Recognition: unknown
CustomDancer: Customized Dance Recommendation by Text-Dance Retrieval
Pith reviewed 2026-05-09 14:47 UTC · model grok-4.3
The pith
CustomDancer achieves state-of-the-art text-to-dance retrieval with 10.23% Recall@1 on the new TD-Data dataset by aligning text, music, and motion features through a CLIP-based framework.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
On top of this dataset, we propose CustomDancer, a multimodal retrieval framework that aligns text with dance through a CLIP-based text encoder, music and motion encoders, and a music-motion blending module. CustomDancer achieves state-of-the-art performance on TD-Data, reaching 10.23% Recall@1 and improving retrieval quality in both quantitative benchmarks and user preference studies.
Load-bearing premise
That expert annotations in TD-Data reliably capture the combined linguistic, rhythmic, and dynamic properties needed for effective text-dance matching, and that standard CLIP and separate music/motion encoders can be aligned via the blending module without major domain-specific failures.
Figures


read the original abstract
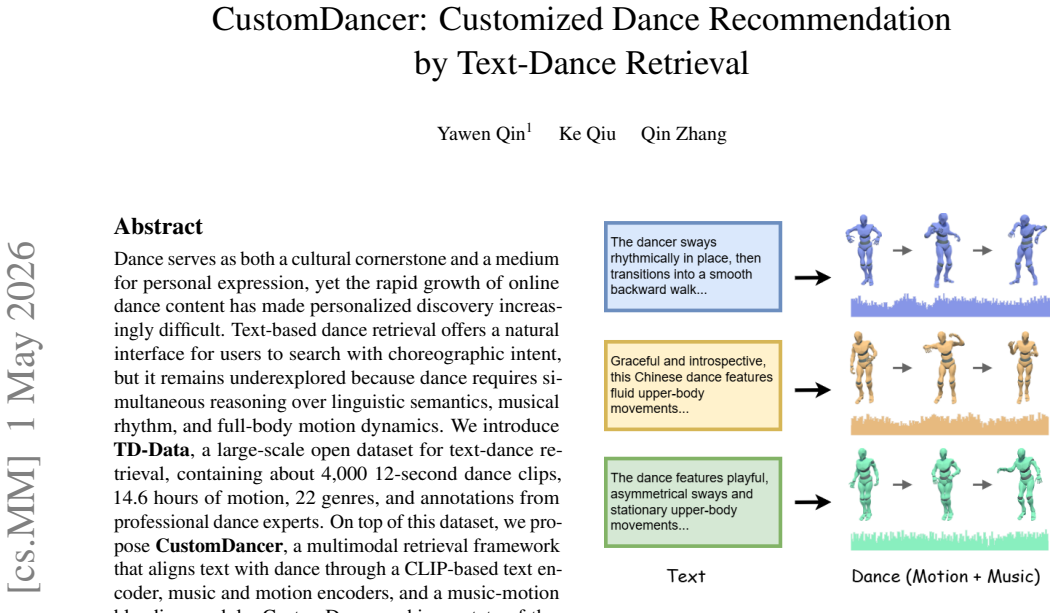
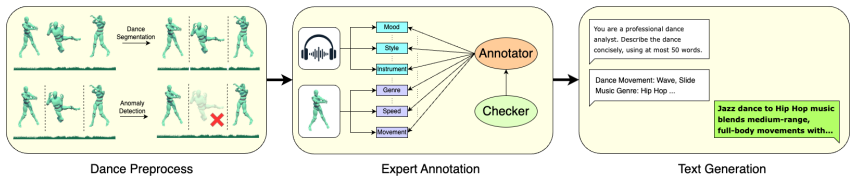
Dance serves as both a cultural cornerstone and a medium for personal expression, yet the rapid growth of online dance content has made personalized discovery increasingly difficult. Text-based dance retrieval offers a natural interface for users to search with choreographic intent, but it remains underexplored because dance requires simultaneous reasoning over linguistic semantics, musical rhythm, and full-body motion dynamics. We introduce TD-Data, a large-scale open dataset for text-dance retrieval, containing about 4,000 12-second dance clips, 14.6 hours of motion, 22 genres, and annotations from professional dance experts. On top of this dataset, we propose CustomDancer, a multimodal retrieval framework that aligns text with dance through a CLIP-based text encoder, music and motion encoders, and a music-motion blending module. CustomDancer achieves state-of-the-art performance on TD-Data, reaching 10.23% Recall@1 and improving retrieval quality in both quantitative benchmarks and user preference studies.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces TD-Data, a new open dataset of approximately 4,000 12-second dance clips (14.6 hours total, 22 genres) with annotations from professional dance experts, and proposes CustomDancer, a multimodal text-dance retrieval framework. CustomDancer employs a CLIP-based text encoder, separate music and motion encoders, and a music-motion blending module to align modalities. The authors claim state-of-the-art results on TD-Data, specifically 10.23% Recall@1, together with quantitative benchmark gains and improved retrieval quality in user preference studies.
