Recognition: unknown
Decentralized Proximal Stochastic Gradient Langevin Dynamics
Pith reviewed 2026-05-09 18:18 UTC · model grok-4.3
The pith
DE-PSGLD converges in 2-Wasserstein distance to a regularized Gibbs distribution for decentralized constrained sampling.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
DE-PSGLD performs stochastic gradient Langevin dynamics in a decentralized setting with Moreau-Yosida proximal regularization to handle convex constraints. The method is proved to converge non-asymptotically in 2-Wasserstein distance to the regularized Gibbs distribution for both single-agent paths and network averages, with an explicit bound on the proximal bias. Experiments on synthetic and real datasets confirm rapid posterior concentration together with high predictive accuracy.
What carries the argument
Moreau-Yosida proximal regularization that approximates the constrained posterior and permits unconstrained decentralized Langevin updates while preserving sampling consistency.
Load-bearing premise
The target distribution is log-concave on a convex domain and the Moreau-Yosida proximal map consistently approximates the constrained posterior without invalidating the convergence guarantees.
What would settle it
A concrete log-concave test distribution on a convex polytope where the empirical 2-Wasserstein distance of DE-PSGLD samples to the regularized target exceeds the derived non-asymptotic bound for sufficiently large iteration counts.
Figures



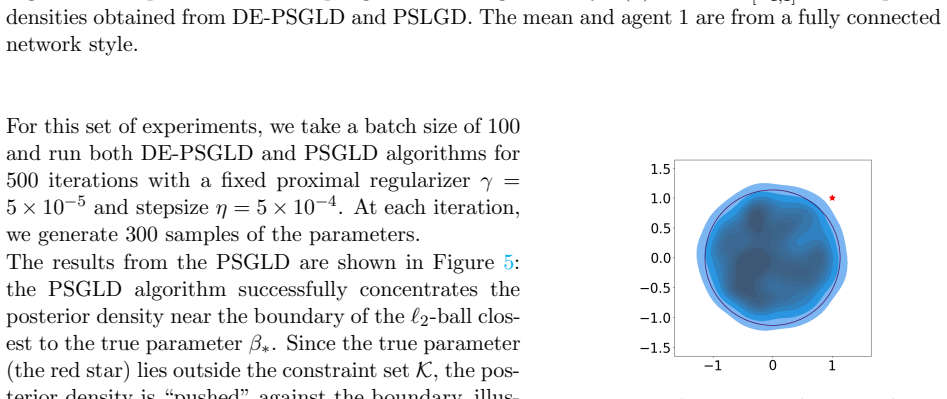



read the original abstract
We propose Decentralized Proximal Stochastic Gradient Langevin Dynamics (DE-PSGLD), a decentralized Markov chain Monte Carlo (MCMC) algorithm for sampling from a log-concave probability distribution constrained to a convex domain. Constraints are enforced through a shared proximal regularization based on the Moreau-Yosida envelope, enabling unconstrained updates while preserving consistency with the target constrained posterior. We establish non-asymptotic convergence guarantees in the 2-Wasserstein distance for both individual agent iterates and their network averages. Our analysis shows that DE-PSGLD converges to a regularized Gibbs distribution and quantifies the bias introduced by the proximal approximation. We evaluate DE-PSGLD for different sampling problems on synthetic and real datasets. As the first decentralized approach for constrained domains, our algorithm exhibits fast posterior concentration and high predictive accuracy.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Decentralized Proximal Stochastic Gradient Langevin Dynamics (DE-PSGLD), a decentralized MCMC method for sampling log-concave distributions constrained to convex domains. Constraints are handled via shared Moreau-Yosida proximal regularization, allowing unconstrained updates. The main results are non-asymptotic 2-Wasserstein convergence bounds for both individual agent iterates and network averages to a regularized Gibbs measure, together with a quantification of the proximal bias; the method is evaluated on synthetic and real datasets for posterior concentration and predictive accuracy.
Significance. If the stated non-asymptotic bounds and bias quantification hold, the contribution is significant: it supplies the first decentralized algorithm for constrained-domain sampling together with explicit rates that incorporate decentralization, stochastic gradients, and proximal regularization. The explicit bias term and the empirical demonstration of fast concentration provide a concrete foundation for distributed Bayesian inference under constraints.
major comments (2)
- [Convergence analysis / main theorem] The non-asymptotic W2 bound (main convergence theorem) is derived under a fixed Moreau-Yosida parameter λ. Recovering the original constrained posterior requires λ → 0, yet no joint schedule relating λ, step-size h, and iteration count T is supplied that simultaneously drives bias (O(λ)), discretization error, and consensus error to zero while preserving the claimed rate. This gap directly affects the consistency claim with the target posterior.
