Recognition: unknown
Make Your LVLM KV Cache More Lightweight
Pith reviewed 2026-05-09 19:01 UTC · model grok-4.3
The pith
Prompt-guided aggregation compresses vision tokens to halve KV cache size in LVLMs while preserving performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
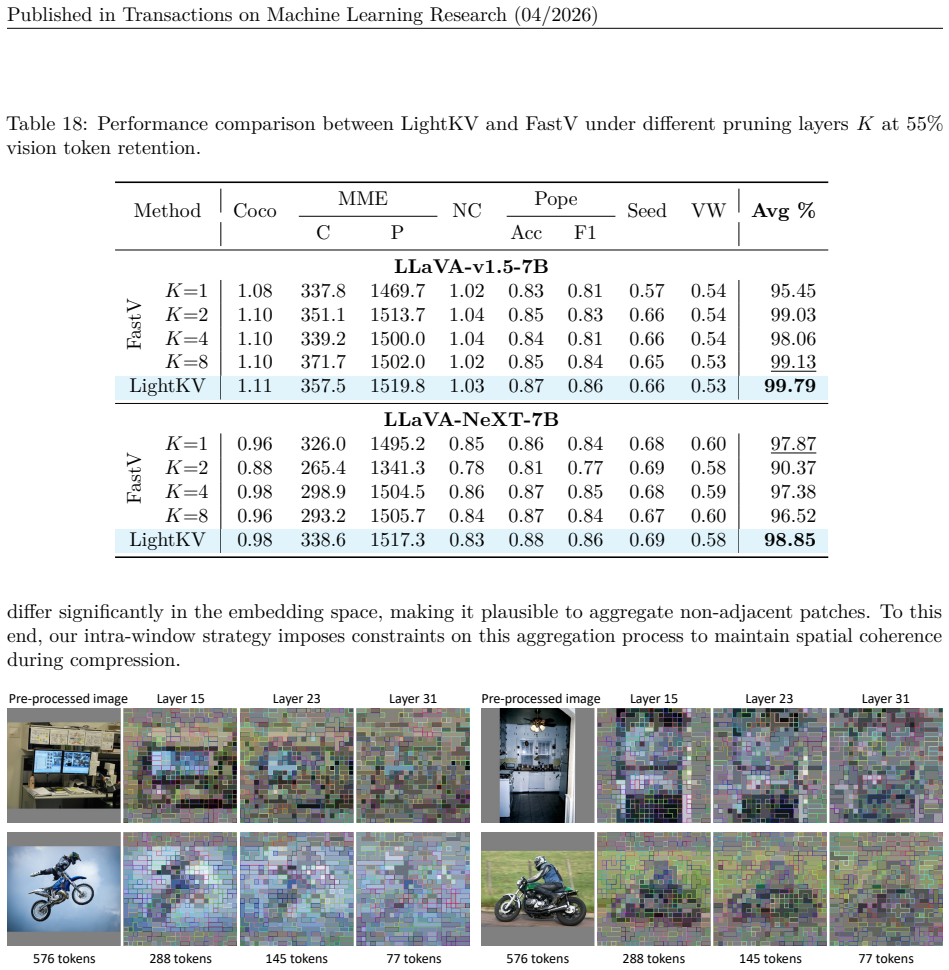
LightKV reduces the KV cache size for vision tokens in Large Vision-Language Models by exploiting redundancy among their embeddings and applying prompt-guided cross-modality message passing to aggregate informative messages, thereby progressively compressing the tokens during prefill; experiments show that retaining only 55 percent of the original vision tokens halves the vision-token KV cache, lowers computation by up to 40 percent, and maintains general-purpose performance while outperforming existing vision-only baselines on datasets such as MME and SeedBench.
What carries the argument
Prompt-guided cross-modality message passing that aggregates informative messages across vision tokens to compress them during prefill.
If this is right
- Vision-token KV cache size is halved while retaining only 55 percent of the original tokens.
- Computation during inference drops by up to 40 percent.
- General-purpose performance on standard benchmarks is preserved and exceeds that of prior vision-only compression methods.
- The prompt-aware guidance distinguishes the approach from methods that compress vision tokens without text input.
- Results hold across eight open-source LVLMs evaluated on eight public datasets.
Where Pith is reading between the lines
- The same prompt-guided aggregation could reduce memory pressure when deploying LVLMs on edge devices with limited RAM.
