Recognition: unknown
Empowering Heterogeneous Graph Foundation Models via Decoupled Relation Alignment
Pith reviewed 2026-05-09 14:28 UTC · model grok-4.3
The pith
Decoupled relation subspace alignment separates feature semantics from structures to fix type collapse and relation confusion in heterogeneous graph foundation models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
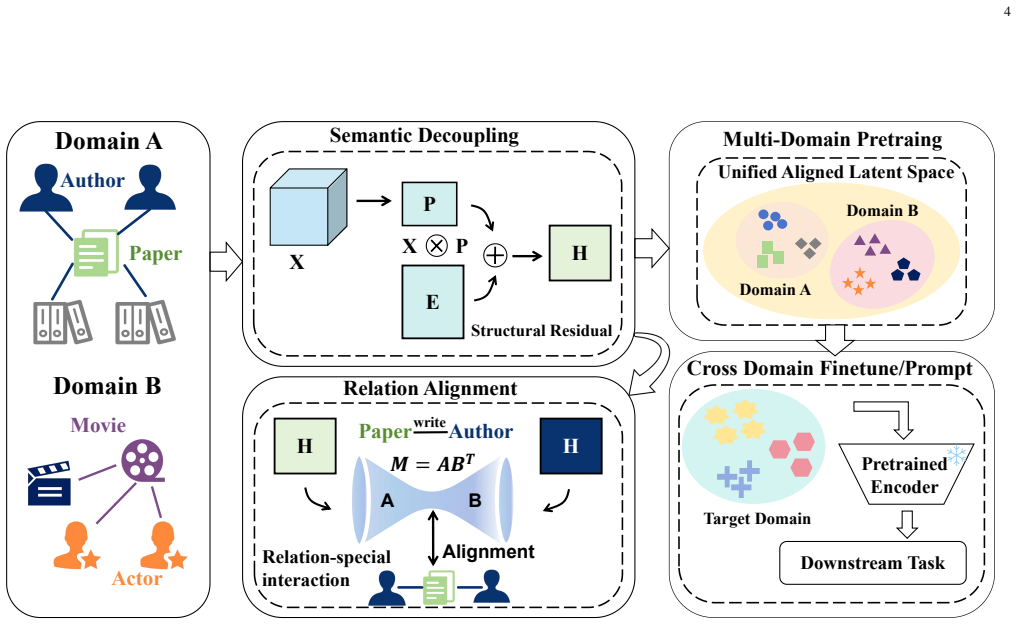
DRSA fundamentally shifts the paradigm by decoupling feature semantics from relation structures. It introduces a dual-relation subspace projection mechanism to coordinate cross-type interactions within a shared low-rank relation subspace explicitly. Furthermore, a feature-structure decoupled representation is designed to decompose aligned features into a semantic projection component and a structural residual term, adaptively absorbing intra-domain variations. Optimized via a stable alternating minimization strategy based on Block Coordinate Descent, DRSA constructs a well-calibrated, structure-aware latent space.
What carries the argument
Dual-relation subspace projection combined with feature-structure decoupled representation, which projects cross-type interactions into a shared low-rank subspace while separating semantic projections from structural residuals.
If this is right
- DRSA can be added as a universal preprocessing step to any state-of-the-art graph foundation model without changing its architecture.
- The resulting latent space supports stronger cross-domain knowledge transfer across different heterogeneous graph domains.
- Few-shot adaptation performance improves because intra-domain relation gaps are explicitly absorbed by the residual term.
- Original topologies remain intact because alignment occurs only inside the low-rank relation subspace rather than in the full feature space.
- Alternating minimization based on block coordinate descent yields stable optimization of the decoupled components.
Where Pith is reading between the lines
- The same decoupling pattern could be tested on knowledge graphs with many relation types to see whether it reduces the need for relation-specific encoders.
- If the residual term successfully captures variations, removing it should cause measurable drops in within-domain accuracy while preserving cross-domain gains.
- The low-rank subspace size becomes a tunable knob that trades off alignment strength against preservation of type-specific detail.
- Downstream tasks that rely on precise local neighborhoods may benefit more than global property prediction because topology is less distorted.
Load-bearing premise
Enforcing alignment by subspace projection and additive residuals will preserve necessary type semantics and intra-domain structures without creating new distortions in multi-domain heterogeneous graphs.