Significance. If the central claims hold after proper validation, the work would provide the first large-scale benchmark for text-based dance retrieval and a practical multimodal alignment method that jointly reasons over semantics, rhythm, and motion. The dataset scale and expert annotations represent a concrete resource for the community, while the user studies add evidence of downstream utility beyond standard metrics. The modest absolute Recall@1 value underscores that the task remains difficult, but successful release of the data and code could accelerate progress in personalized dance recommendation.
major comments (2)
- [Dataset] Dataset section: the claim that professional expert annotations reliably capture combined linguistic, rhythmic, and dynamic properties for effective matching is load-bearing for all retrieval results, yet no details are supplied on annotation protocol, number of annotators per clip, inter-rater reliability, or any validation against rhythmic/dynamic ground truth.
- [Experiments] Experiments / evaluation: the reported 10.23% Recall@1 as SOTA is presented without enumeration of baselines, training hyperparameters, data-split methodology, or statistical significance tests, preventing verification that gains arise from the music-motion blending module rather than dataset artifacts or implementation choices.
minor comments (1)
- [Abstract] The abstract would be clearer if it briefly stated the total motion duration and genre count when introducing TD-Data, rather than deferring all quantitative details.
Simulated Author's Rebuttal
We are grateful to the referee for their insightful comments, which will help strengthen our manuscript. Below, we provide point-by-point responses to the major comments and indicate the revisions we plan to implement.
read point-by-point responses
-
Referee: [Dataset] Dataset section: the claim that professional expert annotations reliably capture combined linguistic, rhythmic, and dynamic properties for effective matching is load-bearing for all retrieval results, yet no details are supplied on annotation protocol, number of annotators per clip, inter-rater reliability, or any validation against rhythmic/dynamic ground truth.
Authors: We agree that additional details on the annotation process are necessary to substantiate the dataset's quality and support the retrieval results. In the revised manuscript, we will expand the Dataset section with a complete description of the annotation protocol, including the number of professional dance experts per clip, inter-rater reliability metrics, and validation procedures against rhythmic and dynamic ground truth. revision: yes
-
Referee: [Experiments] Experiments / evaluation: the reported 10.23% Recall@1 as SOTA is presented without enumeration of baselines, training hyperparameters, data-split methodology, or statistical significance tests, preventing verification that gains arise from the music-motion blending module rather than dataset artifacts or implementation choices.
Authors: We acknowledge that the experimental details require greater clarity and completeness to allow independent verification. In the revised manuscript, we will explicitly enumerate all baselines, provide the full set of training hyperparameters, describe the data-split methodology in detail, and report statistical significance tests to confirm that improvements derive from the music-motion blending module. revision: yes
Circularity Check
No significant circularity in the derivation chain.
full rationale
The paper introduces TD-Data as a new annotated dataset and proposes the CustomDancer architecture (CLIP text encoder + separate music/motion encoders + blending module) as an empirical multimodal retrieval system. Reported performance (10.23% R@1) and user studies are direct evaluations on this dataset using standard retrieval metrics; no equations, fitted parameters, or predictions are defined in terms of themselves. No self-citations, uniqueness theorems, or ansatzes are invoked to justify core components. The framework description and results stand as independent empirical claims rather than reducing to input definitions or self-referential constructions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A CLIP-based text encoder pretrained on general image-text data can be directly applied to align natural language descriptions with dance motion and music features.