- Similar cross-modality compression might extend to other token-heavy multimodal architectures beyond current LVLMs.
- If the aggregation proves stable, it opens a path to dynamically varying the retained token fraction based on prompt complexity.
- Future tests could measure latency gains on real-time video or multi-turn conversation workloads.
Load-bearing premise
Redundancy among vision-token embeddings can be reliably identified and aggregated via prompt-guided cross-modality message passing without losing critical information needed for downstream tasks.
What would settle it
Applying LightKV to a task where vision tokens carry little redundancy and measuring whether accuracy falls below 95 percent of the uncompressed baseline while cache reduction still claims 50 percent.
Figures






read the original abstract
Key-Value (KV) cache has become a de facto component of modern Large Vision-Language Models (LVLMs) for inference. While it enhances decoding efficiency in Large Language Models (LLMs), its direct adoption in LVLMs introduces substantial GPU memory overhead due to the large number of vision tokens processed during the prefill stage. To tackle this problem, we propose LightKV, a novel approach that reduces KV cache size by exploiting the redundancy among vision-token embeddings. Guided by text prompts, LightKV employs cross-modality message passing to aggregate informative messages across vision tokens and progressively compress them during prefill. This prompt-aware guidance distinguishes our method from prior vision-only compression strategies. We evaluate LightKV on eight open-source LVLMs across eight public benchmark datasets, e.g., MME and SeedBench. Experimental results demonstrate that with only 55% of the original vision tokens, LightKV (a) halves the vision-token KV cache size, (b) reduces computation by up to 40%, and (c) preserves general-purpose performance while significantly outperforming existing baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes LightKV, a prompt-guided cross-modality message passing method to aggregate redundant vision-token embeddings during the prefill stage of LVLMs. This reduces the number of vision tokens to 55% of the original, halving the vision-token KV cache size and cutting computation by up to 40% while claiming to preserve general-purpose performance on benchmarks such as MME and SeedBench and outperforming prior vision-only compression baselines across eight open-source LVLMs.
Significance. If the empirical results are robust, LightKV would offer a practical advance in memory-efficient inference for LVLMs by exploiting cross-modal redundancy in a prompt-aware manner, distinguishing it from purely vision-based token pruning. The approach could enable longer contexts or larger batch sizes on limited hardware, but its value depends on whether the compression truly avoids information loss for prompt-unrelated visual details.
major comments (2)
- [Abstract and §4 (Experiments)] The central performance claims (halved KV cache, up to 40% compute reduction, preserved accuracy) rest on the assumption that prompt-conditioned aggregation safely discards only redundant vision tokens. No quantitative bound on information loss or ablation isolating the prompt-guidance effect is provided, leaving open the possibility that fine-grained or prompt-irrelevant content (e.g., background spatial relations) is lost; this directly undermines the “preserves general-purpose performance” result.
- [Abstract] The abstract reports positive results on eight models and datasets but supplies no exact metrics, baseline implementation details, statistical significance tests, or variance across runs. Without these, the claim of “significantly outperforming existing baselines” cannot be verified and the soundness of the empirical contribution remains low.
minor comments (2)
- [§3 (Method)] Notation for the cross-modality message passing (e.g., how messages are aggregated and how the 55% token count is enforced) should be formalized with equations rather than left at a high-level description.
- [§4 (Experiments)] The paper should include an explicit comparison table showing KV cache size, FLOPs, and accuracy for LightKV versus each baseline on every dataset, rather than summarizing aggregate improvements.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight important aspects for strengthening the empirical validation of LightKV. We address each major comment below and outline the revisions we will make.
read point-by-point responses
-
Referee: [Abstract and §4 (Experiments)] The central performance claims (halved KV cache, up to 40% compute reduction, preserved accuracy) rest on the assumption that prompt-conditioned aggregation safely discards only redundant vision tokens. No quantitative bound on information loss or ablation isolating the prompt-guidance effect is provided, leaving open the possibility that fine-grained or prompt-irrelevant content (e.g., background spatial relations) is lost; this directly undermines the “preserves general-purpose performance” result.
