Recognition: unknown
H-Probes: Extracting Hierarchical Structures From Latent Representations of Language Models
Pith reviewed 2026-05-10 14:03 UTC · model grok-4.3
The pith
Language models encode hierarchical depth and pairwise distances in low-dimensional subspaces of their latent representations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
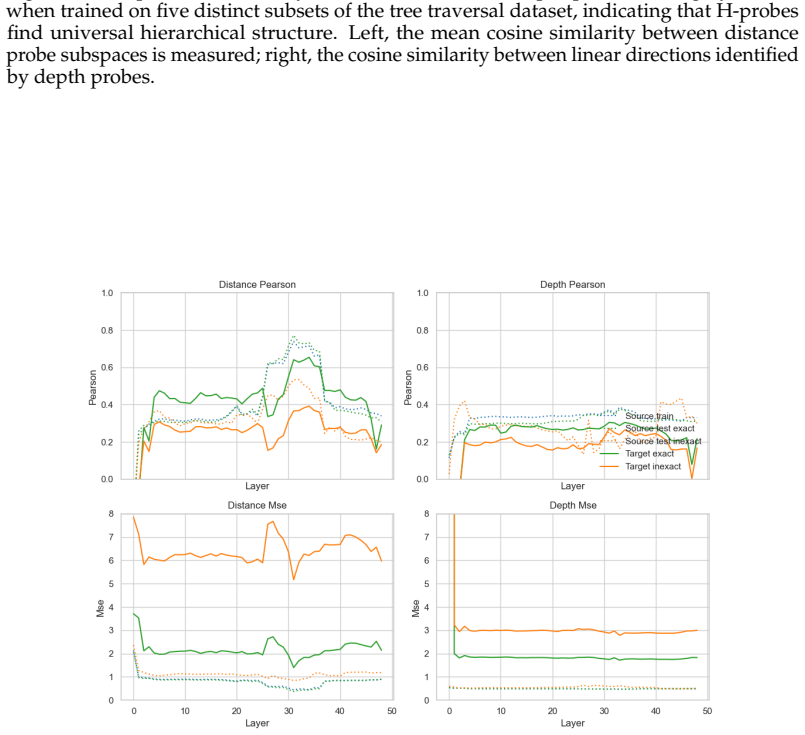
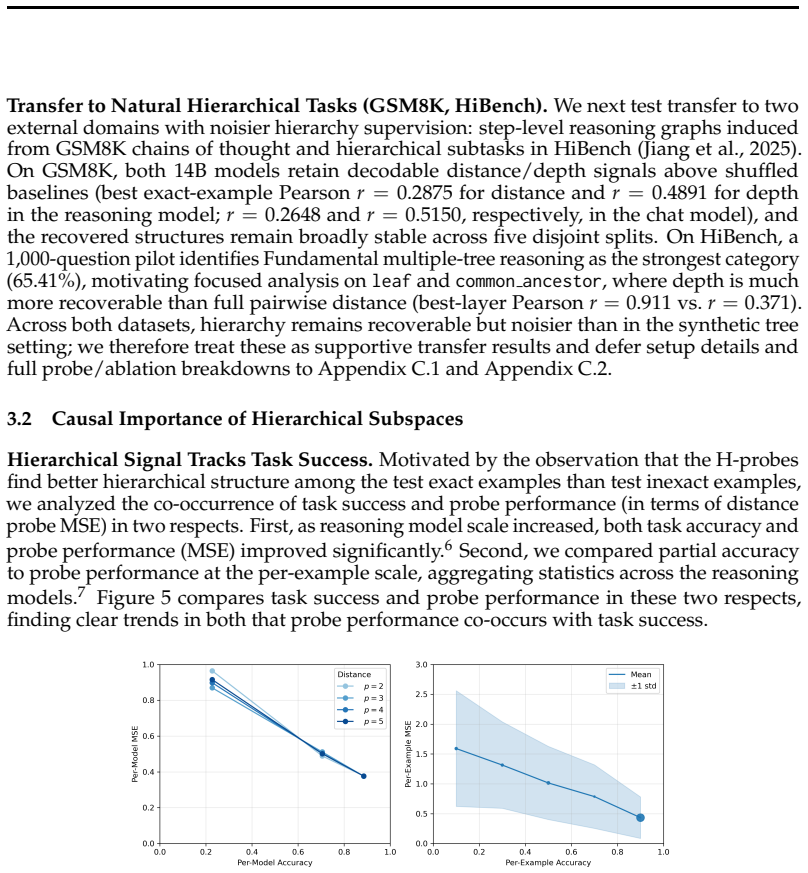
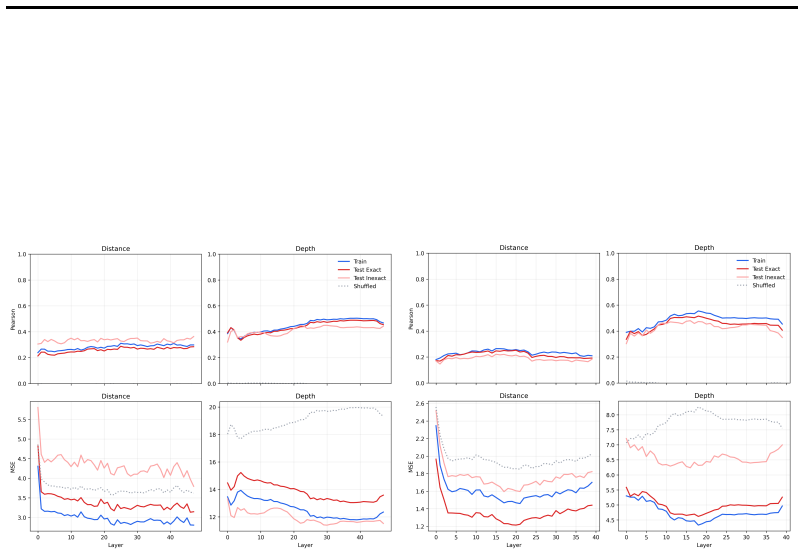
H-probes recover subspaces in language model activations that contain the depth of nodes and the distances between pairs of nodes in hierarchical structures. On synthetic tree traversal problems these subspaces are low-dimensional, their targeted removal degrades performance, and the probes remain effective across different trees and even on out-of-distribution examples. The same kind of signal, though attenuated, appears in the reasoning traces of mathematical problems.
What carries the argument
H-probes: a collection of linear probes trained to predict depth and pairwise distance from latent representations.
If this is right
- The hierarchy subspaces are low-dimensional.
- Removing them reduces task accuracy, showing causal importance.
- The subspaces support generalization both within and across domains.
- Similar hierarchical signals exist, more faintly, in mathematical reasoning traces.
Where Pith is reading between the lines
- If the subspaces are causally important, targeted interventions on them could steer the model's hierarchical decisions.
- The linear extractability suggests that other abstract relations such as causality or ordering may be isolable by similar probes.
- Success on synthetic trees raises the question of whether the same subspaces remain critical when models handle richer, real-world hierarchies.
Load-bearing premise
Depth and pairwise distance capture the hierarchical information that models use for reasoning, and this information is linearly readable from the activations.