What would settle it
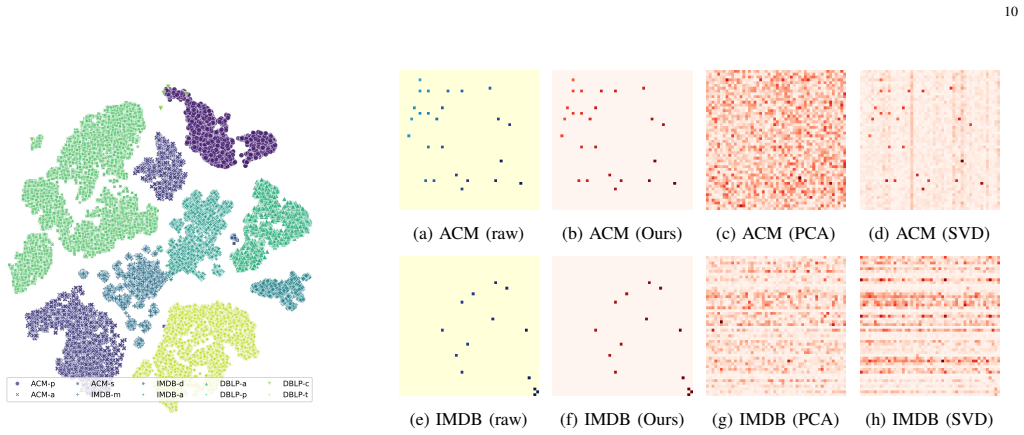
On a held-out multi-domain heterogeneous graph benchmark, a GFM preprocessed with DRSA shows no improvement in cross-domain few-shot accuracy over the same model without DRSA or over models using global PCA/SVD alignment.
Figures


read the original abstract
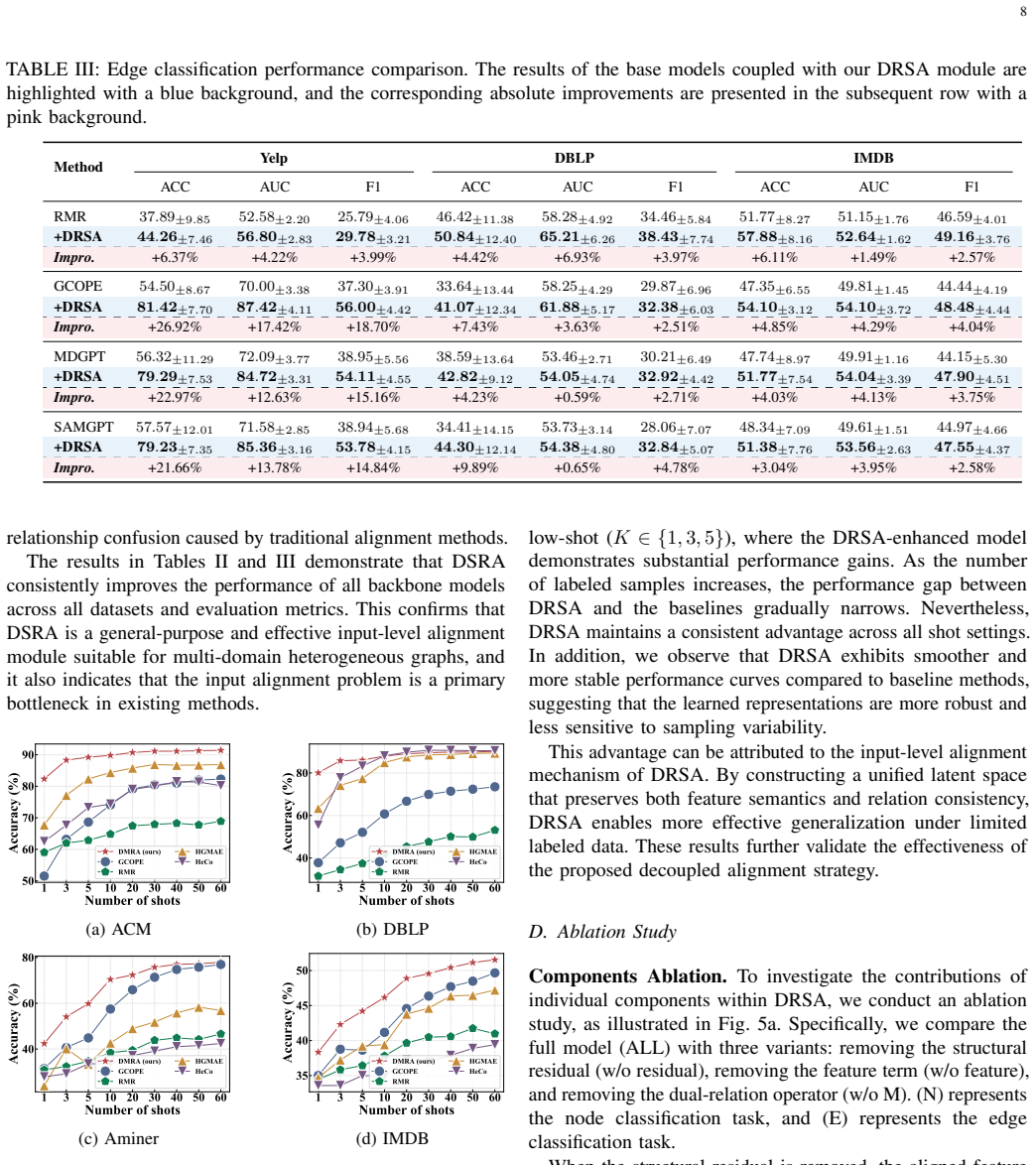
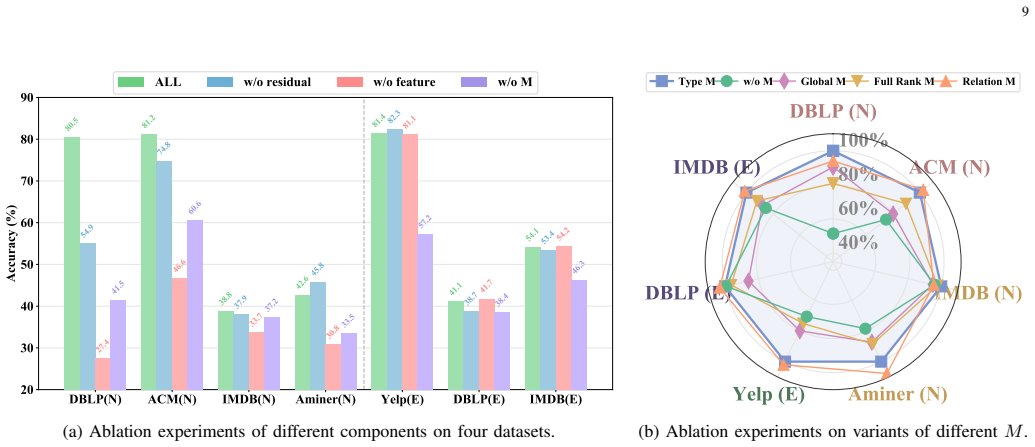
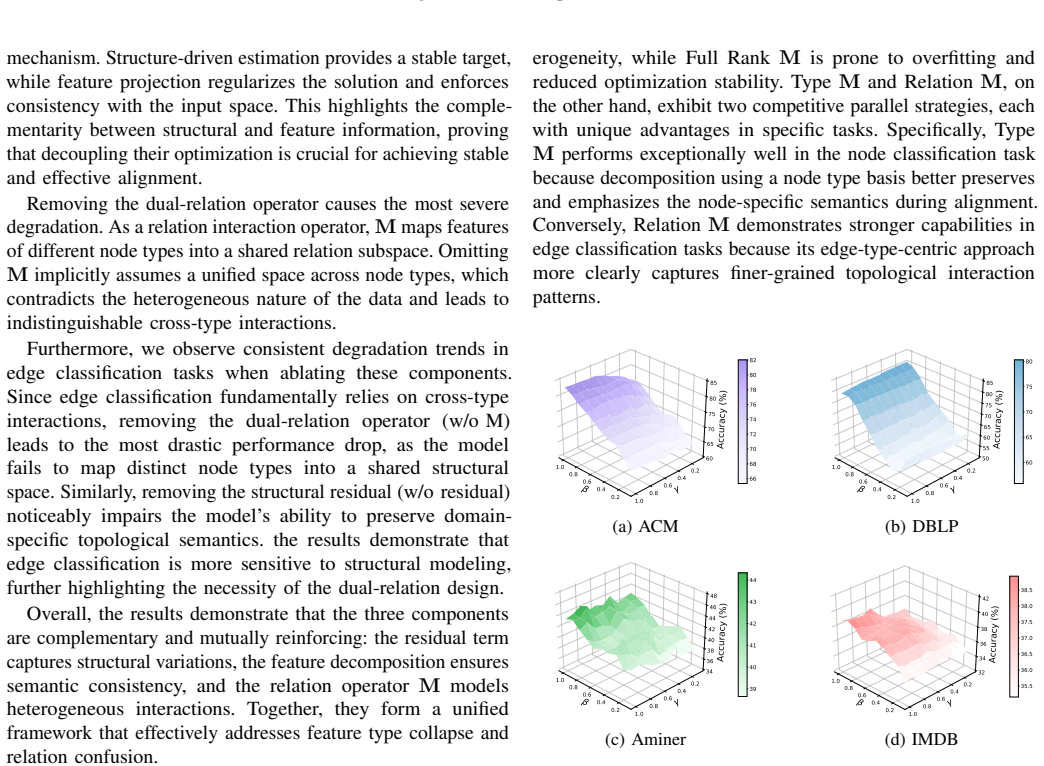
While Graph Foundation Models (GFMs) have achieved remarkable success in homogeneous graphs, extending them to multi-domain heterogeneous graphs (MDHGs) remains a formidable challenge due to cross-type feature shifts and intra-domain relation gaps. Existing global feature alignment methods (PCA or SVD) enforce a shared feature space blindly, which distorts type-specific semantics and disrupts original topologies, inevitably leading to "Type Collapse" and "Relation Confusion". To address these fundamental limitations, we propose Decoupled relation Subspace Alignment (DRSA), a novel, plug-and-play relation-driven alignment framework. DRSA fundamentally shifts the paradigm by decoupling feature semantics from relation structures. Specifically, it introduces a dual-relation subspace projection mechanism to coordinate cross-type interactions within a shared low-rank relation subspace explicitly. Furthermore, a feature-structure decoupled representation is designed to decompose aligned features into a semantic projection component and a structural residual term, adaptively absorbing intra-domain variations. Optimized via a stable alternating minimization strategy based on Block Coordinate Descent, DRSA constructs a well-calibrated, structure-aware latent space. Extensive experiments on multiple real-world benchmark datasets demonstrate that DRSA can be seamlessly integrated as a universal preprocessing module, significantly and consistently enhancing the cross-domain and few-shot knowledge transfer capabilities of state-of-the-art GFMs. The code is available at: https://github.com/zhengziyu77/DSRA.