Authors: We acknowledge the value of a quantitative bound on information loss, though deriving a general, task-independent bound remains challenging because visual redundancy is inherently prompt- and task-dependent. Our evaluation on diverse benchmarks (MME, SeedBench, and six others) shows that general-purpose performance is retained at 55% token retention. To isolate the contribution of prompt guidance, we will add a dedicated ablation in the revised §4 comparing LightKV against a prompt-agnostic (vision-only) aggregation variant. We will also include qualitative visualizations of retained versus discarded tokens to illustrate that prompt-irrelevant background details are the primary targets of compression. revision: yes
-
Referee: [Abstract] The abstract reports positive results on eight models and datasets but supplies no exact metrics, baseline implementation details, statistical significance tests, or variance across runs. Without these, the claim of “significantly outperforming existing baselines” cannot be verified and the soundness of the empirical contribution remains low.
Authors: The abstract is intentionally concise; all exact per-model metrics, baseline implementations, and full comparison tables appear in §4. We will revise the abstract to incorporate two or three key quantitative highlights (e.g., average accuracy retention on MME and SeedBench relative to the strongest vision-only baseline). In the experiments section we will add a short paragraph reporting run-to-run variance (which was low across the eight models) and note that results were stable; we will also include standard deviations in the main result tables. revision: partial
Circularity Check
No circularity; claims rest on empirical benchmarks
full rationale
The paper introduces LightKV as a prompt-guided compression method for vision-token KV caches in LVLMs and supports its claims through direct evaluation on eight models and eight datasets (MME, SeedBench, etc.). No equations, derivations, or parameter-fitting steps are described that reduce by construction to the method's own inputs or prior self-citations. Performance results (55% token retention, halved cache, 40% compute reduction, preserved accuracy) are presented as outcomes of experimental comparison against baselines rather than as identities or forced predictions.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
CVPR , author =
Nocaps: Novel Object Captioning at Scale , shorttitle =. CVPR , author =
-
[2]
GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints
Ainslie, Joshua and. GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints , shorttitle =. doi:10.48550/arXiv.2305.13245 , archiveprefix =
work page internal anchor Pith review doi:10.48550/arxiv.2305.13245
-
[3]
NeurIPS , author =
Flamingo: A Visual Language Model for Few-Shot Learning , shorttitle =. NeurIPS , author =
-
[4]
DivPrune: Diversity-Based Visual Token Pruning for Large Multimodal Models , shorttitle =. CVPR , author =. doi:10.48550/arXiv.2503.02175 , archiveprefix =. 2503.02175 , primaryclass =
-
[5]
HiRED: Attention-Guided Token Dropping for Efficient Inference of High-Resolution Vision-Language Models , shorttitle =. AAAI , author =. doi:10.1609/aaai.v39i2.32171 , isbn =
-
[6]
OpenFlamingo: An Open-Source Framework for Training Large Autoregressive Vision-Language Models
Awadalla, Anas and Gao, Irena and Gardner, Josh and Hessel, Jack and Hanafy, Yusuf and Zhu, Wanrong and Marathe, Kalyani and Bitton, Yonatan and Gadre, Samir and Sagawa, Shiori and Jitsev, Jenia and Kornblith, Simon and Koh, Pang Wei and Ilharco, Gabriel and Wortsman, Mitchell and Schmidt, Ludwig , year = 2023, primaryclass =. OpenFlamingo: An Open-Source...