What would settle it
The probes fail to predict depth or distance above chance on held-out synthetic trees, or ablating the identified dimensions produces no measurable drop in task accuracy.
Figures















read the original abstract
Representing and navigating hierarchy is a fundamental primitive of reasoning. Large language models have demonstrated proficiency in a wide variety of tasks requiring hierarchical reasoning, but there exists limited analysis on how the models geometrically represent the necessary latent constructions for such thinking. To this end, we develop H-probes, a collection of linear probes that extract hierarchical structure, specifically depth and pairwise distance, from latent representations. In synthetic tree traversal tasks, the H-probes robustly find the subspaces containing hierarchical structure necessary to complete the tasks; furthermore, in comprehensive ablation experiments, we show that these hierarchy-containing subspaces are low-dimensional, causally important for high task performance, and generalize within- and out-of-domain. Furthermore, we find analogous, though weaker, hierarchical structure in real-world hierarchical contexts such as mathematical reasoning traces. These results demonstrate that models represent hierarchy not only at the level of syntax and concepts, but at deeper levels of abstraction -- including the reasoning process itself.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces H-probes, linear probes for extracting hierarchical structure (specifically depth and pairwise distance) from LLM latent representations. It reports that in synthetic tree traversal tasks these probes identify low-dimensional subspaces containing the necessary hierarchy, that ablation experiments demonstrate these subspaces are causally important for task performance and generalize within- and out-of-domain, and that weaker analogous structure appears in real mathematical reasoning traces.