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Decoupled Relation Subspace Alignment (DRSA), a plug-and-play preprocessing framework for multi-domain heterogeneous graphs (MDHGs) to empower Graph Foundation Models (GFMs). It claims that existing global alignment methods like PCA/SVD cause 'Type Collapse' and 'Relation Confusion' by distorting type-specific semantics and topologies. DRSA addresses this by decoupling feature semantics from relation structures through a dual-relation subspace projection mechanism that coordinates cross-type interactions in a shared low-rank relation subspace, combined with a feature-structure decomposition (semantic projection plus structural residual) to absorb intra-domain variations. The method is optimized via block coordinate descent (BCD) alternating minimization and is shown to improve cross-domain and few-shot transfer when integrated with existing GFMs on benchmark datasets.
Significance. If the decoupling is rigorously achieved without reintroducing distortions, DRSA would represent a meaningful advance over global alignment baselines by preserving type-specific information while enabling structure-aware latent spaces. This could make it a standard preprocessing step for heterogeneous GFMs, particularly in multi-domain settings where current methods fail to transfer knowledge effectively. The plug-and-play design and code release are positive for reproducibility.
major comments (2)
- [Optimization and BCD strategy] The central claim of clean decoupling relies on the BCD procedure separating the dual-relation subspace projection from the structural residual term. The manuscript must explicitly show (via the objective function and update rules) that no shared term (e.g., a joint Frobenius norm) causes the residual to couple back into the low-rank subspace parameters after each block update; otherwise the claimed separation from global PCA/SVD is not guaranteed.