Reference graph
Works this paper leans on
-
[1]
Ronghui Li, Junfan Zhao, Yachao Zhang, Mingyang Su, Zeping Ren, Han Zhang, Yansong Tang, and Xiu Li. Finedance: A fine-grained choreography dataset for 3d full body dance generation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 10234–10243, 2023. doi: 10.1109/ICCV51070. 2023.00939. 1, 2
-
[2]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. InInterna- tional Conference on Machine Learning, pages 8748– 8763, 2021. 2, 4
2021
-
[3]
Bermano, and Daniel Cohen-Or
Guy Tevet, Brian Gordon, Amir Hertz, Amit H. Bermano, and Daniel Cohen-Or. Motionclip: Exposing human mo- tion generation to clip space. InInternational Conference on Learning Representations, 2023. 2
2023
-
[4]
Guy Tevet, Sigal Raab, Brian Gordon, Yonatan Shafir, Daniel Cohen-Or, and Amit H. Bermano. Human mo- tion diffusion model. InAdvances in Neural Information Processing Systems, volume 35, pages 1673–1686, 2022
2022
-
[5]
Black, and G¨ul Varol
Mathis Petrovich, Michael J. Black, and G¨ul Varol. Tm2t: Stochastic and tokenized motion-to-text generation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 616–626, 2023
2023
-
[6]
Gener- ating diverse and natural 3d human motions from text
Chuan Guo, Xinxin Zuo, Sen Wang, Shihao Zou, Qingyao Sun, Annan Deng, Minglun Gong, and Li Cheng. Gener- ating diverse and natural 3d human motions from text. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5152–5161, 2022. 2
2022
-
[7]
T2m-gpt: Generating human motion from tex- tual descriptions with discrete representations
Jianrong Zhang, Yangsong Zhang, Xiaodong Cun, Yong Huang, Yong Zhang, Hongwei Zhao, Hongtao Lu, and Xi Shen. T2m-gpt: Generating human motion from tex- tual descriptions with discrete representations. InProceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14730–14740, 2023. 2
2023
-
[8]
Momask: Generative masked modeling of 3d human motions
Chuan Guo, Yuxuan Mu, Muhammad Gohar Javed, Sen Wang, and Li Cheng. Momask: Generative masked modeling of 3d human motions. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024. 2
2024
-
[9]
Motiondif- fuse: Text-driven human motion generation with diffusion model
Mingyuan Zhang, Zhongang Cai, Liang Pan, Fangzhou Hong, Xinying Guo, Lei Yang, and Ziwei Liu. Motiondif- fuse: Text-driven human motion generation with diffusion model. InIEEE Transactions on Pattern Analysis and Machine Intelligence, 2024. 2
2024
-
[10]
Semtalk: Holistic co-speech mo- tion generation with frame-level semantic emphasis
Xiangyue Zhang et al. Semtalk: Holistic co-speech mo- tion generation with frame-level semantic emphasis. In Proceedings of the IEEE/CVF International Conference on Computer Vision, 2025. 2
2025
-
[11]
Echomask: Speech-queried attention-based mask modeling for holistic co-speech mo- tion generation
Xiangyue Zhang et al. Echomask: Speech-queried attention-based mask modeling for holistic co-speech mo- tion generation. InProceedings of the ACM International Conference on Multimedia, 2025. 2
2025
-
[12]
Mitigating error accumulation in co-speech mo- tion generation via global rotation diffusion and multi- level constraints
Xiangyue Zhang, Jianfang Li, Jianqiang Ren, and Jiaxu Zhang. Mitigating error accumulation in co-speech mo- tion generation via global rotation diffusion and multi- level constraints. InProceedings of the AAAI Conference on Artificial Intelligence, 2026. 2
2026
-
[13]
Yichao Zhou, Xiangyue Zhang, et al. Not all frames are equal: Complexity-aware masked motion genera- tion via motion spectral descriptors.arXiv preprint arXiv:2603.11091, 2026. 2
-
[14]
Robust 2d skeleton action recogni- tion via decoupling and distilling 3d latent features.IEEE Transactions on Circuits and Systems for Video Technol- ogy, 2025
Xiangyue Zhang et al. Robust 2d skeleton action recogni- tion via decoupling and distilling 3d latent features.IEEE Transactions on Circuits and Systems for Video Technol- ogy, 2025. 2
2025
-
[15]
Music2dance: Dancenet for music-driven dance generation.ACM Trans- actions on Graphics, 39(6):1–16, 2020
Taoran Tang, Jia Jia, and Hanyang Mao. Music2dance: Dancenet for music-driven dance generation.ACM Trans- actions on Graphics, 39(6):1–16, 2020. 2