- [Bias analysis section] The bias quantification between the regularized Gibbs measure and the original constrained posterior is stated, but the dependence of the overall error bound on λ (including how proximal error interacts with the decentralized stochastic-gradient terms) is not made explicit enough to verify that the total error remains controlled under any vanishing-λ regime.
minor comments (2)
- [Experiments] The experimental section would benefit from explicit reporting of the λ values used, sensitivity plots with respect to λ, and a clear statement of how λ is chosen relative to the step-size in the reported runs.
- [Preliminaries] Notation for the communication graph, mixing matrix, and proximal operator should be introduced once and used uniformly; a short table of symbols would improve readability.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive comments on our manuscript. We address the major comments point by point below and will incorporate revisions to improve clarity on the analysis.
read point-by-point responses
-
Referee: The non-asymptotic W2 bound (main convergence theorem) is derived under a fixed Moreau-Yosida parameter λ. Recovering the original constrained posterior requires λ → 0, yet no joint schedule relating λ, step-size h, and iteration count T is supplied that simultaneously drives bias (O(λ)), discretization error, and consensus error to zero while preserving the claimed rate. This gap directly affects the consistency claim with the target posterior.
Authors: Our main theorem provides explicit non-asymptotic 2-Wasserstein bounds to the regularized Gibbs measure for any fixed λ > 0, incorporating decentralization, stochastic gradients, and proximal regularization. The proximal bias to the original constrained posterior is quantified separately as O(λ). We acknowledge that an explicit joint schedule for λ, h, and T is not derived in the current analysis, as this would require a refined time-varying regularization argument beyond the fixed-λ focus of the work. The existing bounds nevertheless permit balancing errors by selecting sufficiently small fixed λ. We will add a discussion remark providing guidance on parameter regimes (e.g., λ = o(1) relative to discretization and consensus terms) to support consistency in the limit λ → 0 after mixing, and will clarify the consistency claim accordingly. revision: partial
-
Referee: The bias quantification between the regularized Gibbs measure and the original constrained posterior is stated, but the dependence of the overall error bound on λ (including how proximal error interacts with the decentralized stochastic-gradient terms) is not made explicit enough to verify that the total error remains controlled under any vanishing-λ regime.
Authors: We agree that the interaction of the proximal bias with the decentralized stochastic-gradient and consensus terms could be stated more explicitly. In the revised manuscript we will expand the bias analysis section to combine the O(λ) bias term directly with the main convergence bound, yielding an overall error expression that makes the dependence on λ transparent and confirms control under vanishing-λ regimes when λ is chosen appropriately relative to h and T. revision: yes
Circularity Check
No circularity: standard analysis applied to proximal decentralized setting
full rationale
The paper derives non-asymptotic 2-Wasserstein convergence of DE-PSGLD iterates and network averages to the regularized Gibbs measure induced by the Moreau-Yosida envelope of the constrained log-concave potential. This target is exactly the stationary distribution of the algorithm by construction, and the bias to the original constrained posterior is quantified separately as an approximation error. No step reduces a claimed prediction or uniqueness result to a fitted parameter, self-citation chain, or definitional tautology. The analysis combines standard SGLD discretization bounds, proximal regularization properties, and decentralized consensus arguments without importing load-bearing results from the authors' prior work or smuggling ansatzes. The derivation remains self-contained against external benchmarks for log-concave sampling.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Target distribution is log-concave
- domain assumption Constraint set is convex
Reference graph
Works this paper leans on
-
[1]
SIAM Journal on Optimization , volume=
On the convergence of decentralized gradient descent , author=. SIAM Journal on Optimization , volume=. 2016 , publisher=
2016
-
[2]
Accelerating
Yao, Nian and Ali, Pervez and Tao, Xihua and Zhu, Lingjiong , journal=. Accelerating