- [Dual-relation subspace projection mechanism] The dual-relation subspace projection is described as coordinating cross-type interactions in a shared low-rank space, but the manuscript should provide the precise projection operator and orthogonality constraints (likely in the method equations) to demonstrate it does not collapse type-specific semantics, with a concrete comparison to standard SVD/PCA on the same MDHG inputs.
minor comments (2)
- [Abstract] The GitHub link in the abstract points to DSRA while the method is abbreviated DRSA; standardize the acronym throughout.
- [Experiments] The abstract claims 'extensive experiments' but the manuscript should include a table summarizing dataset statistics, baseline GFMs, and quantitative gains (e.g., accuracy/F1 deltas) to support the 'significantly and consistently enhancing' statement.
Simulated Author's Rebuttal
We sincerely thank the referee for the thorough and constructive review. The comments raise important points about the rigor of our optimization analysis and the explicit formulation of the projection mechanism. We address each major comment below and will revise the manuscript to incorporate the requested clarifications and derivations.
read point-by-point responses
-
Referee: [Optimization and BCD strategy] The central claim of clean decoupling relies on the BCD procedure separating the dual-relation subspace projection from the structural residual term. The manuscript must explicitly show (via the objective function and update rules) that no shared term (e.g., a joint Frobenius norm) causes the residual to couple back into the low-rank subspace parameters after each block update; otherwise the claimed separation from global PCA/SVD is not guaranteed.