work page internal anchor Pith review doi:10.48550/arxiv.2308.01390 2023
-
[7]
Qwen2.5-VL Technical Report , author =. doi:10.48550/arXiv.2502.13923 , archiveprefix =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2502.13923
-
[8]
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond , shorttitle =
Bai, Jinze and Bai, Shuai and Yang, Shusheng and Wang, Shijie and Tan, Sinan and Wang, Peng and Lin, Junyang and Zhou, Chang and Zhou, Jingren , year = 2023, primaryclass =. Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond , shorttitle =
2023
-
[9]
ICLR , author =
BEiT: BERT Pre-Training of Image Transformers , shorttitle =. ICLR , author =
-
[10]
Fuyu-8B: A Multimodal Architecture for AI Agents , shorttitle =
Bavishi, Rohan and Elsen, Erich and Hawthorne, Curtis and Nye, Maxwell and Odena, Augustus and Somani, Arushi and Ta. Fuyu-8B: A Multimodal Architecture for AI Agents , shorttitle =
-
[11]
ICLR , author =
Token Merging: Your ViT But Faster , shorttitle =. ICLR , author =
-
[12]
Learned Thresholds Token Merging and Pruning for Vision Transformers , shorttitle =
Bonnaerens, Maxim and Dambre, Joni , year = 2023, journal =. Learned Thresholds Token Merging and Pruning for Vision Transformers , shorttitle =
2023
-
[13]
NeurIPS , author =
Language Models Are Few-Shot Learners , shorttitle =. NeurIPS , author =
-
[14]
Spectral networks and locally connected networks on graphs,
Bruna, Joan and Zaremba, Wojciech and Szlam, Arthur and LeCun, Yann , year = 2014, eprint =. Spectral Networks and Locally Connected Networks on Graphs , booktitle =. doi:10.48550/arXiv.1312.6203 , archiveprefix =
-
[15]
PyramidKV: Dynamic KV Cache Compression Based on Pyramidal Information Funneling , shorttitle =
Cai, Zefan and Zhang, Yichi and Gao, Bofei and Liu, Yuliang and Liu, Tianyu and Lu, Keming and Xiong, Wayne and Dong, Yue and Chang, Baobao and Hu, Junjie and Xiao, Wen , year = 2024, archiveprefix =. PyramidKV: Dynamic KV Cache Compression Based on Pyramidal Information Funneling , shorttitle =
2024
-
[16]
T-VSL: text-guided visual sound source localization in mixtures
MADTP: Multimodal Alignment-Guided Dynamic Token Pruning for Accelerating Vision-Language Transformer , shorttitle =. CVPR , author =. doi:10.1109/CVPR52733.2024.01487 , copyright =
-
[17]
ACL , author =
PuMer: Pruning and Merging Tokens for Efficient Vision Language Models , shorttitle =. ACL , author =
-
[18]
ICCV , author =
Emerging Properties in Self-Supervised Vision Transformers , shorttitle =. ICCV , author =
-
[19]
ICCV , author =
DiffRate : Differentiable Compression Rate for Efficient Vision Transformers , shorttitle =. ICCV , author =
-
[20]
NeurIPS , author =
Efficient Large Multi-Modal Models via Visual Context Compression , shorttitle =. NeurIPS , author =
-
[21]
Expanding Performance Boundaries of Open-Source Multimodal Models with Model, Data, and Test-Time Scaling , author =. doi:10.48550/arXiv.2412.05271 , archiveprefix =
work page internal anchor Pith review doi:10.48550/arxiv.2412.05271
-
[22]
How Far Are We to GPT-4V? Closing the Gap to Commercial Multimodal Models with Open-Source Suites
Chen, Zhe and Wang, Weiyun and Tian, Hao and Ye, Shenglong and Gao, Zhangwei and Cui, Erfei and Tong, Wenwen and Hu, Kongzhi and Luo, Jiapeng and Ma, Zheng and Ma, Ji and Wang, Jiaqi and Dong, Xiaoyi and Yan, Hang and Guo, Hewei and He, Conghui and Shi, Botian and Jin, Zhenjiang and Xu, Chao and Wang, Bin and Wei, Xingjian and Li, Wei and Zhang, Wenjian a...
work page internal anchor Pith review doi:10.48550/arxiv.2404.16821 2024
-
[23]
An Image Is Worth 1/2 Tokens After Layer 2: Plug-and-Play Inference Acceleration for Large Vision-Language Models , shorttitle =. ECCV , author =. doi:10.1007/978-3-031-73004-7_2 , isbn =
-
[24]
CVPR , author =
Intern VL: Scaling up Vision Foundation Models and Aligning for Generic Visual-Linguistic Tasks , shorttitle =. CVPR , author =
-
[25]
NeurIPS , author =
InstructBLIP: Towards General-Purpose Vision-Language Models with Instruction Tuning , shorttitle =. NeurIPS , author =
-
[26]
NeurIPS , author =
FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness , shorttitle =. NeurIPS , author =
-
[27]
Unveiling Encoder-Free Vision-Language Models , booktitle =
Diao, Haiwen and Cui, Yufeng and Li, Xiaotong and Wang, Yueze and Lu, Huchuan and Wang, Xinlong , year = 2025, pages =. Unveiling Encoder-Free Vision-Language Models , booktitle =
2025
-
[28]
ICLR , author =
An Image Is Worth 16x16 Words: Transformers for Image Recognition at Scale , shorttitle =. ICLR , author =
-
[29]
Driess, Danny and Xia, Fei and Sajjadi, Mehdi S. M. and Lynch, Corey and Chowdhery, Aakanksha and Ichter, Brian and Wahid, Ayzaan and Tompson, Jonathan and Vuong, Quan and Yu, Tianhe and Huang, Wenlong and Chebotar, Yevgen and Sermanet, Pierre and Duckworth, Daniel and Levine, Sergey and Vanhoucke, Vincent and Hausman, Karol and Toussaint, Marc and Greff,...
