effectiveness, yet a direct quantification would strengthen the claim. We will incorporate a new figure in the revised theoretical section showing feature-space divergence (cosine distance between student and EMA-teacher features) over training epochs for the decoupled versus non-decoupled models, thereby quantifying residual self-reference on the low-contrast SIRST3 scenes. revision: yes
Circularity Check
Self-referential affinity target generation in GSACP remains load-bearing despite EMA/contrastive ablations
specific steps
-
self definitional
[Abstract]
"Because the affinity target is generated from the same feature representation being optimized, training forms a self-referential loop. We theoretically formalize this as Self-Referential Propagation Drift, a representation-supervision entanglement that can sharpen true boundaries or distort the feature space to satisfy its own targets."
The point-to-mask supervision is produced by in-batch feature-affinity propagation on the detector's own features; the training objective therefore minimizes a distance to a target that is a direct function of the parameters being updated. This is circular by construction even after the listed regularizers, because the target generation equation remains a function of the current feature map.
full rationale
The paper explicitly identifies that the affinity supervision target is produced from the identical feature map being optimized, creating a self-referential loop formalized as Self-Referential Propagation Drift. While the authors introduce EMA teacher decoupling, hard-background contrastive separation, and adaptive support geometry as mitigations and report the headline 0.6674 mIoU only for the fully regularized GSACP-Final, the core supervision mechanism is still defined in terms of the model's own evolving representations. This matches the self-definitional pattern: the loss is constructed to match quantities derived from the same network outputs it trains. The empirical performance numbers are therefore not independent of the loop they attempt to regularize. No other circular steps (e.g., self-citation load-bearing or imported uniqueness theorems) are present in the provided text.
Axiom & Free-Parameter Ledger
invented entities (1)
-
Self-Referential Propagation Drift
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Learning pixel-level semantic affinity with image-level supervision for weakly supervised semantic segmentation
Jiwoon Ahn and Suha Kwak. Learning pixel-level semantic affinity with image-level supervision for weakly supervised semantic segmentation. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018
2018
-
[2]
Anonymous. Confidence-weighted boundary-aware learning for semi-supervised se- mantic segmentation.arXiv preprint arXiv:2502.15152, 2025
-
[3]
Weihua Gao, Wenlong Niu, Jie Tang, Man Yang, Jiafeng Zhang, and Xiaodong Peng. Point-to-mask: From arbitrary point annotations to mask-level infrared small target detection.arXiv preprint arXiv:2603.16257, 2026
-
[4]
Weakly-supervised semantic segmentation network with deep seeded region growing
Zilong Huang, Xinggang Wang, Jiasi Wang, Wenyu Liu, and Jingdong Wang. Weakly-supervised semantic segmentation network with deep seeded region growing. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018
2018
-
[5]
Semi-supervised semantic segmentation with error localization network
Donghyeon Kwon and Suha Kwak. Semi-supervised semantic segmentation with error localization network. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022
2022
-
[6]
Monte carlo linear clustering with single-point supervi- sion is enough for infrared small target detection
Boyang Li, Yingqian Wang, Longguang Wang, Fei Zhang, Ting Liu, Zaiping Lin, Wei An, and Yulan Guo. Monte carlo linear clustering with single-point supervi- sion is enough for infrared small target detection. InProceedings of the IEEE/CVF International Conference on Computer Vision, 2023
2023
-
[7]
Label-efficient segmentation via affinity propagation
Weide Li, Tianwei Yuan, Xiaoxiao Liu, Yuxin Liu, and Xihui Liu. Label-efficient segmentation via affinity propagation. InAdvances in Neural Information Processing Systems, 2023
2023
-
[8]
When confidence fails: Revisiting pseudo-label selection in semi- supervised semantic segmentation
Zhen Liu et al. When confidence fails: Revisiting pseudo-label selection in semi- supervised semantic segmentation. InProceedings of the IEEE/CVF International Conference on Computer Vision, 2025
2025
-
[9]
Rixiang Ni, Boyang Li, Jun Chen, Yonghao Li, Feiyu Ren, Yuji Wang, Haoyang Yuan, Wujiao He, and Wei An. Rethinking irstd: Single-point supervision guided encoder-only framework is enough for infrared small target detection.arXiv preprint arXiv:2604.05363, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[10]
Semi-supervised semantic segmentation using unreliable pseudo-labels
Yuchao Wang, Haochen Wang, Yujun Shen, Jingjing Fei, Wei Li, Guoqiang Jin, Li- wei Wu, Rui Zhao, and Xinyi Le. Semi-supervised semantic segmentation using unreliable pseudo-labels. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022
2022
-
[11]
Mapping degeneration meets label evolution: Learning infrared small target detection with single point supervision
Xinyi Ying, Li Liu, Yingqian Wang, Ruojing Li, Nuo Chen, Zaiping Lin, Weidong Sheng, and Shilin Zhou. Mapping degeneration meets label evolution: Learning infrared small target detection with single point supervision. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023
2023
-
[12]
Chuang Yu, Yunpeng Wang, Jin Wang, and Li Liu. From easy to hard: Progressive active learning framework for infrared small target detection with single point su- pervision. InProceedings of the IEEE/CVF International Conference on Computer Vision, 2025. 9 Model Dataset mIoU nIoU Pd Fa (×10 −6) Margin Best mIoU PAL-Repro NUDT-SIRST0.7111 0.71470.94154.24 0...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.