Authors: We appreciate this observation, which strengthens the presentation of our method. The current manuscript describes the BCD alternating minimization at a high level but does not include the full expanded objective and per-block update derivations. In the revised version we will explicitly write the joint objective, derive the closed-form or iterative updates for each block, and prove that the subspace projection parameters are updated independently of the structural residual term (no shared Frobenius coupling term appears across blocks). This will formally establish the separation from global PCA/SVD and confirm that type-specific semantics are not re-coupled. revision: yes
-
Referee: [Dual-relation subspace projection mechanism] The dual-relation subspace projection is described as coordinating cross-type interactions in a shared low-rank space, but the manuscript should provide the precise projection operator and orthogonality constraints (likely in the method equations) to demonstrate it does not collapse type-specific semantics, with a concrete comparison to standard SVD/PCA on the same MDHG inputs.
Authors: We agree that the precise operator and constraints must be stated explicitly. In the revision we will add the mathematical definition of the dual-relation subspace projection (including the shared low-rank basis and the orthogonality constraints enforced on it) together with the feature-structure decomposition. We will also insert a direct side-by-side comparison—both algebraic and on the benchmark MDHG inputs—showing how the DRSA operator preserves type-specific semantics while standard SVD/PCA induces collapse. This comparison will be placed in the method section with supporting equations and a small illustrative table. revision: yes
Circularity Check
No significant circularity; derivation is self-contained construction
full rationale
The abstract and described framework present DRSA as an explicit construction: dual-relation subspace projection plus semantic-projection-plus-residual decomposition, optimized by alternating minimization. No equations or steps are shown reducing to fitted parameters renamed as predictions, self-definitions, or load-bearing self-citations. The central claim (decoupling avoids Type Collapse/Relation Confusion) is advanced as a design choice with empirical support, not derived by construction from its own inputs. This matches the default expectation of non-circularity for a methodological paper.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Cross-type feature shifts and intra-domain relation gaps are the primary challenges in MDHGs for GFMs
- domain assumption Global feature alignment methods like PCA or SVD distort type-specific semantics and disrupt topologies
Reference graph
Works this paper leans on
-
[1]
Interpretable and efficient heterogeneous graph convolutional network,
Y . Yang, Z. Guan, J. Li, W. Zhao, J. Cui, and Q. Wang, “Interpretable and efficient heterogeneous graph convolutional network,”TKDE, 2021
2021
-
[2]
Graph neural networks in recommender systems: a survey,
S. Wu, F. Sun, W. Zhang, X. Xie, and B. Cui, “Graph neural networks in recommender systems: a survey,”ACM Computing Surveys, vol. 55, no. 5, pp. 1–37, 2022. 11
2022
-
[3]
Truthsr: Trustworthy sequential recommender systems via user-generated multimodal content,
M. Yan, H. Huang, Y . Liu, J. Zhao, X. Gao, C. Xu, Z. Guan, and W. Zhao, “Truthsr: Trustworthy sequential recommender systems via user-generated multimodal content,” inDatabase Systems for Advanced Applications. Singapore: Springer Nature Singapore, 2025, pp. 180–195
2025
-
[4]
Graph neural networks for materials science and chemistry,
P. Reiser, M. Neubert, A. Eberhard, L. Torresi, C. Zhou, C. Shao, H. Metni, C. van Hoesel, H. Schopmans, T. Sommeret al., “Graph neural networks for materials science and chemistry,”Communications Materials, vol. 3, no. 1, p. 93, 2022
2022
-
[5]
Paaß and S
G. Paaß and S. Giesselbach,Foundation models for natural language processing: Pre-trained language models integrating media. Springer Nature, 2023
2023
-
[6]
Foundation models defining a new era in vision: a survey and outlook,