Significance. If the results hold, particularly the causal necessity of the identified subspaces, the work would provide concrete geometric evidence that LLMs encode hierarchy at the level of reasoning processes rather than only syntax or concepts. The use of controlled synthetic tasks combined with ablation-based tests of importance and generalization is a methodological strength that could inform both interpretability research and efforts to enhance hierarchical reasoning in models.
major comments (1)
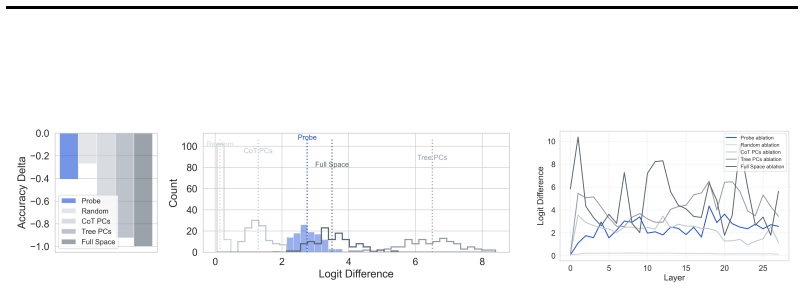
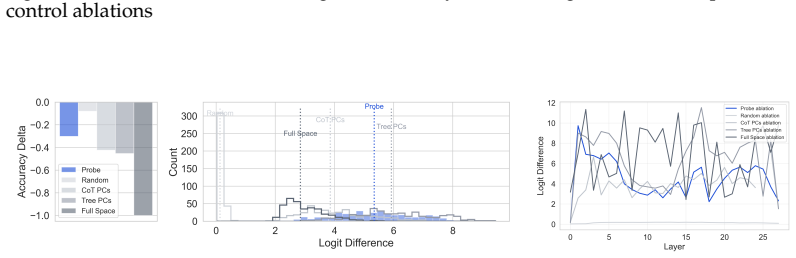
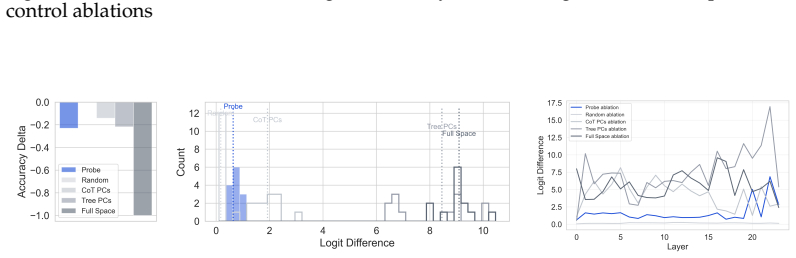
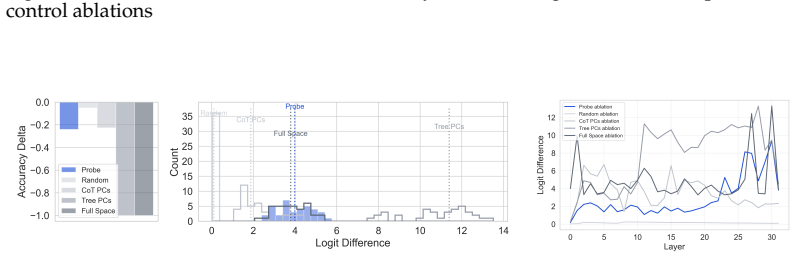
- [Ablation experiments] Ablation experiments: the claim that the low-dimensional subspaces identified by H-probes are causally important for task performance rests on performance drops after projection or zeroing along the probe directions. However, these interventions are not compared against controls that remove random or non-hierarchical subspaces of matched dimensionality while preserving overall representation norm and other linear features. Without such controls, the observed drops could result from generic dimensionality reduction rather than specific removal of hierarchy, which is load-bearing for the central causal claim especially in the synthetic tree tasks where the input explicitly encodes tree structure and multiple redundant pathways may exist.
minor comments (2)
- [Abstract] The abstract and introduction would benefit from a brief explicit statement of how H-probes are trained (e.g., supervision signal, loss, and whether they are trained on the same data used for the downstream tasks).