-
[3]
Generalized
Gurbuzbalaban, Mert and Islam, Mohammad Rafiqul and Wang, Xiaoyu and Zhu, Lingjiong , journal=. Generalized
-
[4]
Advances in Neural Information Processing Systems , volume=
Can decentralized algorithms outperform centralized algorithms? a case study for decentralized parallel stochastic gradient descent , author=. Advances in Neural Information Processing Systems , volume=
-
[5]
SIAM Journal on Optimization , volume=
Extra: An exact first-order algorithm for decentralized consensus optimization , author=. SIAM Journal on Optimization , volume=. 2015 , publisher=
2015
-
[6]
Arjevani, Yossi and Bruna, Joan and Can, Bugra and Gurbuzbalaban, Mert and Jegelka, Stefanie and Lin, Hongzhou , booktitle=
-
[7]
Scikit-learn: Machine learning in
Pedregosa, Fabian and Varoquaux, Ga. Scikit-learn: Machine learning in. Journal of Machine Learning Research , volume=. 2011 , publisher=
2011
-
[8]
Street.Breast Cancer Wisconsin (Diagnostic)
Wolberg, William and Mangasarian, Olvi and Street, Nick and Street, W. , year =. Breast Cancer. doi:10.24432/C5DW2B , note =
-
[9]
Statistical aspects of
Panaretos, Victor M and Zemel, Yoav , journal=. Statistical aspects of. 2019 , publisher=
2019
-
[10]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Stochastic image denoising by sampling from the posterior distribution , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[11]
2005 , publisher=
Gaussian Markov Random Fields: Theory and Applications , author=. 2005 , publisher=
2005
-
[12]
Score-Based Generative Modeling through Stochastic Differential Equations
Score-based generative modeling through stochastic differential equations , author=. arXiv preprint arXiv:2011.13456 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[13]
User-friendly guarantees for the
Dalalyan, Arnak S and Karagulyan, Avetik , journal=. User-friendly guarantees for the. 2019 , publisher=
2019
-
[14]
Penalized overdamped and underdamped
Gurbuzbalaban, Mert and Hu, Yuanhan and Zhu, Lingjiong , journal=. Penalized overdamped and underdamped
-
[15]
Sampling from a log-concave distribution with compact support with proximal
Brosse, Nicolas and Durmus, Alain and Moulines,. Sampling from a log-concave distribution with compact support with proximal. Conference on Learning Theory , pages=. 2017 , volume=
2017
-
[16]
1998 , publisher=
Variational Analysis , author=. 1998 , publisher=
1998
-
[17]
Advances in Neural Information Processing Systems , volume=
Decentralized accelerated proximal gradient descent , author=. Advances in Neural Information Processing Systems , volume=
-
[18]
Foundations and trends
Proximal algorithms , author=. Foundations and trends. 2014 , publisher=
2014
-
[19]
Non-convex learning via Stochastic Gradient
Raginsky, Maxim and Rakhlin, Alexander and Telgarsky, Matus , booktitle=. Non-convex learning via Stochastic Gradient
-
[20]
Systems & Control Letters , volume=
Fast linear iterations for distributed averaging , author=. Systems & Control Letters , volume=. 2004 , publisher=
2004
-
[21]
Introductory Lectures on Convex Optimization: A Basic Course , pages=
Structural Optimization , author=. Introductory Lectures on Convex Optimization: A Basic Course , pages=. 2004 , publisher=
2004
-
[22]
Bayesian learning via stochastic gradient
Welling, Max and Teh, Yee W , booktitle=. Bayesian learning via stochastic gradient. 2011 , organization=
2011
-
[23]
Finite-time analysis of projected
Bubeck, Sebastien and Eldan, Ronen and Lehec, Joseph , booktitle=. Finite-time analysis of projected
-
[24]
Decentralized stochastic gradient
G. Decentralized stochastic gradient. Journal of Machine Learning Research , volume=
-
[25]
Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=
Theoretical guarantees for approximate sampling from smooth and log-concave densities , author=. Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=. 2017 , publisher=
2017
-
[26]
High-dimensional
Durmus, Alain and Moulines, Eric , year=. High-dimensional. Bernoulli , volume=
-
[27]
Nonasymptotic convergence analysis for the unadjusted
Durmus, Alain and Moulines, Eric , journal=. Nonasymptotic convergence analysis for the unadjusted
-
[28]
2014 , publisher=
Stochastic Processes and Applications: Diffusion Processes, the Fokker-Planck and Langevin Equations , author=. 2014 , publisher=
2014
-
[29]
1997 , publisher=
Spectral Graph Theory , author=. 1997 , publisher=
1997
-
[30]
Proceedings of the IEEE , volume=
Consensus and cooperation in networked multi-agent systems , author=. Proceedings of the IEEE , volume=. 2007 , publisher=
2007
-
[31]
2008 , publisher=