M. Awais, M. Naseer, S. Khan, R. M. Anwer, H. Cholakkal, M. Shah, M.-H. Yang, and F. S. Khan, “Foundation models defining a new era in vision: a survey and outlook,”IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
2025
-
[7]
Graph foundation models: Concepts, opportunities and challenges,
J. Liu, C. Yang, Z. Lu, J. Chen, Y . Li, M. Zhang, T. Bai, Y . Fang, L. Sun, P. S. Yuet al., “Graph foundation models: Concepts, opportunities and challenges,”IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
2025
-
[8]
Towards graph foundation models: A survey and beyond,
——, “Towards graph foundation models: A survey and beyond,”arXiv preprint arXiv:2310.11829, 2023
-
[9]
Samgpt: Text-free graph foundation model for multi-domain pre-training and cross-domain adaptation,
X. Yu, Z. Gong, C. Zhou, Y . Fang, and H. Zhang, “Samgpt: Text-free graph foundation model for multi-domain pre-training and cross-domain adaptation,” inProceedings of the ACM on Web Conference 2025, 2025, pp. 1142–1153
2025
-
[10]
All in one and one for all: A simple yet effective method towards cross-domain graph pretraining,
H. Zhao, A. Chen, X. Sun, H. Cheng, and J. Li, “All in one and one for all: A simple yet effective method towards cross-domain graph pretraining,” inProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, 2024, pp. 4443–4454
2024
-
[11]
Multi-domain graph foundation models: Robust knowledge transfer via topology alignment,
S. Wang, B. Wang, Z. Shen, B. Deng, and Z. Kang, “Multi-domain graph foundation models: Robust knowledge transfer via topology alignment,” arXiv preprint arXiv:2502.02017, 2025
-
[12]
Graver: Generative graph vocabularies for robust graph foundation models fine-tuning,
H. Yuan, Q. Sun, J. Shi, X. Fu, B. Hooi, J. Li, and P. S. Yu, “Graver: Generative graph vocabularies for robust graph foundation models fine- tuning,”arXiv preprint arXiv:2511.05592, 2025
-
[13]
Overcoming in-memory bot- tlenecks in graph foundation models via retrieval-augmented generation,
H. Yuan, Q. Sun, J. Tao, X. Fu, and J. Li, “Overcoming in-memory bot- tlenecks in graph foundation models via retrieval-augmented generation,” arXiv preprint arXiv:2601.15124, 2026
-
[14]
Domain adversarial neural networks for domain generalization: When it works and how to improve,
A. Sicilia, X. Zhao, and S. J. Hwang, “Domain adversarial neural networks for domain generalization: When it works and how to improve,” Machine Learning, vol. 112, no. 7, pp. 2685–2721, 2023
2023
-
[15]
Graphprompt: Unifying pre- training and downstream tasks for graph neural networks,
Z. Liu, X. Yu, Y . Fang, and X. Zhang, “Graphprompt: Unifying pre- training and downstream tasks for graph neural networks,” inProceedings of the ACM web conference 2023, 2023, pp. 417–428
2023
-
[16]
Beyond single-granularity prompts: A multi-scale chain-of-thought prompt learn- ing for graph,
Z. Zheng, Y . Yang, Z. Guan, W. Zhao, X. Huang, and W. Lu, “Beyond single-granularity prompts: A multi-scale chain-of-thought prompt learn- ing for graph,” inProceedings of the ACM Web Conference 2026, 2026, pp. 547–558
2026
-
[17]
Universal prompt tuning for graph neural networks,
T. Fang, Y . Zhang, Y . Yang, C. Wang, and L. Chen, “Universal prompt tuning for graph neural networks,”Advances in Neural Information Processing Systems, vol. 36, pp. 52 464–52 489, 2023
2023
-
[18]
Self-supervised heterogeneous graph pre-training based on structural clustering,
Y . Yang, Z. Guan, Z. Wang, W. Zhao, C. Xu, W. Lu, and J. Huang, “Self-supervised heterogeneous graph pre-training based on structural clustering,”Advances in Neural Information Processing Systems, vol. 35, pp. 16 962–16 974, 2022
2022
-
[19]
Enhancing homophily- heterophily separation: Relation-aware learning in heterogeneous graphs,
Z. Zheng, Y . Yang, Z. Guan, W. Zhao, and W. Lu, “Enhancing homophily- heterophily separation: Relation-aware learning in heterogeneous graphs,” inProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V .2, 2025, p. 4050–4061
2025
-
[20]
Heterogeneous graph attention network,
X. Wang, H. Ji, C. Shi, B. Wang, Y . Ye, P. Cui, and P. S. Yu, “Heterogeneous graph attention network,” inThe World Wide Web Conference, 2019, pp. 2022–2032
2019
-
[21]
Self-supervised heterogeneous graph neural network with co-contrastive learning,