- [Figures] Figure captions and axis labels for the ablation plots should include error bars or confidence intervals and state the number of random seeds or runs.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation of our work's potential significance and for the constructive major comment on the ablation experiments. We address the point below and will revise the manuscript accordingly to strengthen the causal claims.
read point-by-point responses
-
Referee: Ablation experiments: the claim that the low-dimensional subspaces identified by H-probes are causally important for task performance rests on performance drops after projection or zeroing along the probe directions. However, these interventions are not compared against controls that remove random or non-hierarchical subspaces of matched dimensionality while preserving overall representation norm and other linear features. Without such controls, the observed drops could result from generic dimensionality reduction rather than specific removal of hierarchy, which is load-bearing for the central causal claim especially in the synthetic tree tasks where the input explicitly encodes tree structure and multiple redundant pathways may exist.
Authors: We appreciate the referee identifying this gap in our ablation analysis. The referee is correct that the manuscript does not currently include controls ablating random or non-hierarchical subspaces of matched dimensionality (while preserving norm), which leaves open the possibility that observed performance drops stem from generic dimensionality reduction effects rather than specific removal of hierarchical structure. To address this directly, we will add new control experiments in the revised manuscript. These will involve sampling random directions in the activation space of the same dimensionality as the H-probe subspaces (e.g., via Gaussian sampling followed by orthogonalization to the probe directions where needed), applying identical projection and zeroing interventions, and comparing the resulting task performance drops against those from the hierarchy-specific directions. We will also preserve overall representation norms in the controls as suggested. This will provide a direct test of specificity. In the synthetic tree tasks, while inputs encode tree structure and redundant pathways may exist, the added controls will quantify whether the H-probe directions produce larger drops than random ones, thereby supporting the causal role of the identified subspaces. revision: yes
Circularity Check
No significant circularity in empirical probing methodology
full rationale
The paper develops linear H-probes to extract depth and pairwise distance from latent representations, then evaluates them via experiments on synthetic tree tasks and ablations for dimensionality, causal importance, and generalization. These steps consist of standard probe training followed by intervention-based testing on task performance; no load-bearing claim reduces by construction to a fitted parameter or self-citation chain. The central results rest on external metrics (accuracy drops, generalization scores) rather than any self-definitional loop, satisfying the criteria for a self-contained empirical analysis.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Hierarchical structure in reasoning tasks is linearly representable in model latent spaces
invented entities (1)
-
H-probes
no independent evidence
Reference graph
Works this paper leans on
-
[1]
David D Baek, Yuxiao Li, and Max Tegmark. Generalization from starvation: Hints of universality in llm knowledge graph learning.arXiv preprint arXiv:2410.08255,
-
[2]
Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, et al. Qwen technical report.arXiv preprint arXiv:2309.16609,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Training Verifiers to Solve Math Word Problems
URLhttps://arxiv.org/abs/2110.14168. Hoagy Cunningham, Aidan Ewart, Logan Riggs, Robert Huben, and Lee Sharkey. Sparse autoencoders find highly interpretable features in language models.arXiv preprint arXiv:2309.08600,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
arXiv preprint arXiv:2405.14860 , year=
Joshua Engels, Eric J Michaud, Isaac Liao, Wes Gurnee, and Max Tegmark. Not all language model features are one-dimensionally linear.arXiv preprint arXiv:2405.14860,
-
[6]
Zeyuan Allen Gao, Leo Gao, Tengyu Xu, Haotian Ye, Yike Wu, and Percy Liang. Physics of language models: Part 2.1, grade-school math and the hidden reasoning process.arXiv preprint arXiv:2308.01825,
-
[7]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Wes Gurnee and Max Tegmark. Language models represent space and time.arXiv preprint arXiv:2310.02207,
-
[9]
Designing and interpreting probes with control tasks
10 John Hewitt and Percy Liang. Designing and interpreting probes with control tasks. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 2733–2743,
2019
-
[10]
A structural probe for finding syntax in word representations