Optimal Transport: Old and New , author=. 2008 , publisher=
2008
-
[32]
Proceedings of COMPSTAT'2010: 19th International Conference on Computational Statistics, Paris France, August 22-27, 2010 Keynote, Invited and Contributed Papers , pages=
Large-scale machine learning with stochastic gradient descent , author=. Proceedings of COMPSTAT'2010: 19th International Conference on Computational Statistics, Paris France, August 22-27, 2010 Keynote, Invited and Contributed Papers , pages=. 2010 , organization=
2010
-
[33]
2011 , publisher=
Convex Analysis and Monotone Operator Theory in Hilbert Spaces , author=. 2011 , publisher=
2011
-
[34]
Weighted
Bolley, Fran. Weighted. Annales-Facult\'e des sciences Toulouse Mathematiques , Number =
-
[35]
2024 , volume=
Zheng, Haoyang and Du, Hengrong and Feng, Qi and Deng, Wei and Lin, Guang , title =. 2024 , volume=
2024
-
[36]
Accelerated constrained sampling: A large deviations approach , Year =
Wang, Yingli and Tu, Changwei and Wang, Xiaoyu and Zhu, Lingjiong , Journal =. Accelerated constrained sampling: A large deviations approach , Year =
-
[37]
Non-reversible
Du, Hengrong and Feng, Qi and Tu, Changwei and Wang, Xiaoyu and Zhu, Lingjiong , journal=. Non-reversible
-
[38]
Accelerating
Hwang, Chii-Ruey and Hwang-Ma, Shu-Yin and Sheu, Shuenn-Jyi , Journal =. Accelerating
-
[39]
Accelerating diffusions , Volume =
Hwang, Chii-Ruey and Hwang-Ma, Shu-Yin and Sheu, Shuenn-Jyi , Journal =. Accelerating diffusions , Volume =
-
[40]
Accelerating the diffusion-based ensemble sampling by non-reversible dynamics , volume=
Futami, Futoshi and Sato, Iseei and Sugiyama, Masashi , Booktitle =. Accelerating the diffusion-based ensemble sampling by non-reversible dynamics , volume=
-
[41]
Advances in Neural Information Processing Systems (NeurIPS) , Title =
Gao, Xuefeng and G\". Advances in Neural Information Processing Systems (NeurIPS) , Title =
-
[42]
Hu, Yuanhan and Wang, Xiaoyu and Gao, Xuefeng and G\". arXiv:2004.02823 , Title =
-
[43]
Sampling from a log-concave distribution with projected
Bubeck, S. Sampling from a log-concave distribution with projected. Discrete & Computational Geometry , volume=. 2018 , publisher=
2018
-
[44]
Mirrored
Hsieh, Ya-Ping and Kavis, Ali and Rolland, Paul and Cevher, Volkan , booktitle=. Mirrored
-
[45]
Exponential ergodicity of mirror-
Chewi, Sinho and Le Gouic, Thibaut and Lu, Cheng and Maunu, Tyler and Rigollet, Philippe and Stromme, Austin , Booktitle =. Exponential ergodicity of mirror-
-
[46]
Conference on Learning Theory , Title =
Zhang, Kelvin Shuangjian and Peyr\'. Conference on Learning Theory , Title =
-
[47]
Efficient constrained sampling via the mirror-
Ahn, Kwangjun and Chewi, Sinho , Booktitle =. Efficient constrained sampling via the mirror-
-
[48]
Constrained
Zheng, Yuping and Lamperski, Andrew , booktitle=. Constrained
-
[49]
Primal dual interpretation of the proximal stochastic gradient
Salim, Adil and Richt\'. Primal dual interpretation of the proximal stochastic gradient. Advances in Neural Information Processing Systems (NeurIPS) , volume=
-
[50]
and Wibisono, Andre , booktitle =
Li, Ruilin and Tao, Molei and Vempala, Santosh S. and Wibisono, Andre , booktitle =. The mirror
-
[51]
Projected stochastic gradient
Lamperski, Andrew , booktitle =. Projected stochastic gradient. 2021 , organization =
2021
-
[52]
He, Lie and Bian, An and Jaggi, Martin , booktitle=
-
[53]
Advances in Neural Information Processing Systems , pages=
An accelerated decentralized stochastic proximal algorithm for finite sums , author=. Advances in Neural Information Processing Systems , pages=
-
[54]
A First Course in Bayesian Statistical Methods , Volume =
Hoff, Peter D , Publisher =. A First Course in Bayesian Statistical Methods , Volume =
-
[55]
A survey on
Wang, Hao and Yeung, Dit-Yan , Journal =. A survey on
-
[56]
and Sokolov, Vadim , Journal =
Polson, Nicholas G. and Sokolov, Vadim , Journal =. Deep Learning: A
-
[57]
Variance reduction in stochastic gradient
Dubey, Kumar Avinava and Reddi, Sashank J and Williamson, Sinead A and Poczos, Barnabas and Smola, Alexander J and Xing, Eric P , Booktitle =. Variance reduction in stochastic gradient
-
[58]
and Gurbuzbalaban, Mert and Kutbay, Mustafa Ali and Zhu, Lingjiong and Zulqarnain, Muhammad , journal=
Bajwa, Waheed U. and Gurbuzbalaban, Mert and Kutbay, Mustafa Ali and Zhu, Lingjiong and Zulqarnain, Muhammad , journal=
-
[59]
The Annals of Mathematical Statistics , volume=
On information and sufficiency , author=. The Annals of Mathematical Statistics , volume=. 1951 , publisher=
1951
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.