X. Wang, N. Liu, H. Han, and C. Shi, “Self-supervised heterogeneous graph neural network with co-contrastive learning,” inProceedings of the 27th ACM SIGKDD conference on knowledge discovery & data mining, 2021, pp. 1726–1736
2021
-
[22]
Self-supervised heterogeneous graph learning: a homophily and het- erogeneity view,
Y . Mo, F. Nie, P. Hu, H. T. Shen, Z. Zhang, X. Wang, and X. Zhu, “Self-supervised heterogeneous graph learning: a homophily and het- erogeneity view,” inThe Twelfth International Conference on Learning Representations
-
[23]
Progressive feature alignment for unsupervised domain adaptation,
C. Chen, W. Xie, W. Huang, Y . Rong, X. Ding, Y . Huang, T. Xu, and J. Huang, “Progressive feature alignment for unsupervised domain adaptation,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 627–636
2019
-
[24]
Principal component analysis,
H. Abdi and L. J. Williams, “Principal component analysis,”Wiley interdisciplinary reviews: computational statistics, vol. 2, no. 4, pp. 433–459, 2010
2010
-
[25]
On the early history of the singular value decomposition,
G. W. Stewart, “On the early history of the singular value decomposition,” SIAM review, vol. 35, no. 4, pp. 551–566, 1993
1993
-
[26]
Heteroge- neous graph neural network,
C. Zhang, D. Song, C. Huang, A. Swami, and N. V . Chawla, “Heteroge- neous graph neural network,” inProceedings of the 25th ACM SIGKDD international conference on knowledge discovery & data mining, 2019, pp. 793–803
2019
-
[27]
Heterogeneous graph transformer,
Z. Hu, Y . Dong, K. Wang, and Y . Sun, “Heterogeneous graph transformer,” inProceedings of the web conference 2020, 2020, pp. 2704–2710
2020
-
[28]
Magnn: Metapath aggregated graph neural network for heterogeneous graph embedding,
X. Fu, J. Zhang, Z. Meng, and I. King, “Magnn: Metapath aggregated graph neural network for heterogeneous graph embedding,” inProceed- ings of the web conference 2020, 2020, pp. 2331–2341
2020
-
[29]
Convergence of a block coordinate descent method for nondifferentiable minimization,
P. Tseng, “Convergence of a block coordinate descent method for nondifferentiable minimization,”Journal of optimization theory and applications, vol. 109, no. 3, pp. 475–494, 2001
2001
-
[30]
Unsupervised attributed multiplex network embedding,
C. Park, D. Kim, J. Han, and H. Yu, “Unsupervised attributed multiplex network embedding,” inProceedings of the AAAI conference on artificial intelligence, vol. 34, no. 04, 2020, pp. 5371–5378
2020
-
[31]
Hdmi: High-order deep multiplex infomax,
B. Jing, C. Park, and H. Tong, “Hdmi: High-order deep multiplex infomax,” inProceedings of the Web Conference 2021, 2021, pp. 2414– 2424
2021
-
[32]
Heterogeneous graph masked autoencoders,
Y . Tian, K. Dong, C. Zhang, C. Zhang, and N. V . Chawla, “Heterogeneous graph masked autoencoders,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 37, no. 8, 2023, pp. 9997–10 005
2023
-
[33]
Mug: Meta- path-aware universal heterogeneous graph pre-training,
L. Shan, J. Zhao, D. He, Y . Huang, Z. Feng, and W. Zhang, “Mug: Meta- path-aware universal heterogeneous graph pre-training,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 40, no. 30, 2026, pp. 25 260–25 268
2026
-
[34]
Revisiting self-supervised heterogeneous graph learning from spectral clustering perspective,
Y . Mo, Z. Lu, R. Yu, X. Zhu, and X. Wang, “Revisiting self-supervised heterogeneous graph learning from spectral clustering perspective,” Advances in Neural Information Processing Systems, vol. 37, pp. 43 133– 43 163, 2024
2024
-
[35]
Reserving-masking-reconstruction model for self-supervised heterogeneous graph representation,
H. Duan, C. Xie, and L. Li, “Reserving-masking-reconstruction model for self-supervised heterogeneous graph representation,” inProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, 2024, pp. 689–700
2024
-
[36]
Hetgpt: Harnessing the power of prompt tuning in pre-trained heterogeneous graph neural networks,
Y . Ma, N. Yan, J. Li, M. Mortazavi, and N. V . Chawla, “Hetgpt: Harnessing the power of prompt tuning in pre-trained heterogeneous graph neural networks,” inProceedings of the ACM Web Conference 2024, 2024, pp. 1015–1023
2024
-
[37]