2023
-
[30]
doi:10.48550/arXiv.2501.07108 , archiveprefix =
How GPT Learns Layer by Layer , author =. doi:10.48550/arXiv.2501.07108 , archiveprefix =
-
[31]
Adaptive Token Sampling for Efficient Vision Transformers , shorttitle =. ECCV , author =. doi:10.1007/978-3-031-20083-0_24 , isbn =
-
[32]
MME: A Comprehensive Evaluation Benchmark for Multimodal Large Language Models
Fu, Chaoyou and Chen, Peixian and Shen, Yunhang and Qin, Yulei and Zhang, Mengdan and Lin, Xu and Yang, Jinrui and Zheng, Xiawu and Li, Ke and Sun, Xing and Wu, Yunsheng and Ji, Rongrong , year = 2024, primaryclass =. MME: A Comprehensive Evaluation Benchmark for Multimodal Large Language Models , shorttitle =. doi:10.48550/arXiv.2306.13394 , archiveprefix =
work page internal anchor Pith review doi:10.48550/arxiv.2306.13394 2024
-
[33]
Gemini 1.5: Unlocking Multimodal Understanding across Millions of Tokens of Context , shorttitle =
Gemini Team , year = 2024, doi =. Gemini 1.5: Unlocking Multimodal Understanding across Millions of Tokens of Context , shorttitle =
2024
-
[34]
Gemini: A Family of Highly Capable Multimodal Models , shorttitle =
Gemini Team , year = 2024, doi =. Gemini: A Family of Highly Capable Multimodal Models , shorttitle =
2024
-
[35]
and Riley, Patrick F
Gilmer, Justin and Schoenholz, Samuel S. and Riley, Patrick F. and Vinyals, Oriol and Dahl, George E. , year = 2017, series =. Neural Message Passing for Quantum Chemistry , booktitle =
2017
-
[36]
ISPASS , author =
Generative AI Beyond LLMs: System Implications of Multi-Modal Generation , shorttitle =. ISPASS , author =
-
[37]
MultiModal-GPT: A Vision and Language Model for Dialogue with Humans , shorttitle =
Gong, Tao and Lyu, Chengqi and Zhang, Shilong and Wang, Yudong and Zheng, Miao and Zhao, Qian and Liu, Kuikun and Zhang, Wenwei and Luo, Ping and Chen, Kai , year = 2023, primaryclass =. MultiModal-GPT: A Vision and Language Model for Dialogue with Humans , shorttitle =
2023
-
[38]
and Monfardini, G
Gori, M. and Monfardini, G. and Scarselli, F. , year = 2005, volume =. A New Model for Learning in Graph Domains , booktitle =
2005
-
[39]
CVPR , author =
VizWiz Grand Challenge: Answering Visual Questions From Blind People , shorttitle =. CVPR , author =
-
[40]
ECCV , author =
IVTP: Instruction-Guided Visual Token Pruning for Large Vision-Language Models , shorttitle =. ECCV , author =
-
[41]
NeurIPS , author =
Language Is Not All You Need: Aligning Perception with Language Models , shorttitle =. NeurIPS , author =
-
[42]
CVPR , author =
GQA: A New Dataset for Real-World Visual Reasoning and Compositional Question Answering , shorttitle =. CVPR , author =
-
[43]
NeurIPS , author =
Matryoshka Query Transformer for Large Vision-Language Models , shorttitle =. NeurIPS , author =
-
[44]
Mistral 7B , author =. doi:10.48550/arXiv.2310.06825 , archiveprefix =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2310.06825
-
[45]
Token Fusion: Bridging the Gap between Token Pruning and Token Merging , shorttitle =. WACV , author =. doi:10.1109/WACV57701.2024.00141 , copyright =
-
[46]
SPViT: Enabling Faster Vision Transformers via Latency-Aware Soft Token Pruning , shorttitle =. ECCV , author =. doi:10.1007/978-3-031-20083-0_37 , isbn =
-
[47]
Efficient memory management for large language model serving with pagedattention
Kwon, Woosuk and Li, Zhuohan and Zhuang, Siyuan and Sheng, Ying and Zheng, Lianmin and Yu, Cody Hao and Gonzalez, Joseph and Zhang, Hao and Stoica, Ion , year = 2023, pages =. Efficient Memory Management for Large Language Model Serving with PagedAttention , booktitle =. doi:10.1145/3600006.3613165 , isbn =