2020
-
[16]
Dance revolution: Long-term dance generation with music via curriculum learning
Ruozi Huang, Huang Hu, Wei Wu, Kei Sawada, Mi Zhang, and Daxin Jiang. Dance revolution: Long-term dance generation with music via curriculum learning. InInter- national Conference on Learning Representations, 2021
2021
-
[17]
Ross, and Angjoo Kanazawa
Ruilong Li, Shan Yang, David A. Ross, and Angjoo Kanazawa. Aist++: Learning to synthesize 3d dance motion with music. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 11001–11011, 2021. 2
2021
-
[18]
Bailando: 3d dance generation by actor-critic gpt with choreographic memory
Li Siyao, Weijiang Yu, Tianpei Gu, Chunze Lin, Quan Wang, Chen Qian, Chen Change Loy, and Ziwei Liu. Bailando: 3d dance generation by actor-critic gpt with choreographic memory. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 11050–11059, 2022. 2
2022
-
[19]
Bailando++: 3d dance gpt with choreographic memory
Siyao Li, Weijiang Yu, Tianpei Gu, Chunze Lin, Quan Wang, Chen Qian, Chen Change Loy, and Ziwei Liu. Bailando++: 3d dance gpt with choreographic memory. IEEE Transactions on Pattern Analysis and Machine In- telligence, 2023. 2
2023
-
[20]
Duolando: Follower gpt with off-policy reinforce- ment learning for dance accompaniment
Siyao Li, Yuejiang Sun, Ziwei Li, Ziyang Huang, Zhaoyang Liu, Haoye Zhang, Chaotian Cao, and Ziwei Liu. Duolando: Follower gpt with off-policy reinforce- ment learning for dance accompaniment. InInternational Conference on Learning Representations, 2024. 2
2024
-
[21]
Lodge: A coarse to fine diffusion network for long dance gener- ation guided by the characteristic dance primitives
Ronghui Li, YuXiang Zhang, Yachao Zhang, Hongwen Zhang, Jie Guo, Yan Zhang, Yebin Liu, and Xiu Li. Lodge: A coarse to fine diffusion network for long dance gener- ation guided by the characteristic dance primitives. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1524–1534, 2024. 2 9
2024
-
[22]
Exploring multi-modal control in music-driven dance generation.arXiv preprint arXiv:2401.01382, 2024
Ronghui Li et al. Exploring multi-modal control in music-driven dance generation.arXiv preprint arXiv:2401.01382, 2024
-
[23]
Ronghui Li et al. Interdance: Reactive 3d dance gen- eration with realistic duet interactions.arXiv preprint arXiv:2412.16982, 2024
-
[24]
Ronghui Li, Zhongyuan Hu, Siyao Li, Youliang Zhang, Haozhe Xie, Mingyuan Zhang, Jie Guo, Xiu Li, and Ziwei Liu. Infinitedance: Scalable 3d dance genera- tion towards in-the-wild generalization.arXiv preprint arXiv:2603.13375, 2026
-
[25]
Souldance: Music-aligned holistic 3d dance generation via hierarchical motion modeling
Ronghui Li et al. Souldance: Music-aligned holistic 3d dance generation via hierarchical motion modeling. In Proceedings of the IEEE/CVF International Conference on Computer Vision, 2025. 2
2025
-
[26]
Kehong Gong, Defu Lian, Heng Chang, Chuan Guo, Zi- hang Jiang, Xinxin Zuo, Michael Bi Mi, and Xinchao Wang. Tm2d: Bimodality driven 3d dance generation via music-text integration.arXiv preprint arXiv:2304.02419,
-
[27]
Codancers: Music-driven coherent group dance generation with choreographic unit.Proceed- ings of the ACM International Conference on Multimedia Retrieval, 2024
Kaixing Yang, Xulong Tang, Ran Diao, Hongyan Liu, Jun He, and Zhaoxin Fan. Codancers: Music-driven coherent group dance generation with choreographic unit.Proceed- ings of the ACM International Conference on Multimedia Retrieval, 2024. 2
2024
-
[28]
Cohedancers: Enhancing interactive group dance generation through music-driven coherence decomposition
Kaixing Yang, Xulong Tang, Haoyu Wu, Biao Qin, Hongyan Liu, Jun He, and Zhaoxin Fan. Cohedancers: Enhancing interactive group dance generation through music-driven coherence decomposition. InProceedings of the ACM International Conference on Multimedia, pages 6663–6671, 2025. 2
2025
-
[29]
Megadance: Mixture-of- experts architecture for genre-aware 3d dance generation
Kaixing Yang, Xulong Tang, Ziqiao Peng, Yuxuan Hu, Jun He, and Hongyan Liu. Megadance: Mixture-of- experts architecture for genre-aware 3d dance generation. arXiv preprint arXiv:2505.17543, 2025. 2