John Hewitt and Christopher D Manning. A structural probe for finding syntax in word representations. InProceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language T echnologies, Volume 1 (Long and Short Papers), pp. 4129–4138,
2019
-
[11]
Aaron Jaech, Adam Kalai, Adam Lerer, Adam Richardson, Ahmed El-Kishky, Aiden Low, Alec Helyar, Aleksander Madry, Alex Beutel, Alex Carney, et al. Openai o1 system card. arXiv preprint arXiv:2412.16720,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
doi: 10.18653/ v1/2021.naacl-main.381
Subhash Kantamneni and Max Tegmark. Language models use trigonometry to do addition. arXiv preprint arXiv:2502.00873,
-
[13]
From System 1 to System 2: A Survey of Reasoning Large Language Models
Zhong-Zhi Li, Duzhen Zhang, Ming-Liang Zhang, Jiaxin Zhang, Zengyan Liu, Yuxuan Yao, Haotian Xu, Junhao Zheng, Pei-Jie Wang, Xiuyi Chen, et al. From system 1 to system 2: A survey of reasoning large language models.arXiv preprint arXiv:2502.17419,
work page internal anchor Pith review arXiv
-
[14]
Samuel Marks and Max Tegmark. The geometry of truth: Emergent linear structure in large language model representations of true/false datasets.arXiv preprint arXiv:2310.06824,
work page internal anchor Pith review arXiv
-
[15]
The Linear Representation Hypothesis and the Geometry of Large Language Models
Kiho Park, Yo Joong Choe, and Victor Veitch. The linear representation hypothesis and the geometry of large language models.arXiv preprint arXiv:2311.03658,
work page internal anchor Pith review arXiv
-
[16]
arXiv preprint arXiv:2406.01506 , year=
Kiho Park, Yo Joong Choe, Yibo Jiang, and Victor Veitch. The geometry of categorical and hierarchical concepts in large language models.arXiv preprint arXiv:2406.01506,
-
[17]
Bill Tuck Weng Pung and Alvin Chan. Orchard: A benchmark for measuring systematic generalization of multi-hierarchical reasoning.arXiv preprint arXiv:2111.14034,
-
[18]
Thread: Thinking deeper with recursive spawning
Philip Schroeder, Nathaniel W Morgan, Hongyin Luo, and James Glass. Thread: Thinking deeper with recursive spawning. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language T echnologies (Volume 1: Long Papers), pp. 8418–8442,
2025
-
[19]
Hypothesis-Driven Feature Manifold Analysis in LLMs via Supervised Multi-Dimensional Scaling
Federico Tiblias, Irina Bigoulaeva, Jingcheng Niu, Simone Balloccu, and Iryna Gurevych. Shape happens: Automatic feature manifold discovery in llms via supervised multi- dimensional scaling.arXiv preprint arXiv:2510.01025,
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
Analyzing the structure of attention in a transformer language model,
11 Jesse Vig and Yonatan Belinkov. Analyzing the structure of attention in a transformer language model.arXiv preprint arXiv:1906.04284,
-
[21]
Hierarchical reasoning model, 2025
Guan Wang, Jin Li, Yuhao Sun, Xing Chen, Changling Liu, Yue Wu, Meng Lu, Sen Song, and Yasin Abbasi Yadkori. Hierarchical reasoning model.arXiv preprint arXiv:2506.21734,
-
[22]
Self-Consistency Improves Chain of Thought Reasoning in Language Models
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-consistency improves chain of thought reasoning in language models.arXiv preprint arXiv:2203.11171,
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
Least-to-Most Prompting Enables Complex Reasoning in Large Language Models
Denny Zhou, Nathanael Sch ¨arli, Le Hou, Jason Wei, Nathan Scales, Xuezhi Wang, Dale Schuurmans, Claire Cui, Olivier Bousquet, Quoc Le, et al. Least-to-most prompting enables complex reasoning in large language models.arXiv preprint arXiv:2205.10625,
work page internal anchor Pith review arXiv
-
[24]
Representation Engineering: A Top-Down Approach to AI Transparency
Andy Zou, Long Phan, Sarah Chen, James Campbell, Phillip Guo, Richard Ren, Alexander Pan, Xuwang Yin, Mantas Mazeika, Ann-Kathrin Dombrowski, et al. Representation engineering: A top-down approach to ai transparency.arXiv preprint arXiv:2310.01405,
work page internal anchor Pith review arXiv
-
[25]
PATH: n0 n1 n2 ... n f
For samples with s= 2, we construct the traversals by concatenating the shortest paths between consecutive nodes and dropping duplicate boundary nodes. The resulting dataset is comprised of the following: (depth= 1, steps= 1): 61 examples, (depth= 1, steps= 2): 22 examples, (depth= 2, steps= 1): 439 examples, and (depth= 2, steps= 2): 478 examples. We not...
2000
-
[26]
We extracted depth direction from our depth probe coefficients and lifted to the full space via PCA components when required
and the depth probe direction (having rank 1). We extracted depth direction from our depth probe coefficients and lifted to the full space via PCA components when required. Interventions were implemented via forward hooks at various transformer layers. When ablating subspaces, we updated our hidden states by subtracting the projection onto the ablation ba...
2054
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.