-
[48]
OSDI , author =
InfiniGen: Efficient Generative Inference of Large Language Models with Dynamic KV Cache Management , shorttitle =. OSDI , author =
-
[49]
ICLR , author =
EViT: Expediting Vision Transformers via Token Reorganizations , shorttitle =. ICLR , author =
-
[50]
ICML , author =
BLIP-2: Bootstrapping Language-Image Pre-Training with Frozen Image Encoders and Large Language Models , shorttitle =. ICML , author =
-
[51]
EMNLP , author =
Evaluating Object Hallucination in Large Vision-Language Models , shorttitle =. EMNLP , author =
-
[52]
LLaMA-VID: An Image Is Worth 2 Tokens in Large Language Models , shorttitle =. ECCV , author =. doi:10.1007/978-3-031-72952-2_19 , isbn =
-
[53]
LLaVA-OneVision: Easy Visual Task Transfer
Li, Bo and Zhang, Yuanhan and Guo, Dong and Zhang, Renrui and Li, Feng and Zhang, Hao and Zhang, Kaichen and Zhang, Peiyuan and Li, Yanwei and Liu, Ziwei and Li, Chunyuan , year = 2024, primaryclass =. LLaVA-OneVision: Easy Visual Task Transfer , shorttitle =. doi:10.48550/arXiv.2408.03326 , archiveprefix =
-
[54]
Microsoft COCO: Common Objects in Context , shorttitle =. ECCV , author =. doi:10.1007/978-3-319-10602-1_48 , isbn =
-
[55]
EMNLP , author =
Video-LLaVA: Learning United Visual Representation by Alignment Before Projection , shorttitle =. EMNLP , author =
-
[56]
Otterhd: A high-resolution multi- modality model
Li, Bo and Zhang, Peiyuan and Yang, Jingkang and Zhang, Yuanhan and Pu, Fanyi and Liu, Ziwei , year = 2023, primaryclass =. OtterHD: A High-Resolution Multi-Modality Model , shorttitle =. doi:10.48550/arXiv.2311.04219 , archiveprefix =
-
[57]
Otter: A Multi-Modal Model with In-Context Instruction Tuning , shorttitle =
Li, Bo and Zhang, Yuanhan and Chen, Liangyu and Wang, Jinghao and Yang, Jingkang and Liu, Ziwei , year = 2023, primaryclass =. Otter: A Multi-Modal Model with In-Context Instruction Tuning , shorttitle =
2023
-
[58]
CVPR , author =
SEED-Bench: Benchmarking Multimodal Large Language Models , shorttitle =. CVPR , author =
-
[59]
Semantic routing: Exploring multi-layer llm feature weighting for diffusion transformers
Li, Bozhou and Guan, Yushuo and Li, Haolin and Zeng, Bohan and Ji, Yiyan and Ding, Yue and Wan, Pengfei and Gai, Kun and Zhang, Yuanxing and Zhang, Wentao , year = 2026, primaryclass =. Semantic Routing: Exploring Multi-Layer LLM Feature Weighting for Diffusion Transformers , shorttitle =. doi:10.48550/arXiv.2602.03510 , archiveprefix =
-
[60]
NeurIPS , author =
SnapKV: LLM Knows What You Are Looking for Before Generation , shorttitle =. NeurIPS , author =
-
[61]
Efficient Inference of Vision Instruction-Following Models with Elastic Cache , booktitle =
Liu, Zuyan and Liu, Benlin and Wang, Jiahui and Dong, Yuhao and Chen, Guangyi and Rao, Yongming and Krishna, Ranjay and Lu, Jiwen , editor =. Efficient Inference of Vision Instruction-Following Models with Elastic Cache , booktitle =. doi:10.1007/978-3-031-72643-9_4 , isbn =
-
[62]
Improved Baselines with Visual Instruction Tuning
Liu, Haotian and Li, Chunyuan and Li, Yuheng and Lee, Yong Jae , year = 2024, primaryclass =. Improved Baselines with Visual Instruction Tuning , shorttitle =. doi:10.48550/arXiv.2310.03744 , archiveprefix =
work page internal anchor Pith review doi:10.48550/arxiv.2310.03744 2024
-
[63]
LLaVA-NeXT: Improved Reasoning, OCR, and World Knowledge , shorttitle =