-
[30]
Ziyue Yang, Kaixing Yang, and Xulong Tang. Token- dance: Token-to-token music-to-dance generation with bidirectional mamba.arXiv preprint arXiv:2603.27314,
-
[31]
Kaixing Yang, Xulong Tang, Ziqiao Peng, Xiangyue Zhang, Puwei Wang, Jun He, and Hongyan Liu. Flow- erdance: Meanflow for efficient and refined 3d dance generation.arXiv preprint arXiv:2511.21029, 2025. 2
-
[32]
BiTDiff: Fine-Grained 3D Conducting Motion Generation via BiMamba-Transformer Diffusion
Tianzhi Jia, Kaixing Yang, Xiaole Yang, Xulong Tang, Ke Qiu, Shikui Wei, and Yao Zhao. Bitdiff: Fine- grained 3d conducting motion generation via bimamba- transformer diffusion.arXiv preprint arXiv:2604.04395,
work page internal anchor Pith review Pith/arXiv arXiv
-
[33]
MACE-Dance: Motion-Appearance Cascaded Experts for Music-Driven Dance Video Generation
Kaixing Yang, Jiashu Zhu, Xulong Tang, Ziqiao Peng, Xiangyue Zhang, Puwei Wang, Jiahong Wu, et al. Mace-dance: Motion-appearance cascaded experts for music-driven dance video generation.arXiv preprint arXiv:2512.18181, 2025. 2
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
Audioclip: Extending clip to image, text and audio
Andrey Guzhov, Federico Raue, J ¨orn Hees, and Andreas Dengel. Audioclip: Extending clip to image, text and audio. InIEEE International Conference on Acoustics, Speech and Signal Processing, pages 976–980, 2022. 2
2022
-
[35]
Clap: Learning audio concepts from natural language supervision
Yusong Huang et al. Clap: Learning audio concepts from natural language supervision. InIEEE International Conference on Acoustics, Speech and Signal Processing, pages 1–5, 2023. 2
2023
-
[36]
Sophia Koepke, Olivia Wiles, Yonatan Moses, and Andrew Zisserman
A. Sophia Koepke, Olivia Wiles, Yonatan Moses, and Andrew Zisserman. Audio retrieval with natural language queries. InProceedings of Interspeech, 2022. 2
2022
- [37]
-
[38]
Clamp: Contrastive language-music pre-training for cross-modal symbolic music information retrieval
Yusong Wu, Ke Chen, Tianyu Zhang, Yuchen Hui, Mar- ianna Nezhurina, Taylor Berg-Kirkpatrick, and Shlomo Dubnov. Clamp: Contrastive language-music pre-training for cross-modal symbolic music information retrieval. arXiv preprint arXiv:2304.11029, 2023. 2
-
[39]
Beatdance: A beat-based model-agnostic contrastive learning frame- work for music-dance retrieval
Kaixing Yang, Xukun Zhou, Xulong Tang, Ran Diao, Hongyan Liu, Jun He, and Zhaoxin Fan. Beatdance: A beat-based model-agnostic contrastive learning frame- work for music-dance retrieval. InProceedings of the ACM International Conference on Multimedia Retrieval, pages 11–19, 2024. doi: 10.1145/3652583.3658045. 2
-
[40]
Multi-modal transformer for video retrieval
Valentin Gabeur, Chen Sun, Karteek Alahari, and Cordelia Schmid. Multi-modal transformer for video retrieval. InProceedings of the European Conference on Computer Vision, pages 214–229, 2020. 2, 6, 7
2020
-
[41]
Table: Tagging before alignment for multi-modal retrieval
Yuqi Liu, Yao Li, Yuanjun Xiong, Yu Zhang, and Dahua Lin. Table: Tagging before alignment for multi-modal retrieval. InProceedings of the AAAI Conference on Artificial Intelligence, 2023. 2, 6, 7
2023
-
[42]
Language-conditioned motion re- trieval with contrastive learning
Anindita Ghosh et al. Language-conditioned motion re- trieval with contrastive learning. InProceedings of the IEEE/CVF Winter Conference on Applications of Com- puter Vision, pages 1234–1243, 2023. 3
2023
-
[43]
Brian McFee, Colin Raffel, Dawen Liang, Daniel P. W. Ellis, Matt McVicar, Eric Battenberg, and Oriol Nieto. librosa: Audio and music signal analysis in python. In Proceedings of the Python in Science Conference, pages 18–25, 2015. 4
2015
-
[44]
Gomez, Lukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need. InAd- vances in Neural Information Processing Systems, 2017. 4 10
2017
-
[45]
Matthew Loper, Naureen Mahmood, Javier Romero, Ger- ard Pons-Moll, and Michael J. Black. Smpl: A skinned multi-person linear model.ACM Transactions on Graph- ics, 34(6):1–16, 2015. 5 11
2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.