Hgprompt: Bridging homogeneous and heterogeneous graphs for few-shot prompt learning,
X. Yu, Y . Fang, Z. Liu, and X. Zhang, “Hgprompt: Bridging homogeneous and heterogeneous graphs for few-shot prompt learning,” inProceedings of the AAAI conference on artificial intelligence, vol. 38, no. 15, 2024, pp. 16 578–16 586
2024
-
[38]
Edge prompt tuning for graph neural networks,
X. Fu, Y . He, and J. Li, “Edge prompt tuning for graph neural networks,” arXiv preprint arXiv:2503.00750, 2025
-
[39]
Gppt: Graph pre- training and prompt tuning to generalize graph neural networks,
M. Sun, K. Zhou, X. He, Y . Wang, and X. Wang, “Gppt: Graph pre- training and prompt tuning to generalize graph neural networks,” in Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, 2022, pp. 1717–1727
2022
-
[40]
Text-free multi-domain graph pre-training: Toward graph foundation models,
X. Yu, C. Zhou, Y . Fang, and X. Zhang, “Text-free multi-domain graph pre-training: Toward graph foundation models,”arXiv preprint arXiv:2405.13934, 2024
-
[41]
Saˆ 2gfm: Enhancing robust graph foundation models with structure-aware semantic augmentation,
J. Shi, Q. Sun, H. Yuan, and X. Fu, “Saˆ 2gfm: Enhancing robust graph foundation models with structure-aware semantic augmentation,”arXiv preprint arXiv:2512.07857, 2025
-
[42]
How much can transfer? bridge: Bounded multi-domain graph foundation model with generalization guarantees,
H. Yuan, Q. Sun, J. Shi, X. Fu, B. Hooi, J. Li, and P. S. Yu, “How much can transfer? bridge: Bounded multi-domain graph foundation model with generalization guarantees,” inForty-second International Conference on Machine Learning
-
[43]
Random projection in dimensionality reduction: applications to image and text data,
E. Bingham and H. Mannila, “Random projection in dimensionality reduction: applications to image and text data,” inProceedings of the seventh ACM SIGKDD international conference on Knowledge discovery and data mining, 2001, pp. 245–250
2001
-
[44]
Random features for large-scale kernel machines,
A. Rahimi and B. Recht, “Random features for large-scale kernel machines,”Advances in neural information processing systems, vol. 20, 2007
2007
-
[45]
Extensions of lipschitz mappings into a hilbert space,
W. B. Johnson, J. Lindenstrausset al., “Extensions of lipschitz mappings into a hilbert space,”Contemporary mathematics, vol. 26, no. 189-206, p. 1, 1984
1984
-
[46]
Bridging input feature spaces towards graph foundation models,
M. Eliasof, K. S. I. Mantri, B. Bevilacqua, B. Ribeiro, and C.-B. Schönlieb, “Bridging input feature spaces towards graph foundation models,” inThe Fourteenth International Conference on Learning Representations
-
[47]
Network schema preserving heterogeneous information network embedding,
J. Zhao, X. Wang, C. Shi, Z. Liu, and Y . Ye, “Network schema preserving heterogeneous information network embedding,” inInternational joint conference on artificial intelligence (IJCAI), 2020. 12
2020
-
[48]
Rhine: Relation structure-aware heterogeneous information network embedding,
C. Shi, Y . Lu, L. Hu, Z. Liu, and H. Ma, “Rhine: Relation structure-aware heterogeneous information network embedding,”IEEE Transactions on Knowledge and Data Engineering, vol. 34, no. 1, pp. 433–447, 2020
2020
-
[49]
metapath2vec: Scalable representation learning for heterogeneous networks,
Y . Dong, N. V . Chawla, and A. Swami, “metapath2vec: Scalable representation learning for heterogeneous networks,” inSIGKDD. ACM, 2017, pp. 135–144
2017
-
[50]
P. Veli ˇckovi´c, G. Cucurull, A. Casanova, A. Romero, P. Lio, and Y . Bengio, “Graph attention networks,”arXiv preprint arXiv:1710.10903, 2017
work page internal anchor Pith review arXiv 2017
-
[51]
Semi-Supervised Classification with Graph Convolutional Networks
T. N. Kipf and M. Welling, “Semi-supervised classification with graph convolutional networks,”arXiv preprint arXiv:1609.02907, 2016
work page internal anchor Pith review arXiv 2016
-
[52]
arXiv preprint arXiv:1803.00676 , year=
M. Ren, E. Triantafillou, S. Ravi, J. Snell, K. Swersky, J. B. Tenenbaum, H. Larochelle, and R. S. Zemel, “Meta-learning for semi-supervised few-shot classification,”arXiv preprint arXiv:1803.00676, 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.