Liu, Haotian and Li, Chunyuan and Li, Yuheng and Li, Bo and Zhang, Yuanhan and Shen, Sheng and Lee, Yong Jae , year = 2024, howpublished =. LLaVA-NeXT: Improved Reasoning, OCR, and World Knowledge , shorttitle =
2024
-
[64]
NeurIPS , author =
MiniCache: KV Cache Compression in Depth Dimension for Large Language Models , shorttitle =. NeurIPS , author =
-
[65]
NeurIPS , author =
Scissorhands: Exploiting the Persistence of Importance Hypothesis for LLM KV Cache Compression at Test Time , shorttitle =. NeurIPS , author =
-
[66]
ICCV , author =
Swin Transformer: Hierarchical Vision Transformer Using Shifted Windows , shorttitle =. ICCV , author =
-
[67]
NeurIPS , author =
Visual Instruction Tuning , shorttitle =. NeurIPS , author =
-
[68]
The Llama 3 Herd of Models , shorttitle =. doi:10.48550/arXiv.2407.21783 , archiveprefix =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2407.21783
-
[69]
Content-Aware Token Sharing for Efficient Semantic Segmentation with Vision Transformers , booktitle =
Lu, Chenyang and. Content-Aware Token Sharing for Efficient Semantic Segmentation with Vision Transformers , booktitle =
-
[70]
DeepSeek-VL: Towards Real-World Vision-Language Understanding
Lu, Haoyu and Liu, Wen and Zhang, Bo and Wang, Bingxuan and Dong, Kai and Liu, Bo and Sun, Jingxiang and Ren, Tongzheng and Li, Zhuoshu and Yang, Hao and Sun, Yaofeng and Deng, Chengqi and Xu, Hanwei and Xie, Zhenda and Ruan, Chong , year = 2024, primaryclass =. DeepSeek-VL: Towards Real-World Vision-Language Understanding , shorttitle =. doi:10.48550/arX...
work page internal anchor Pith review doi:10.48550/arxiv.2403.05525 2024
-
[71]
NeurIPS , author =
Learn to Explain: Multimodal Reasoning via Thought Chains for Science Question Answering , shorttitle =. NeurIPS , author =
-
[72]
Prune and Merge: Efficient Token Compression for Vision Transformer with Spatial Information Preserved , shorttitle =
Mao, Junzhu and Shen, Yang and Guo, Jinyang and Yao, Yazhou and Hua, Xiansheng and Shen, Hengtao , year = 2025, journal =. Prune and Merge: Efficient Token Compression for Vision Transformer with Spatial Information Preserved , shorttitle =
2025
-
[73]
WACV , author =
DocVQA: A Dataset for VQA on Document Images , shorttitle =. WACV , author =
-
[74]
AdaViT: Adaptive Vision Transformers for Efficient Image Recognition , shorttitle =. CVPR , author =. doi:10.1109/CVPR52688.2022.01199 , isbn =
-
[75]
CVPR , author =
ALGM: Adaptive Local-Then-Global Token Merging for Efficient Semantic Segmentation with Plain Vision Transformers , shorttitle =. CVPR , author =
-
[76]
GPT-4 Technical Report , shorttitle =
OpenAI , year = 2024, doi =. GPT-4 Technical Report , shorttitle =
2024
-
[77]
DINOv2: Learning Robust Visual Features without Supervision , shorttitle =
Oquab, Maxime and Darcet, Timoth. DINOv2: Learning Robust Visual Features without Supervision , shorttitle =
-
[78]
AAAI , author =
Less Is More: Pay Less Attention in Vision Transformers , shorttitle =. AAAI , author =
-
[79]
AAAI , author =
Reverend Bayes on Inference Engines: A Distributed Hierarchical Approach , shorttitle =. AAAI , author =
-
[80]
Kosmos-2: Grounding Multimodal Large Language Models to the World , shorttitle =
Peng, Zhiliang and Wang, Wenhui and Dong, Li and Hao, Yaru and Huang, Shaohan and Ma, Shuming and Wei, Furu , year = 2023, primaryclass =. Kosmos-2: Grounding Multimodal Large Language Models to the World , shorttitle =
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.